SAP Data Services Designer使用教程
一、作用介绍
1、定时数据抽取
在SAP Data Services Designer可以设置定时从Oracle、Sqlserver、Mysql、Postgresql等数据源库抽取需要的表到另一个库中,抽取包括所有字段及属性。常应用在BI项目中。
2、定时跑存储过程
在SAP Data Services Designer也可以设置定时跑存储过程(oracle)
二、SAP Data Services Designer抽取源表及存储过程(全量抽取:在抽取之前把表所有数据删除,之后再全部抽取过来,增量抽取在第五步)
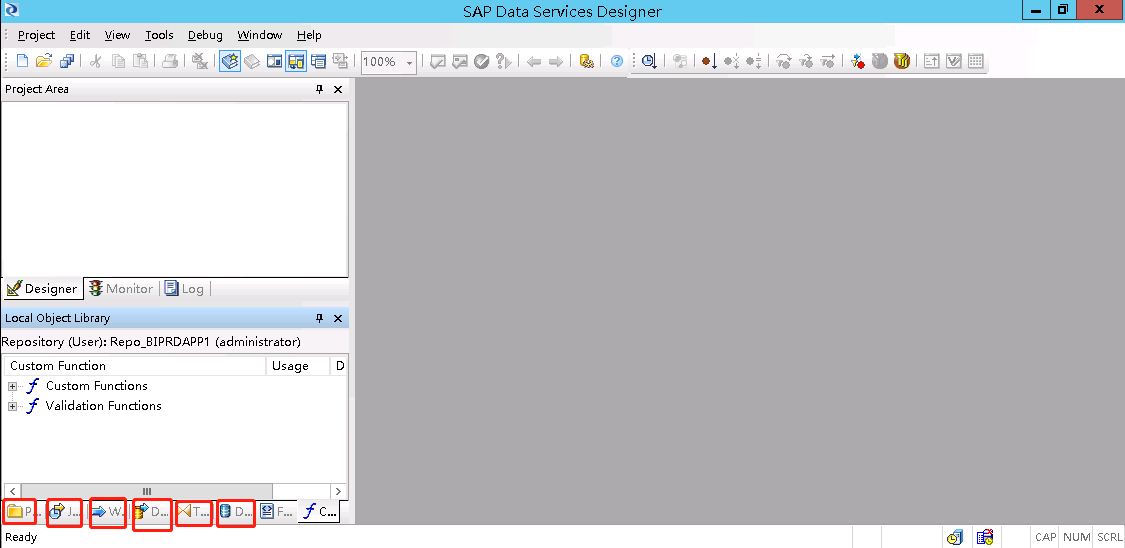
a、Project:项目,下面包含多个Job
b、Job:定时任务,需要在Data Services Management Consoles里面的Batch JobConfiguration进行时间设置,Job下面包含多个WorkFlow,命名规则是JOB_系统_ODS,比如JOB_EHR_ODS。
c、WorkFlow:工作流,下面包含一个DataFlow,命名规则是WF_系统_源表名,比如WF_EHR_BM。
d、DataFlow:数据流,下面包含源表、转换工具、目标表,命名规则是DF_系统_源表名,比如DF_EHR_BM。建立好DF之后可以点击validate,验证一下准确性。
e、Transforms:转换工具,Data Integrator下面包含pivot,Platform下面有merge、query、sql
