
Lec 13 同步原语
Lec 13 同步原语
License
本内容版权归上海交通大学并行与分布式系统研究所所有
使用者可以将全部或部分本内容免费用于非商业用途
使用者在使用全部或部分本内容时请注明来源
资料来自上海交通大学并行与分布式系统研究所+材料名字
对于不遵守此声明或者其他违法使用本内容者,将依法保留追究权
本内容的发布采用 Creative Commons Attribution 4.0 License
完整文本
Contents
- 多线程问题:竞争条件
- 四种同步原语
- 互斥锁:保证互斥访问
- 条件变量:提供睡眠/唤醒
- 信号量:资源管理
- 读写锁:区分读者以提高并行度
- 同步原语带来的问题
- 死锁的检测、预防与避免
并发问题:竞争条件
对于以下程序,创建三个线程同时执行。
unsigned long a = 0; void * routine(void * arg) { for(int i = 0; i < 1000000000; i++) a++; return NULL; }
执行结果实际上不是3000000000。实际的结果却不唯一。多个进程在共享内存中的变量也会存在上述的问题。
- 竞争条件Race Condition
- 如何确保多个进程/线程不会讲新产生的数据放入到同一个缓冲区中,造成数据覆盖?
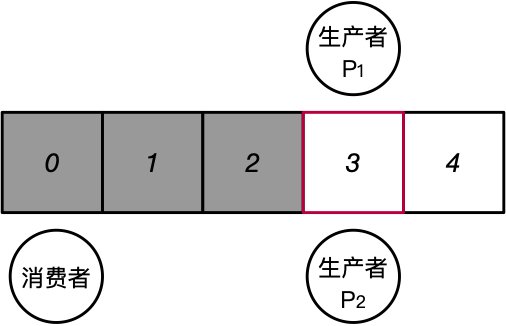
- 此时产生了竞争条件(也称为竞争冒险)
- 当2个或以上的线程同时对共享的数据进行操作,其中至少有一个写操作
- 该共享数据的最后结果依赖于这些线程特定的执行顺序
- example:两个线程同时执行增加a的操作,但最终a仅增加了1.
生产者消费者
基础实现:生产者
while (true) { /* Produce an item */ while (prodCnt - consCnt == BUFFER_SIZE) ; /* do nothing -- no free buffers */ buffer[prodCnt % BUFFER_SIZE] = item; prodCnt = prodCnt + 1; }
基础实现:消费者
while (true) { while (prodCnt == consCnt) ; /* do nothing */ item = [consCnt % BUFFER_SIZE] ; consCnt = consCnt + 1; }
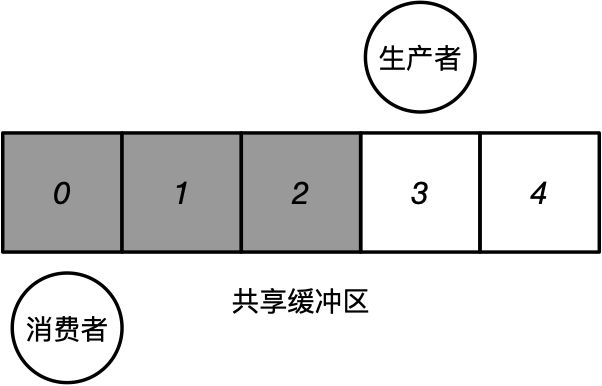
通过两个计数器协调生产者和消费者,是少数符合竞争定义但不出现竞争问题的实现。当出现多生产者时,如何保证多个生产者不会将新产生的数据放入同一个缓冲区中出现数据覆盖问题?(假设为原子操作)
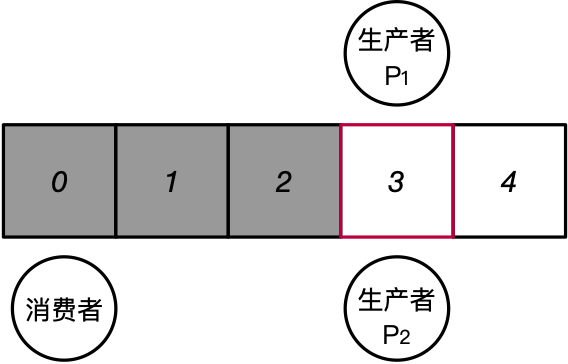
新的抽象:临界区
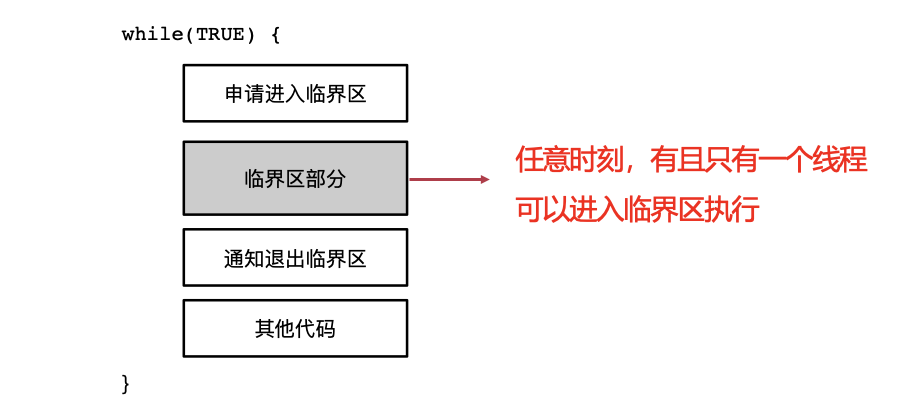
-
实现临界区抽象的三个要求
-
互斥访问:同一时刻,有且仅有一个线程可以进入临界区。
-
有限等待:当一个线程申请进入临界区之后,必须在有限的时间内获得许可进入临界区而不能无限等待
-
空闲让进:当没有线程在临界区中,必须在申请进入临界区的线程中选择一个进入临界区保证执行临界区的进展
-
同步原语
-
一个平台(OS等)提供的用于帮助开发者实现线程之间同步的软件工具。
-
有限的共享资源上正确的协同工作
-
在生产者/消费者例子中:有限的共享缓冲区以及生产者/消费者能够有序地从共享缓冲区中存取数据
互斥锁(Mutex)
- 互斥锁(Mutual Exclusive Lock)接口
- Lock:尝试拿到锁“lock”
- 其他线程没有拿到lock,则获取lock并继续往下执行。
- 其他线程已经拿到lock,则不断循环等待放锁。(busy loop)
