

Oracle性能管理;AWR报告(自动化作业任务)
一、AWR报告
分析工具AWR(Automatic Workload Repository,自动负载仓库):默认每小时生成一份快照,保留8天,第二次快照和第一份快照相减对比出来。有主动维护:定期备份、自动刷新自动生成AWR报告;被动维护:告警日志非常危险且无法自动修复的错误,sql顾问和段顾问会自动收集oracle的一些awr报告。性能调优主要在I/O设备竞争、资源竞争、应用代码问题、网络瓶颈四个方面。
1、术语介绍
(1)、统计信息,有Optimizer statistics和database statistics两种
(2)、Metric:统计信息中心的变化率
(3)、Threshold:用来对比度量值的边界值
(4)、snapshot:特定时间点捕获到一系列性能统计信息
(5)、Automatic Workload Repository(AWR):用于数据收集、分析和解决方案建议的基础信息仓库。
(6)、AWR Baseline:一组AWR快照,用于性能比较
(7)、Active Session History(ASH):存储在AWR中的历史会话活动信息,对很短时间内的数据库运行情况进行汇总收集。
@$ORACLE_HOME/rdbms/admin/ashrpt.sql; //这个是单实例,ashrpti.sql指定实例或rac
(8)、Automatic Database Diagnostic Monitor(ADDM):用来监视实例,检测瓶颈点(自动在每个AWR快照后运行(也可以手动生成),每次AWR快照生成后,ADDM自动分析最近的两份快照,主动监控实例和检测瓶颈点),下面是手动生成的方法,采用的是sql脚本的方法,系统包比较复杂。
@?/rdbms/admin/addmrpt.sql
2、管理baseline
1、生成baseline

select snap_id,startup_time,begin_interval_time,end_interval_time from dba_hist_snapshot order by snap_id; //查看snap_id,开始时间是begin_interval_time begin DBMS_WORKLOAD_REPOSITORY.CREATE_BASELINE( start_snap_id => 616, end_snap_id => 617, baseline_name => 'oltp_peakload_bl', expiration => 10); end; /

2、删除baseline
begin DBMS_WORKLOAD_REPOSITORY.DROP_BASELINE( baseline_name => 'oltp_peakload_bl', cascade=> true); end; / //cascade表示同时删除快照
3、管理AWR报告
采集等级控制受参数statistics_level影响,basic:禁用多数的ADDM,自动收集优化信息功能被关闭;typical:建议值,也是默认值;all:收集所有可能的优化信息。
(1)、生成AWR报告步骤
@?/rdbms/admin/awrrpt.sql; //生成awr报告
//输入报告类型:html
Enter value for report_type:html
//提示num_days收集几天的报告信息
Enter value for num_days:1
//提示begin_snap抓取时间范围对应的开始快照id,如果快照很少可以手动生成快照
Enter value for begin_snap:613
//提示end_snap抓取时间范围对应的结束快照id
Enter value for end_snap:614
//提示report_name输出报告名称
Enter value for report_name:awrrpt20221204.html
//一般情况下文件保存当前目录下,可通过!pwd查看
(2)、生成快照和删除快照的方法
begin dbms_workload_repository.create_snapshot(); end; / begin dbms_workload_repository.drop_snapshot_range( low_snap_id=>127, high_snap_id=>127, dbid=3344514553 ); end; /
(3)、修改AWR配置
begin dbms_workload_repository.modify_snapshot_settings( retention=>9*24*60, interval=>60, topnsql=>50 ); end; / //retention表示快照保留10天;interval表示每30分钟采集一次;topnsql表示统计top50的sql,statistics=Typical下的默认是30,all是100。
4、AWR报告分析(将awr报告下载到本地并用Google浏览器打开)
参考连接:Oracle AWR报告详细分析