f、DataStore:数据存储,包括源数据库(数据来源的库)和目标数据库(数据抽取存放的库),命名规则是S_系统或Target_ods或Target_dw,S开头的是源数据库的命名,Target_ods表示数据抽取到ods库,Target_dw表示输出处理后存进dw库。
在对数据进行抽取时,第一步要创建Datastores连接到源库和目标库,在源库里导入需要的源表(Import By Name);
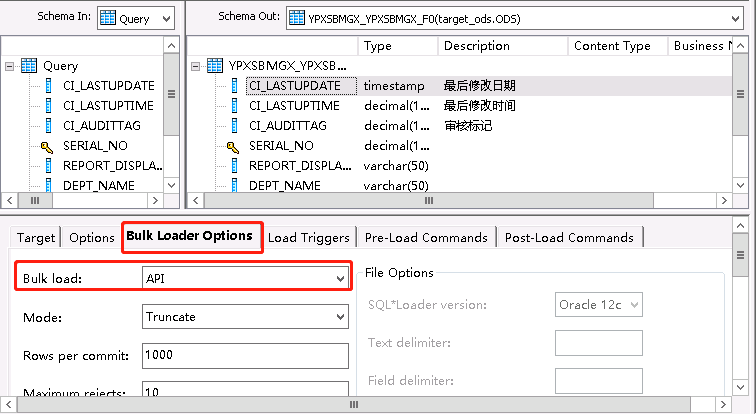
第二步是创建DataFlow,拉入源表,从右边控件栏拉入query组件并把源表里所有字段放入query里,从右边控件栏拉入Template(如果没有目标表就用临时表,之后需要Import Table成为目标表,如果是全量抽取,在Import Table之后抽取目标表之前删除全部数据再重新抽取,就是双击目标表里Bulk Loader Options下的Bulk Load选择API)
第三步是创建WorkFlow,拉入刚刚设置好的DataFlow
第四步是创建Job,拉入创建好的WorkFlow,可以放多个WF,之后到Data Services Management Consoles里设置定时任务
第五步是创建Project,放入多个Job。
创建好的这些控件保存在Repository里,下面是详细步骤:
1、创建Datastores
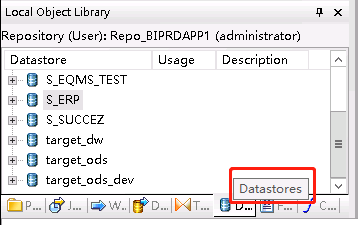
Datastores里面的是源数据库和目标数据库。
a、新建数据库步骤
新建数据库就在datastores里空白区域右击,点击new开始新建。源数据库以S_开头,目标数据库以target_开头。
