知识扩展--if...else...与switch...case...的执行原理
一、简述
编程语言中的条件分支结构有两种:if-else和switch-case,这两种条件分支之间可以相互转换,但是也存在一些区别,那么什么时候该用if-else,什么时候该用switch-case呢?这就需要我们去了解它们之间的练习和区别了。
1.1 if...else...简述
if-else的基本知识点包含4点:
- 单独if语句:单分支结构,简单的一个控制语句,如果满足条件则做对应的操作,否则不做。
if( 条件 ) { 条件成立时执行的代码 }
- if-else语句:双分支结构,这两个分支场景一定是相互对立,非此即彼的两种场景。
if( 条件 ) { 条件成立时执行的代码 } else { 条件失败时执行的代码 }
- if-else-if语句:多分支结构,这多个分支最多只会执行一个分支的操作,而且执行过程是从上到下依次判断,一旦某个条件满足,执行对应的操作后就不会继续执行后面的条件判断了。
if ( 条件1 ) { 代码块1 } else if ( 条件2 ) { //在条件 1 不满足的情况下,才会进行条件 2 的判断 代码块2 } else if ( 条件3 ) { 代码块3 } else { //当前面的条件均不成立时,才会执行 else 块内的代码。 代码块N }
- if嵌套:每一对大括号对应的语句块中都可以进行任何流程控制,所以任何的if语句块、else语句块中都可以继续进行if-else的分支结构。但是只有当外层 if 的条件成立时,才会判断内层 if 的条件。
//只有当外层 if 的条件成立时,才会判断内层 if 的条件。 if(条件1){ if(条件2){ 代码块1 }else{ 代码块2 } }else{ 代码块3 }
1.2 switch...case...简述
switch ( 常量表达式 ){ case 常量1 :语句; case 常量2 :语句; case 常量3 :语句; ... case 常量n:语句; default :语句; }
- switch后面小括号中常量表达式的值必须是整型或字符型(不同的编程语言规定不一样,Java除了整数之外还可以是枚举和字符串,PHP还可以是浮点数)
- case后面的值可以是常量数值,如1、2;也可以是一个常量表达式,如2+2;但不能是变量或带有变量的表达式,如a*2。
- break的用法:case匹配后,执行匹配块里的程序代码,如果没有遇见break会继续执行下一个case块的内容,直到遇到break语句或这switch语句块结束
二、执行原理分析
这里转载自文章:if和switch的原理
感兴趣的同学还可以查看一下:If-else 三目运算符 底层实现 效率差异
2.1 if...else...执行原理
在编程语言中,不管是那种编程语言,if和switch都是是条件分支的重要组成部分。if的功能是计算判断条件的值,根据返回的值的不同来决定跳转到哪个部分。值为真则跳转到if语句块中,否则跳过if语句块。下面来分析一个简单的if实例:
if(argc > 0) { printf("argc > 0\n"); } if (argc <= 0) { printf("argc <= 0\n"); } printf("argc = %d\n", argc);
//上述代码对应的汇编代码如下 9: if(argc > 0) cmp dword ptr [ebp+8],0 0040102C jle main+2Bh (0040103b) ;argc <= 0就跳转到下一个if处 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (0042003c) call printf (00401090) add esp,4 12: } 13: if (argc <= 0) ;argc > 0跳转到后面的printf语句输出argc的值 0040103B cmp dword ptr [ebp+8],0 0040103F jg main+3Eh (0040104e) 14: { 15: printf("argc <= 0\n"); push offset string "argc <= 0\n" (0042002c) call printf (00401090) 0040104B add esp,4 16: } 17: printf("argc = %d\n", argc); 0040104E mov eax,dword ptr [ebp+8] push eax push offset string "argc = %d\n" (0042001c) call printf (00401090) 0040105C add esp,8
根据汇编代码我们看到,首先执行第一个if中的比较,jle表示当cmp得到的结果≤0时会进行跳转,第二个if在汇编中的跳转条件是>0,从这个上面可以看出在代码执行过程当中if转换的条件判断语句与if的判断结果时相反的,也就是说cmp比较后不成立则跳转,成立则向下执行。同时每一次跳转都是到当前if语句的下一条语句。
