
SimAI(NSDI 2025)
SimAI Reading
Abstract
简介
-
大量的资源消耗阻碍了对整个模型的优化。模拟器在基础设施的投资前后都十分重要。
-
计划阶段:帮助估计需要的规模和架构。
-
操作阶段:帮助增加资源利用率,保证在投资上的回报。
-
模拟器不仅仅是增加效率的工具,也是最大化资源使用和保证对基础资源的投资能够有有效回报结果的策略集合。
-
当前一般采用模拟器,分别进行容量规划和表现精调。
-
对于容量规划,一般在流或工作层面进行模拟,忽视包级别的表现。
-
对于表现精调部分,依赖于包级别的模拟来分析网络交通的模式,延时和包丢失,在AI训练和推理中对于优化通信和计算至关重要。
Motivation
-
单个LLM模型的训练需要大量的GPU,阻碍了对新的设计,优化和精调的验证。
-
存在的模拟器,仅针对于整个训练中特定的粒度,本质上导致了不精确。
-
动机1: AI 训练 infra
-
动机2: 统一的模拟器需要
- 对全局AI-infra架构评估的需求。(GPU选择,网络架构设计,主机架构设计)
- 较低开销的对于优化的验证:(调参,评估新机制)
- 统一的模拟框架的发展
-
目标:
- 生成符合现实的训练时工作负载。灵活并且精确,可以在多种模型,参数和规模上。
- 基于浮点运算的粒度太粗。
- 基于函数层面的跟踪仅在具有相同参数的LLM上有效。
- 高精度的集合通信模拟器,包含关键优化和提升。
- NS-3和OMNET++提供包层级模拟但是忽视了集合通信在分布式训练的影响。(引入NCCL)
- 有效的计算模拟器,提供精度和可扩展性。
- GPGPU-sim模拟核级别运算但是时间过长。
- ASTRA-sim不支持不同GPU且某些情况下精度不高。
- 可扩展并且可以在大规模LLM上有效快速运行。
- 生成符合现实的训练时工作负载。灵活并且精确,可以在多种模型,参数和规模上。
挑战
分离的多个粒度的不同模拟器会导致一下的挑战。
- 这样的方法导致了开销-表现分析的不准确性,很难去预测负载均衡表现,评估系统失败。
- 精调模拟器的表现不佳,粗调模拟器的低准确度限制了对大规模部署模型的训练的优化。
- 分裂的方法是测试和发展变得复杂,增加了模拟和实际表现的分离的风险。
应对
部署一个统一两个部分(容量规划,表现精调)的单一框架。需要解决以下难点:
- 生成高精确度的工作负担来反应真实的AI训练表现。
- 模拟高精确度的跨多GPU架构计算。
- 精确地对通信进行建模来估计网络来估计网络交通模式和延时。
- 规模化模拟器来支持多样,大规模的AI基础设施的配置。
- 为了生成精准的对于任意规模的LLM训练的工作负载,SimAI借用了当前主流的训练架构,例如Megatron,DeepSeed,在单一主机上运行和创造精细化的工作负载。(3.2)
不同的解决方案保证了针对计算和通信的精确模拟。
- 计算:将工作负载分裂到精细化的核,在已经存在的GPU上衡量执行时间,并将它们映射到其他类型的GPU上。(3.3)
- 通信:借用NCCL库来精准模拟包级别的集合通信行为。(3.4)
通过多线程加速和全局无锁上下文分享来加速执行速度。(3.5)在准确度上仅有1.9%偏差,在可扩展性上具有适应性,健壮性。(4)
- 指导性意见针对包括新主机设计,仅准度评估和规模化优势。(5)
- 转换方法,将simAI从单一模拟器转换成广泛使用的模拟器服务(6)
SimAI可以做什么?