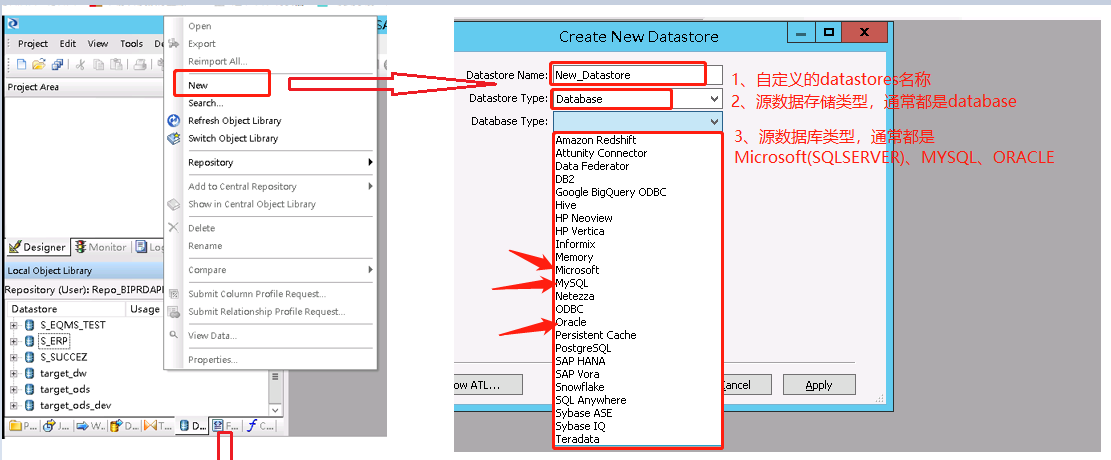
数据库类型是sqlserver
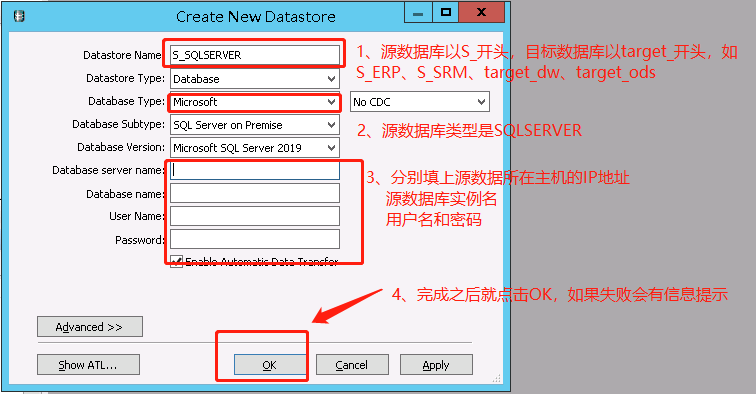
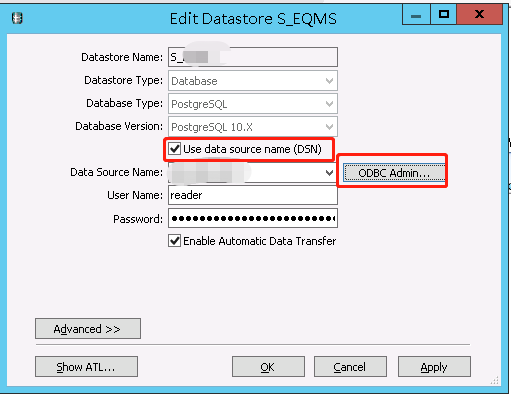
数据库类型是Mysql(这里的名称应该要改掉,如果实际类型是Mysql但是命名成sqlserver会造成歧义);数据库名是root。当数据库类型是Mysql时要选中Use data Source name(DSN)并配置ODBC,方法和下面的PostgreSql一样。之后Data Source Name就选择配置完成的。
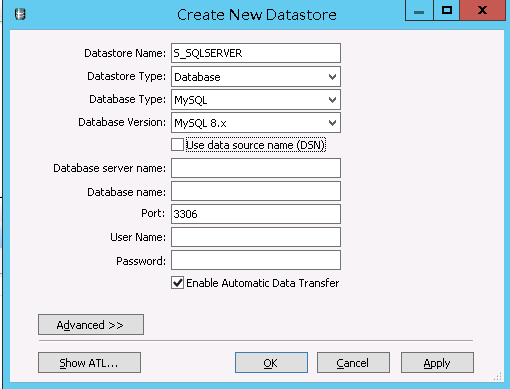
数据库类型是Oracle(这里的名称应该要改掉,如果实际类型是Oracle但是命名成sqlserver会造成歧义);

当数据库类型是PostgreSQL时要选中Use data Source name(DSN)并配置ODBC(Mysql也需要),点击ODBC添加驱动程序。
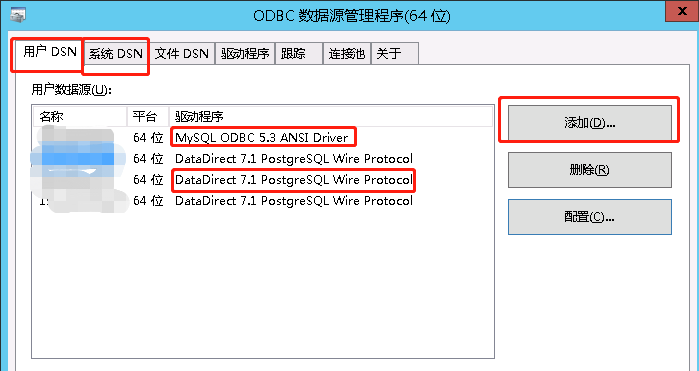
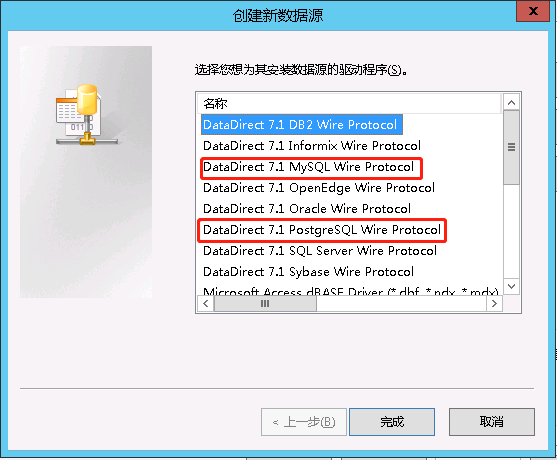
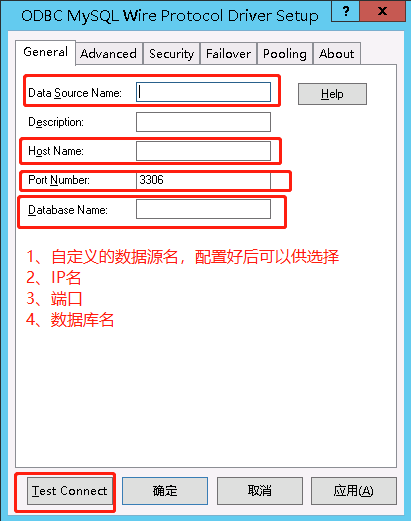
(如果连接出现 [ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序,说明需要下载驱动器,之后再根据驱动器进行连接)
b、导入源数据表
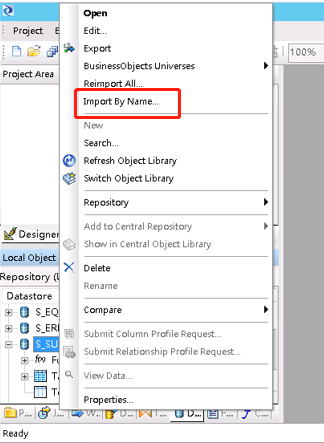
