
AI学习笔记:特征工程

一、概述
-
Andrew Ng:Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering( 吴恩达, 人工智能和机器学习领域国际最权威学者之一:提取特征是困难的,耗时的,需要丰富的专家知识。“应用机器学习”从根本上来说就是特征工程)
-
业界广泛流传:数据和特征决定了机器学习的上限, 而模型和算法只是逼近这个上限而已。
-
特征工程:Feature Engineering,指使用专业背景知识和技巧进行数据处理,使得特征能够在机器学习算法上发挥更好的作用。特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
特征工程主要包含三部分内容
- 特征提取:包含字典特征提取、文档特征提取、图像特征提取(深度学习)等
- 特征预处理:对数据进行无量纲化处理:标准化、归一化等。无量纲化方法有很多,但是从几何角度来说可以分为:直线型、折线型、曲线形无量纲化方法。
- 特征降维:包含特征选择,PCI(主要内容分析)、PCA(线性判别分析法),PCA( 主成分分析法)等
二、数据的基本描述
2.1 定义
- 数据:data,指事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的原始素材。
- 属性:attribute,是一个数据字段,表述数据对象的一个特征。
- 特征向量:用来描述一个给定对象的一组属性。
2.2 数据的基本属性:
包括标称属性、二元属性、序数属性、数值属性、连续/离散属性等等。
- 标称属性:一些符号或事物的名称,每种值代表某种类别、编码或状态。比如颜色、职业等。标称值不具有有意义的顺序,且不是定量的。
- 二元属性:布尔属性,比如0/1、true/false。通常1表示对结果重要的 。
- 序数属性:具有意义的顺序或排序等级,但是相继值之间的差是未知的。比如size(大、中、小), 客户价值(高、中、低) 。序数也可能是通过将数值量的值域划分有限个有序类别,把数值属性离散化后得到的。
- 数值属性:略
- 离散/连续属性:机器学习的分类算法通常把属性分成离散的或连续的,每种类型都可以用不同的方法处理。离散属性具有有限或无限个值 如果属性不离散,则它是连续的。在实际应用中,连续属性一般用浮点(float)变量表示 。
补充说明:标称、二元和序数属性都是定性的,不是定量的,即它们能够描述对象的特征,而不能给出实际大小或数量。
三、数据型特征处理
3.1 归一化
归一化可以使不同维度的数据在点乘和核函数计算相似性时拥有统一的标准, 数学上就是把每整个向量转化为“单位向量”。
常用的方法:
-
min-max标准化(Min-Max Normalization)

公式解释:(当前数据-最小数据)/(最大值-最小值)。
不难发现,x1每列的值都在[0,1]之间,也就是说,该模块是按列计算的。并且MinMaxScaler在构造类对象的时候也可以直接指定最大最小值的范围:scaler = MinMaxScaler(feature_range=(min, max)). -
Z-score标准化方法
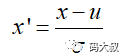
公式解释:(原始数据-样本均值)/样本标准差。