- Unlock
- 放锁。
- Lock:尝试拿到锁“lock”
- 保证同时只有一个线程可以拿到锁。
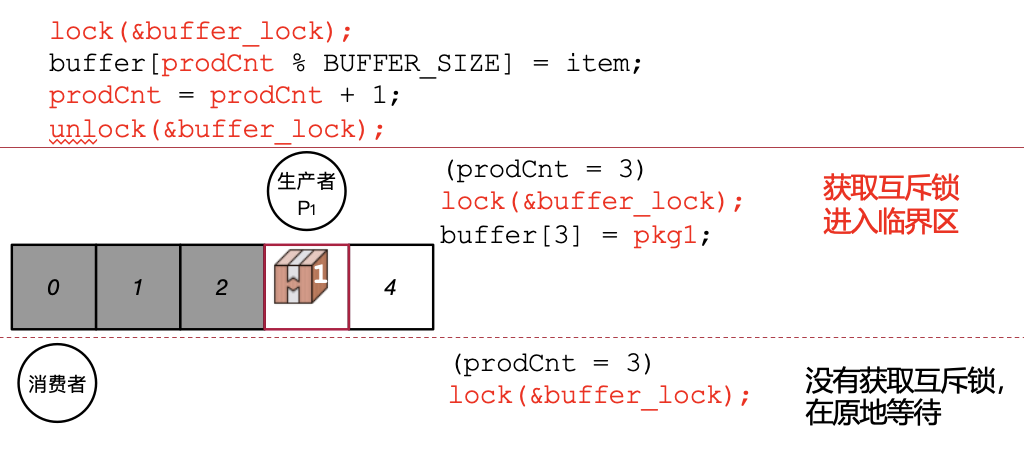
获取到互斥锁后,即可进入临界区写数据。buffer[4]=pkg2;
采用互斥锁实现多线程计数问题:
unsigned long a = 0; void * routine(void * arg) { for(int i = 0; i < 1000000000; i++) { pthread_mutex_lock(&global_lock); a++; pthread_mutex_unlock(&global_lock); } return NULL; }
条件变量
- 条件变量:利用睡眠/唤醒机制,避免无意义的等待。让操作系统的调度器调度其他线程/进程执行。

接口


如果出现多个等待空位代码,不使用while而是if的话,会出现以下情况:
- 线程1获得锁,执行cond_wait,进入等待,调度执行线程2
- 线程2获得锁,执行cond_wait,进入等待,调度执行线程3
- 线程3增加了一个empty_slot,发送信号唤醒线程1
- 线程1执行empty_slot--;
- 线程2此时不再检查empty_slot(已经唤醒则PC已经指向下一条),继续执行empty_slot--;
- empty_slot变为-1,X_X。
信号量
生产者消费者另一种实现
生产者:
while(true) { new_msg = produce_new(); // 获取锁。两个锁分别控制填充条目和空余条目。 lock(&empty_slot_lock); lock(&filled_slot_lock); while (empty_slot == 0) { // ; /* No more empty slot. */ cond_wait(&empty_slot_cond, &empty_slot_lock); } empty_slot--; unlock(&empty_slot_lock); // 释放第一个锁。 buffer_add(new_msg); filled_slot++; unlock(&filled_slot_lock); // 释放第二个锁。 }
消费者
while(true) { lock(&filled_slot_lock); lock(&empty_slot_lock); while (filled_slot == 0) { ; /* No new data. */ } filled_slot--; unlock(&filled_slot); cur_msg = buffer_remove(); empty_slot++; cond_signal(&empty_slot_cond); unlock(&empty_slot_lock); handle_msg(cur_msg); }
- 为了保护计数器并发正确,需要在哪里加锁?如上面代码示例
- 为了避免忙等,在哪里用条件变量?如上面代码示例
- 当前实现:需要单独创建互斥锁与条件变量,并手动通过计数器来管理资源数量。需要新的同步原语,便于在多个线程之间管理资源。
信号量:PV原语
荷兰大佬Dijkstra在1965年提出的方法。
- 信号量:协调(阻塞/放行)多个线程共享有限数量的资源
- 语义上:信号量的值cnt记录了当前可用资源的数量
- 提供了两个原语 P 和 V 用于等待/消耗资源。pass为减少,消耗资源。V为荷兰语的increment,表示增加资源。cnt代表了剩余资源的量。
我们在这里使用down(sig_t *signal)作为P操作,将up(sig_t *signal)作为V操作。我们有:
- down操作在当前资源数量为0时阻塞,释放锁并且进行等待,直到得到唤醒条件为止,将资源数量消耗-1.