下面来看看if...else...语句的跳转:
if(argc > 0) { printf("argc > 0\n"); } else { printf("argc <= 0\n"); } printf("argc = %d\n", argc);
//上面代码对应的汇编代码 9: if(argc > 0) cmp dword ptr [ebp+8],0 0040102C jle main+2Dh (0040103d) ;条件不满足则跳转到else语句块中 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (0042003c) call printf (00401090) add esp,4 12: }else 0040103B jmp main+3Ah (0040104a);如果执行if语句块就会执行这条语句跳出else语句块 13: { 14: printf("argc <= 0\n"); 0040103D push offset string "argc <= 0\n" (0042002c) call printf (00401090) add esp,4 15: } 16: printf("argc = %d\n", argc); 0040104A mov eax,dword ptr [ebp+8]
上述的汇编代码指出,对于if...else..语句,首先进行条件判断,if表达式为真,则继续执行if快中的语句,然后利用jmp跳转到else语句块外,否则会利用jmp跳转到else语句块中,然后依次执行其后的每一句代码。
最后再来展示if...else if...else这种分支结构:
if(argc > 0) { printf("argc > 0\n"); } else if(argc < 0) { printf("argc < 0\n"); } else { printf("argc == 0\n"); } printf("argc = %d\n", argc);
//上述代码对应的汇编代码 9: if(argc > 0) cmp dword ptr [ebp+8],0 0040102C jle main+2Dh (0040103d);条件不满足则会跳转到下一句else if中 10: { 11: printf("argc > 0\n"); 0040102E push offset string "argc > 0\n" (00420f9c) call printf (00401090) add esp,4 12: }else if(argc < 0) 0040103B jmp main+4Fh (0040105f) ;当上述条件符合则执行这条语句跳出分支外,跳转的地址正是else语句外的printf语句 0040103D cmp dword ptr [ebp+8],0 jge main+42h (00401052) 13: { 14: printf("argc < 0\n"); push offset string "argc < 0\n" (0042003c) call printf (00401090) 0040104D add esp,4 15: }else jmp main+4Fh (0040105f) 16: { 17: printf("argc == 0\n"); push offset string "argc <= 0\n" (0042002c) call printf (00401090) 0040105C add esp,4 18: } 19: printf("argc = %d\n", argc); 0040105F mov eax,dword ptr [ebp+8]
通过汇编代码可以看到对于这种结构,会依次判断每个if语句中的条件,当有一个满足,执行完对应语句块中的代码后,会直接调转到分支结构外部,当前面的条件都不满足则会执行else语句块中的内容。这个逻辑结构在某些情况下可以利用if return if return 这种结构来替代。当某一条件满足时执行完对应的语句后直接返回而不执行其后的代码。一条提升效率的做法是将最有可能满足的条件放在前面进行比较,这样可以减少比较次数,提升效率。
2.2 switch...case...执行原理
switch是另一种比较常用的多分支结构,在使用上比较简单,效率上也比if...else if...else高,下面将分析switch结构的实现:
switch(argc) { case 1: printf("argc = 1\n"); break; case 2: printf("argc = 2\n"); break; case 3: printf("argc = 3\n"); break; case 4: printf("argc = 4\n"); break; case 5: printf("argc = 5\n"); break; case 6: printf("argc = 6\n"); break; default: printf("else\n"); break; }