SimAI可以适应各个层面的LLM训练生态。
- 框架层面:探索并行策略,计算-通信重叠技术,便利参数调整减少端到端训练时间。
- 集合通信层面:提供验证和量化新算法的表现赠一的平台。允许对主机间/内配置,寻找最优方案。
- 网络层面:允许对多种CC算法,网络协议,路由策略在不同架构设定上的效果进行调查。
SimAI模拟器
1 总览
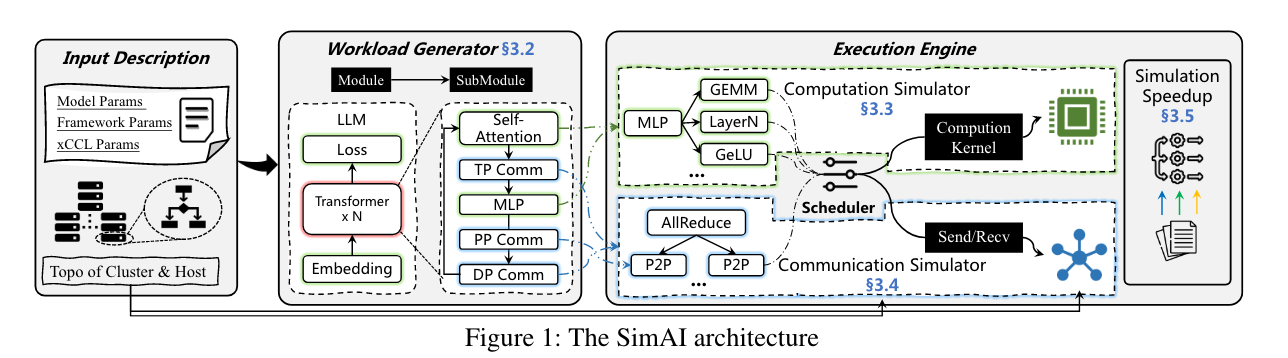
-
每个模拟请求包括:
- 训练进程(模型自身和参数),训练框架设置,集合通讯库相关参数,网络主机内/间拓扑结构。
-
工作负载生成器对每一个模拟请求生成实际的工作负载,输出工作负载描述文件,算法模块梗概,集合通讯方式和依赖。
-
随后工作负载文件将会通过执行引擎进行处理,模拟了作为离散事件同时进行的计算和通信。采用计算模拟器(CP)和通信模拟器(CM)分别进行对计算和通信任务的模拟。
-
采用多线程加速和全局无锁上下文分享来加速执行速度。
2 工作负载生成器
2.1 生成工作负载文件
- 单一主机生成工作负载。
- 在没有使用大规模GPU集群的条件下,主要的挑战是在单一主机上借用DeepSeed/Megatron框架并且考虑多个主机对之间的互动。为了解决挑战,我们在NCCL框架上做出了两点修改:
- 让NCCL框架相信自己在一个拥有目标数量的GPU集群上运行。主机间的拓扑结构也设定用于模拟一个全局的集群配置。