- up操作获取锁,将当前资源数量增加一后,释放唤醒信号与释放锁。
可以看到,我们可以将上述的生产者消费者代码更改为:
生产者:作为空槽的消费者和填充槽的生产者。
while(true) { new_msg = produce_new(); down(&empty_slot_sig); // 减少空槽资源。 // down在资源不足时进入cond_wait,等待唤醒。 buffer_add(new_msg); up(&filled_slot_sig); // 增加填充槽资源。 // 具有唤醒功能,如果有因为资源不足进入睡眠的程序。 }
消费者:作为填充槽的消费者和空槽的生产者。
while(true) { down(&filled_slot_sig); cur_msg=buffer_remove(); up(&empty_slot_sig); handle_msg(cur_msg); }
进阶:二元信号量
语义表现如下:
void sig_init(sig_t *signal, int init_cnt) { signal -> cnt = init_cnt; }
-
当初始化的资源数量为1时,为二元信号量。其计数器(counter)只有可能为0、1两个值,故被称为二元信号量。同一时刻只有一个线程能够拿到资源。
-
当初始化的资源数量大于1时,为计数信号量。同一时刻可能有多个线程能够拿到资源
读写锁
不想让某个共享资源在读操作完成之前数据就被写操作给污染/覆盖。并且,多个读操作是不互斥的。
- 互斥锁:所有的线程均互斥,同一时刻只能有一个线程进入临界区
- 对于部分只读取共享数据的线程过于严厉
- 读写锁:区分读者与写者,允许读者之间并行,读者与写者之间互斥
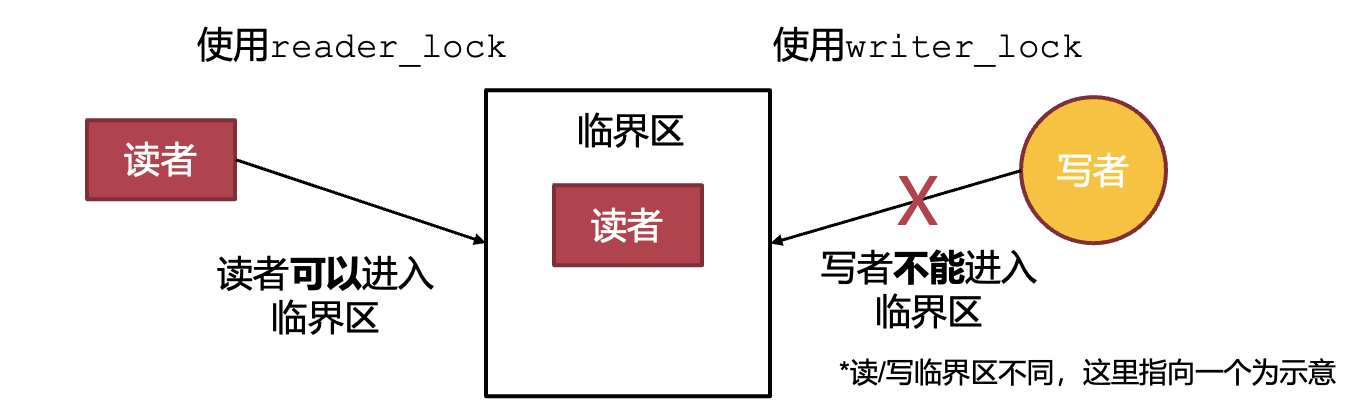
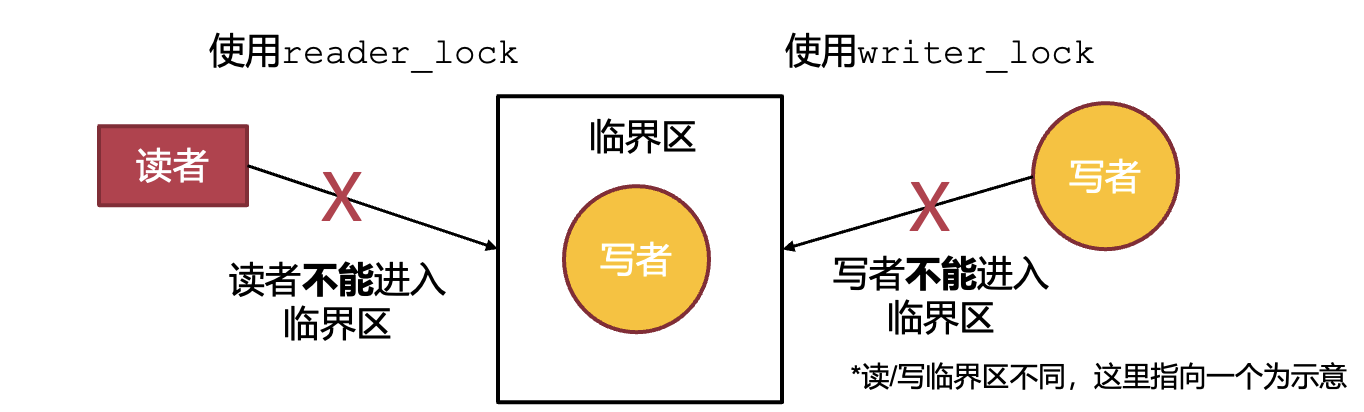
同步原语的一些简单对比
互斥锁vs二元信号量
- 互斥锁与二元信号量功能类似,但抽象不同:
- 互斥锁有拥有者的概念,一般同一个线程拿锁/放锁
- 信号量为资源协调,一般一个线程signal,另一个线程wait
- 互斥锁+条件变量可以实现与二元信号量相同的功能。
互斥锁vs读写锁
- 接口不同:读写锁区分读者与写者
- 针对场景不同:获取更多程序语义,标明只读代码段,达到更好性能
- 读写锁在读多写少场景中可以显著提升读者并行度
- 即允许多个读者同时执行读临界区
- 只用写者锁,则与互斥锁的语义基本相同
