ORACLE基础SQL命令(HR模板用户创建、运算符、单行子函数、多行函数)
一、实验用户、表等数据来源(如果安装数据库的时候忘记创建模板就需要手动运行脚本来创建表)
进入/u01/app/oracle/product/19.0.0/dbhome_1/demo/schema/human_resources目录有以下文件
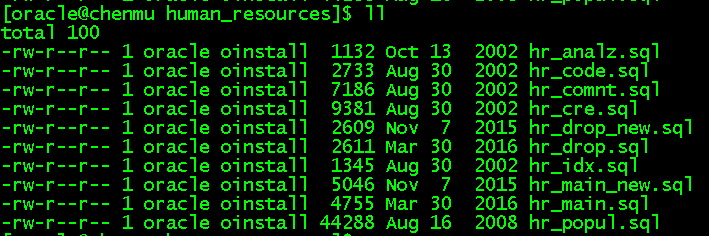
hr_analz.sql执行dbms_stats里面的函数,选择最佳物理访问策略
hr_code.sql在employees上创建语句级触发,以允许在工作时间使用DML,department_id或job_id列修改之后触发行级触发器,创建存储过程,将一行插入JOB_HISTORY表中。
hr_comnt.sql对regions、locations、departments、job_history、countries、jobs、employees表及其列做备注
hr_cre.sql创建6个表及其相关约束和索引,regions、locations、departments、job_history、countries、jobs、employees,还有emp_details_view视图
hr_drop_new.sql删除存储过程、视图、序列、表
hr_drop.sql同hr_drop_new.sql
hr_idx.sql创建索引
hr_popul.sql向表中添加数据,populate为增添数据
hr_main_new.sql创建用户,指定密码和使用的默认表空间和临时表空间,执行hr_cre.sql -> hr_popul.sql -> hr_idx.sql -> hr_code.sql -> hr_comnt.sql -> hr_analz.sql
hr_main.sql同hr_main_new.sql但是取消授权sys.dbms_stats
只需登录数据库执行sql脚本即可,在当前目录下登录数据库,执行@hr_main.sql即可,还需输入以下信息,日志路径输入/tmp