- NCCL中的通信部分全部跳过。对于存在流水线并行的架构,需要对WG进行准确的阶次配置。
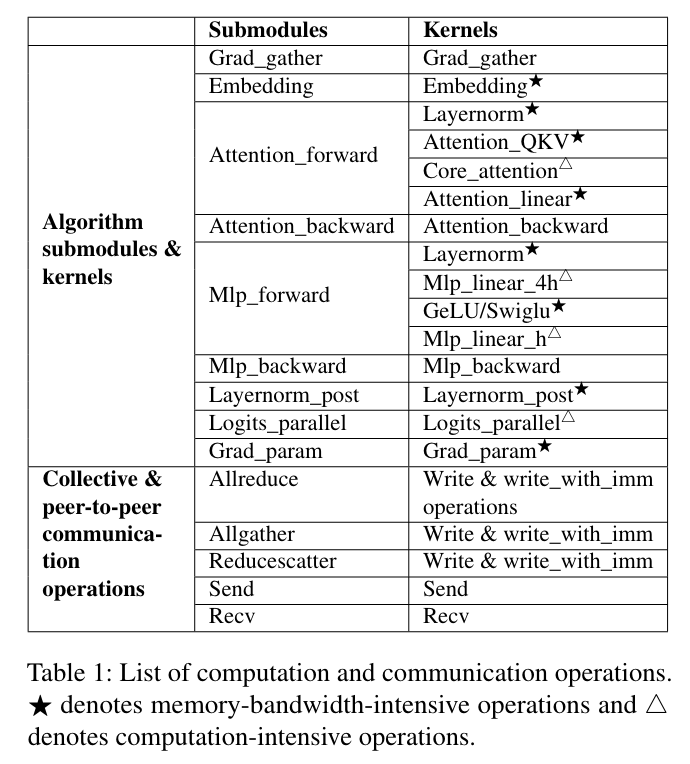
这样允许训练框架生成一系列计算/通信操作,包括算法子模块,集合/p2p通信。但是这些操作缺乏依赖关系说明。
- 确定操作依赖关系
基于使用的并行化架构来确定依赖关系(dependencies)并且在Nvidia Nsight系统上用1024个GPU集群验证。
下图是使用了向量并行,数据并行,流水线并行的实例。
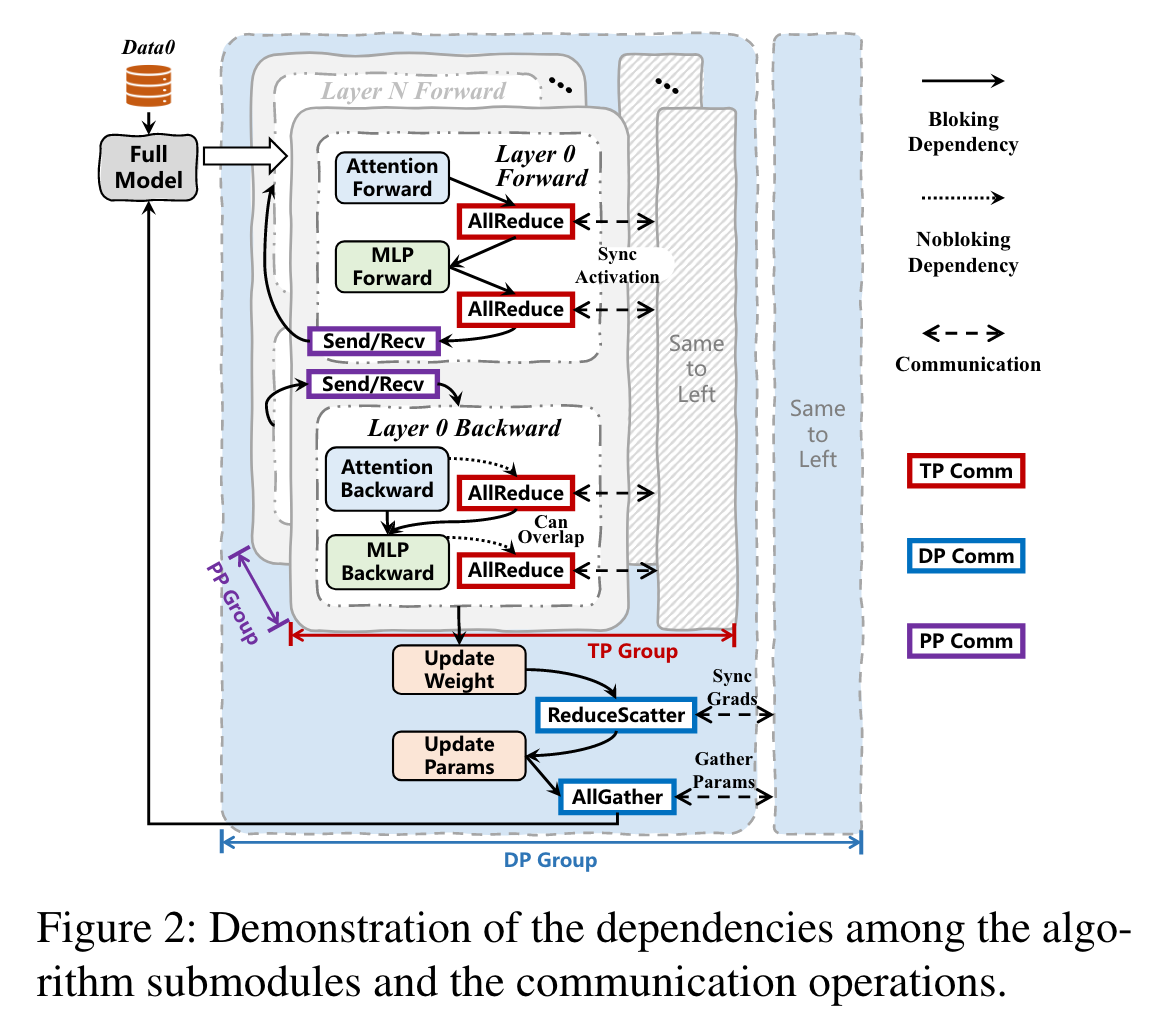
将工作负载从训练框架中解耦,用于独立的模拟。我们用simAI的WG来提取模型的工作负载,并且在simAI的执行引擎中模拟。这样避免了对训练模型,数据流水线等关键部分的大量修改。
- 在大语言模型中的通信
LLM训练中元数据交换(metadata exchange)和同步屏障操作(barrier operation)在LLM中可以被忽略,不是simAI模拟的关注点。
张量/流水线/专家/数据并行引入了通讯事件。前三者有固定的通讯模式和容量,不会受到集群大小的影响,包括中型大小的信息。数据并行会随着集群模式的增加而增加,包括gigabyte级别的集群通信(AllGather/ReduceScatter)操作。
2.2 决定benchmark
- 模型/框架选择:三类别(小,中等,大)
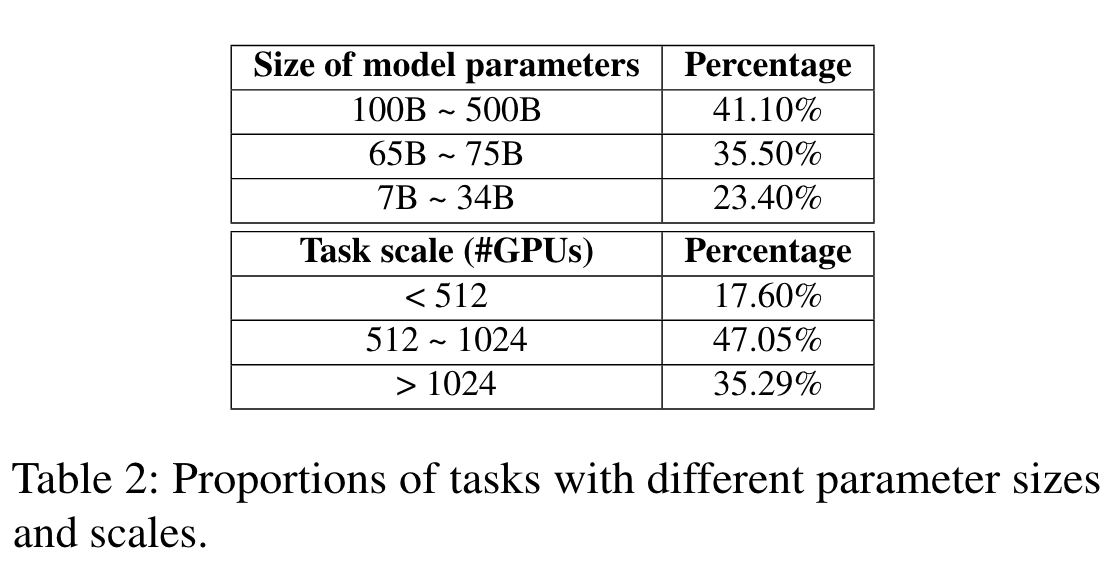