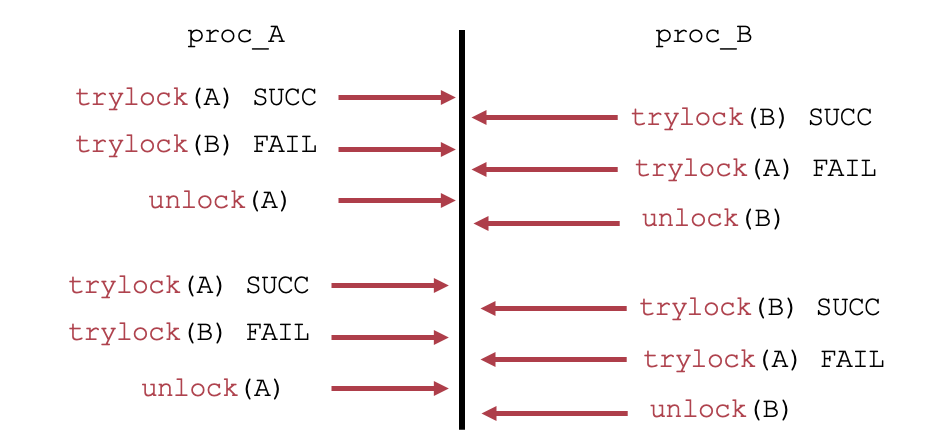
DEADLOCK:死锁
假设我们有:(1) T0时刻,线程1拿到了锁A。线程2拿到了锁B。(2)T1时刻,线程1开始等待锁B被释放。但是线程2也开始等待锁A被释放。这时候双方都被阻塞,都不能继续执行,出现死锁。
产生原因
- 互斥访问:同一时刻只有一个线程能够访问
- 持有并等待:一直持有一部分资源并且等待另一部分。不会中途释放锁。
- 资源非抢占:其他线程不会抢占已经持有锁的资源。
- 循环等待:相互等待对方释放锁。
解决死锁问题
-
出了问题再说法:
- 打破循环等待。
- 直接kill所有循环中的线程;
- Kill一个,看有没有环,有的话继续kill;
- 全部回滚到之前的某一状态。
-
预防方法,不想出了问题再背锅
- 避免互斥访问:通过其他手段(代理执行)
- 只有代理线程能够访问共享资源避免数据竞争(代理锁)
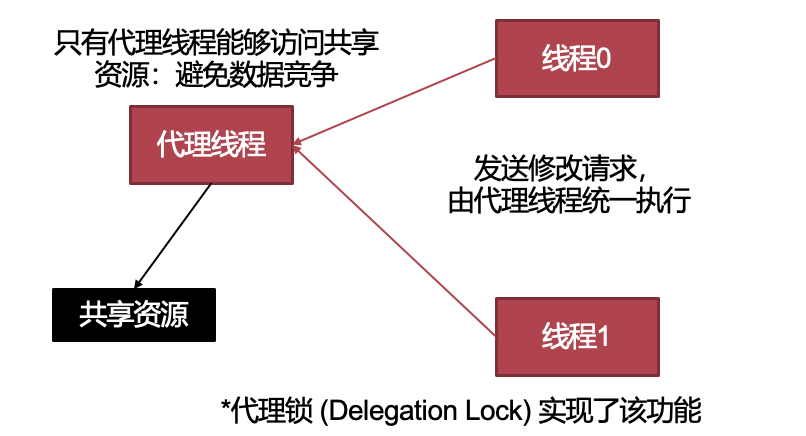
- 不允许持有并等待:一次性申请所有资源。

- 但有可能产生活锁:live lock,一直循环往复成功-失败-释放。
- 解决方法:抢占式资源。需要考虑如何恢复。
- 打破循环等待:按照特定顺序获取资源。(1)编号。(2)递增获取。任意时刻,获取最大资源号的线程可以继续执行然后释放资源。
-
解决运行时死锁办法:运行时检查是否会出现死锁。
- 银行家算法
- 所有线程获取资源需要管理者的同意。
- 管理者预演不会造成死锁。如果会造成则阻塞该线程。
- 预演判断:系统分为两个状态。对于一组线程
- 安全状态:找出至少一个执行序列
- 非安全状态:无法找出序列,必定导致死锁。
- 安全状态:找出至少一个执行序列
- 四个数据结构:对于M个资源,N个进程:
- 全局可利用资源:
Available[M] - 每个线程最大需求量:
Max[N][M] - 已经分配的资源:
Allocated[N][M] - 还需要资源:
Need[N][M]
- 全局可利用资源:
某时刻我们有:
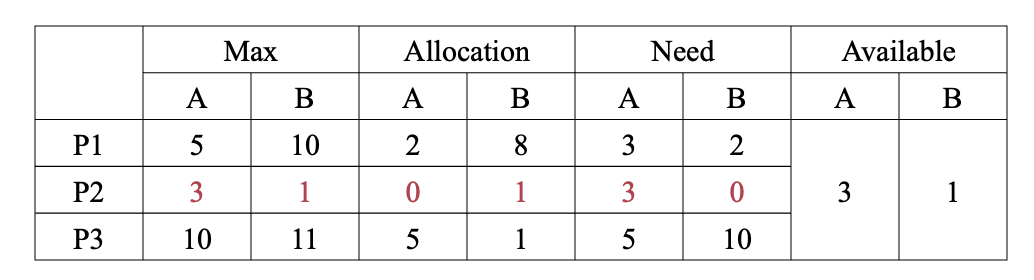
- P2请求到来。
- 第一次,模拟执行P2,最终available为A3B2。
- 第二次,模拟执行P1,最终available为A5B10。
- 第三次,模拟执行P3,最终available为A10B11。
- 执行路径:
- 假如首次到来的请求为P1.
