mysql中主外键关系
一、外键:
- 1、什么是外键
- 2、外键语法
- 3、外键的条件
- 4、添加外键
- 5、删除外键
1、什么是外键:
主键:是唯一标识一条记录,不能有重复的,不允许为空,用来保证数据完整性
外键:是另一表的主键, 外键可以有重复的, 可以是空值,用来和其他表建立联系用的。所以说,如果谈到了外键,一定是至少涉及到两张表。例如下面这两张表:
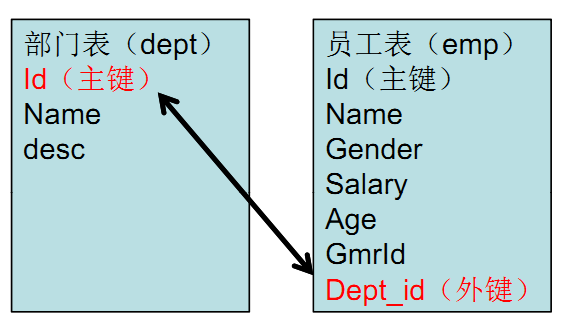
上面有两张表:部门表(dept)、员工表(emp)。Id=Dept_id,而Dept_id就是员工表中的外键:因为员工表中的员工需要知道自己属于哪个部门,就可以通过外键Dept_id找到对应的部门,然后才能找到部门表里的各种字段信息,从而让二者相关联。所以说,外键一定是在从表中创建,从而找到与主表之间的联系;从表负责维护二者之间的关系。
我们先通过如下命令把部门表和职工表创建好,方便后面的举例:

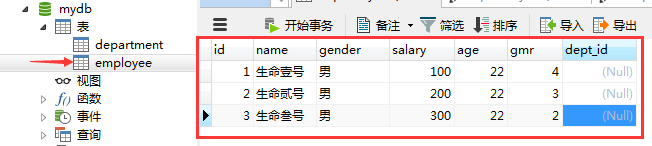
create table department( id int primary key auto_increment, name varchar(20) not null, description varchar(100) ); create table employee( id int primary key auto_increment, name varchar(10) not null, gender varchar(2) not null, salary float(10,2), age int(2), gmr int, dept_id int );然后把两张表的数据填好,显示效果如下:
部门表:

员工表:
2、外键的使用需要满足下列的条件:(这里涉及到了InnoDB的概念)
1. 两张表必须都是InnoDB表,并且它们没有临时表。
注:InnoDB是数据库的引擎。MySQL常见引擎有两种:InnoDB和MyISAM,后者不支持外键。
2. 建立外键关系的对应列必须具有相似的InnoDB内部数据类型。
3. 建立外键关系的对应列必须建立了索引。
4. 假如显式的给出了CONSTRAINT symbol,那symbol在数据库中必须是唯一的。假如没有显式的给出,InnoDB会自动的创建。
面试题:你的数据库用什么存储引擎?区别是?