二、对表的操作
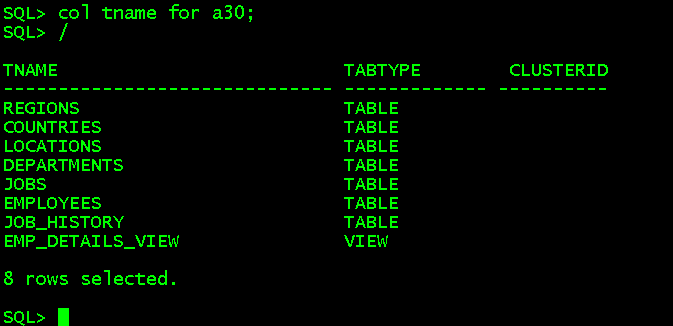
1、查看某用户有多少表,以创建的hr用户为例
conn hr/hr123 select * from tab; //因为显示出来的TNAME列比较长,可以通过col调整 col tname for a30;
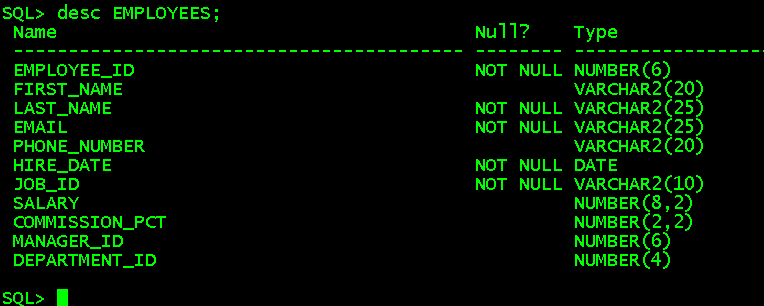
2、查看表结构
desc employees;
三、运算符(优先级从上至下1>2>3....)
1、算数运算符
+、-、*、/
2、连接运算符
||
3、比较运算符
>、>=、<、<=、<>或!=或^=
4、is [not] null、[not]like、[not] in
5、[not] between ... and ...
6、not
7、and
8、or
值排序中NULL是最大值,默认排序是升值排序,所以NULL排在后面,如果指定desc降序排列是NULL在前面,可用nulls last和nulls first指定null位置;order by 后面跟1表示第一列排序,1,2 desc 表示1列是升序,2列是降序。
like '_' 中 _ 匹配一个任意字符,like '%' 中 % 匹配一个或多个任意字符;字段别名如果有空格或特殊字符,要用双引号括起来,不能用单引号括起来。
oracle中的转义字符有 _ 、 % 、 & 、 ' ,_ 匹配任意一个字符,% 匹配一个或多个任意字符,& 是获取变量,' 是单引号
insert into employees(employee_id,first_name,last_name,email,hire_date,job_id,salary) values(207,'chenmu','_aylor','chen.com','10-Aug-22','IT_PROG',5000); insert into employees(employee_id,first_name,last_name,email,hire_date,job_id,salary) values(208,'yang','%%aylor','yang.com','10-Aug-22','IT_PROG',6000);
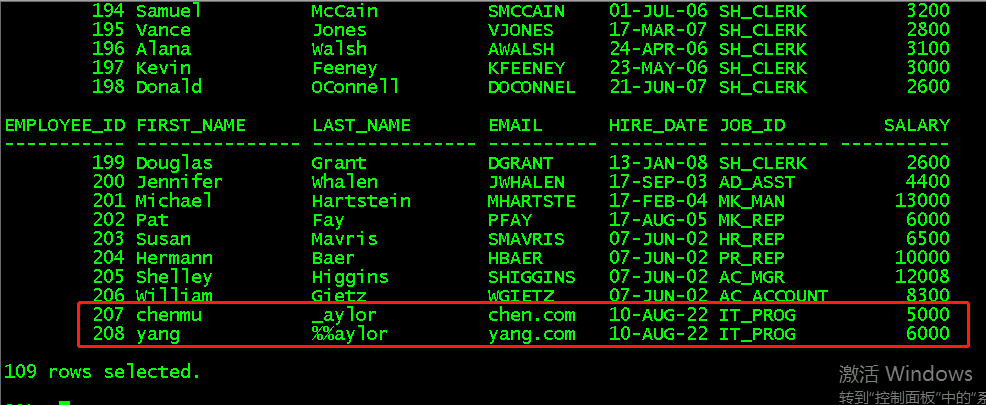
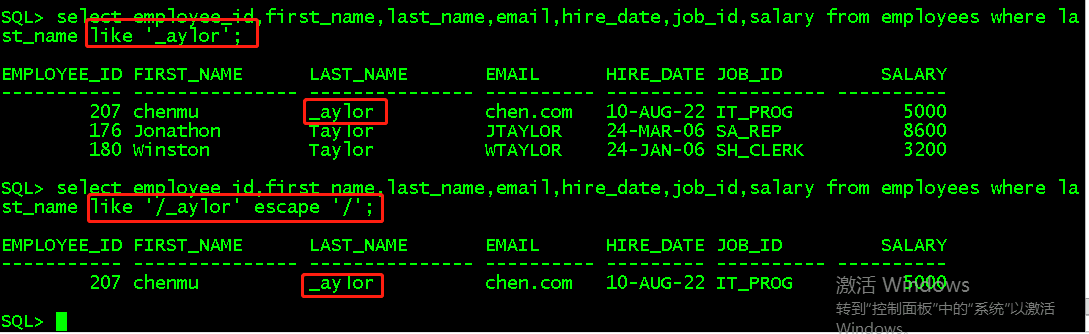
a、_ 测试
select employee_id,first_name,last_name,email,hire_date,job_id,salary from employees where last_name like '_aylor'; select employee_id,first_name,last_name,email,hire_date,job_id,salary from employees where last_name like '/_aylor' escape '/'; //取消 _ 的转义
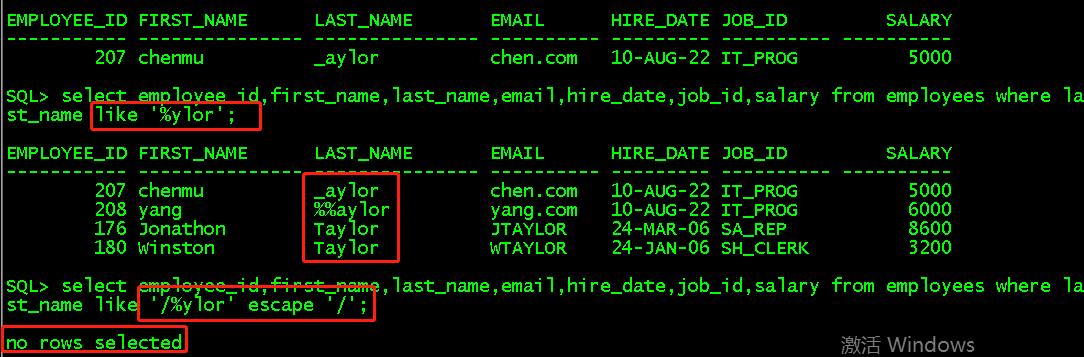
b、% 测试
select employee_id,first_name,last_name,email,hire_date,job_id,salary from employees where last_name like '%ylor'; select employee_id,first_name,last_name,email,hire_date,job_id,salary from employees where last_name like '/%ylor' escape '/';
c、& 测试
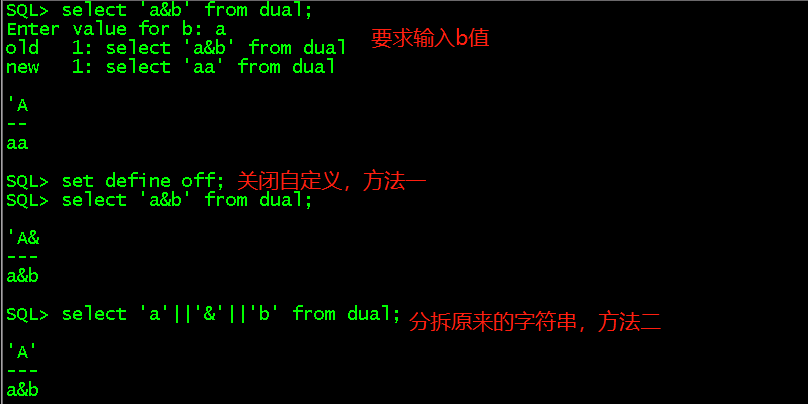
上面出现old和new值两行是因为verify参数,显示替代变量被替代前后的语句,set verify on显示,set verify off不显示。
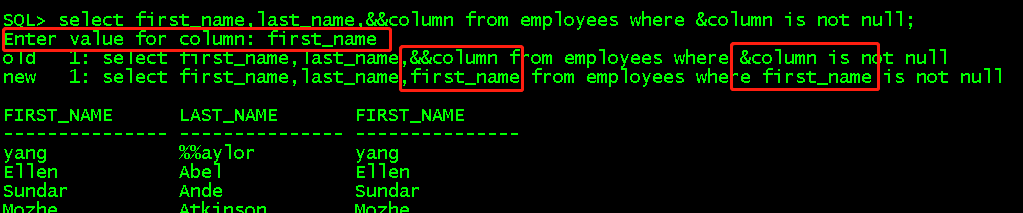
想通过输入字段然后判断字段是否为空,出现两次&column需要输入两次,因为sql从后向前解析,所以第一个&column可以写成&&column,这样就只需输入一次就够了,&column是临时的,每次执行都要赋值,&&column就记住变量了。
select first_name,last_name,&column from employees where &column is not null; select first_name,last_name,&&column from employees where &column is not null;