(1)、WORKLOAD REPOSITORY report for
数据库的基本信息,数据库名称DB Name、版本Release、最近一次启动时间Startup Time。
DB Time= cpu time + all of nonidle wait event time,db time记录服务器花在数据库运算和等待(非空闲等待)上的时间,如果db time远远小于Elapsed时间,说明数据库比较空闲。

Elapsed是快照的时间间隔,DB Time是60min内使用的CPU时间,CPU数是2,所以如果DB Time大于60*2=120min,说明CPU负载高。
(2)、Report Summary
Instance Efficiency Percentages (Target 100%):实例有效占比(目标100%)
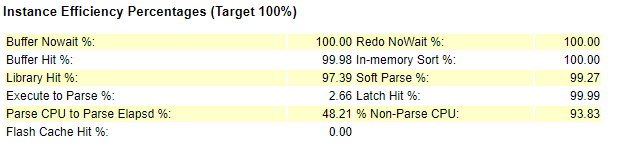
Buffer Nowait:在内存获取数据的未等待比例,在缓冲区中获取Buffer的未等待比例。一般要大于99%,否则可能存在争用。
Redo Nowait:表示LOG缓冲区获得BUFFER的未等待比例。
Buffer Hit:进程从内存中找到数据块的比例,监视这个值是否发生重大变化比这个值本身更重要。命中率突然变大,可以检查top buffer get SQL,查看导致大量逻辑读的语句和索引;命中率突然变小,可以检查top physical reads SQL。
In-memory Sort:在内存中排序的比率,如果过低说明有大量的排序在临时表空间中进行。
Library hit:Oracle从Library Cache中检索到一个解析过的SQL或PL/SQL语句的比例。低的Library Hit ratio会导致过多的解析,增加CPU消耗,降低性能。STATEMENT在共享区的命中率,应保持在95%以上,否则要考虑加大共享池、使用绑定变量、修改cursor_sharing等参数。
Soft Parse:软解析的百分比,近似当做sql在共享区的命中率,太低则需要使用绑定变量。
Latch Hit:Latch是一种保护内存结构的锁。要确保大于99%,否则意味Share Pool Latch争用。
Parse CPU to Parse Elapsed:解析实际运行时间/(解析实际运行时间+解析中等待资源时间),越高越好。
Non-Parse CPU:SQL实际运行时间/(SQL实际运行时间+SQL解析时间),太低表示解析消耗时间过多。
Execute to Parse:是语句执行与分析的比例。如果SQL重用率高,则这个比例会很高。该值越高表示一次解析后被重复执行的次数越多。
Top 10 Foreground Events by Total Wait Time:按总等待时间排序的前10个前台事件
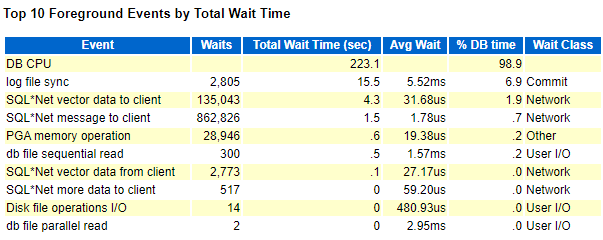
Event是事件名称;Waits是等待事件发生次数;Total Wait Time(sec)是等待事件消耗的总计时间;Avg Wait是该等待事件平均等待时间。
(3)、main report(sql statistics)
SQL ordered by Elapsed Time:SQL按照运行时间排序
Elapsed Time:SQL运行的总时长
Executions:SQL语句在监控范围内的执行次数总计
Elapsed Time per Exec:执行一次sql的平均时间
%Total:是SQL的Elapsed Time时间占数据库总时间的百分比
SQL Text:是简略的sql语句。
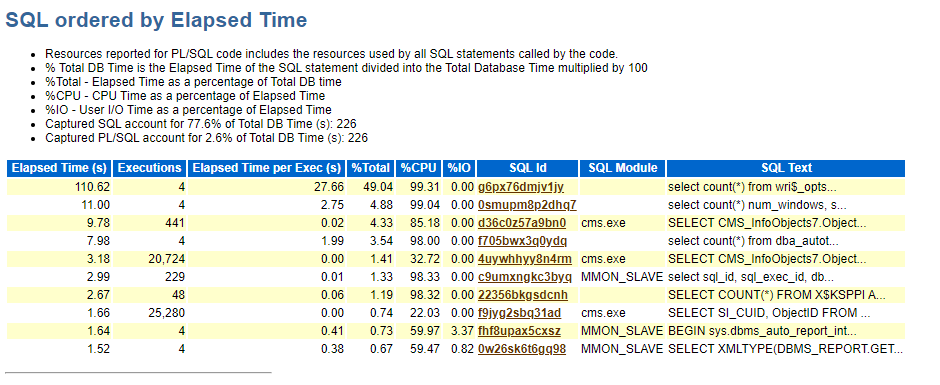
点击SQL_ID查看详细的SQL语句。
二、性能优化方式
1、SQL调优集
(1)、创建索引
a、尽量避免全表扫描,首先考虑在where及order by涉及的列上建立索引。
b、在经常需要检索的字段上创建索引,个表的索引数最好不要超过6个
c、及时调整索引不生效的情况
d、避免在索引上使用计算,避免在索引列使用NOT、IS NULL或IS NOT NULL
(2)、尽量将多条SQL语句压缩到一句SQL中:每次执行SQL都要建立网络连接、SQL语句的查询优化、发送执行结果
(3)、用Where子句替换Having:Having会在检索出所有记录之后对结果集进行过滤,这个处理需要排序、总计等操作。
(4)、用TRUNCATE替代DELETE:TRUNCATE是全表删除,是DDL,不能再被恢复;DELETE是DML,回滚段用来存放可以被恢复的信息,如果没有commit,Oracle会将数据恢复到删除之前的状态。
(5)、使用表的别名:SQL连接多个表时。使用表的别名把别名前缀与每个列名上,减少解析时间和列名歧义引起的语法错误
(6)、减少查询字段,不使用" * "
2、硬解析、软解析
(1)、执行SQL语句时,要经历几个步骤:
a、语法检查
b、语义检查
c、解析SQL语句