答案:常见的有MyISAM和InnoDB。
MyISAM:不支持外键约束。不支持事务。对数据大批量导入时,它会边插入数据边建索引,所以为了提高执行效率,应该先禁用索引,在完全导入后再开启索引。
InnoDB:支持外键约束,支持事务。对索引都是单独处理的,无需引用索引。
3、添加外键的语法:
有两种方式:
- 方式一:在创建表的时候进行添加
- 方式二:表已经创建好了,继续修改表的结构来添加外键
【方式一】在创建表的时候进行添加
[CONSTRAINT symbol] FOREIGN KEY [id] (从表的字段1) REFERENCES tbl_name (主表的字段2) [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION}] [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION} 上面的代码是同一行,中括号里的内容是可选项。
解释如下:
CONSTRAINT symbol:可以给这个外键约束起一个名字,有了名字,以后找到它就很方便了。如果不加此参数的话,系统会自动分配一个名字。
FOREIGN KEY:将从表中的字段1作为外键的字段。
REFERENCES:映射到主表的字段2。
ON DELETE后面的四个参数:代表的是当删除主表的记录时,所做的约定。
- RESTRICT(限制):如果你想删除的那个主表,它的下面有对应从表的记录,此主表将无法删除。
- CASCADE(级联):如果主表的记录删掉,则从表中相关联的记录都将被删掉。
- SET NULL:将外键设置为空。
- NO ACTION:什么都不做。
注:一般是RESTRICT和CASCADE用的最多。
【方式二】表已经创建好了,继续修改表的结构来添加外键。
我们在第一段中内容中已经将表建好了,数据也填充完了,现在来给从表(员工表)添加外键,让它与主表(部门表)相关联。代码举例如下:
ALTER TABLE employee ADD FOREIGN KEY(dept_id) REFERENCES department(id); 代码解释:
ALTER TABLE employee:在从表employee中进行操作;
ADD FOREIGN KEY(dept_id):将从表的字段dept_id添加为外键;
REFERENCES department(id):映射到主表department当中为id的字段。
