

用python来爬取某鱼的商品信息(2/2)
目录
1|0上一篇文章
2|0本章内容
主要讲的是上一章的代码实现

导入所需要的程序包
3|0设置浏览器为运行结束后不关闭(可选)
之后先设置自己想要搜索的内容,并且把浏览器设置为允许结束后不关闭,并且打开要爬取的咸鱼网站(可设可不设)
3|1定位到搜索框的xpath地址
4|0执行动作
执行动作(调用鼠标api点击刚刚定位的搜索框,然后输入input_1的值并且回车
中间的.pause(1)以及time.sleep(1)是等待一秒钟的时间(保险起见,怕网页没有加载好,或者你设置一个selenium等待函数更保险)
5|0获取cookie
接下来就是获取cookie,获取cookie方法上一章讲了

在你的浏览器上,下载cookie editor插件登录,不要用运行python时跳出的浏览器,正常打开浏览器(这样不会跳验证码。。。即使跳了也可以手动成功过),导出你的cookie
5|1保存为json文件
然后新建一个json格式的文件并且把它命名为cookie.json
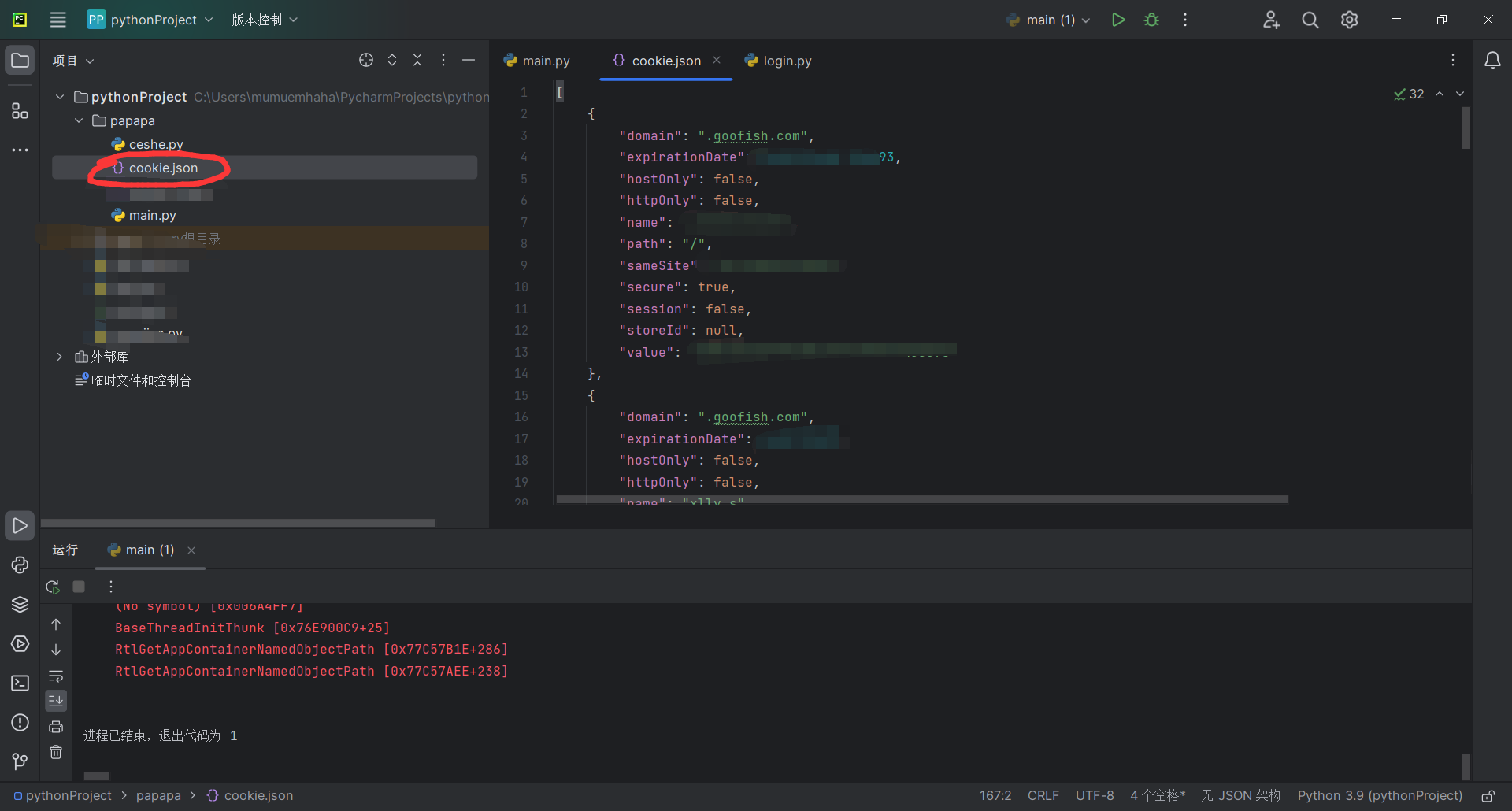
6|0修改cookie的sameSite值并且导入cookie
6|1导入cookie(出错)
但是!!!!
前面讲过直接导入会报错
由于这里语法规定sameSite必须为‘Strict‘, ‘Lax‘两个之一,不然就报错
所以我们要遍历字典,并且把字典中的sameSite设置为Strict
6|2导入cookie(修改后)
所以代码改为
注意,导入cookie后要用driver.refresh()刷新
7|0打印源代码
然后打印网页的源代码,注意要等3秒加载元素(或者用re库带的筛选,筛选你想要的的元素,比如商品链接,价格,以及介绍)
8|0最后出现页面

9|0需要注意的问题
- 首先要说的是这个通过python不如通过app抓包来的稳定
- 页面中你登录的cookie的失效时间是不确定的,所以你可能需要经常更新cookie(看个人情况)
- 无法频繁(比如5分钟一次)搜索,否则会跳滑块验证,或者你有多个账号也可以搞(大概也就这个流程)
- 写出来的代码只是提取出来网页源代码——其实都提取出网页源代码了,使用就只有一个筛选了(csdn上有大把的优质博主和大佬教你通过源代码过滤有用的信息)
- 当然如果需要的话我可以再水一篇博客

- 它理论上可以关联到钉钉机器人或者是QQ机器人上实现定时推送咸鱼信息(啊?你问我为什么不继续写?因为还没学,不然这期标题末尾就不是(2/2)而是(2/3)了;咳咳咳...u1s1,钉钉应该是有教程教的,傻妞机器人应该也可以执行python脚本的,
“按理”来说不会很难实现,实在不行我再去学吧(累die...)
10|0所有代码
所有代码附上吧
11|0总结
这些代码搞得我晕头转向的,尤其是那个内嵌的登录页面让我走了很多弯路,但是对于这个库的学习应该也算是初窥门径吧,如果有大佬有优化的地方欢迎指出(真的没学多深,很容易出错的)
__EOF__

本文作者:xxxx
本文链接:https://www.cnblogs.com/mumuemhaha/p/17710176.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/mumuemhaha/p/17710176.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通