- 参数选择:
- 模型参数:(隐藏层大小,层数,序列长度等)
- 框架参数:(全局总进程个数,ZeRO优化层级,reduce桶个数,all_gather桶的个数,并行策略。)
3 精确的计算模拟
精确模拟存在的GPU
根据生成的子模块工作流来模拟在单一主机上的当前GPU执行子模块的时间。
由于在LLM训练中单个GPU专门执行一项任务,因此可以通过跟随工作负载晚间来模拟整体的计算流程,然后得到每个子模块的执行时间。
维护了一个数据库来记录所有基准LLM中的子模块执行时间。
对于基准外的情况,需要特定的GPU测试来手机其他数据。
精细化的核模拟
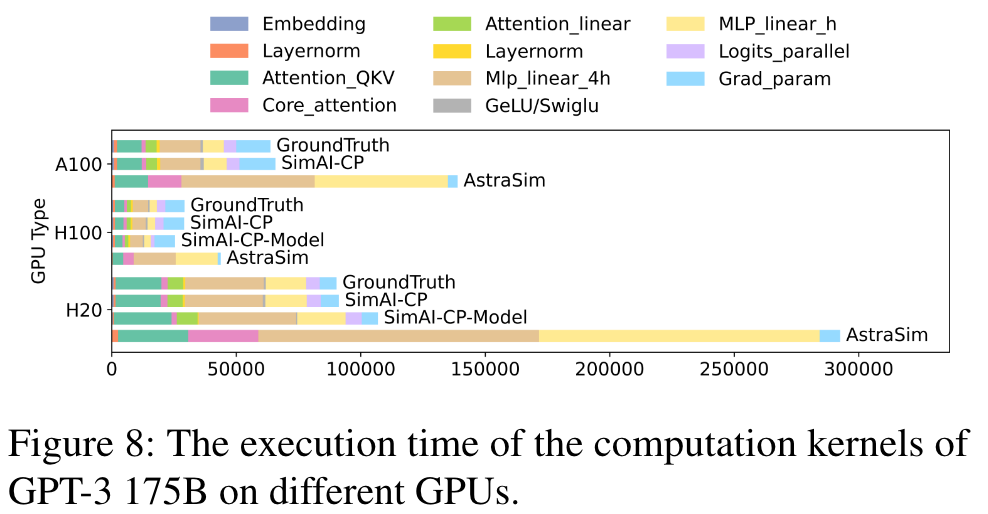
新的并行策略或优化重组或着精调核用于更好的表现,在以上的情况下需要精细化的模拟策略。simAI设计了模块-核转换器将这些子模块分裂成更小的核,在不同的GPU上进行测试。上图的第三列举例说明了不同子模块里的核。
支持没有释放的GPU
- 传统方式是从现有的GPU直接按照核的规格进行缩放,但是精确度不佳。
- 不同的核具有不同的表现瓶颈,一般会分成两个类别:计算紧需和内存带宽紧需。例如,GEMM(通用矩阵乘法核,用来更新注意力中的KV缓存,是内存带宽紧需型,但是flash-注意力是计算紧需型的。
- 增加精确度,采用以下两个公式进行计算:
- 对于计算紧需型:
- 自然很容易推知内存/带宽紧需型:
建议在相同框架的GPU上进行估测。(?)