运行上方代码后,我们通过navicat来看一下外键有没有添加成功:
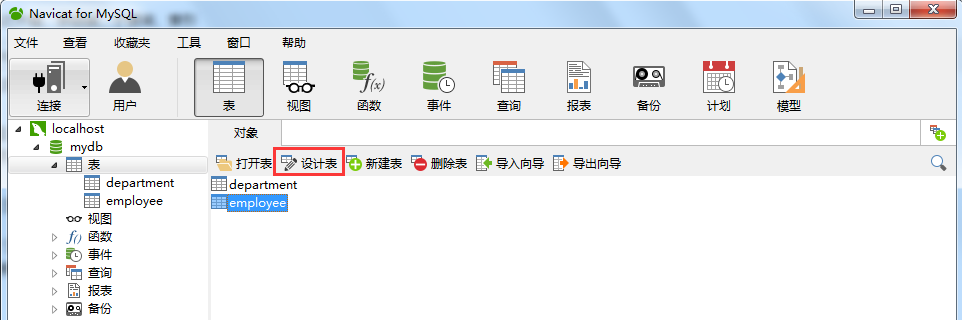
上图中,选中表employee,单击红框部分的“设计表”按钮,界面如下:
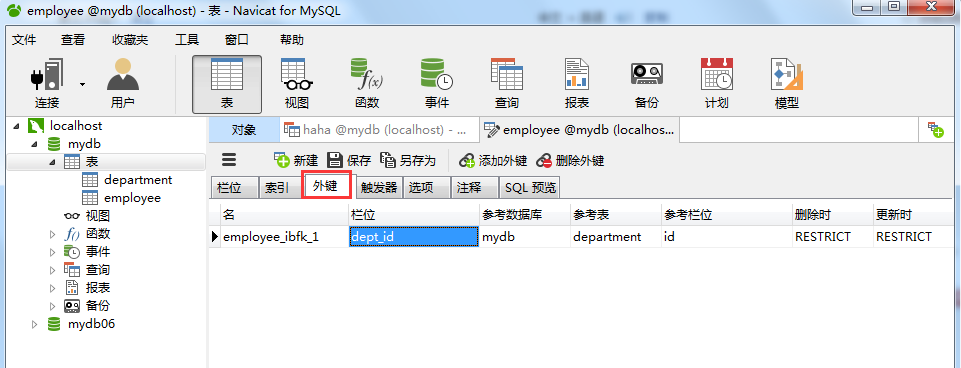
上图中就可以看到我们新建的外键了,而且系统默认给这个外键起了个名字:employee_ibfk_1。默认规则是RESTRICT。紧接着来给外键设置值:
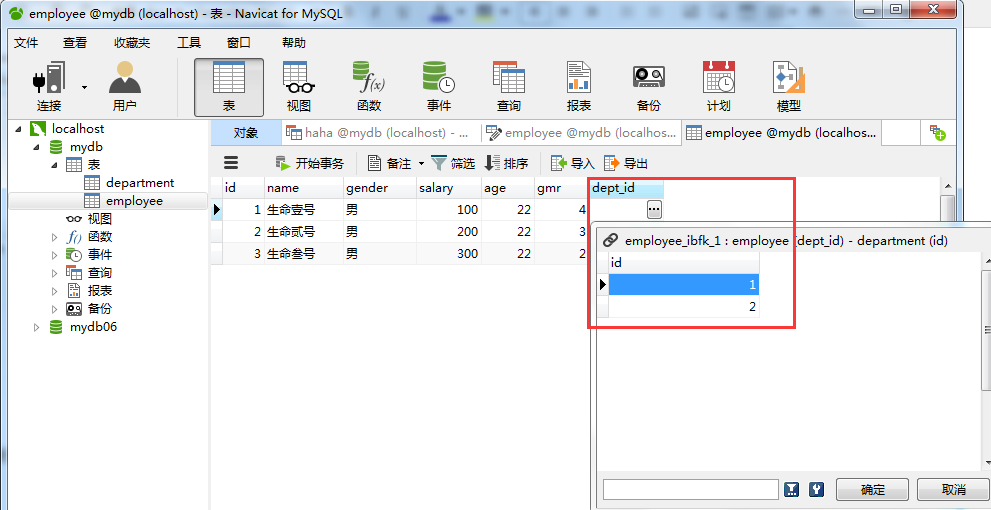
上图中,我们打开员工表,然后给外键设置值,1代表宣传部,2代表秘书部。
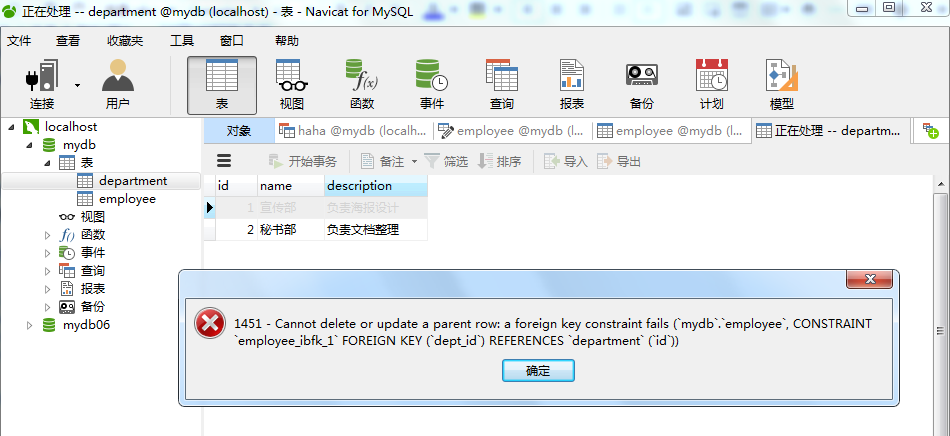
然后我们回到主表(部门表),此时如果想删除id为1的宣传部,会弹出如下提示:(因为外键的默认规则为RESTRICT)
4、删除外键:(通过sql语句的方式)
我们在navicat中可以通过图形界面的方式删除外键,也可以通过sql语句来删除。
(1)获取外键名:
如果在命令行中不知道外键的名字,可以通过查看表的定义找出外键的名称:
show create table emp;运行效果如下:
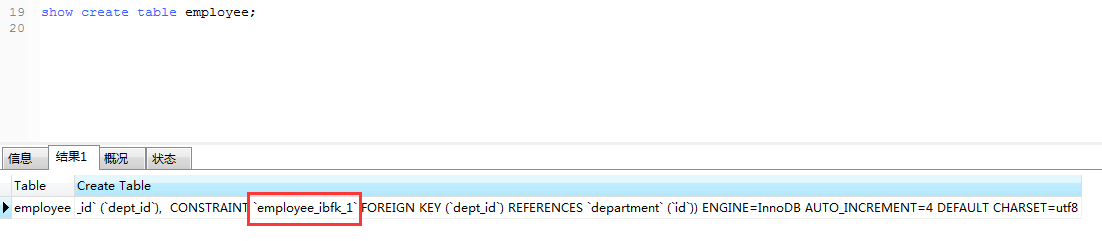
其实我们在表的信息中也可以看到:(注意书写命令的格式)

(2)删除外键:
alter table emp drop foreign key 外键名;
二、表连接(join)
我们以下面的两张表举例:作为本段内容的例子
department部门表:
employee员工表:

其中,外键对应关系为:employee.dept_id=department.id。employee.leader中的数字的含义为:生命壹号的leader是生命二号,生命二号没有leader,生命叁号的leader是生命壹号。
1、内连接:只列出匹配的记录
语法:
SELECT … FROM join_table [INNER] JOIN join_table2 [ON join_condition] WHERE where_definition解释:只列出这些连接表中与连接条件相匹配的数据行。INNER可以不写,则默认为内连接。[ON join_condition]里面写的是连接的条件。