可以看出,z-score标准化方法试图将原始数据集标准化成均值为0,方差为1且接近于标准正态分布的数据集。然而,一旦原始数据的分布 不 接近于一般正态分布,则标准化的效果会不好。该方法比较适合数据量大的场景(即样本足够多,现在都流行大数据,因此可以比较放心地用)。此外,相对于min-max归一化方法,该方法不仅能够去除量纲,还能够把所有维度的变量一视同仁(因为每个维度都服从均值为0、方差1的正态分布),在最后计算距离时各个维度数据发挥了相同的作用,避免了不同量纲的选取对距离计算产生的巨大影响。所以,涉及到计算点与点之间的距离,如利用距离度量来计算相似度、PCA、LDA,聚类分析等,并且数据量大(近似正态分布),可考虑该方法。相反地,如果想保留原始数据中由标准差所反映的潜在权重关系应该选择min-max归一化。
3.2 离散化
有些场合,比如广告点击率预测, 最适合用线性分类器来分类预测, 但是采集到的Y和X是非线性的关系, 因此需要对X做离散化, 使离散化后的单值X变成一个向量, 进一步训练这个向量和Y之间的线性模型。离散化有利于分类模型的训练。
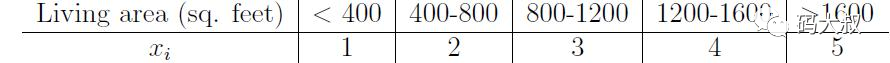
四、类别型特征处理
别特征特征指的是能在有限范围内取值的特征,如性别(男,女),血型(A,B,O,AB)等。类别特征的输入往往是原始的字符串,因此除了例如决策树等少数能直接处理字符串形式输入的模型,其他模型往往需要将类别特征处理成数值型才能正常处理。几种常见的类别特征处理方法:
4.1、序号编码(Ordinal Encoding)
序号编码通常用于处理类别具有大小或顺序关系的数据,例如成绩可以分为“高”,“中”,“低”,且“高>中>低”,因此可以相应的转换成3,2,1。
4.2、独热编码(One-hot Encoding)
One-hot 编码通常用于处理类别不具有大小关系的类别特征,最常见的用法是NLP中对词库中单词的编码。例如对于血型(A,B,O,AB),对应的One-hot编码可以表示为((1000),(0100),(0010),(0001))。但是使用One-hot编码需要注意以下问题:
- 使用稀疏向量节省空间。对于范围特别大的常见,例如字典,生产的one-hot编码非常稀疏,因此需要节省存储空间。
- 配合特征选择来降低特征维度。同样是为了解决高维情况下的存储问题。
4.3、二进制编码(Binary Encoding)
二进制编码主要分为两步,先用序号编码给每个类别赋予一个唯一的ID,然后将该ID对应的二进制编码作为结果。同样以血型(A,B,O,AB)为例,其对应的序号编码为(1,2,3,4),那么其对应的二进制棉麻可以表示为(001,010,011,100)。相比较One-hot编码,在高维特征的情况下,能节省大量的存储空间。
五、日期型特征处理
问题:比如日期时间 (比如2014-09-20 20:45:40), 如何转化成有用的特征?
-
场景1:如果你想知道某一天的时间段跟其它属性的关系, 你可以创建一个数字特征“Hour_Of_Day”来帮你建立一个回归模型, 或者你可以建立一个序数特征, “Part_Of_Day”,取值“Morning,Midday,Afternoon,Night”来关联你的数据。
-
场景2:研究一个商场的销售额, 时间可以抽取出季节、 月份、 一年第几周等作为新的特征, 进而进行模型训练。
-
场景3:研究星期几对交通压力的影响, 可以采取One-hot方法变成7个变量, 每个代表1天, 周一为(0,1,0,0,0,0,0),周三为(0,0,0,1,0,0,0)等,再进行模型训练。
常见处理方式:
- 时间本身的特征:将时间变量作为类别变量处理
- 时间变量之间的组合特征:根据两个或多个时间变量的含义,进行特征组合
- 时间序列相关特征:滞后特征、滑动窗口统计特征
六、文本型特征处理
问题:垃圾邮件检测时, 如何建立特征?