//对应的汇编代码 0040B798 mov eax,dword ptr [ebp+8] ;eax = argc 0040B79B mov dword ptr [ebp-4],eax 0040B79E mov ecx,dword ptr [ebp-4] ;ecx = eax 0040B7A1 sub ecx,1 0040B7A4 mov dword ptr [ebp-4],ecx 0040B7A7 cmp dword ptr [ebp-4],5 ;比较argc 与 5的大小关系 0040B7AB ja $L544+0Fh (0040b811) ;argc > 5则跳转到default处,至于为什么是5而不是6,看后面的说明 0040B7AD mov edx,dword ptr [ebp-4] ;edx = argc 0040B7B0 jmp dword ptr [edx*4+40B831h] 11: case 1: 12: printf("argc = 1\n"); 0040B7B7 push offset string "argc = 1\n" (00420fc0) 0040B7BC call printf (00401090) 0040B7C1 add esp,4 13: break; 0040B7C4 jmp $L544+1Ch (0040b81e) 14: case 2: 15: printf("argc = 2\n"); 0040B7C6 push offset string "argc = 2\n" (00420fb4) 0040B7CB call printf (00401090) 0040B7D0 add esp,4 16: break; 0040B7D3 jmp $L544+1Ch (0040b81e) 17: case 3: 18: printf("argc = 3\n"); 0040B7D5 push offset string "argc = 3\n" (00420fa8) 0040B7DA call printf (00401090) 0040B7DF add esp,4 19: break; 0040B7E2 jmp $L544+1Ch (0040b81e) 20: case 4: 21: printf("argc = 4\n"); 0040B7E4 push offset string "argc = 4\n" (00420f9c) 0040B7E9 call printf (00401090) 0040B7EE add esp,4 22: break; 0040B7F1 jmp $L544+1Ch (0040b81e) 23: case 5: 24: printf("argc = 5\n"); 0040B7F3 push offset string "argc < 0\n" (0042003c) 0040B7F8 call printf (00401090) 0040B7FD add esp,4 25: break; 0040B800 jmp $L544+1Ch (0040b81e) 26: case 6: 27: printf("argc = 6\n"); 0040B802 push offset string "argc <= 0\n" (0042002c) 0040B807 call printf (00401090) 0040B80C add esp,4 28: break; 0040B80F jmp $L544+1Ch (0040b81e) 29: default: 30: printf("else\n"); 0040B811 push offset string "argc = %d\n" (0042001c) 0040B816 call printf (00401090) 0040B81B add esp,4 31: break; 32: } 33: 34: return 0; 0040B81E xor eax,eax
上面的代码中并没有看到像if那样,对每一个条件都进行比较,其中标红的一行代码 “jmp dword ptr [edx*4+40B831h]” 从表面上看应该是取数组中的元素,再根据元素的值来进行跳转,而这个元素在数组中的位置与eax也就是与argc的值有关,下面我们跟踪到数组中查看数组的元素值:
0040B831 B7 B7 40 00
0040B835 C6 B7 40 00
0040B839 D5 B7 40 00
0040B83D E4 B7 40 00
0040B841 F3 B7 40 00
0040B845 02 B8 40 00