d、' 测试
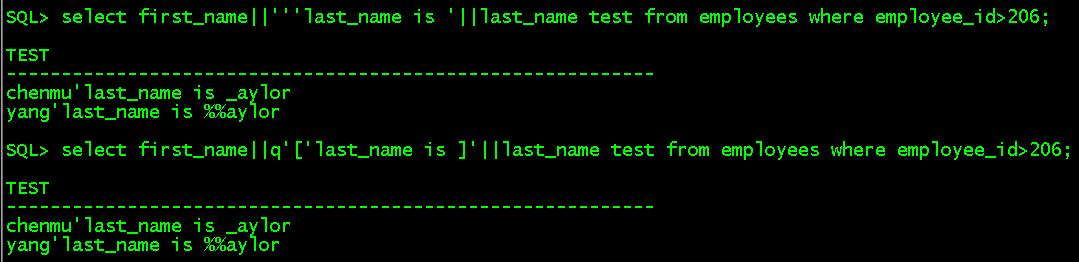
select first_name||''last_name is'||last_name test from employees;

可在前面再添加一个单引号,或者在使用quote
select first_name||'''last_name is '||last_name test from employees where employee_id>206; select first_name||q'['last_name is ]'||last_name test from employees where employee_id>206;
四、函数
1、单行函数(输入一行返回一行,而不是输入多行返回一行,单行行数可以嵌套nest)
(1)字符函数
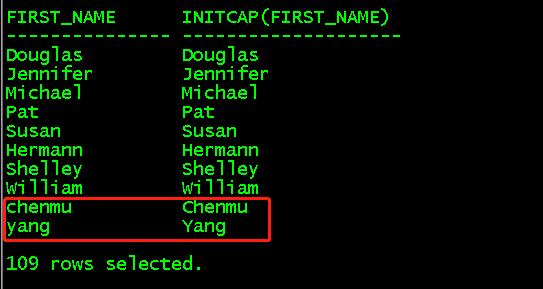
a、initCap(string1)将每个单词首字母大写
select first_name,initCap(first_name) from employees order by employee_id;
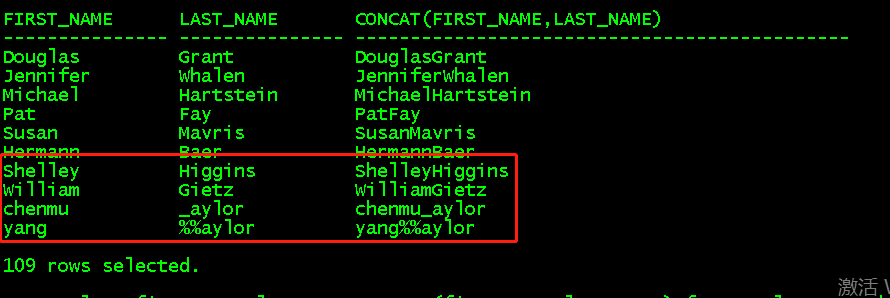
b、concat(str1,str2)连接str1和str2两个字符串,但是只能连接两个表达式,可以嵌套
select first_name,last_name,concat(first_name,last_name) from employees order by employee_id;
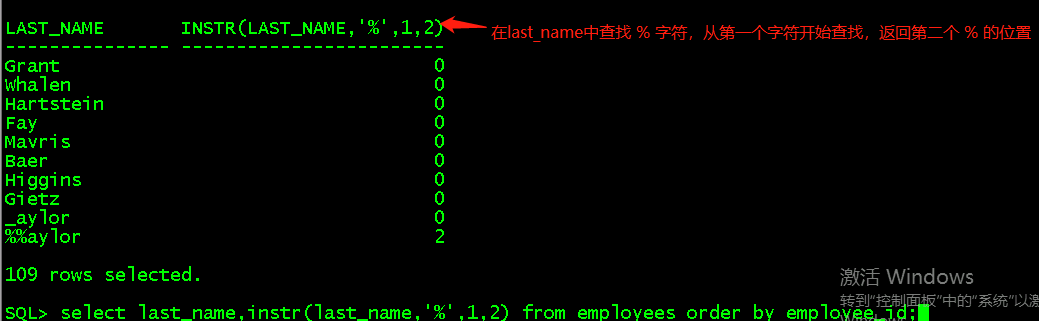
c、instr(str1,str2,start_position,nth_appearance)查找str2在str1中出现的位置,start_position代表从str1的哪个位置开始查找,nth_appearance表示要查找第几次出现的str2,后返回其位置
select last_name,instr(last_name,'%',1,2) from employees order by employee_id;
d、lpad(str,padded_length,[pad_str])在str左边填充pad_str字符,padded_length是填充之后的字符串长度,如果padded_length比str长度小,就会从左到右截取str中的padded_length个字符,如果pad_str未写,默认填充空格字符,rpad(str,padded_length,[pad_str])在str右边填充,padded_length比str长度小,处理同lpad。
select first_name,salary,lpad(salary,10,'*') lpad10,lpad(salary,3,'*') lpad3 from employees order by employee_id; select first_name,salary,rpad(salary,10,'*') rpad10,rpad(salary,3,'*') rpad3 from employees order by employee_id