4 精确地对通信的模拟
训练框架,依赖于集合通信库(NCCL)等,将通信原语(all reduce等)转换成为网络层级的操作(send,recv)。这样复杂的流程包括基于节点数,消息大小,配置参数来选择最优化的算法。很小的偏差都会导致很大的模拟偏差。
重现NCCL中关键的措施
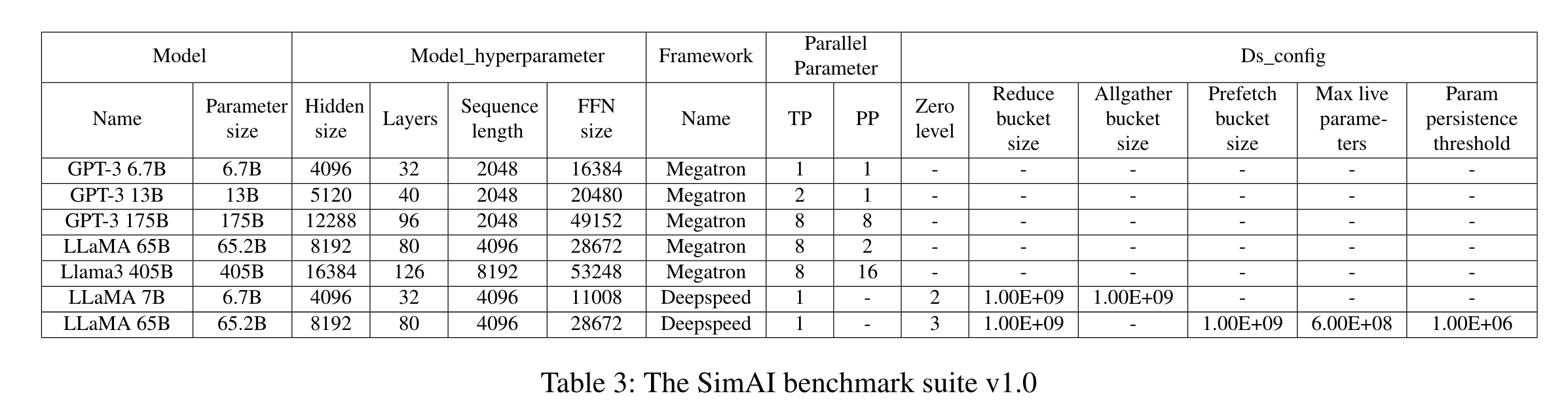
simAI-CM(通信模拟器)采用编辑后(跳过实际的通信)的NCCL观察核心操作。simCCL将会捕捉集合通信的初始化/核接口来生成点对点通讯列表。类似于生成工作负载的方式,simCCL在单个主机上来模拟在集合通信层级的详细的点对点操作。
- CCL修改了NCCL的相关行为:
- NCCL初始化:simCCL观察使用libhacknccl.so动态库的NcclCommInitAll函数行为,为每一个GPU生成虚拟通信器。这样可以使得系统好像在一个真的GPU集群上,允许初始化阶段的套接字连接和数据交换。在bootstrap和网络初始化阶段,多个虚拟通讯器将会在同一个通讯集群中创建,但实际上只有一个通讯器实际创建了。
- 发现拓扑结构:simCCL读取用户定义的拓扑文件来明确拓扑结构。每个虚拟通讯器可以独立处理拓扑结构无需同步。