通过对比可以发现0x0040b7b7是case 1处的地址,后面的分别是case 2、case 3、case 4、case 5、case 6处的地址,每个case中的break语句都翻译为了同一句话“jmp $L544+1Ch (0040b81e)”,所以从这可以看出,在switch中,编译器多增加了一个数组用于存储每个case对应的地址,根据switch中传入的整数在数组中查到到对应的地址,直接通过这个地址跳转到对应的位置,减少了比较操作,提升了效率。编译器在处理switch时会首先校验不满足所有case的情况,当这种情况发生时代码调转到default或者switch语句块之外。然后将传入的整数值减一(数组元素是从0开始计数)。最后根据参数值找到应该跳转的位置。
上述的代码case是从0~6依次递增,这样做确实可行,但是当我们在case中的值并不是依次递增的话会怎样?此时根据不同的情况编译器会做不同的处理。
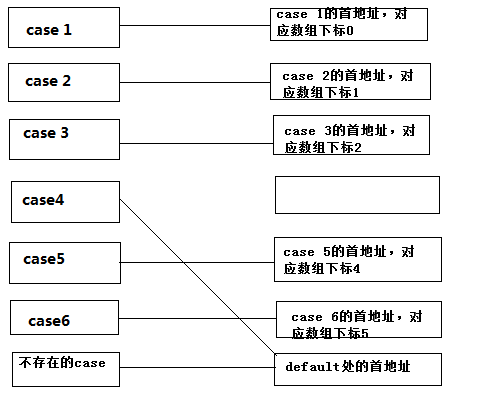
- 一般仍然会建立这样的一个表,将case中出现的值填写对应的跳转地址,没有出现的则将这个地址值填入default对应的地址或者switch语句结束的地址,比如当我们上述的代码去掉case 5, 这个时候填入的地址值如下图所示
- 如果每两个case之间的差距大于6,或者case语句数小于4则不会采取上面的做法,如果再采用这种方式,那么会造成较大的资源消耗。这个时候编译器会采用索引表的方式来进行地址的跳转。例如:
switch(argc) { case 1: printf("argc = 1\n"); break; case 2: printf("argc = 2\n"); break; case 5: printf("argc = 5\n"); break; case 6: printf("argc = 6\n"); break; case 255: printf("argc = 255\n"); default: printf("else\n"); break; }
//对应的汇编代码 0040B798 mov eax,dword ptr [ebp+8] 0040B79B mov dword ptr [ebp-4],eax 0040B79E mov ecx,dword ptr [ebp-4] ;到此eax = ecx = argc 0040B7A1 sub ecx,1 0040B7A4 mov dword ptr [ebp-4],ecx 0040B7A7 cmp dword ptr [ebp-4],0FEh 0040B7AE ja $L542+0Dh (0040b80b) ;当argc > 255则跳转到default处 0040B7B0 mov eax,dword ptr [ebp-4] 0040B7B3 xor edx,edx 0040B7B5 mov dl,byte ptr (0040b843)[eax] 0040B7BB jmp dword ptr [edx*4+40B82Bh] 11: case 1: 12: printf("argc = 1\n"); 0040B7C2 push offset string "argc = 1\n" (00420fb4) 0040B7C7 call printf (00401090) 0040B7CC add esp,4 13: break; 0040B7CF jmp $L542+1Ah (0040b818) 14: case 2: 15: printf("argc = 2\n"); 0040B7D1 push offset string "argc = 3\n" (00420fa8) 0040B7D6 call printf (00401090) 0040B7DB add esp,4 16: break; 0040B7DE jmp $L542+1Ah (0040b818) 17: case 5: 18: printf("argc = 5\n"); 0040B7E0 push offset string "argc = 5\n" (00420f9c) 0040B7E5 call printf (00401090) 0040B7EA add esp,4 19: break; 0040B7ED jmp $L542+1Ah (0040b818) 20: case 6: 21: printf("argc = 6\n"); 0040B7EF push offset string "argc < 0\n" (0042003c) 0040B7F4 call printf (00401090) 0040B7F9 add esp,4 22: break; 0040B7FC jmp $L542+1Ah (0040b818) 23: case 255: 24: printf("argc = 255\n"); 0040B7FE push offset string "argc <= 0\n" (0042002c) 0040B803 call printf (00401090) 0040B808 add esp,4 25: default: 26: printf("else\n"); 0040B80B push offset string "argc = %d\n" (0042001c) 0040B810 call printf (00401090) 0040B815 add esp,4 27: break; 28: } 29: 30: return 0; 0040B818 xor eax,eax