- 模拟无法通过,造成死锁。阻塞P1。
同步原语的实现
lock:错误的实现
#include<stdio.h> enum stat_t { UNLOCKED = 0, LOCKED }; struct lock_t { enum stat_t state; }; void lock(struct lock_t *L) { while(L->state == LOCKED) continue; L->state = LOCKED; } void unlock(struct lock_t *L) { L->state = UNLOCKED; }
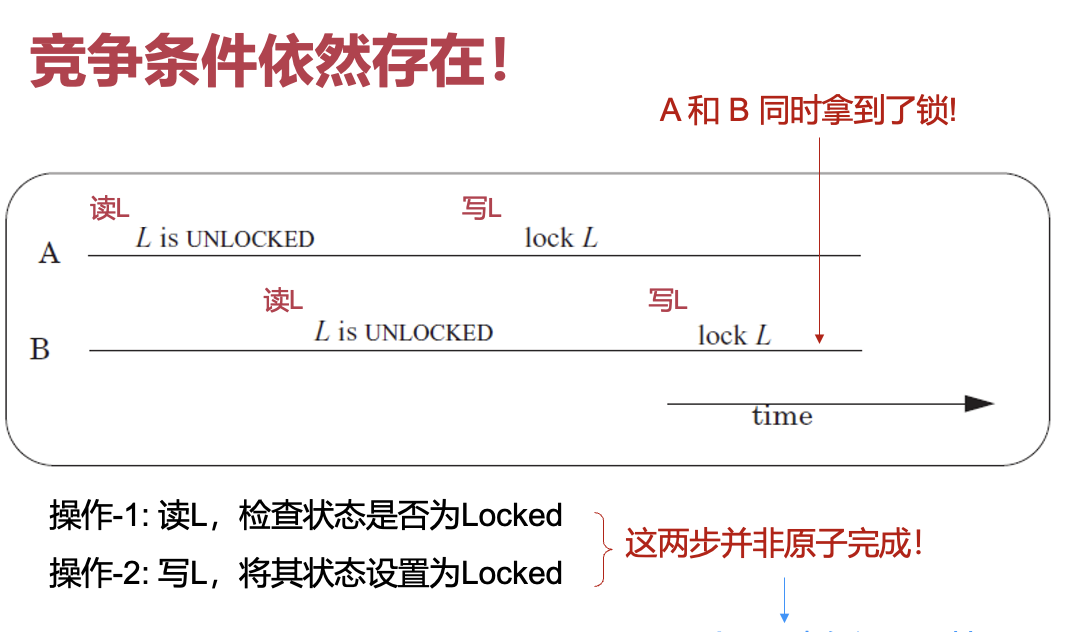
互斥锁的实现:基于硬件原子指令
- 硬件方法:保证两步是原子的(atomic)!