e、trim截取字符
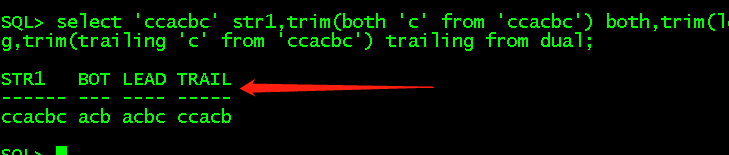
trim(both|leading|trailing 'char' from str1),both表示从str1左右遍历,leading表示从str1左侧遍历,trailing表示从str1右侧遍历,默认值是both。一旦str1中字符为char就去除,否则直接返回结果,注意这里是char。
select 'ccacbc' str1,trim(both 'c' from 'ccacbc') both,trim(leading 'c' from 'ccacbc') leading,trim(trailing 'c' from 'ccacbc') trailing from dual;
ltrim(str1,str2)从str1左边开始遍历,一旦str1中字符出现在str2中(字符集)就去除,否则直接返回结果,rtrim(str1,str2)同ltrim,但其从右边开始遍历。
select 'ccacbc' str1,ltrim('ccacbc','cb')left,rtrim('ccacbc','cb')rtrim from dual;

f、replace(source,old,new)在source中将old字符串替换成new字符串
select replace('chenmu*yang*chenmu*yang','mu','MM') from dual;

(2)数字函数
a、round(number,num_digits)number保留小数点后num_digits位,从num_digits后一位开始四舍五入
select 125.453738 test,round(125.453738,1) r1,round(125.453738,2) r2,round(125.453738,0) r0,round(125.453738,-2) rr2 from dual;

b、ceil(number)如果number有小数,返回int(number)+1,如果number没有小数,返回int(number),没有四舍五入
select ceil(125.453333) r1,ceil(125.546788) r2,ceil(125.00000) r3 from dual;

c、floor(number)无论number有没有小数,都返回int(number),没有四舍五入
select floor(125.453333) r1,floor(125.546788) r2,floor(125.00000) r3 from dual

d、trunc(number,num_digites)截取number小数点后num_digits位,不进行四舍五入(在MySQL是TRUNCATE函数)
select 125.453738 test,trunc(125.453738,1) r1,trunc(125.453738,2) r2,trunc(125.453738,0) r0,trunc(125.453738,-2) rr2 from dual

e、to_char(number,'format_model')将number转为相应的格式;9代表显示数字;0代表强制显示0;$表示美元符号;L表示使用当地货币;. 表示小数点(D);, 表示千分符(同G);. 和 , 一起使用,D和G一起使用
select 4023.156 test,to_char(4023.156,'$0,999.0000') testA, to_char(4023.156,'L0,999.0000') testB,to_char(4023.156,'$0G999D0000') testC from dual;