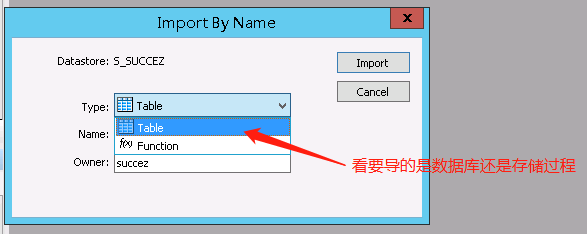
要导入源数据表就右击源数据库S_SUCCEZ,选择Import By Name。

2、创建Data Flows
到DataFlow里右击空白处,选择New->Data Flow。命名规则是DF_系统名_表名,如DF_ERP_TEST。双击DF_ERP_TEST,进入DataFlow工作界面。


a、在datastores选择要抽取的源表,拉倒工作界面。
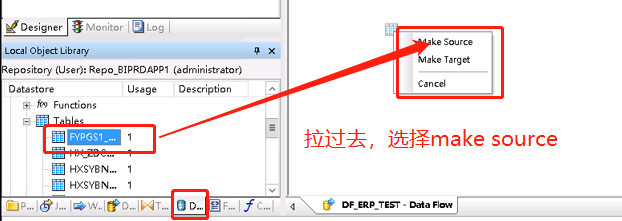
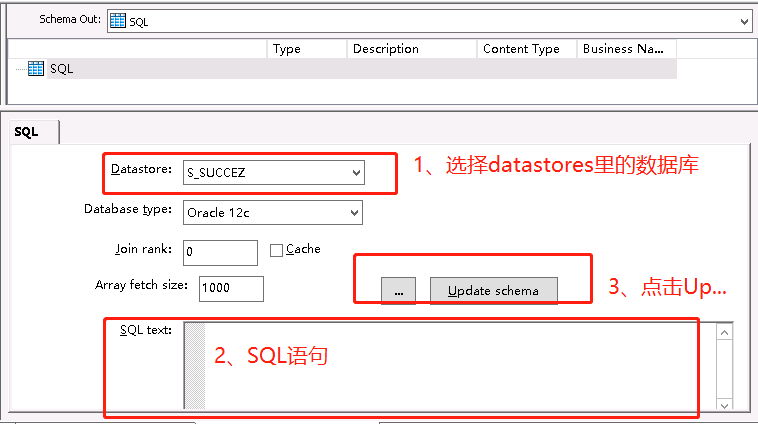
如果不抽取源表的全部信息,可以写SQL进行抽取,SQL控件在下方的TransForm。
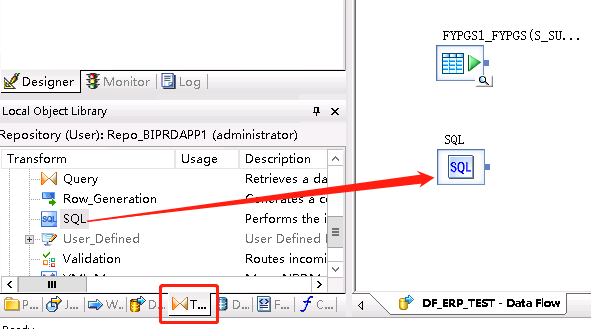
b、先点击Query Transform,之后点击空白处放置一个Query控件,之后连接源表和Query控件,如果不连接点击query控件会出错(也可以不手工连接,右击控件选择Connect to 到相应的后续控件)。

在左边选中要抽取的字段,可以按中shift键然后点击最后一个字段就选中全部了,拉倒Query工作区。
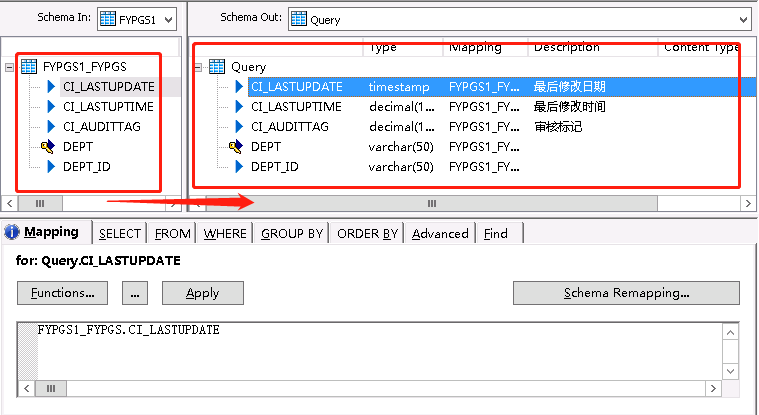
可以点击Find进行字段查询,通常用来查找某字段用来修改该字段的长度(因为Sqlserver和Oracle的varchar可能不同)。

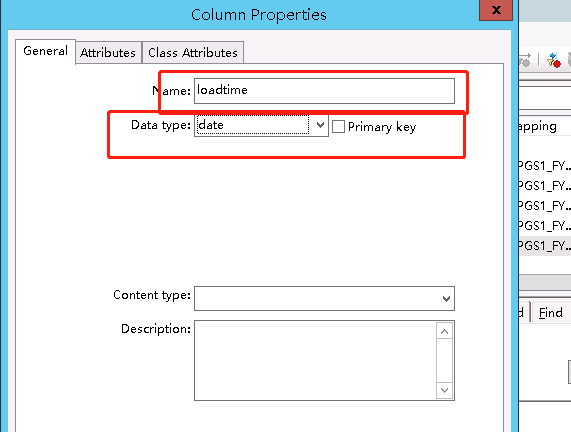