- 以下四种指令:
// Test and Set.(1960s) int TestAndSet(int *old_ptr, int new) { int old = *old_ptr; // 从旧指针中获得值。 *old_ptr = new; // 将新的指针存入旧的指针中。 return old; // 返回旧值。 } int CompareAndSwap(int *ptr, int expected, int new) { int actual = *ptr; if (actual == expected) *ptr = new; return actual; } enum stat_t { UNLOCKED = 0, LOCKED }; struct lock_t { enum stat_t state; }; void init(struct lock_t *L) { L -> state = UNLOCKED; } void lock1(struct lock_t *L) { while(TestAndSet(&L->state, LOCKED)==LOCKED) continue; L->state = LOCKED; } void lock2(struct lock_t *L) { while(==LOCKED) continue; L->state = LOCKED; } void unlock(struct lock_t *L) { L->state = UNLOCKED; }
- ARM: load-linked与store-conditional:
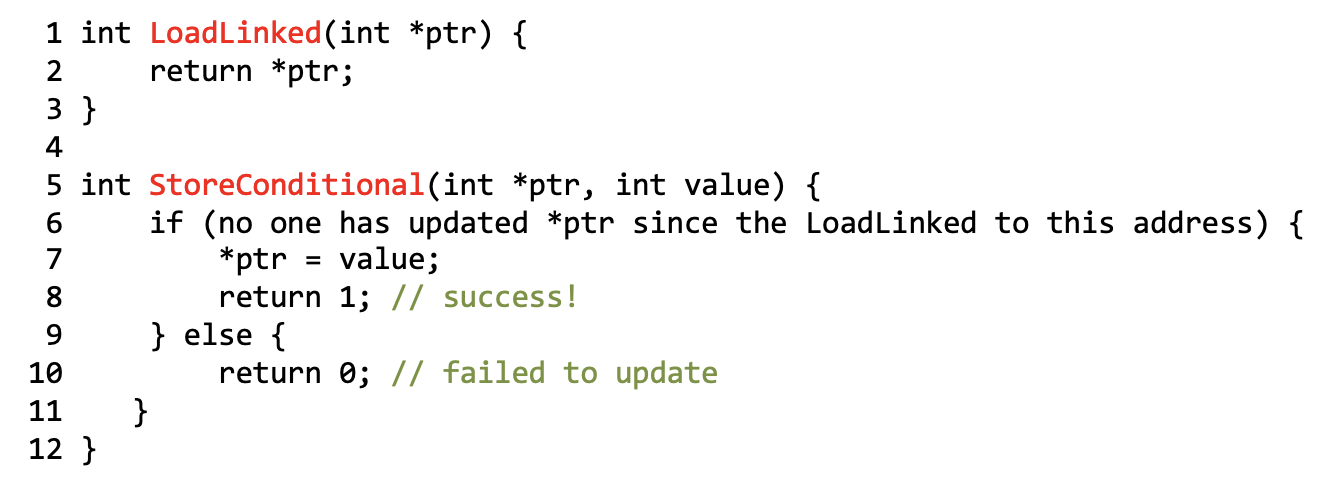

- Fetch-and-add实现Ticket Lock
int FetchAndAdd(int *ptr) { int old = *ptr; *ptr = old + 1; return old; } typedef struct __lock_t { int ticket; int turn; } lock_t; void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; } void lock(lock_t *lock) { int myturn = FetchAndAdd(&lock -> ticket); while (lock -> turn != myturn) continue; } void unlock(lock_t *lock) { lock->turn = lock->turn + 1; }
排号锁(Ticket Lock)
- 如何保证竞争者的公平性?遵循竞争者到达的顺序传递锁。
条件变量的implement
-
void wait(struct cond *cond, struct lock * mut) -
放入条件变量的等待队列
-
阻塞自己释放锁
-
唤醒后重新获取锁
-
void signal(struct cond *cond) -
检查等待队列
-
存在等待者移出队列并且唤醒。
-
系统调用
yield()- 暂停当前运行的线程,保存上下文
- 选择新的可以运行的线程,可以通过RR找到下一个线程。
- 恢复上一步所选的线程。重新加载上下文。
-
三个数据结构:
threads table记录所有线程的表。t_lock也就是线程表的锁,保护线程表。CPUs table记录每个CPU当前的运行线程。(没有lock保护,是因为每个CPU只会访问自己的表,不可能跨核访问)。
void yield() { lock(&threads_table_lock); // 锁上线程表。 // 暂停运行的线程 id = cpus[cur_cpu].thread; threads[id].state = RUNNABLE; threads[id].sp = stack_pointer; // 选择新线程 do { id = (++id) % N; } while (threads[id].state != RUNNABLE) // 恢复线程的运行 stack_pointer = threads[id].sp; threads[id].state = RUNNING; cpus[cur_cpu].thred = id; unlock(&threads_table_lock); }
条件变量的implement:wait与signal

-
loss Notification问题
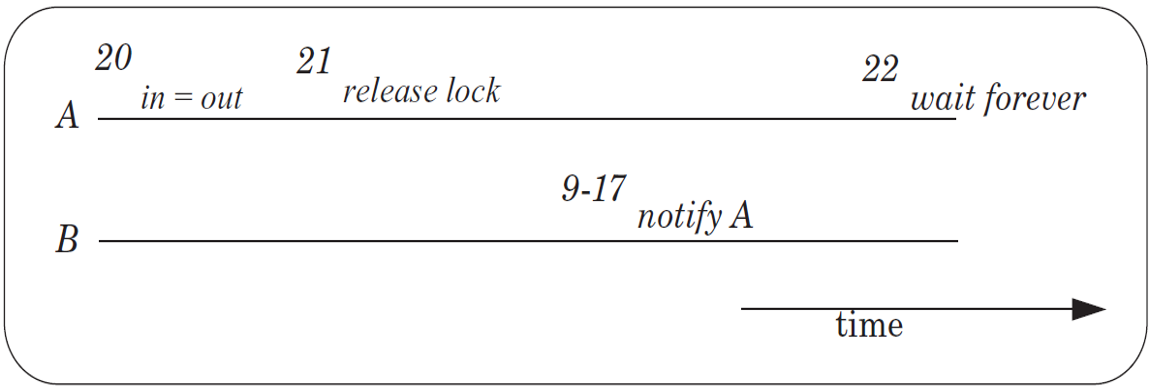

- 先放lock,有可能在执行到
yield_wait()之前,send就已经发送信号,导致无法收到信号,进而永远等待下去。
-