这段代码与上述的线性表相比较区别并不大,只是多了一句 “mov dl,byte ptr (0040b843)[eax]” 这似乎又是一个数组,通过查看内存可以知道这个数组的值分别为:00 01 05 05 02 03 05 05 ... 04,下一句根据这些值在另外一个数组中查找数据,我们列出另外一个数组的值:
C2 B7 40 00 D1 B7 40 00 E0 B7 40 00 EF B7 40 00 FE B7 40 00 0B B8 40 00
通过对比我们发现,这些值分别是每个case与default入口处的地址,编译器先查找到每个值在数组中对应的元素位置,然后根据这个位置值再在地址表中从、找到地址进行跳转,这个过程可以用下面的图来表示:
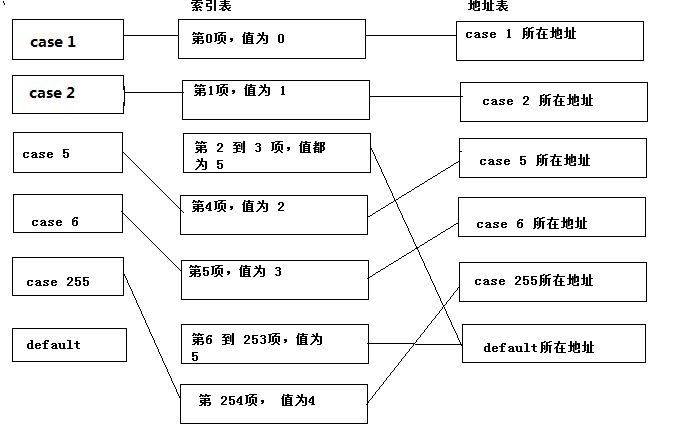
这样通过一个每个元素占一个字节的表,来表示对应的case在地址表中所对应的位置,从而跳转到对应的地址,这样通过对每个case增加一个字节的内存消耗来达到,减少地址表对应的内存消耗。
在上述的汇编代码中,是利用dl寄存器来存储对应case在地址表中项,这样就会产生一个问题,当case 值大于 255,也就是超出了一个字节的,超出了dl寄存器的表示范围时,又该如何来进行跳转这个时候编译器会采用判定树的方式来进行判定,在根节点保存的是所有case值的中位数, 左子树都是大于这个大于这个值的数,右字数是小于这个值的数,通过每次的比较来得到正确的地址。比如下面的这个判定树,首先与10进行比较,根据与10 的大小关系进入左子树或者右子树,再看看左右子树的分支是否不大于3,若不大于3则直接转化为对应的if...else if... else结构,大于3则检测分支是否满足上述的优化条件,满足则进行对应的地址表或者索引表的优化,否则会再次对子树进行优化,以便减少比较次数。

2.3 总结
switch-case会生成一个跳转表来指示实际的case分支的地址,而这个跳转表的索引号与switch变量的值是相等的。从而,switch-case不用像if-elseif那样遍历条件分支直到命中条件,而只需访问对应索引号的表项从而到达定位分支的目的。 具体地说,switch-case会生成一份表项数为case量+1的跳表,程序首先判断switch变量是否大于(小于)最大(最小)case 常量,若大于(小于),则跳到default分支处理;否则取得索引号为switch变量大小的跳表项的地址(即跳表的起始地址+表项大小*索引号),程序接着跳到此地址执行,到此完成了分支的跳转。
由此看来,switch-case结构有一点以空间换时间的意思,当分支较多的时候明显switch-case结构的实行效率会高很多。但是switch-case的缺点是只能处理常量的匹配,在仅有常量选择分支的时候,可以选用switch-case结构,而此时通过遍历数组比较更是不可取的一种方式,但是if-elseif可以应用于更多的场合(如a > 10 && a < 20),显得更为灵活。
三、简单优化
暂且不说if-else与switch相比哪一个的执行效率高,先就知道原理后,我们应如何去优化。
3.1 if-else
对于if-else,在系统是自上而下逐个条件去判断,直到命中;所以应将机率大的条件置于最前面。以下给出一个简单例子
double random = Math.random()*100;//生成0-100的随机数 if(random > 10){ //90% }else if(random > 5){//5% }else{//剩下的5% }
对于条件机率相等或是条件个数非常多的情况,因为switch的执行时间与条件数量无关,他是根据switch值直接跳转到对应分支,所以可以选择switch代替if-else。
3.2 switch
对于switch,实际上是根据case最小值与最大值,维系了一段连续的内存空间,以空间换取时间。以下给出一个简单的反例,最大值与最小值跨度较大,且之间没有更多的条件情况,那个无疑实际申请的很多空间是没用的,所以就应考虑使用if-else在代替。
int random = (int) Math.random() * 100;// 生成0-100的随机数 switch (random) { case 0: break; case 100: break; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号