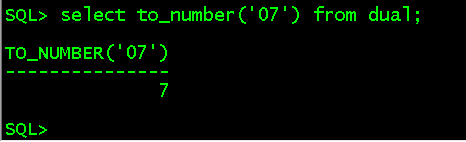
f、to_number(str)将数字格式的str转换成数字
select to_number('07') from dual;
g、mod(被除数,除数)=余数
select employee_id, last_name from employees where mod(employee_id,2)=0; //查询id号是偶数的员工
(3)时间函数
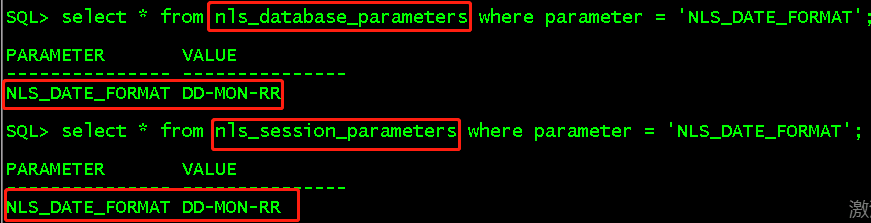
有四种修改NLS_DATE_FORMAT的方式
第一种是在用户的.bash_profile中增加两句:export NLS_LANGUAGE=AMERICAN;export NLS_DATE_FORMAT='yyyy/mm/dd hh24:mi:ss'。
第二种是SQLPLUS的glogin.sql文件增加一句:alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
第三种是直接修改当前会话的日期格式:alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
第四种是修改系统的日期格式,在重启之后生效: alter system set nls_date_format='yyyy-mm-dd hh24:mi:ss' scope=spfile;
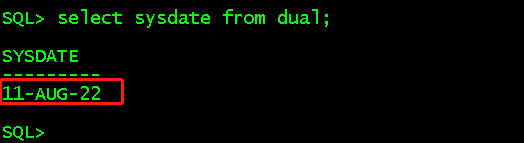
系统的时间格式是DD-MON-RR,而不是DD-MON-YY。RR是后两位年份,但是需要根据系统时间来判断前两位年份。
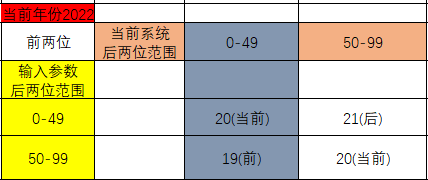
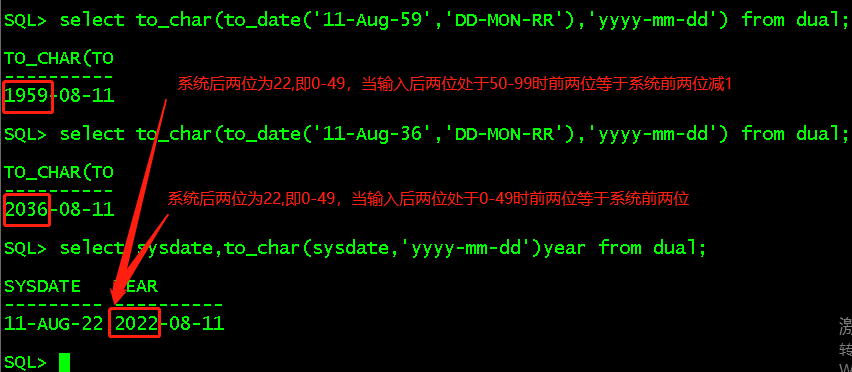
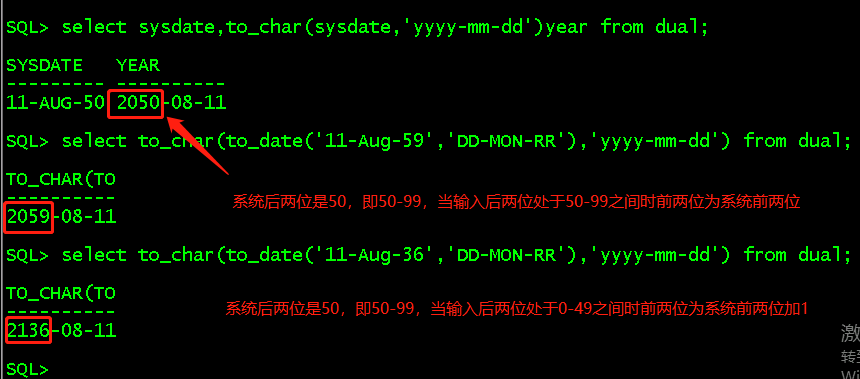
date -s '2050-08-11'; //在root用户下修改系统时间到2050 clock -w; select sysdate,to_char(sysdate,'yyyy-mm-dd')year from dual; select to_char(to_date('11-Aug-59','DD-MON-RR'),'yyyy-mm-dd') from dual; select to_char(to_date('11-Aug-36','DD-MON-RR'),'yyyy-mm-dd') from dual;
两个时间相减的到的是天数;相关时间和时区有相关连接https://www.cnblogs.com/muhai/p/16623341.html
a、to_char(date,'format')将date类型转为字符类型
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss')time from dual;

b、to_date(str,'format')将时间格式的字符类型转为date类型
select to_date('20220228','yyyy-mm-dd') from dual;
![]()
c、trunc(date,'format')根据相应格式截取时间
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss'; //将其转换成熟悉的格式 select trunc(sysdate,'yy') from dual; //截取年份,得到年的第一天
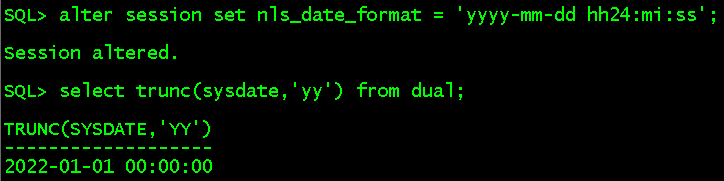
to_char和trunc的参考连接https://www.cnblogs.com/muhai/p/15335482.html
d、cast(col1 as data_type1)将某一列数据类型转换成data_type1类型
select cast('12.555555' as decimal(6,2))dec from dual; //将12.555555换成2位小数

f、round(date,'format')根据时间判断,如果是后半年就返回下一年第一天;如果是后半月就返回下一个月第一天;如果是后半天就返回下一天
select round(sysdate,'year')year,round(to_date('2022-10-16','yyyy-mm-dd'),'month')month,round(to_date('2022-10-16 12:00:01','yyyy-mm-dd hh24:mi:ss'),'dd')dd from dual;

以上三个函数都可参考时间格式参考连接
g、months_between(date1,date2),查看两个日期之间相差的月份
参考连接:https://www.cnblogs.com/muhai/p/15435554.html
h、add_months(date,num),对date加减月份
参考连接:https://www.cnblogs.com/muhai/p/15435679.html
i、next_day、last_day等时间函数可参考https://www.cnblogs.com/muhai/p/15788504.html
2、多行处理函数(分组函数,对某一组数据进行操作,显示的字段需要先通过group by分组;高级分组函数除了对某一组数据进行操作外还返回一行汇总,分组函数不统计空值)
分组函数筛选是要使用having,而不是通过where来筛选,group by和having位置可以调换,但是要在where之后。
select last_name,count(*) from employees where last_name='Taylor' having count(*)>1 group by last_name;