设计yield_wait()可以参考yield。
void yield_wait() { // 不需要再锁上表因为已经拿到锁。 id = cpus[cur_cpu].thread; // 不需要设置状态因为当前状态已经设置了。 threads[id].sp = stack_pointer; // 时钟中断导致thread错误睡眠! cpus[cur_cpu].thread = NULL; // 设置一个cpu栈表储存上下文信息。 temp_SP = cpus[cur_cpu].stack; // 选择新线程 do { id = (++id) % N; // 避免死锁问题:如果没有一个线程runnable,并且线程表一直被锁,无法唤醒其他线程。 unlock(&thread_table_lock); // 时钟中断:突然发生时钟中断,导致拿起锁后没有释放锁,却需要再一次拿锁,出现死锁。 enable_interrupt(); disable_interrupt(); lock(&thread_table_lock); // 下一个CPU可能立刻执行该线程,导致两个CPU的栈指针指向当前线程,破坏线程的栈! /* 1. 0-unlock, 1-signal把0变成runnable, 2-wait 2. 2-找到了0线程是runnable的 3. 2原先的线程栈崩坏。 */ } while (threads[id].state != RUNNABLE) // 恢复线程的运行 stack_pointer = threads[id].sp; threads[id].state = RUNNING; cpus[cur_cpu].thred = id; // unlock(&threads_table_lock); } void yield() { lock(&threads_table_lock); // 锁上线程表。 // 暂停运行的线程 id = cpus[cur_cpu].thread; if (thread == NULL) return; threads[id].state = RUNNABLE; threads[id].sp = stack_pointer; // 选择新线程 do { id = (++id) % N; } while (threads[id].state != RUNNABLE) // 恢复线程的运行 stack_pointer = threads[id].sp; threads[id].state = RUNNING; cpus[cur_cpu].thred = id; unlock(&threads_table_lock); } void wait(cv, lock) { disable_interrupt(); // 防止时钟中断问题 lock(t_lock) unlock(lock) threads[id].cv = cv threads[id].state = WAITING yield_wait() unlock(t_lock) enable_interrupt() lock(lock) }
信号量的实现
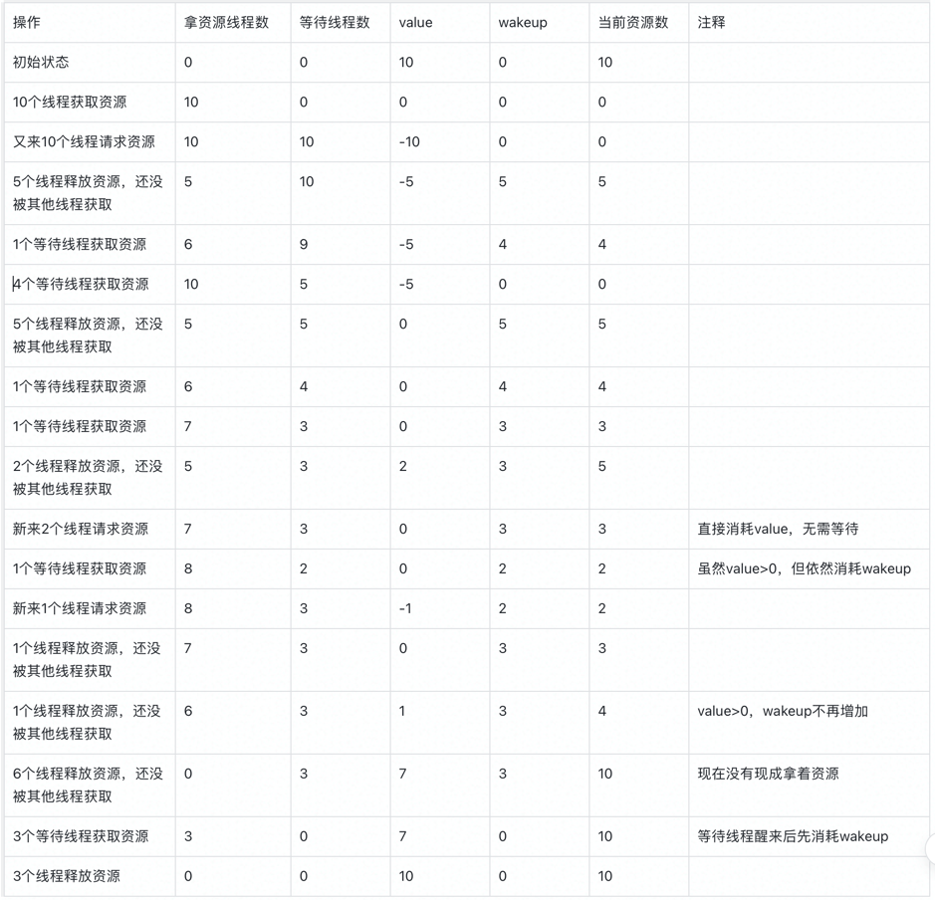
void wait(sem_t *S) { lock(S->sem_lock); // 改成负数减少signal次数,仅有负数才有人等待。 // 加入wakeup变量判断有多少可以唤醒。 // 某一时刻真实资源数量:value < 0 ? wakeup:value+wakeup. S->value--; while(S->value < 0) { // unlock(S->sem_lock); // lock(S->sem_lock); // 不要忙等 // cond_wait(S->sem_cond, S->sem_lock); do { cond_wait(S->sem_cond, S->sem_lock); } while (s->wakeup == 0); //有限等待 } // S->value --; // 防止等于-1. S->wakeup--; unlock(S->sem_lock); } void signal(sem_t *S) { lock(S->sem_lock); S->value ++; // cond_signal(s->sem_cond); // 每次都需要signal,可能没有函数调用了wait。只有资源小于0才有人等待。 if(S->value < 0) { S -> wakeup++; cond_signal(s->sem_cond); } unlock(S->sem_lock); }
读写锁的实现
- 考虑这种情况:
- t0:有读者在临界区
- t1:有新的写者在等待
- t2:另一个读者能否进入临界区?