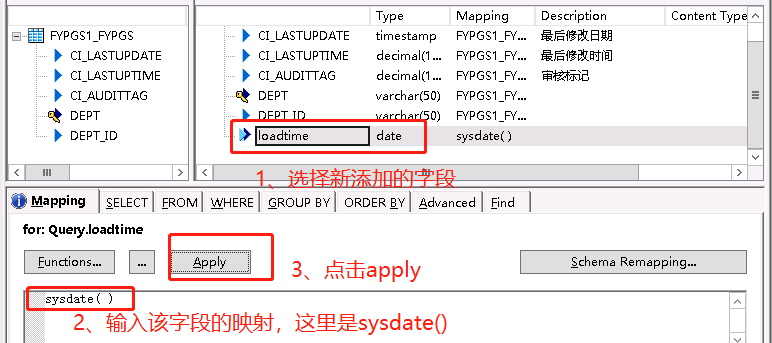
也可以点击New Output Column添加新字段,选择insert below即放在后面,通常添加loadtime即更新时间,将其设置为sysdate()。
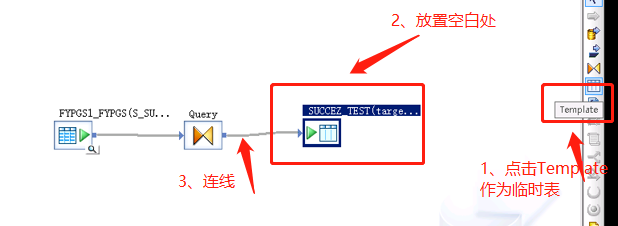
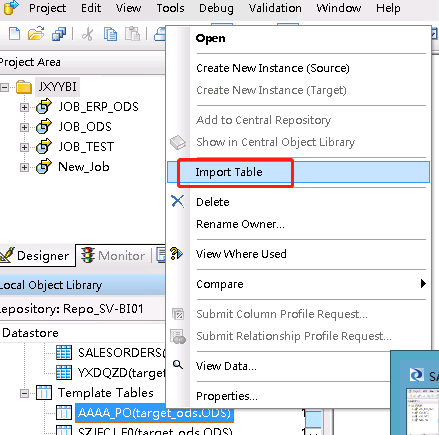
c、新建临时表,作为目标表。在后面运行数据抽取时表还是临时表,需要到DataStores里面的Template Tables右击表,点击Import Table把表变成数据库表。因为是

3、创建Work Flows。
在WorkFlow右击空白处,选择New。命名规则是WF_系统名_表名,如WF_ERP_TEST。双击WF_ERP_TEST,进入WataFlow工作界面。把刚刚新建的DataFlow拉到WorkFlow工作区。
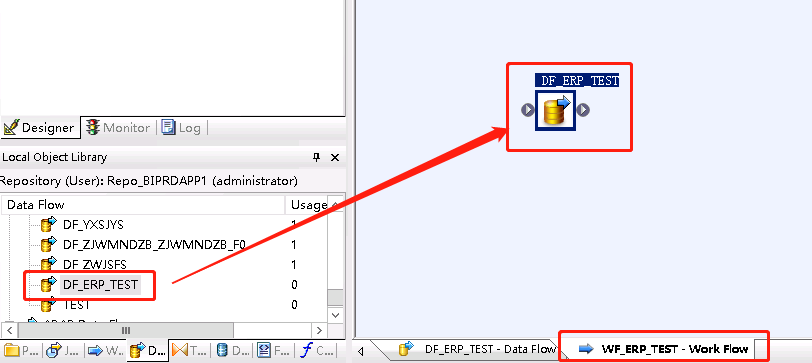
4、创建JOBS。
在JOBS右击空白处,选择New->Batch JOB。命名规则是JOB_系统名_ODS,如JOB_ERP_ODS。双击JOB_ERP_ODS,进入JOB工作界面。把刚刚新建的WorkFlow拉到JOB工作区。
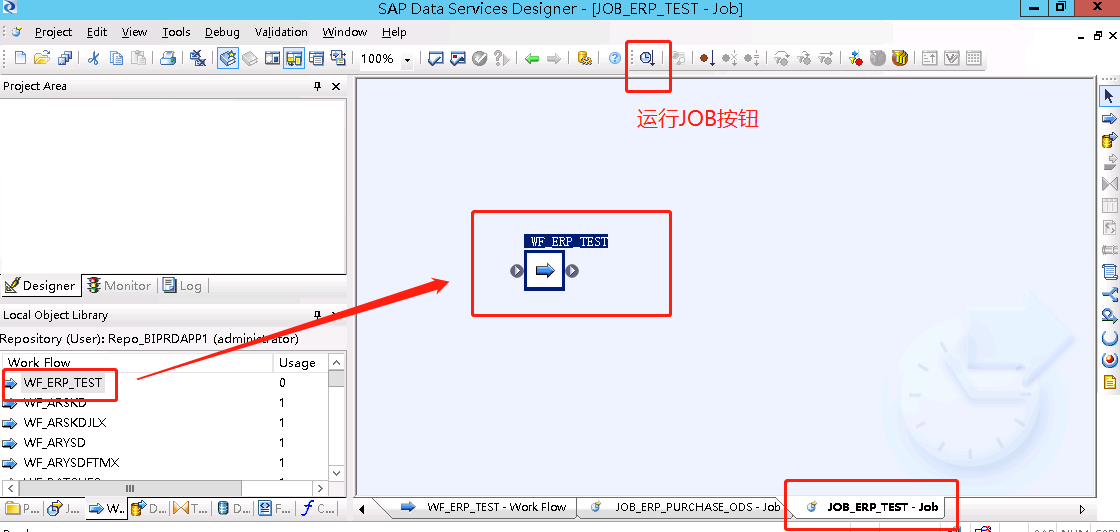
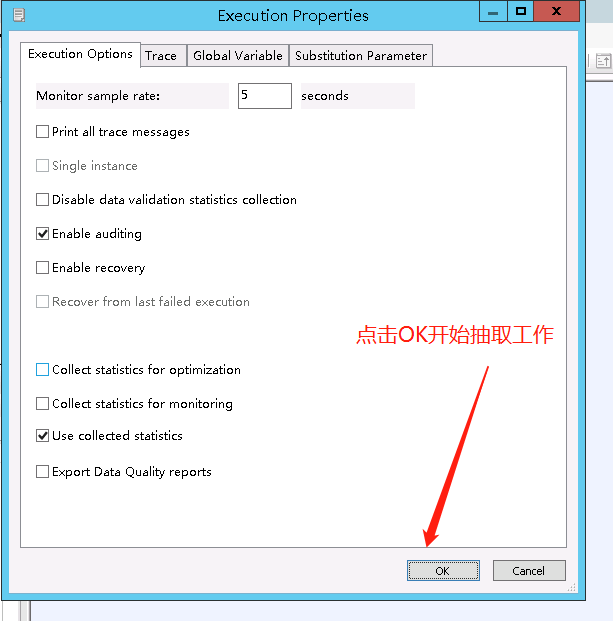
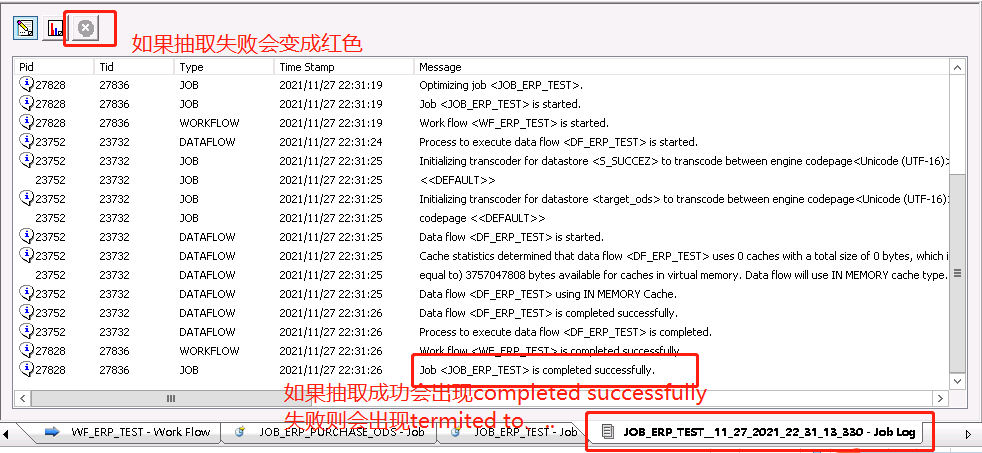