Oracle使用内部哈希算法获取sql的哈希值,然后查找该哈希值是够存在于库缓存中(共享池的库高速缓存)。若存在,将该sql与缓存中的sql进行比较,若相同则使用现有的分析树和执行计划,省略优化器的相关工作,这是软解析的过程;若不存在哈希值或不相同,优化器将执行创建解析树并生成执行计划,此过程称为硬解析。
d、执行SQL并返回结果
(2)、绑定变量
select * from scott.emp where empno =7900;
select * from scott.emp where empno = :emp_no;
第一条语句:查询员工编号是 7900 的员工,Oracle经过第一次分析编译后执行,下次要查询编号为 7902 和 7934 员工信息时,Oracle会再将这句SQL分析编译,然后再执行。
第二条语句:定义变量emp_no,将 7900 赋给变量,第一次经过编译后,把查询计划存储在一个共享池中,后执行,下次查询编号为 7902 和 7934 员工信息时,不会再进行编译。
使用绑定变量减少编译次数(硬编译->软编译):要求变量名称,数据类型以及长度是一直的,减少编译次数可以使用较少的时间,而且可以减少锁存时间,降低锁存频率。
select * from scott.emp where empno = 7900; select * from scott.emp where empno = 7902; select * from scott.emp where empno = 7934; select sql_text from v$sql where sql_text like 'select * from scott.emp where empno%'; //存储在shared pool里保存最近执行的sql,或者获取硬解析的次数,以上三条数据都在 var emp_no number; //声明变量 exec :emp_no :=7900; select * from scott.emp where empno = :emp_no; exec :emp_no :=7902; select * from scott.emp where empno = :emp_no; exec :emp_no :=7934; select * from scott.emp where empno = :emp_no; select sql_text from v$sql where sql_text like 'select * from scott.emp where empno%'; //只有一条sql
(3)、更改参数cursor_sharing
cursor_sharing = {SIMILAR | EXACT | FORCE}
EXACT:要求SQL语句完全相同才会重用,否则会被重新执行硬解析操作。
SIMILAR:某条SQL语句的谓词条件可能会影响他的执行计划,才会重新解析。
Force:任何情况下,无条件重用SQL
show parameter cursor_sharing; alter session set sql_trace=true; //sql_trace是用于进行sql语句追踪的工具 //当cursor_sharing参数是exact alter session set cursor_sharing=exact; //修改参数 select * from scott.emp where empno = 7900; select * from scott.emp where empno = 7902; select * from scott.emp where empno = 7934; select sql_text from v$sql where sql_text like 'select * from emp where empno%'; //有三条数据 //当cursor_sharing参数是similar alter system flush share_pool; //清理共享池,测试环境使用,生产环境不使用 alter session set cursor_sharing=similar; select * from scott.emp where empno = 7900; select * from scott.emp where empno = 7902; select * from scott.emp where empno = 7934; select sql_text from v$sql where sql_text like 'select * from emp where empno%'; //显示出select * from scott.emp where empno= :"SYS_B_0",系统自己绑定一个变量 //当cursor_sharing参数是Force alter system flush share_pool; alter session set cursor_sharing=force; select * from scott.emp where empno = 7900; select * from scott.emp where empno like '7902'; select sql_text from v$sql where sql_text like 'select * from emp where empno%'; //显示出select * from scott.emp where empno= :"SYS_B_0",select * from scott.emp where empno like :'SYS_B_0'