(1)分组函数:count()统计某一组有多少行,但不统计空值
select last_name,count(*) from employees group by last_name; //对last_name进行分组,查看last_name有多少种,每种有多少个,last_name没有重复显示
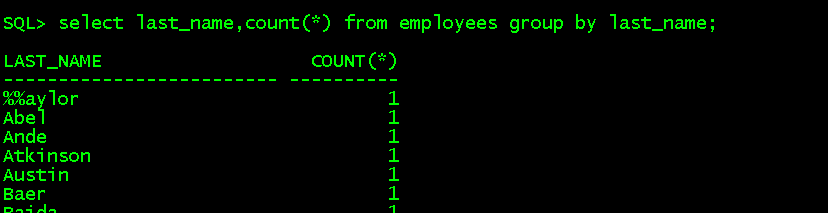
高级分组函数:count()统计某一组有多少行,并返回所有组的总行数,不统计空值
select last_name,count(*) from employees group by rollup(last_name); //等价于先select last_name,count(*) from employees group by last_name,最后一行select count(*) from employees group by 0
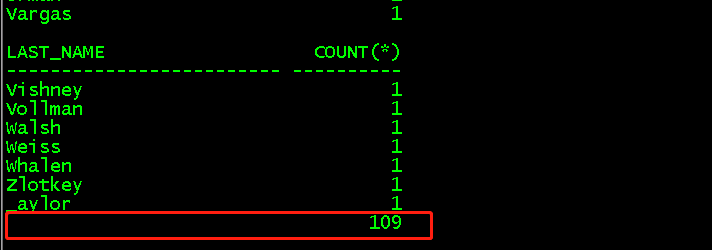
(2)sum()函数对某一组中的某一列求和
select sum(salary) from employees; //所有人作为一组,求所有人的工资总和
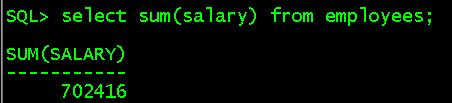
select last_name,sum(salary) from employees group by last_name; //对last_name进行分组,并对组进行salary求和,last_name只出现一次 select last_name,sum(salary) from employees group by rollup(last_name); //在底部对数据进行汇总 //等价于select last_name,sum(salary) from employees group by last_name,最后select sum(salary) from employees group by 0 select last_name,sum(salary) from employees group by cube(last_name); //在上面对数据进行汇总 //等价于select sum(salary) from employees group by 0,最后select last_name,sum(salary) from employees group by last_name
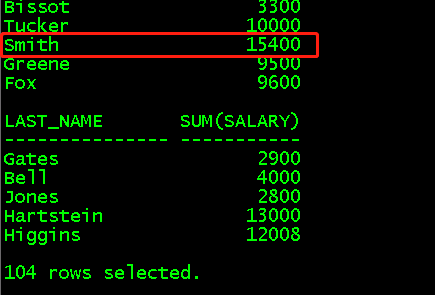
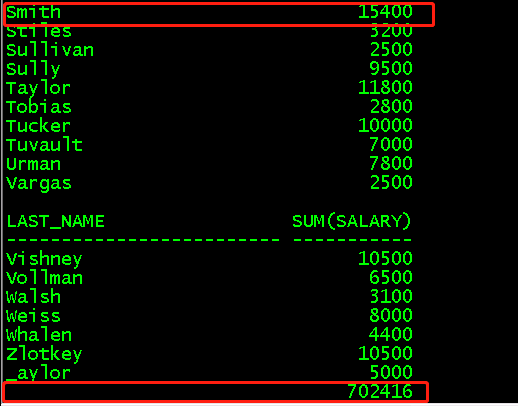
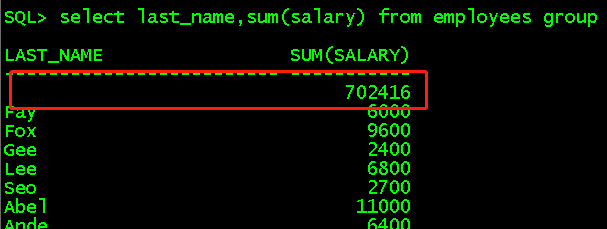
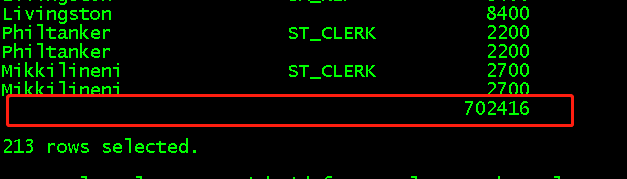
select last_name,job_id,sum(salary) from employees group by rollup(last_name,job_id); //等价于select last_name,job_id,sum(salary) from employees group by last_name,job_id //还有select last_name,sum(salary) from employees group by last_name //最后select sum(salary) from employees group by 0 select last_name,job_id,sum(salary) from employees group by cube(last_name,job_id); //等价于一、select sum(salary) from employees group by 0 //二、select job_id,sum(salary) from employees group by job_id //三、select last_name,sum(salary) from employees group by last_name //四、最后select last_name,job_id,sum(salary) from employees group by last_name,job_id