举例:
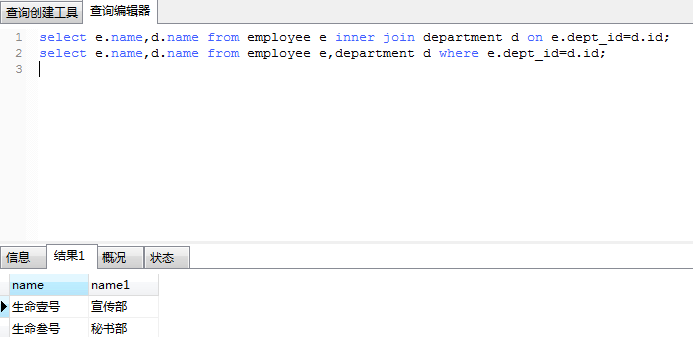
select e.name,d.name from employee e inner join department d on e.dept_id=d.id; 等价于:
select e.name,d.name from employee e,department d where e.dept_id=d.id; 运行效果:
2、外连接:
外连接分类:
- 左外连接(LEFT [OUTER] JOIN)
- 右外连接(RIGHT [OUTER] JOIN)
- 全外连接(FULL [OUTER] JOIN) 注:MySQL5.1的版本暂不支持
语法:
SELECT … FROM join_table1 (LEFT | RIGHT | FULL) [OUTER] JOIN join_table2 ON join_condition WHERE where_definition 解释:
不仅列出与连接条件(on)相匹配的行,还列出左表table1(左外连接)、或右表table2(右外连接)、或两个表(全外连接)中所有符合WHERE过滤条件的数据行。一般都是用左连接或者外连接。
其中,[OUTER]部分可以不写,(LEFT | RIGHT | FULL)部分要写其中一个。
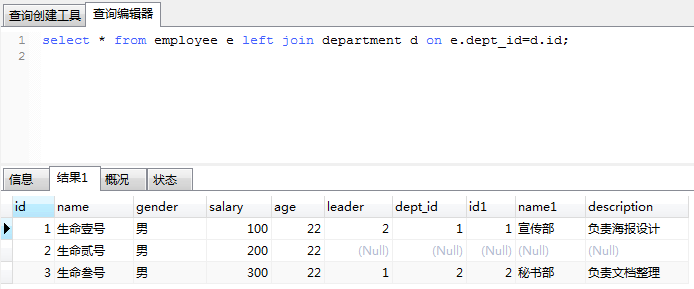
2、1左外连接:左表列出全部,右表只列出匹配的记录。
举例:
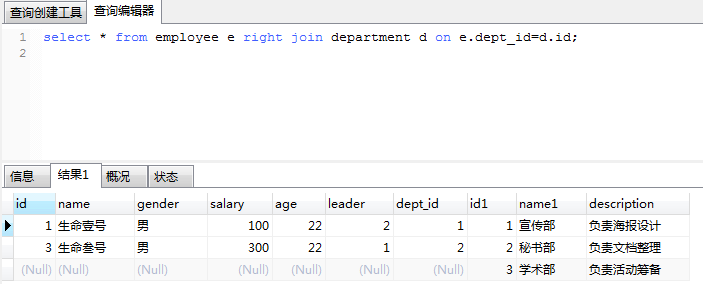
2、2右外连接:右表列出全部,左表只列出匹配的记录。
举例:
3、交叉连接:
语法:
SELECT … FROM join_table1 CROSS JOIN join_table2; 没有ON子句和WHERE子句,它返回的是连接表中所有数据行的笛卡尔积。
笛卡尔积举例:假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}
其结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
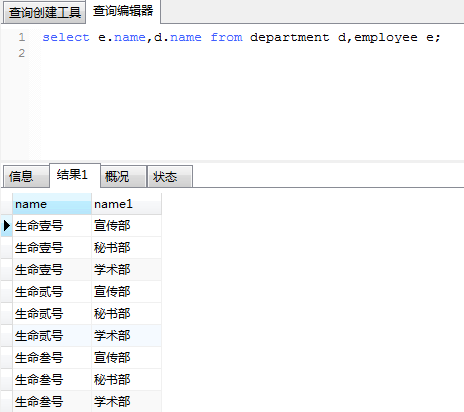
等价于:(荐)
SELECT … FROM table1, table2; 举例:
4、自连接:参与连接的表都是同一张表。(通过给表取别名虚拟出两张表)
注:非常重要,在JavaWeb中的目录树中用的特别多。
举例:查询出员工姓名和其leader的姓名(类似于求节点及其父节点)
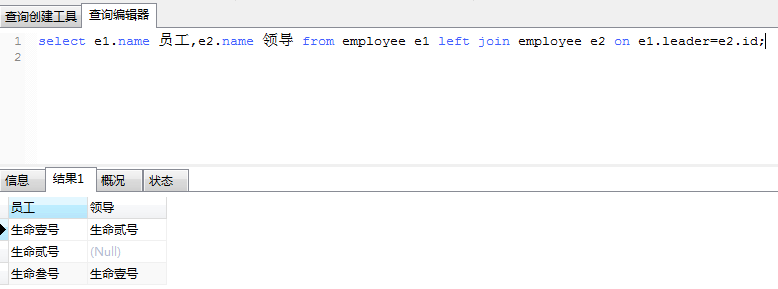
我们来详细解释一下上面的代码。对于同一张employee表,我们把e1作为员工表,e2作为领导表。首先把全部的员工列出来(基于左外连接),然后找到我们所需要的条件:员工的经理id(e1.leader)等于经理表的id(e2.id)。
举例:查询出所有leader的姓名。
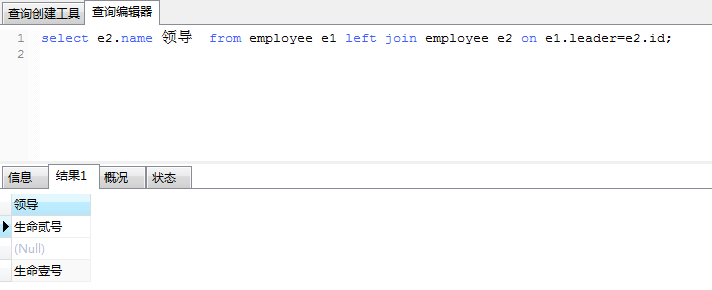
分析的道理同上。
其实,上面的两个查询结果都是下面这个查询结果的一部分:
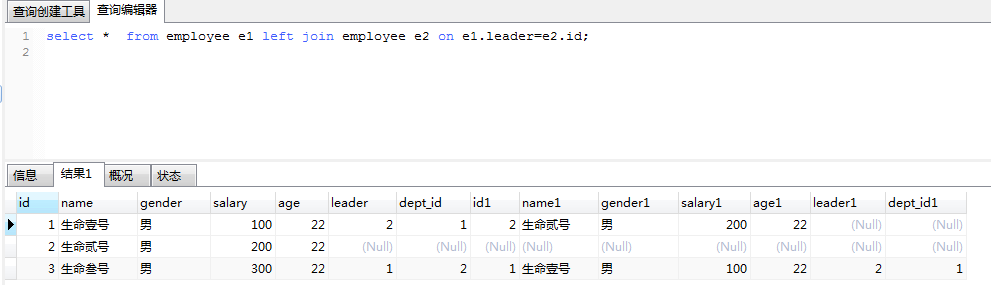
三、子查询:
作用:某些情况下,当进行查询的时候,需要的条件是另外一个select 语句的结果,这个时候,就要用到子查询。
定义:为了给主查询(外部查询)提供数据而首先执行的查询(内部查询)被叫做子查询。也就是说,先执行子查询,根据子查询的结果,再执行主查询。
关键字:用于子查询的关键字主要包括 IN、NOT IN、EXIST、NOT EXIST、=、<>等(符号“<>”的意思是:不等于)。
备注:MySQL从4.1开始才支持SQL的子查询。一般说子查询的效率低于连接查询(因为子查询至少需要查询两次,即至少两个select语句。子查询嵌套也多,性能越低)。表连接都可以用子查询替换,但反过来说却不一定。
我们一下面的这张员工表举例:
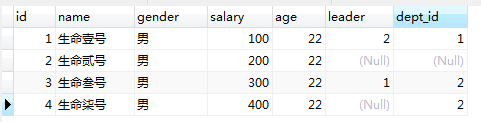
1、举例:查询月薪最高的员工的名字
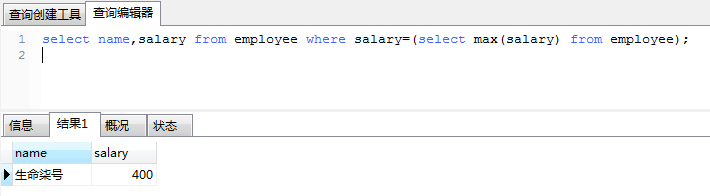
上面的例子中,我们就是先通过聚合函数查出最高的月薪,然后根据这个值查出对应员工的名字。
2、举例:查询出每个部门的平均月薪
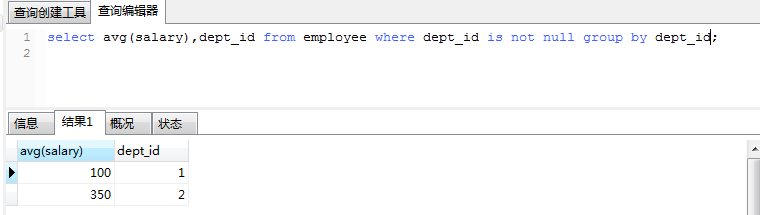
上面的例子中,先将部门进行分类(前提是部门不能为空),然后分别单独求出各类中的薪水平均值。
注:这里我们没有用到子查询,因为比较麻烦。
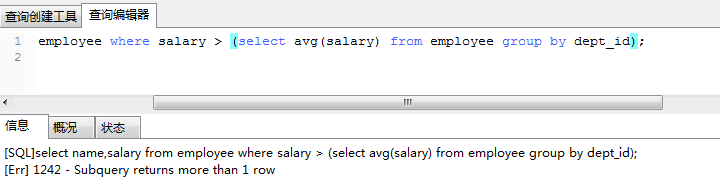