JOB是能独立运行的控件,可以在JOB工作区点击运行JOB控件"Execute..."执行JOB,也可以在Project Area下的Designer窗口右击Job点击Execute执行,运行没有问题之后可以到Data Services Management Consoles设置定时任务(在下面的第三大步)。
5、创建Projects
右击Projects空白处点击new进行新建。
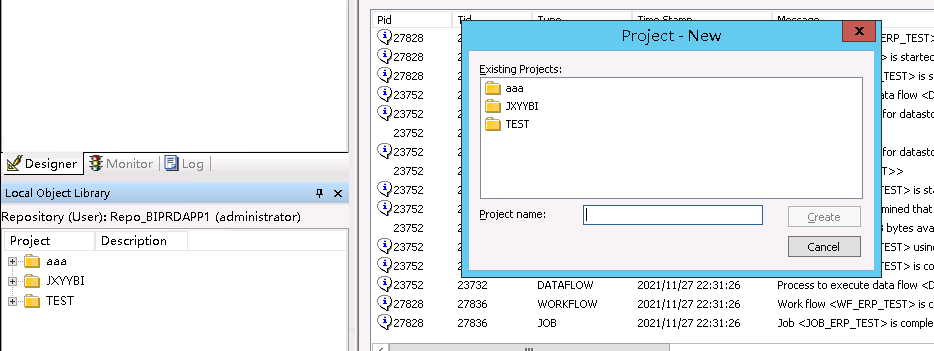
三、定时任务的设置
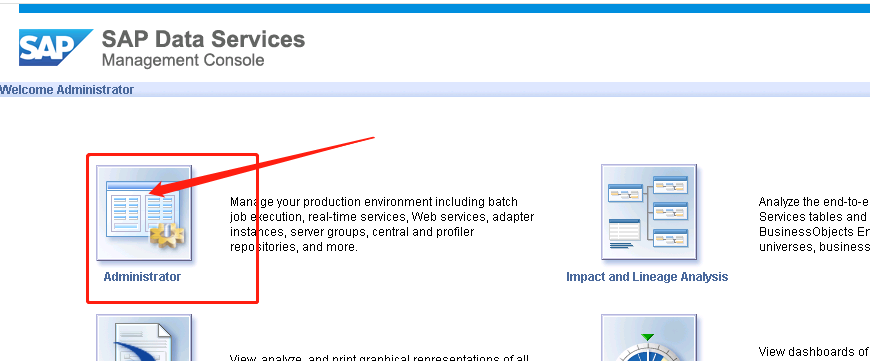
1、登录管理员控制台,填入相关信息

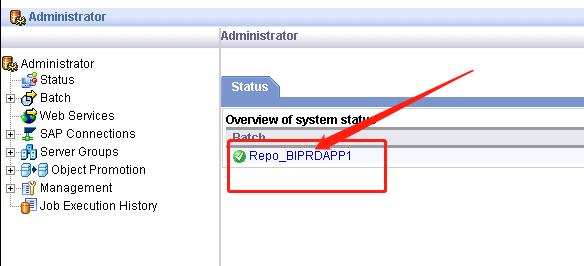
2、点击Administrator->工作台
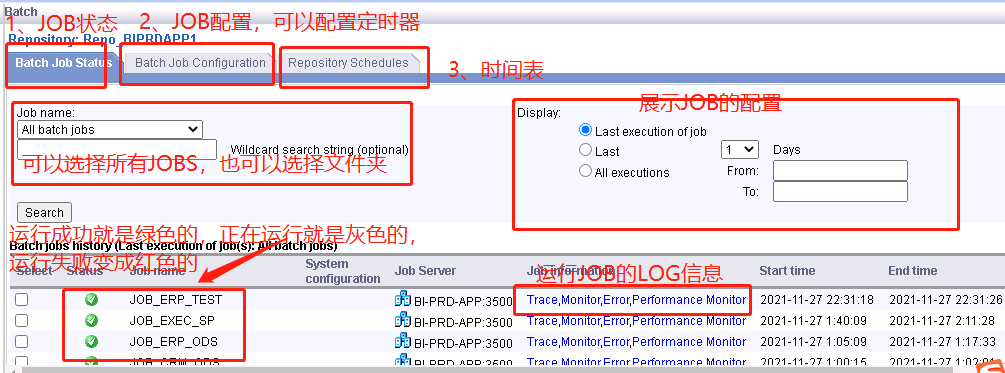
3、JOB相关信息
(下图标注的“可以选择所有JOBS,也可以选择文件夹”那里,不是选择文件夹,而是选择其中一个JOB;Repository Schedules里面就是所有配置的日程表)
4、进入Batch Job Configuration进行JOB配置

5、为JOB设置定时器,设置完最后点击Apply,会有设置成功或失败的提示信息,可能要等久一点才有。
补充:一定要选择active(就在定时任务命名的下面,如果不激活定时任务是不会启动的)
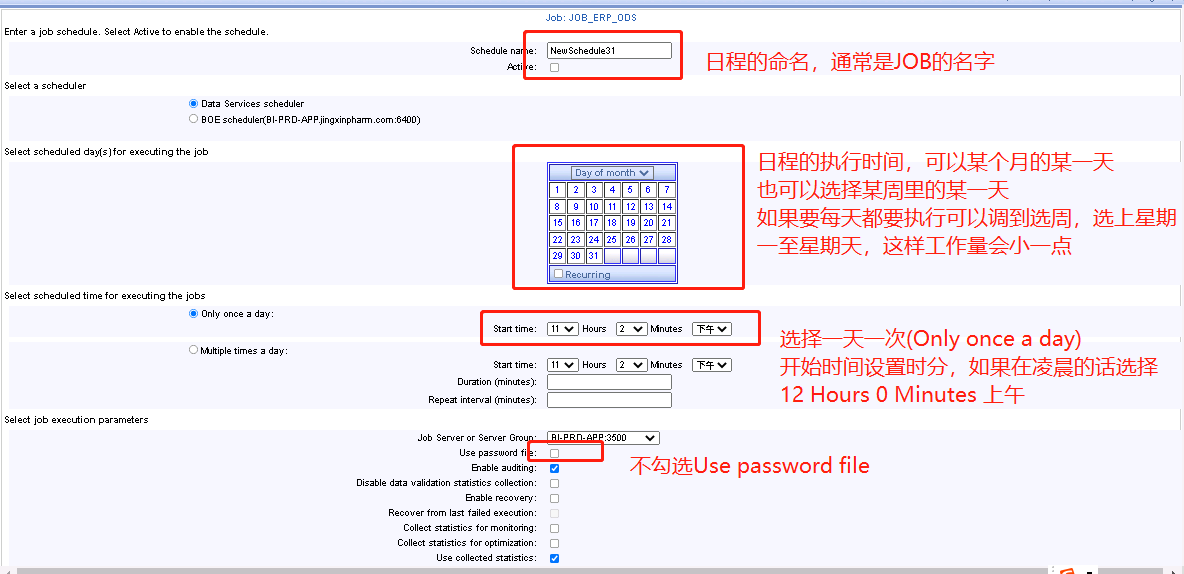
6、某一JOB的日程信息

四、将文件从测试区导到正式区
1、点击JOB,右击选择EXPORT,右边界面出现导出的对象及导出的数据库,右击选择Export to ATL file