3、资源管理
(1)、dbms_resource_manager包:用于维护资源计划,资源使用组和资源计划指令,以下是功能列表
资源消费组:具有相似资源需求的用户组或会话;
资源计划:在资源消费组之间分配资源的计划,同一时间内,一个数据库只能计划一个资源计划;
资源计划指令:指定如何在资源消费组之间分配资源。
spool /tmp/e.txt; //将包输出到文件里 desc dbms_resource_manager; spool off; dbms_resource_manager.clear_pending_area(); //清除资源管理器 dbms_resource_manager.create_pending_area(); //创建pending内存区,该内存区用于改变资源管理对象 dbms_resource_manager.validate_pending_area(); //校验资源管理器的改变 dbms_resource_manager.submit_pending_area(); //提交资源管理器的改变 dbms_resource_manager.create_plan(plan,comment,cpu_mth); //创建资源计划,plan是指定资源计划名,comment指定用户注释信息 dbms_resource_manager.create_cdb_plan(plan,comment); //创建cdb资源计划 dbms_resource_manager.delete_plan(plan); //删除资源计划 dbms_resource_manager.delete_cdb_plan(plan); //删除cdb资源计划 dbms_resource_manager.update_plan(plan); //更新资源计划的定义 dbms_resource_manager.update_cdb_plan(plan); //更新cdb资源计划的定义 dbms_resource_manager.create_plan_directive(plan,group_or_subplan,comment,cpu_mth,mgmt_mth,active_sess_pool_mth,parallel_degree_limit_mth,max_idle_blocker_time);
//建立资源计划指令,mgmt_mth分配cpu使用率,mth是p1、p2...;active_sess_pool_mth是限制活动会话数量;parallel_degree_limit_mth是任何操作的并行限制;max_idle_blocker_time是最大执行时间 dbms_resource_manager.create_cdb_plan_directive(plan,pluggable_database,comment); ////建立cdb资源计划指令 dbms_resource_manager.delete_plan_directive(plan); //删除资源计划指令 dbms_resource_manager.delete_cdb_plan_directive(plan,pluggable_database); //删除cdb资源计划指令 dbms_resource_manager.update_plan_directive(plan,pluggable_database); //更新资源计划指令 dbms_resource_manager.update_cdb_plan_directive(plan,pluggable_database); //更新cdb资源计划指令 dbms_resource_manager.create_consumer_group(consumer_group,comment,cpu_mth); //建立资源使用组,consumer_group指定资源使用组名 dbms_resource_manager.delete_consumer_group(consumer_group); //删除资源使用组 dbms_resource_manager.update_consumer_group(consumer_group); //更新资源使用组信息
(2)、实例(还未建立成功)