- 主机内通讯频道创建:在虚拟通讯器之间创建通信频道,并且将细节存储在独立的信息表中。
- 主机间通讯频道建立:旁路将会收集其他使用
allgather操作的信息。直接创建主机间通信。 - 集合通信转换:观察集合通信的调用,重构操作以跟踪低等级的通信情况。跳过了十几的数据传输,并且捕捉GPU间的通信事件,包括数据大小,发送/接收端阶次,路由,模拟RDMA层行为。
支持所有的参数
simCCL反映了大部分主要的NCCL参数的通信行为。支持PCIxNVLINK(PXN)。PXN允许GPU使用非本地网卡(在同一个节点内),通过NVLINK来进行数据传输。
在轨道-优化网络拓扑结构中部署,允许跨节点网络交通流量在同一个轨道(单跳交换机)来实现信息收集和交通优化。simCCL可以识别这些交通方式,并且反映在输出流模型中。
simCCL设计为模仿NCCL或其他CCL处理工作流时的通信行为。关注于将集合通信转换为一组易于解释的点对点通信,没有引入实际的数据验证/真实性检测。这样就实际上没有影响端到端训练,因为犹豫实际数据的缺失并没有引入新的工作流。
在专家模型中,门模块令牌的分布受到数据值的影响。在模拟中假设成平均分布,对模拟结果影响最小。
5 大规模模拟加速
部署了多线程加速simAI通信模拟。采用UNISON分布式网络拓扑和并行离散事件模拟来加速网络模拟。原因如下:(1)来源且基于NS-3.(2)自动化分割网络拓扑结构并且安排任务给合适的线程。(3)具有很强的可扩展性。