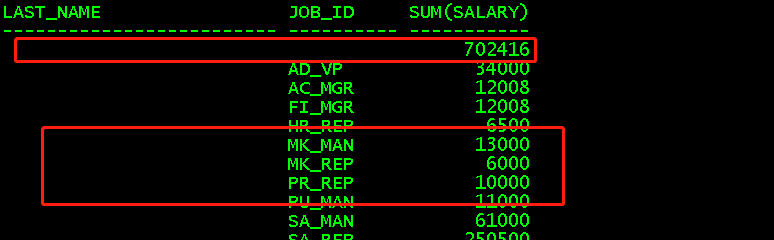
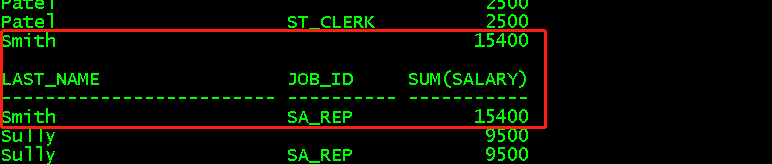
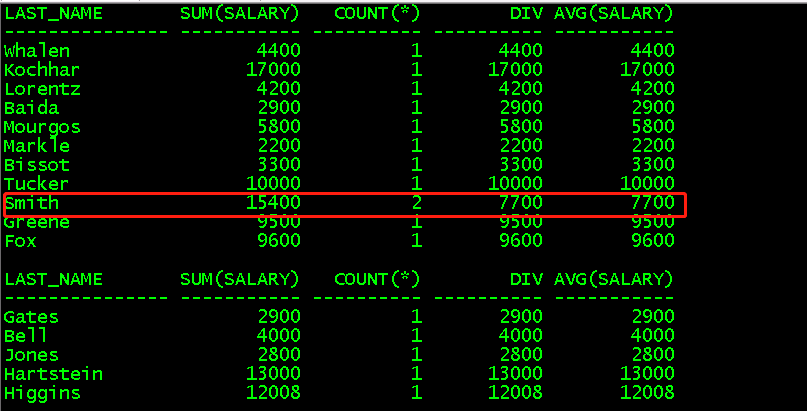
(3)avg()对某一组中的某一列求平均值,使用方法同sum()
select sum(salary),count(*),sum(salary)/count(*) div,avg(salary) from employees; //对整个表求平均值,等价于sum()/个数

