

python之pd.DataFrame函数使用
原文链接:https://blog.csdn.net/linchunmian/article/details/80293251
在使用 pandas 的 DataFrame 方法时碰到的一个错误 ValueError: If using all scalar values, you must pass an index。
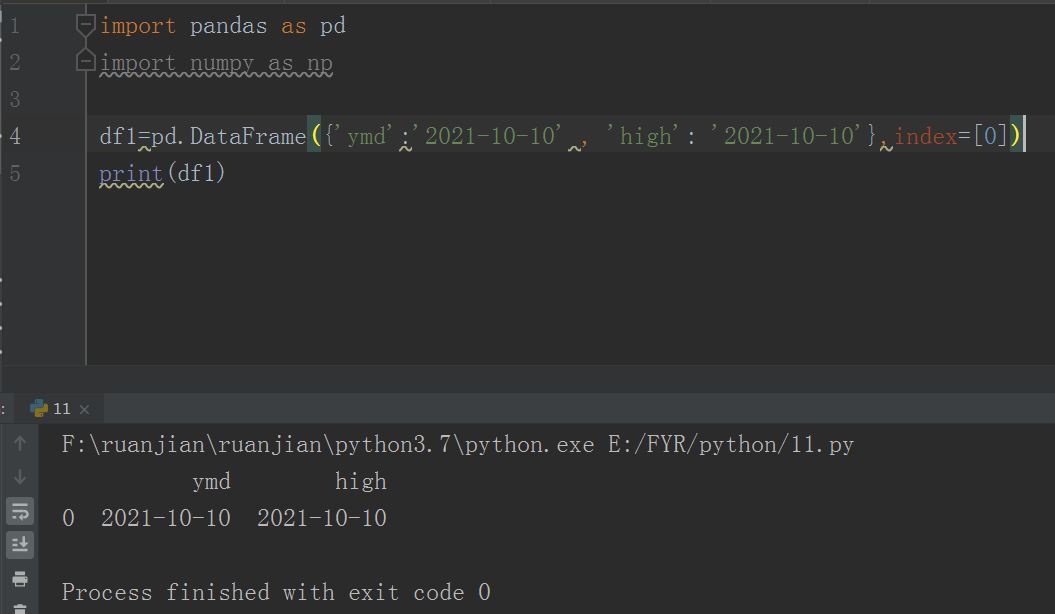
这是因为 pandas 的 DataFrame 方法需要传入一个可迭代的对象(列表,元组,字典等), 或者给 DataFrame 指定 index 参数就可以解决这个问题。如下: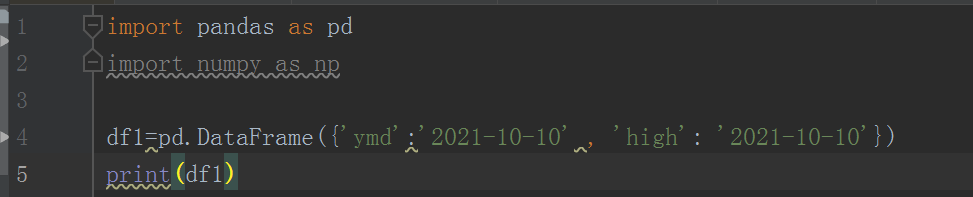

解决办法:

一、关于DataFrame 的介绍
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表;DataFrame的单元格可以存放数值、字符串等,这和excel表很像,同时DataFrame可以设置列名columns与行名index。
二、创建DataFrame
1.1函数创建
pandas常与numpy库一起使用,所以通常会一起引用
1 2 3 4 5 6 7 8 9 10 | import pandas as pdimport numpy as npdf1 = pd.DataFrame(np.random.randn(3, 3), index=list('abc'), columns=list('ABC'))print(df1) A B Ca 0.261756 1.955353 -0.412198b 0.689325 0.177569 -1.530981c -0.149398 -2.810199 -0.621954 |
1.2直接创建
1 2 3 4 5 6 7 8 9 10 | df4 = pd.DataFrame([[1, 2, 3], [2, 3, 4], [3, 4, 5]], index=list('abc'), columns=list('ABC'))print(df4)# A B C# a 1 2 3# b 2 3 4# c 3 4 5 |
1.3字典创建
1 2 3 4 5 6 7 8 9 10 11 12 13 | dic1 = { 'name': [ '张三', '李四', '王二麻子', '小淘气'], 'age': [ 37, 30, 50, 16], 'gender': [ '男', '男', '男', '女']}df5 = pd.DataFrame(dic1)print(df5) name age gender0 张三 37 男1 李四 30 男2 王二麻子 50 男3 小淘气 16 女 |
二、DataFrame属性
2.1 查看列的数据类型
1 2 3 4 5 6 | print(df5.dtypes)# age int64# gender object# name object# dtype: object |
2.2 查看DataFrame的头尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | 使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。 使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。 比如看前5行。import pandas as pdimport numpy as npdf6 = pd.DataFrame(np.arange(36).reshape(6, 6), index=list('abcdef'), columns=list('ABCDEF'))print(df6)# A B C D E F# a 0 1 2 3 4 5# b 6 7 8 9 10 11# c 12 13 14 15 16 17# d 18 19 20 21 22 23# e 24 25 26 27 28 29# f 30 31 32 33 34 35print(df6.head())# A B C D E F# a 0 1 2 3 4 5# b 6 7 8 9 10 11# c 12 13 14 15 16 17# d 18 19 20 21 22 23# e 24 25 26 27 28 29 |
比如只看前2行
1 2 3 4 5 | print(df6.head(2))# A B C D E F# a 0 1 2 3 4 5# b 6 7 8 9 10 11 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 比如看后5行。print(df6.tail())# A B C D E F# b 6 7 8 9 10 11# c 12 13 14 15 16 17# d 18 19 20 21 22 23# e 24 25 26 27 28 29# f 30 31 32 33 34 35比如只看后2行。print(df6.tail(2))# A B C D E F# e 24 25 26 27 28 29# f 30 31 32 33 34 35 |
2.3 查看行名与列名
1 2 3 4 5 | print(df6.index)print(df6.columns)# Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')# Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') |
2.4 查看数据值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 使用values可以查看DataFrame里的数据值,返回的是一个数组。print(df6.values)# [[ 0 1 2 3 4 5]# [ 6 7 8 9 10 11]# [12 13 14 15 16 17]# [18 19 20 21 22 23]# [24 25 26 27 28 29]# [30 31 32 33 34 35]]比如说查看某一列所有的数据值。print(df6['B'].values)[ 1 7 13 19 25 31] |
2.5 查看行列数
1 2 3 4 5 6 | 使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数print(df6.shape[0])print(df6.shape[1])# 6# 6 |
2.6 切片与索引
1 2 3 4 5 6 | 使用冒号进行切片print(df6['a':'b'])# A B C D E F# a 0 1 2 3 4 5# b 6 7 8 9 10 11 |
1 2 3 4 5 6 7 8 9 10 11 12 | <br>print(df6.loc[:,'A':'B'])# A B# a 0 1# b 6 7# c 12 13# d 18 19# e 24 25# f 30 31#切片表示的是行切片#索引表示的是列索引 |
3 DataFrame操作
3.1 转置
1 2 3 4 5 6 7 8 9 | print(df6.T)# a b c d e f# A 0 6 12 18 24 30# B 1 7 13 19 25 31# C 2 8 14 20 26 32# D 3 9 15 21 27 33# E 4 10 16 22 28 34# F 5 11 17 23 29 35 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现