无锁全局变量分享
当模拟规模增大后,大量的全局配置和上下文将会跨线程分享。更新分享的数据如果具有全局锁,即使是原子层面,也会成为表现瓶颈。
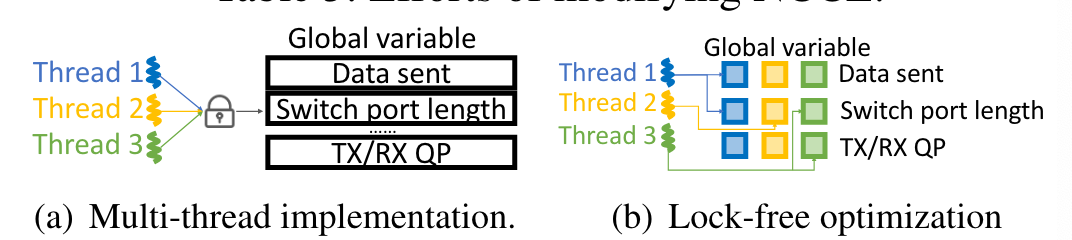
全局变量跟踪主机间通讯,例如节点间的数据流量和交换机中的队伍长度。在变量上的院子操作将会减缓这些并发的线程操作。
基于此我们观察到大部分的全局变量被特定的线程进行读写。将这些变量按照线程独立的方式管理,移除了全局锁。实现了23x提速。对于有锁的多线程提升了15%。
评估
- 基于精确度和可扩展性进行评估。
- 采用开源模拟器ASTRA-sim进行比较。
- 真实结果作为ground truth。
1 平台与基准
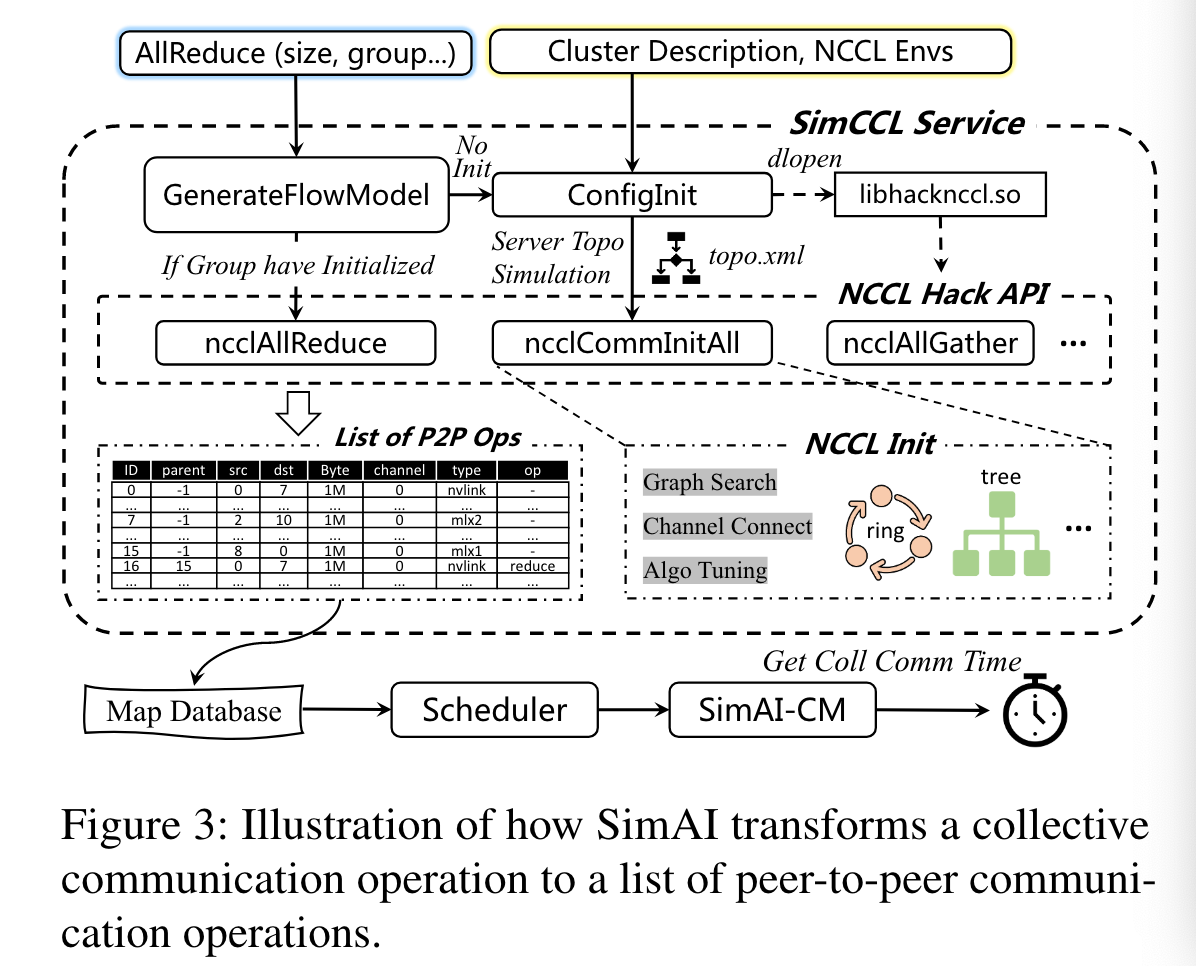
两个平台,共享多轨宽树主机间采用RoCEv2网络的平台。
- A100集群拥有128个GPU主机,每个配备八个NVIDIA A100GPU,4个Mellanox ConnectX-6 网卡。
- H100集群拥有128 GPU服务器, 每个主机有八个NVIDIA H100 GPUs和八个Mellanox ConnectX-7 网卡。