3、举例:查询月薪比平均月薪高的员工的名字(我们知道,整体的平均工资是250)

疑问:如果要查询比部门平均工资高的员工,该怎么写呢?下面的这种写法是错误的:
四、索引
主要内容如下:
- 1、索引的概念
- 2、普通索引
- 3、唯一索引
- 4、主键索引
- 5、全文索引
- 6、删除、禁用索引
- 7、设计索引的原则
关于索引,推荐的学习链接:
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html(大牛)
http://blog.csdn.net/cuidiwhere/article/details/8452997
http://www.cnblogs.com/cq-home/p/3482101.html
1、索引的概念:
索引是数据库中用来提高查询性能的最常用工具。
所有MySQL列类型都可以被索引,对相关列使用索引是提高SELECT操作性能的最佳途径。索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存。
在使用以下操作符时,都会用到相关列上的索引:
- >、<、>=、<=、<>、IN、 BETWEEN
- LIKE 'pattern'(pattern不能以通配符开始,即通配符不能放前面,即使放在了前面,索引也无效)
注:索引的值因为不断改变,所以是它需要维护的。如果数据量较少,建议不用索引。
2、normal普通索引(第一种索引)
- 方式一:直接创建索引:
语法:
CREATE INDEX 索引名 ON 表名(列名[(length)]…); 举例:
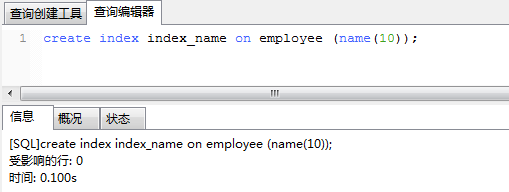
然后,我们在表中可以看到新创建的索引:(我们可以在这个navicat的可视化界面中修改索引类型)
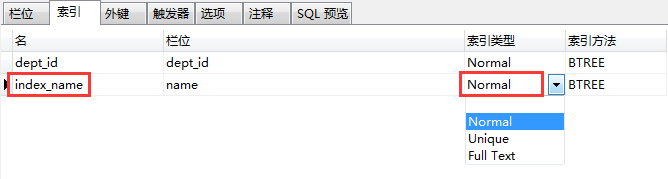
- 方式二:修改表时添加索引
语法:
ALTER TABLE 表名 ADD INDEX [索引名] (列名[(length)]…);
- 方式三:创建表的时候指定索引:
CREATE TABLE 表名 ( 表名 ( [...], INDEX [索引名] (列名[(length)]…); 注意:如果要创建索引的列的类型是CHAR、VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定length。