show parameter resource; exec dbms_resource_manager.clear_pending_area(); //清理内存区 exec dbms_resource_manager.create_pending_area(); //建立内存区 exec dbms_resource_manager.create_plan('TestPlan','测试资源计划'); //创建资源计划 exec dbms_resource_manager.create_consumer_group('TestGroup','测试资源使用组'); //创建资源使用组 exec dbms_resource_manager.create_plan_directive(plan=>'TestPlan',group_or_subplan=>'TestGroup',comment=>'测试资源组',cpu_p1=>40,parallel_degree_limit_p1=>3); //建立资源计划指令 exec dbms_resource_manager_privs.grant_switch_consumer_group('scott','TestGroup',false); //分配用户到资源使用组 alter system set resource_manager_plan='TestPlan' scope=momory exec dbms_resource_manager.validate_pending_area(); //验证内存区,验证通过即可提交,不许清除pending内存区重建资源对象 exec dbms_resource_manager.submit_pending_area(); //提交内存区
4、调度任务(12c没有图形界面EM,一下命令行还未测试成功)
创建/home/oracle/index_shell.sh脚本(索引的重建)
alter table emp move; alter table dept move; //保证有无效的索引 select index_name,status from user_index;
vi scheduler
(1)、创建程序
表示调度应该做什么事情,program_type是存储过程(stored_procedure),需要指定存储过程的名称;
program_type是PL/SQL块(PLSQL_BLOCK),需要输入完整的PL/SQL代码块;
program_type是外部程序(EXECUTABLE),需要输入script的名称或操作系统的指令名
begin dbms_scheduler.create_program( program_name=>' "SYS"."SCOTT_INDEX_P1" ', program_action=>'/home/oracle/index_shell.sh', program_type=>'EXECUTABLE', number_of_arguments=>0, comments=>'test a schedule program', enables=>TRUE ); //program_name指定程序的名称;program_action实际执行的操作;program_type指定程序的类型;number_of_arguments指定支持的参数个数,0表示没有参数
(2)、创建并使用调度
schedule表示调度计划表,调度从什么时候开始被调度,什么时候结束,以什么频率调度。
BEGIN dbms_scheduler.create_schedule( schedule_name=>' "SYS"."SCOTT_INDEX_S1" ', repeat_interval => 'FREQ=DAILY;BYHOUR=23', start_date=>systimestamp at time zone 'Asia/Shanghai' ); END //schedual_name是调度名称;start_date是开始时间,systimestamp 返回系统当前日期;end_date是结束时间;
//repeat_interval是重复频率,freq是用来指定间隔的时间周期,可选的参数由yearly、monthly、weekly、daily、hourly...,interval是指定间隔的频率,如若freq=daily;interval=7表示每7天执行一次;
//byhour指定执行时的具体的时,byminute指定几分;bysesond指定秒
(3)、创建并提交作业
作业是一个组合,包括调度、要执行的操作说明以及作业需要的所有附加参数。
按照指定的schedule,执行执行program,完成用户指定的工作。
BEGIN sys.dbms_scheduler.create_job( job_name=> ' "SYS"."SCOTT_INDEX_JOB1" ', program_name=>' "SYS"."SCOTT_INDEX_P1" ', schedule_name=>' "SYS"."SCOTT_INDEX_S1" ', job_class=> ' "DEFAULT_JOB_CLASS" ', auto_drop =>FALSE, enabled=>TRUE); //job_name任务名称;auto_drop设置job执行完毕都到期是否直接删除job;enabled创建后是否自动激活


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下