FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising
论文来源:FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising
笔记参考:论文阅读:FFDNet
代码参考:FFDNet_pytorch
DnCNN利用Batch Normalization和residual learning可以有效地去除均匀高斯噪声,且对一定噪声水平范围的噪声都有抑制作用。然而真实的噪声并不是均匀的高斯噪声,其是信号依赖的,各颜色通道相关的,而且是不均匀的,可能随空间位置变化的。在这种情况下,FFDNet使用噪声估计图作为输入,权衡对均布噪声的抑制和细节的保持,从而应对更加复杂的真实场景。而CBDNet进一步发挥了这种优势,其将噪声水平估计过程也用一个子网络实现,从而使得整个网络可以实现盲去噪。
文章贡献:
- 针对图像去噪问题,提出了一种快速灵活的去噪网络FFDNet。通过将一个可调噪声级别图作为输入,一个单一的FFDNet能够处理不同级别的噪声,以及空间变化的噪声。
- 我们强调了确保噪音水平图在控制降噪和细节保留之间的平衡方面的重要性。
- FFDNet在被AWGN破坏的合成噪声图像和真实噪声图像上都展示了具有感知吸引力的结果,展示了它在实际图像去噪方面的潜力。
在DnCNN的基础上添加了下采样和上采样:
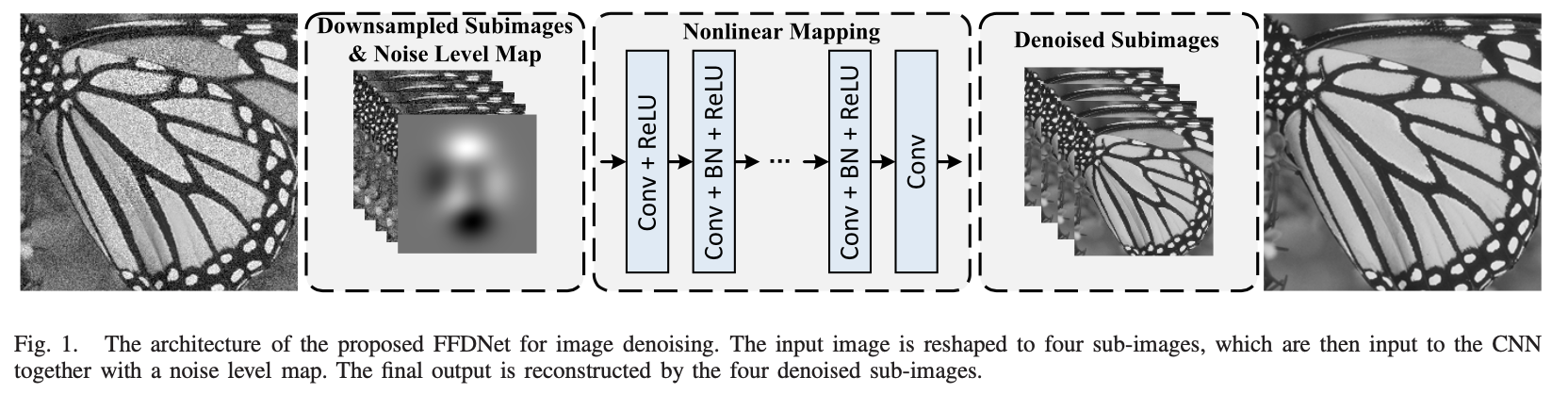
引入可逆下采样算子将W×H×C的输入图像重塑为4个下采样(W/2)×(H/2)× 4C的子图像。这里C为通道数,灰度图像C = 1,彩色图像C = 3。为了使噪声级图能够在不引入视觉伪影的情况下,有效地控制噪声降低和细节保留之间的平衡,对卷积滤波器采用了正交初始化方法。
代码(pytorch):
1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 import torch.optim as optim 5 from torch.autograd import Variable 6 7 import utils 8 9 class FFDNet(nn.Module): 10 11 def __init__(self, is_gray): 12 super(FFDNet, self).__init__() 13 14 if is_gray: 15 self.num_conv_layers = 15 # all layers number 16 self.downsampled_channels = 5 # Conv_Relu in 17 self.num_feature_maps = 64 # Conv_Bn_Relu in 18 self.output_features = 4 # Conv out 19 else: 20 self.num_conv_layers = 12 21 self.downsampled_channels = 15 22 self.num_feature_maps = 96 23 self.output_features = 12 24 25 self.kernel_size = 3 26 self.padding = 1 27 28 layers = [] 29 # Conv + Relu 30 layers.append(nn.Conv2d(in_channels=self.downsampled_channels, out_channels=self.num_feature_maps, \ 31 kernel_size=self.kernel_size, padding=self.padding, bias=False)) 32 layers.append(nn.ReLU(inplace=True)) 33 34 # Conv + BN + Relu 35 for _ in range(self.num_conv_layers - 2): 36 layers.append(nn.Conv2d(in_channels=self.num_feature_maps, out_channels=self.num_feature_maps, \ 37 kernel_size=self.kernel_size, padding=self.padding, bias=False)) 38 layers.append(nn.BatchNorm2d(self.num_feature_maps)) 39 layers.append(nn.ReLU(inplace=True)) 40 41 # Conv 42 layers.append(nn.Conv2d(in_channels=self.num_feature_maps, out_channels=self.output_features, \ 43 kernel_size=self.kernel_size, padding=self.padding, bias=False)) 44 45 self.intermediate_dncnn = nn.Sequential(*layers) 46 47 def forward(self, x, noise_sigma): 48 noise_map = noise_sigma.view(x.shape[0], 1, 1, 1).repeat(1, x.shape[1], x.shape[2] // 2, x.shape[3] // 2) 49 50 x_up = utils.downsample(x.data) # 4 * C * H/2 * W/2 51 x_cat = torch.cat((noise_map.data, x_up), 1) # 4 * (C + 1) * H/2 * W/2 52 x_cat = Variable(x_cat) 53 54 h_dncnn = self.intermediate_dncnn(x_cat) 55 y_pred = utils.upsample(h_dncnn) 56 return y_pred