3、unique 唯一索引:(第二种索引)
这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都必须唯一。例如可以将身份证号作为索引。
创建方式和上方的普通索引类似。即:将普通索引的“index”改为“unique index”。
4、主键索引(一种特殊的唯一索引)
主键是一种特殊的唯一索引,一般在创建表的时候指定。在 MYSQL 中,当你建立主键时,主键索引同时也已经建立起来了,不必重复设置。
记住:一个表只能有一个主键,也即只有一个主键索引。
5、FULLTEXT全文索引:(第三种索引)
MySQL从3.2版开始支持全文索引和全文检索。在MySQL中,全文索引的索引类型为FULLTEXT。
MySQL5.0版本只有MyISAM存储引擎支持FULLTEXT,并且只限于CHAR、VARCHAR和TEXT类型的列上创建。
注:全文索引维护起来很吃力,所以了解即可。
创建方式和上方的普通索引类似。即:将普通索引的“index”改为“fulltext index”。
6、删除、禁用索引:
一般使用“删除”,不使用“禁用”。
删除索引:
语法:
DROP INDEX 索引名 ON 表名 对于MyISAM表在做数据大批量导入时,它会边插入数据边建索引。所以为了提高执行效率,应该先禁用索引,在完全导入后,再开启索引。而InnoDB表对索引都是单独处理的,无需禁用索引。
禁用索引:
ALTER TABLE 表名 DISABLE KEYS; 打开索引:
ALTER TABLE 表名 ENABLE KEYS;
7、设计索引的原则:
- 最适合索引的列是出现在WHERE子句中的列,或连接子句(on语句)中指定的列,而不是出现在SELECT后的列。
- 索引列的值中,不相同的数目越多,索引的效果越好。
- 使用短索引:对于CHAR和VARCHAR列,只用它的一部分来创建索引,可以节省索引空间,也会使查询更快捷。
如:CREATE INDEX part_of_name ON employees(name(10)); 这个句子中指定的length长度为10,就是使用短索引,也就是说取name的前十个字符。
- 利用最左前缀。
- 根据搜索的关键字建立多列索引。
- 不要过度索引。维护索引需要成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号