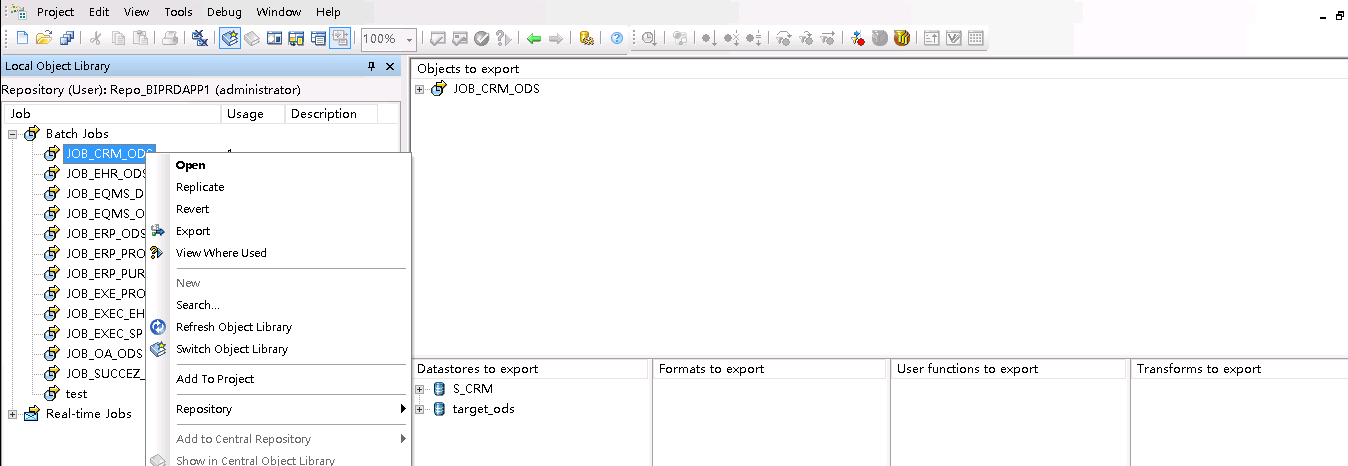
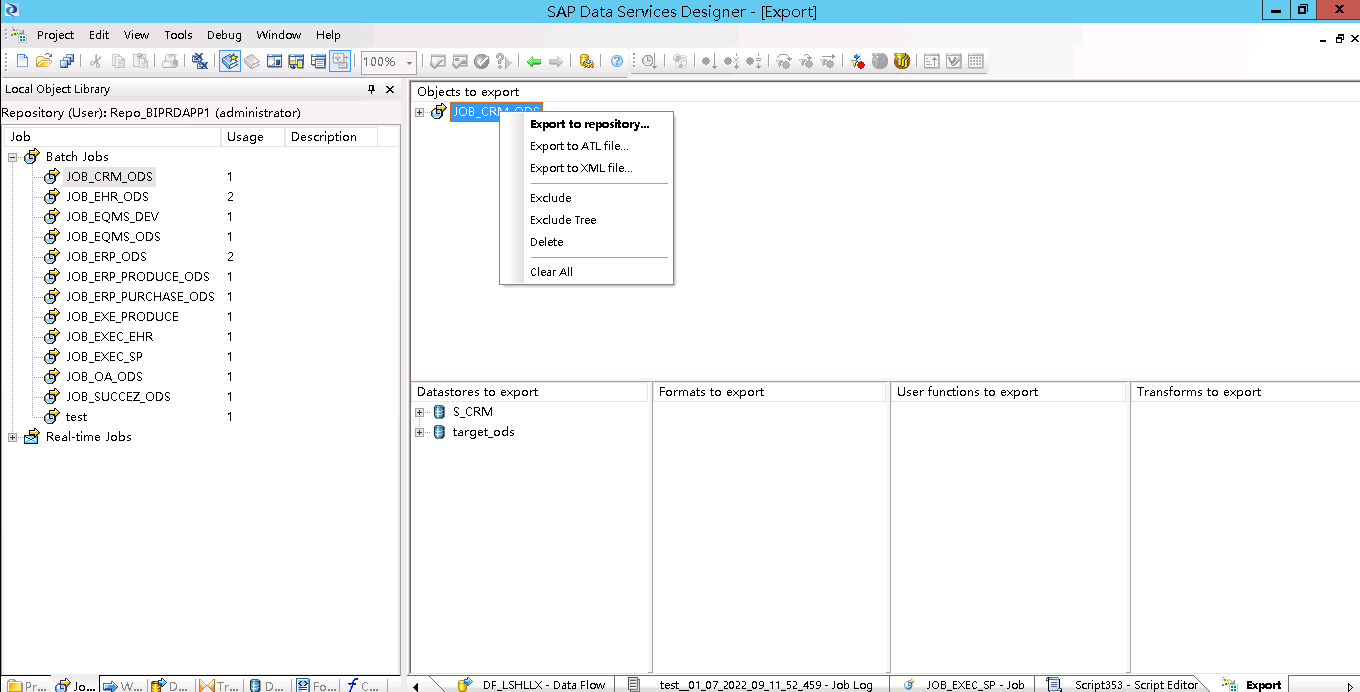
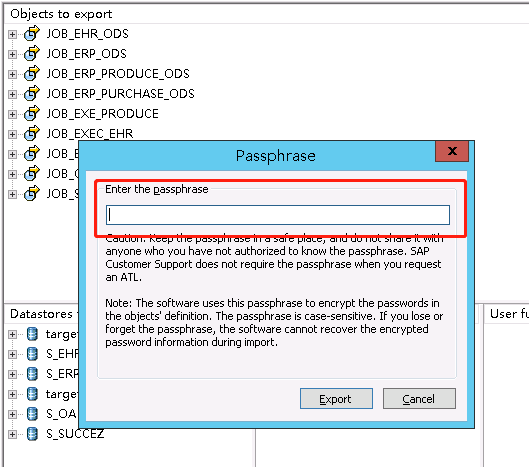
2、导出,设置密码,因为导入的时候需要输入该密码
3、导入,右击选择Repository->Import From File,可以通过EXCLUDE和INCLUDE排除或选择导入的对象和数据库,之后点击Import。导入之后,连接数据库的配置改成正式区。

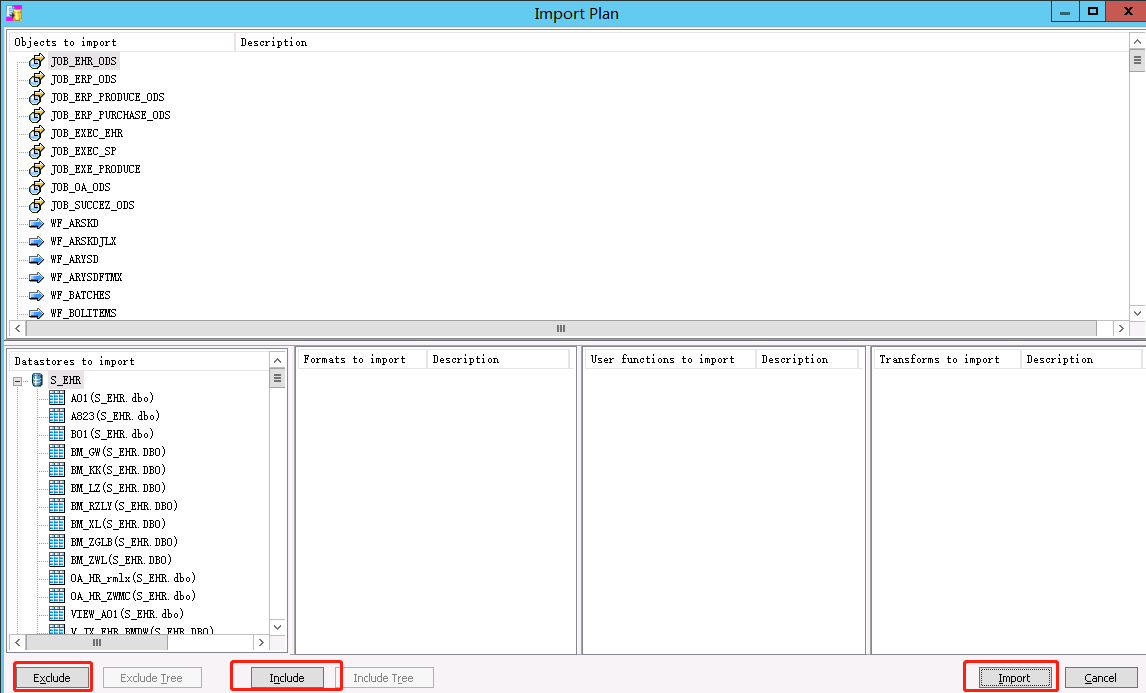
五、增量抽取数据
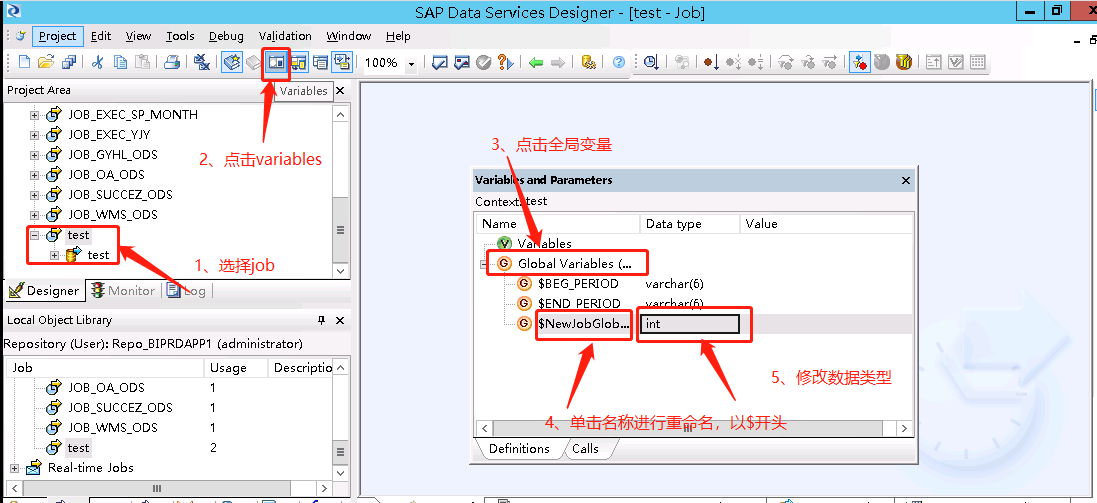
1、选择目标JOB,点击工具栏的Variables,右击Global Variables选择insert,单击变量名称和类型区域进行修改(名称是以$开头),因为这里是以一个月为间隔进行更新,所以数据类型选择varchar(6)。
2、选择目标job,创建脚本(在右侧控件栏),双击脚本给全局变量设置初始值(在每个语句结束后不要忘记 ; 否则会出现错误)
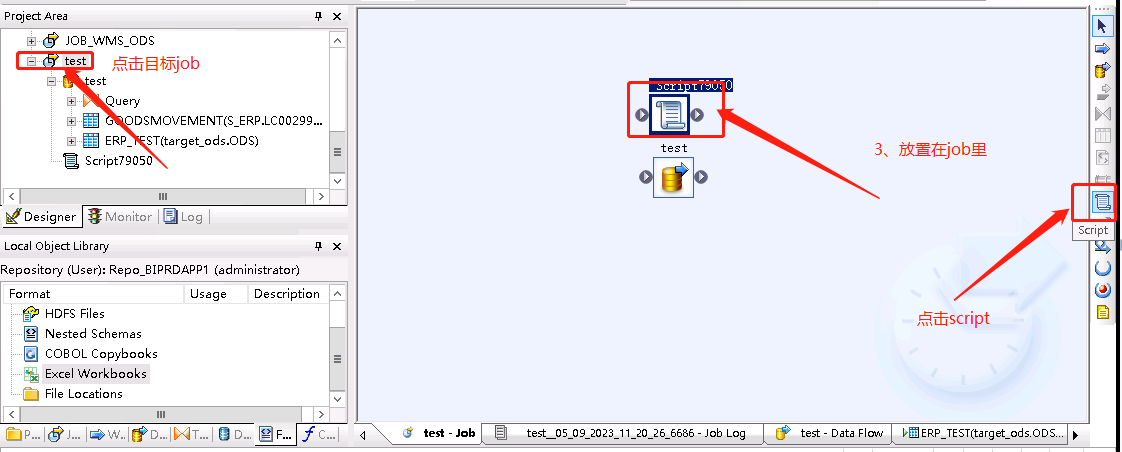
if ($BEG_PERIOD is null) begin $BEG_PERIOD = to_char(add_months( sysdate()-1,-2),'yyyymm'); #更新最近两个月的数据 end begin $END_PERIOD = to_char(add_months( sysdate()-1,-2),'yyyymm'); #更新最近两个月的数据 end print('======BEG_PERIOD is ====== [$BEG_PERIOD]'); #[$variable]输出参数的值