- 主机间通讯采用NVLINK,A100带宽为600GBps,H100为900GBps。
2 通讯模拟精确度
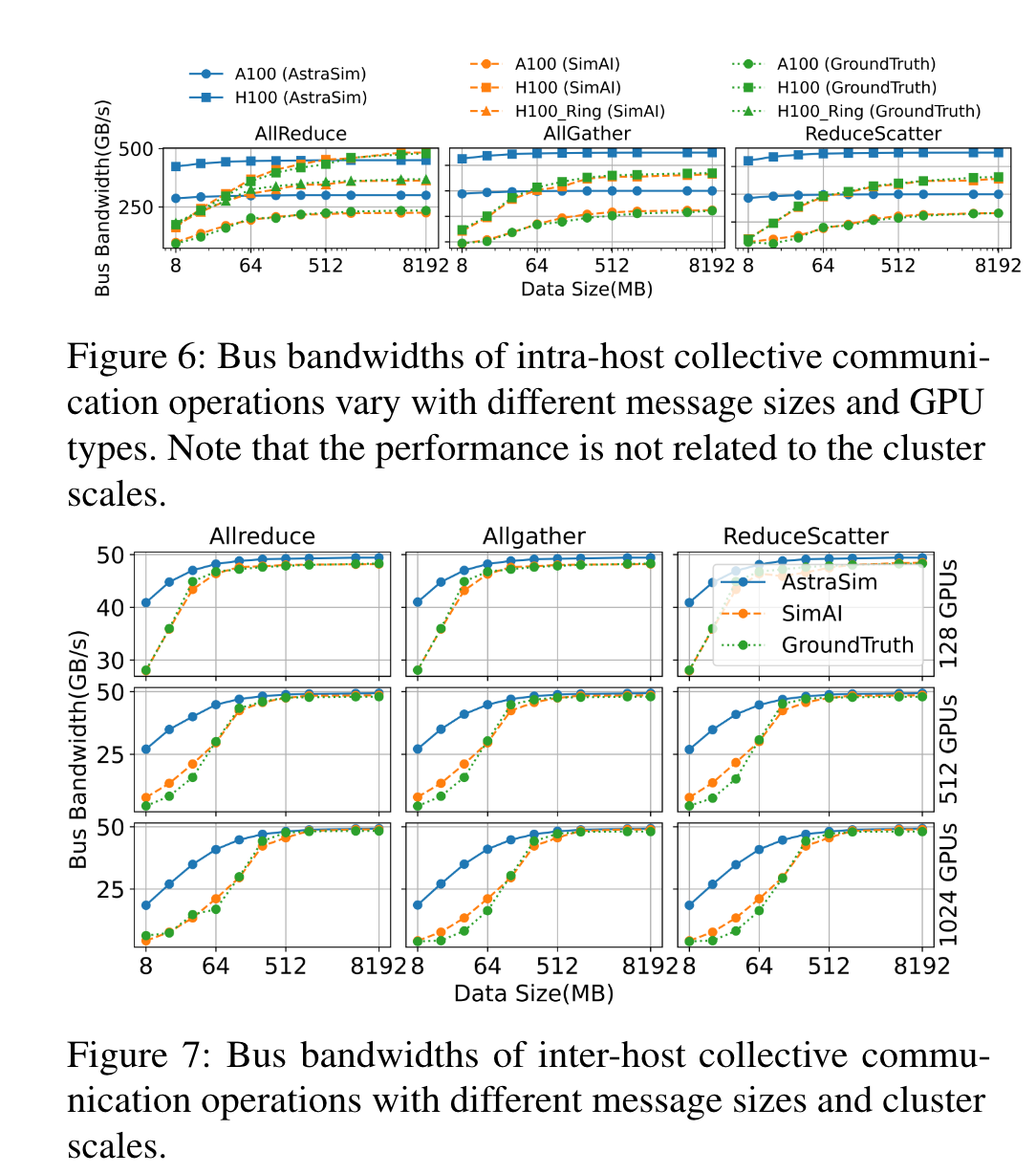
3 计算模拟精确度
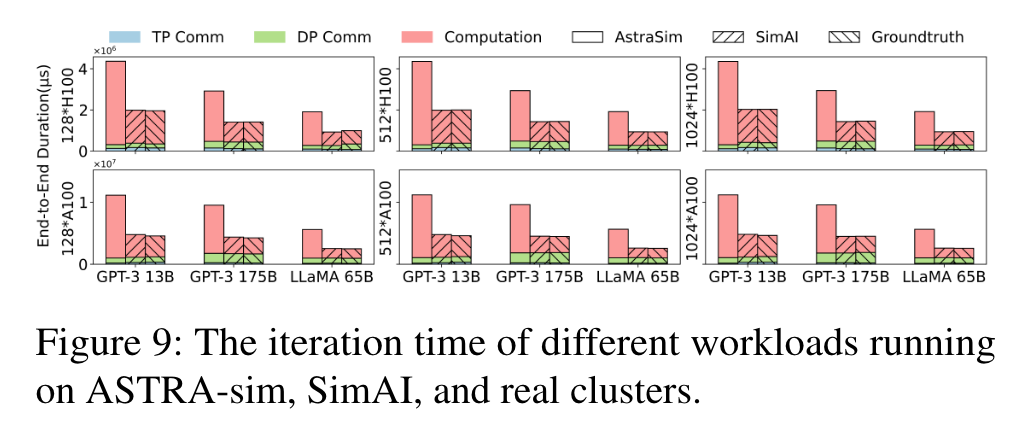
4 端到端模拟精确度
贡献
- 指导了对新GPU的主机设计。对于新的GPU,给出了带宽大小实现最小化开销,最大化H100利用率
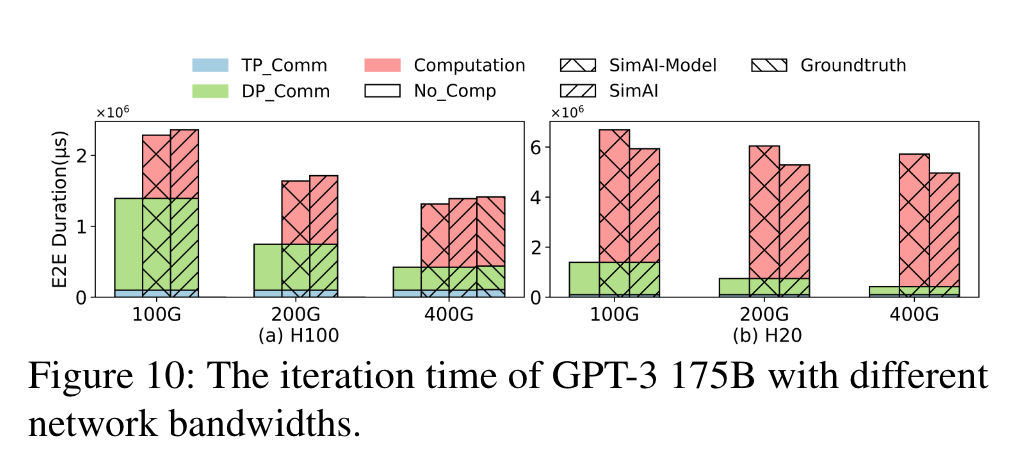
- 量化了GPU和张量并行中张量大小扩展后带来的增益
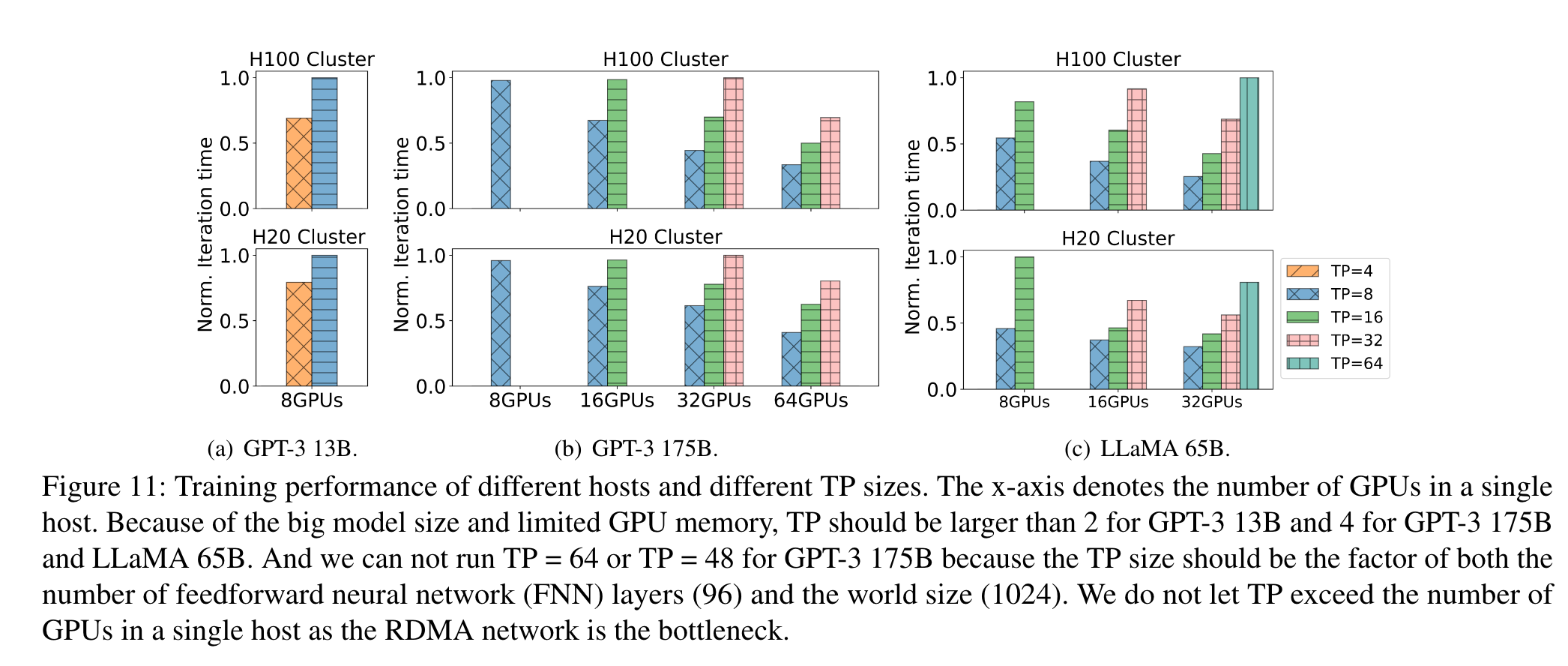
实验过程
- 从头开始保持精确度。从打算重建megatron/deepseed的工作流转变到在单一主机上模拟工作流。
- 提升运算模拟精确度。通过关注影响LLM训练情况的重要子模块入手衡量时间,分裂子模块运算成核运算并且分类,来估计操作时间在不同GPU上的表现。
- 提升集合通信时间。模拟NCCL通信行为来提升ASTRA模拟精度。
- 提升整体时间。多线程/无锁。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库