select last_name,sum(salary),count(*),sum(salary)/count(*) div,avg(salary) from employees group by last_name;
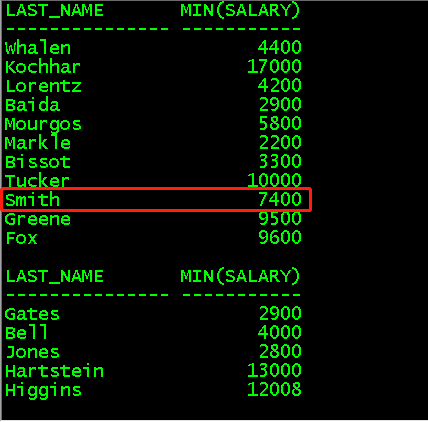
(4)min()函数对某一分组中的某一列求最小值,方法同sum
select last_name,min(salary) from employees group by last_name;
(5)max()函数对某一分组中的某一列求最大值,方法同sum
select last_name,max(salary) from employees group by last_name;
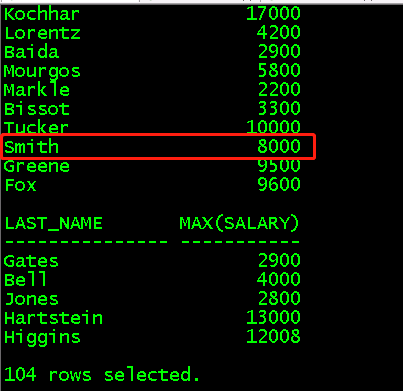
3、分析函数(要显示的字段不必先用group by分组,over(partition by columnA)是对columnA进行分区,over(oder by columnB)是对cloumnB进行累计统计)
(1)count()统计各分区中的个数
select last_name,count(*) over(partition by last_name)count from employees; //查看各个last_name分区有多少行,last_name重复出现
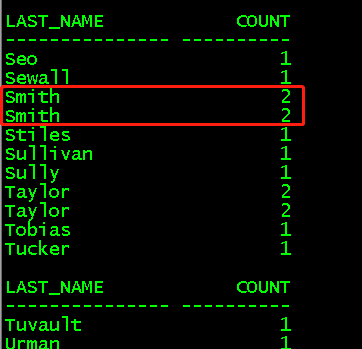
(2)sum()统计各分区中某一列的和
select last_name,salary,sum(salary)over (partition by last_name)sum from employees; //对last_name进行分区,并对各个区进行salary求和,last_name出现多
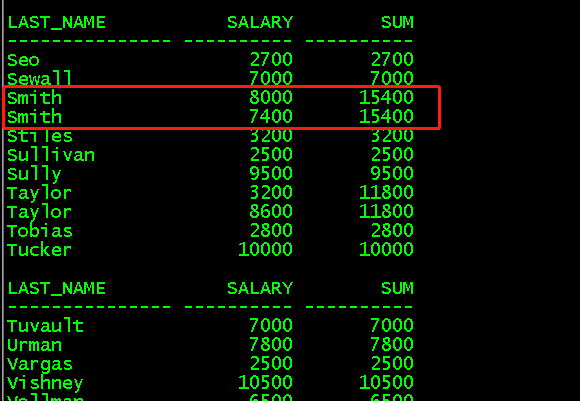
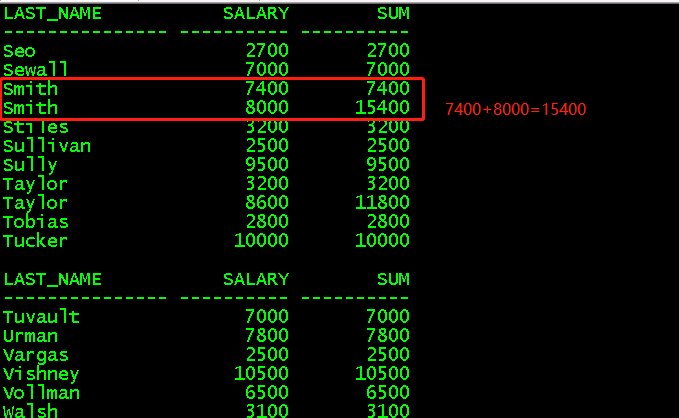
select last_name,salary,sum(salary)over (partition by last_name order by salary)sum from employees; //对last_name进行分区,并根据salary排序累加,last_name出现多次
(3)avg()对各个分区中的某一列求平均值
select last_name,salary,avg(salary)over (partition by last_name)avg from employees; //根据last_name进行分区,求各个分区的平均值
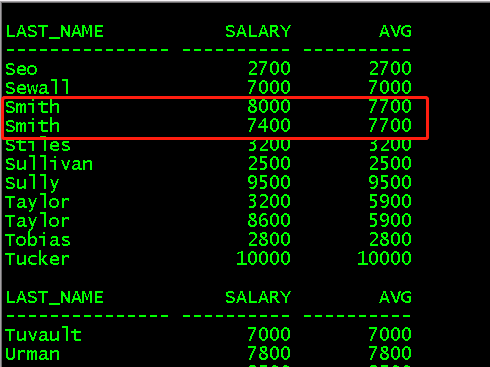
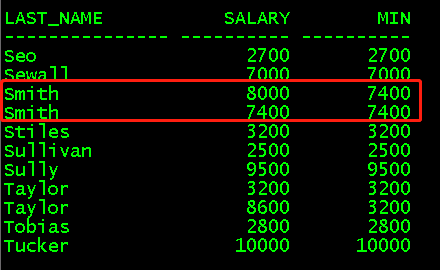
(4)min()对各个分区的某一列求最小值
c/avg/min //将上面的sql中的avg直接替换成min /; //可直接执行替换后的语句 select last_name,salary,min(salary)over (partition by last_name)avg from employees;
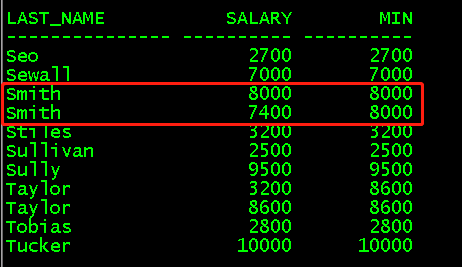
(5)max()对各个分区的某一列求最大值

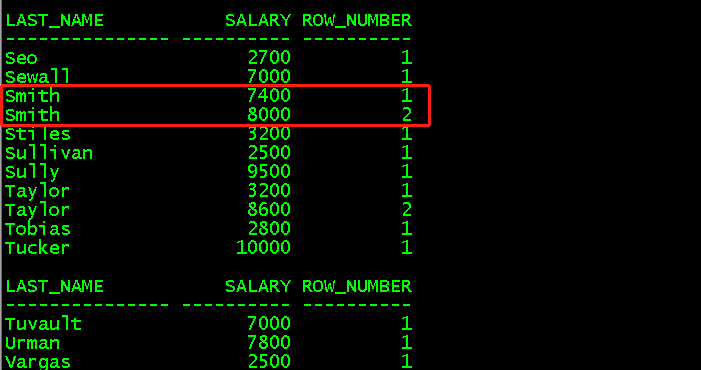
(6)row_number()对数据进行排序,重复值也会分出1,2,3
select last_name,salary,row_number() over (partition by last_name order by salary)row_number from employees; //对last_name进行分区,并对salary进行排序
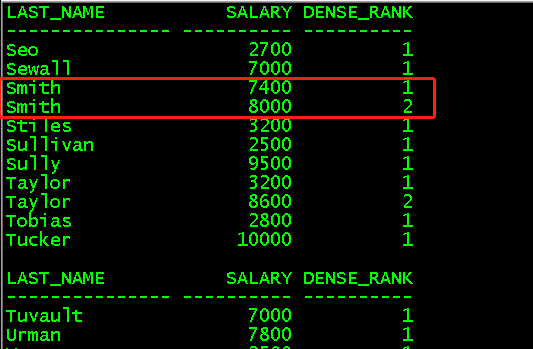
(7)dense_rank()对数据进行排序,重复值不会分出1,2,3
select last_name,salary,dense_rank() over (partition by last_name order by salary)dense_rank from employees;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号