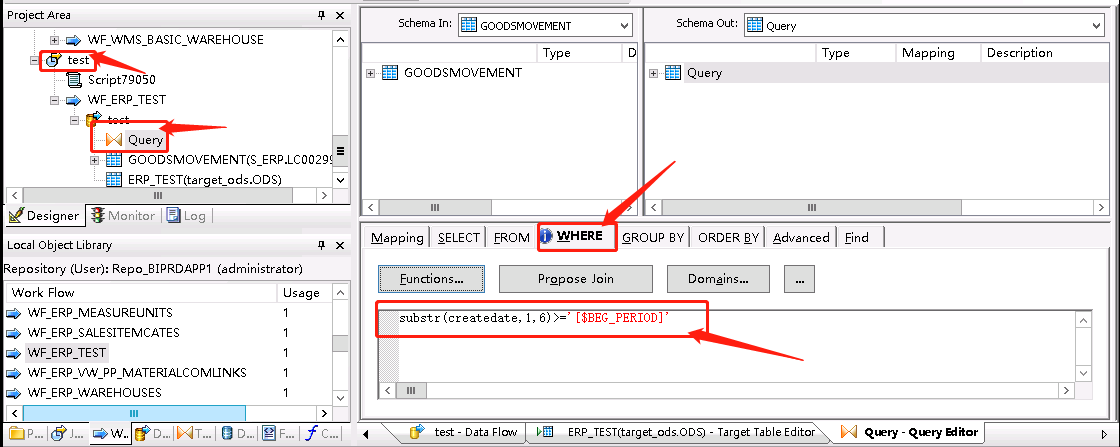
3、打开dataflow里的query组件,在where中使用参数,输入如下语句
substr(createdate,1,6)>=$BEG_PERIOD
4、打开DataFlow中的目标表,点击pre-load-command,使用参数删除数据,点击选择insert before,进度条拉下去可以看到有个value,在里面输入下面的语句
delete from ERP_TEST where substr(createdate,1,6)>='[$BEG_PERIOD]' //要注意这里写的是目标表的表名而不是源表的表名,否则会一直报错违反唯一性
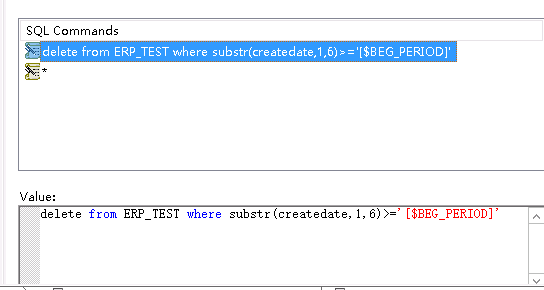
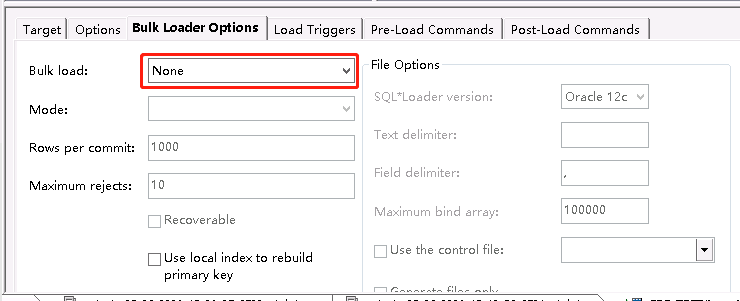
Bulk Loader Options选择None,如果和全量抽取一样的话API-Truncate会删除全表,然后只抽取符合条件的数据。
5、连接脚本和WF,运行JOB
6、验证(在只更新三月以后的数据)
SELECT MAX(CREATEDATE),MIN(CREATEDATE), LOADTIME FROM ODS.ERP_TEST GROUP BY LOADTIME
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号