- 不能:偏向写者的读写锁(公平性)
- 后序读者必须等待写者进入后才进入
- 能:偏向读者的读写锁(并行性)
- 后序读者可以直接进入临界区

- 偏向读者的读写锁。
- reader:多少读者。
- 第一个/最后一个读者获取/释放锁。只有完全没有读者的时候写者才能进入临界区域。
- 获取读者锁,更新读计数器
- 如果没有读者在,拿写锁避免写者进入。有读者在,无需再次获取写锁。如果有写者在,等待。
- 如果没有其他读者,释放读者锁和写锁。否则释放读者锁,不需要释放写锁。
同步原语比较

互斥锁vs读写锁2
- 读写锁为特定场景(衍生场景一)下提升读者并行度
- 衍生场景一直接使用互斥锁
- 也可以保证正确性
- 读者之间不能并发执行
- 特定场景下的性能优化
互斥锁vs条件变量
- 解决不同场景(正交)
- 互斥锁:互斥访问
- 条件变量:条件等待与唤醒
- 条件变量需要搭配互斥锁使用
- 互斥锁中也可以使用条件变量避免循环等待
- 场景一中也可能包含场景二的需求
互斥锁vs信号量
- 互斥锁与二元信号量
- 功能基本一致,二元信号量可以实现互斥
- 语义差别:二元信号量可以由不同的线程获取/释放。互斥锁语义上只能由同一个线程获取与释放
- 保护资源互斥场景,推荐使用互斥锁(方便优化)
- 互斥锁与计数信号量
- 应对不同场景
- 互斥锁控制对唯一资源的互斥访问(即临界区)
- 计数信号量控制多个线程对多个资源的获取与释放
- 应对不同场景
条件变量vs信号量
- 提供了类似的接口
- 抽象层级的区别
- 条件变量
- 更底层,提供睡眠唤醒机制
- 适用范围更广
- 信号量
- 针对具体的场景:提供对有限资源的管理
- 可以使用条件变量+互斥锁+计数器实现信号量
- 条件变量
案例分析
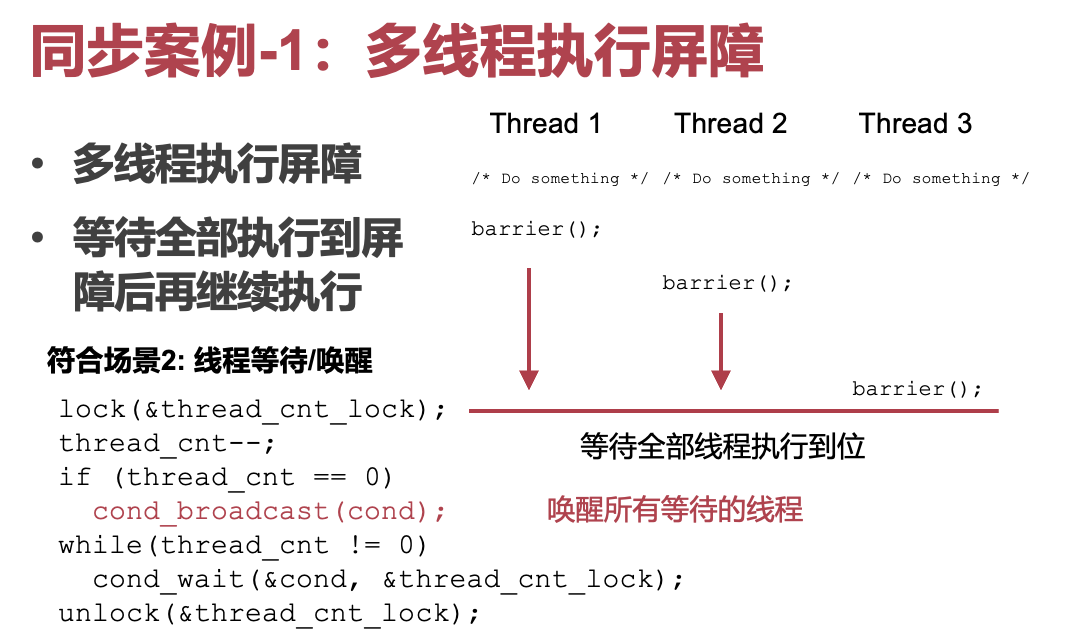


// mapper: void mapper() { lock(&finished_cnt_lock); finished_cnt ++; cond_signal(&cond); unlock(&thread_cnt_lock); } // reducer: void reducer() { lock(&finished_cnt_lock); while(finished_cnt == 0) cond_wait(&cond, &finished_cnt_lock); /* collect result */ finished_cnt = 0; unlock(&thread_cnt_lock); }
- 上述场景也符合场景3:将Mapper的结果视为资源。
- 上一种可以多个结果一起collect,sem这种只能一次collect一个sem的语义,就是一次能拿走一个(counter每次只能减一),但cv更复杂
void mapper() { signal(&finish_sem); } void reducer() { while(finished_cnt != mapper_cnt) { wait(&finish_sem); /* collect result */ finished_cnt ++; } }


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库