采用Word2vector方法, 或者TF-IDF的方法, 将所有邮件中出现的单词按词频从高到低排序, 再取前m个(比如5000) 单词叫做词袋, 再将每个邮件中出现的在词袋中的单词次数累计为相应向量位置的数字, 这样对每个邮件都构造了一个m维的一个向量, 作为这个邮件的特征。处理过程中一些技巧比如去掉stopword 如英文的“a”, “the” 汉语“的”, “这”, “是”之类的词。
常用方式如下:
- 词袋法(BOW/TF)
- TF-IDF(Term frequency-inverse document frequency)
- HashTF4、Word2Vec(主要用于单词的相似性考量)
七、组合特征分析
比如进行自动疾病诊断时, 有些疾病带有一些并发症, 或者有几个典型的特征, 如果可以组合成这样的一个典型的发病症状组合特征, 对疾病的诊断会更有把握。
比如:评价一个人在网络课程中的积极性指标,可通过资料完善度、社区活跃度、作业完成率、考核得分率等等方面。
八、基于权重的特征选取
自变量和目标变量之间的关联, 通过分析特征子集内部的特点来衡量其好坏, 然后选择排名靠前的特征, 比如前10%, 或前10个, 或者相关系数大于预设阈值, 从而达到特征选择目的。
本质:筛选器, 侧重于单个特性
评价函数:
Pearson相关系数、Gini-index 基尼系数、IG 信息增益, 互信息、卡方检验、Distance Metrics距离度量
优点:计算时间上较为高效, 对于过拟合问题具有高的鲁棒性。
缺点:倾向于选择冗余的特征;因为不考虑特征之间的相关性, 导致虽然某一个特征分类能力很差, 但是和其他特征组合起来效果不错, 这样的特征被筛选掉了(多重共线性) 。
九、自动特征学习
很多算法工程也在思考,能不能通过模型的方式来自动的学习和构成特征呢?"所有的想法都会有实现的一天",现在市面上有效的特征构造模型有 深度学习(提取训练好的模型中隐层作为特征)可以自己学习出一些特征以及特征之间的组合关系。主题模型 LDA、word2vec来作为特征生成的模型,将模型训练的中间结果,比如 LDA 的主题分布、word2vec 生成的词向量用于LR 这样的线性模型,线上测试效果都非常好。
从场景目标出发,去找出与之有关的因素。但是在实际场景除了天马行空想特征之外,还需要对于想出来的特征做一可行性评估:获取难度、覆盖度、准确度等,比如笛卡尔积会使得特征维度增加的非常快,会出现大量覆盖度低的特征,如果把这些覆盖度低的特征加入到模型中训练,模型会非常不稳定;然而这一系列的工作就是传说中的特征工程比如卷积神经网络。
十、算法选择导图
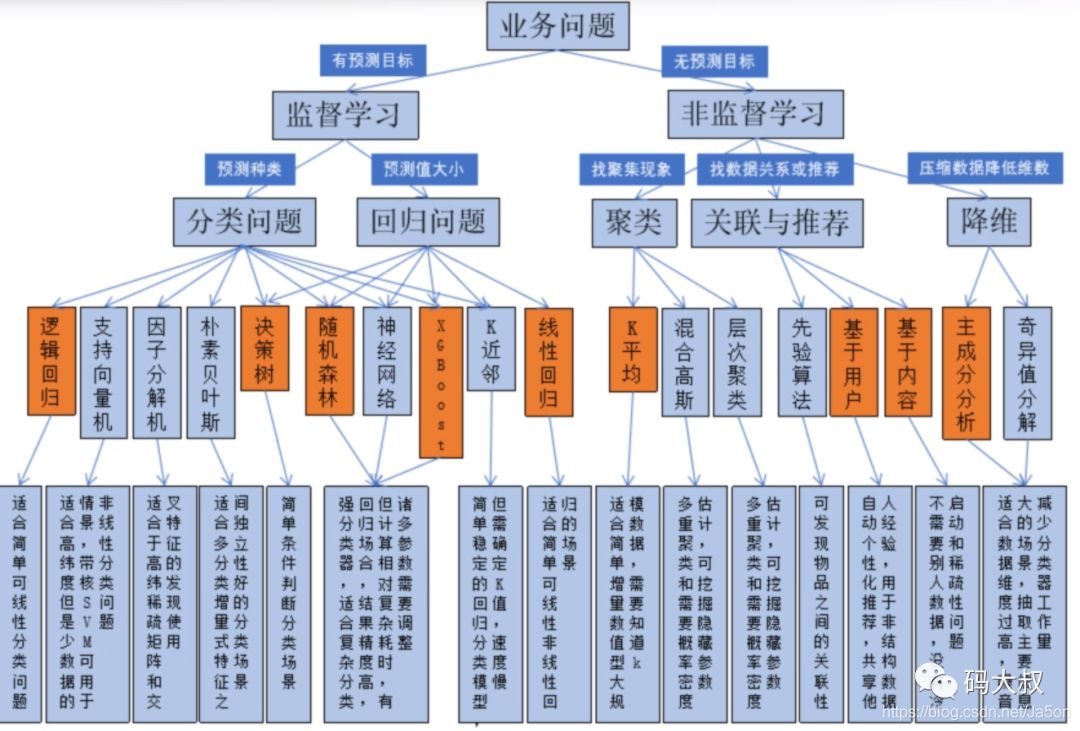
说明:
本文大部分内容来自星环科技AI工程师公开培训视频,版权归星环科技所有。大家也可以直接去观看视频,老师讲的更为详细。
B站直播地址:https://live.bilibili.com/21878856,免费噢(星环科技最近不定时有很多大数据、云计算、人工智能相关的分享)
AI讲师:孙国库 星环科技AI架构师&金牌讲师
其他参考资料:
https://www.jianshu.com/p/7066558bd386
https://www.cnblogs.com/ftl1012/p/10498480.html
https://blog.csdn.net/onthewaygogoing/article/details/79871559
推荐阅读:
AI学习笔记(一):人工智能与机器学习概述
从千万级数据查询来聊一聊索引结构和数据库原理
读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
我成功攻击了Tomcat服务器,大佬们的反应亮了
原创 史上最强的Java堆内缓存框架,不接受反驳(附源码)
微信公众号:“码大叔”,架构师,十年戎“码”,老“叔”开花,我们一起学习交流!


