ORACLE的字典(dba_*,user_*,v$*,all_*类别)查看系统权限和对象权限;sequence、synonyms、index、constraint、view对象;外部表
一、ORACLE的视图区别
1、dba_*视图,如dba_tables,dba_users,dba_objects等,记录了数据库所有的对象信息,是SYSDBA、SYS等拥有dba角色的用户才能查看的基表
2、user_*视图,如user_tables,user_users,user_objects等,记录当前用户的所有对象信息
3、v$*视图,如v$lock,v$session等,动态性能视图。所有者是SYS,管理员可以利用这些动态性能视图了解数据库运行的一些基本信息
4、all_*视图,如all_users,all_objects,记录当前用户的对象信息,以及当前用户可以访问的用户的所有对象信息
5、X$*视图,X$表仅仅驻留在内存中。
静态视图:dba、user、all等开头的视图;动态视图:V$开头的视图,会动态改变。
二、查看用户
desc dict; //全部字典的名称及其注释,字典包括user_、dba_、all_等 select * from dict where table_name like '%TABLE%';
查看所有用户
select * from dba_users; select * from user_users; select * from all_users;

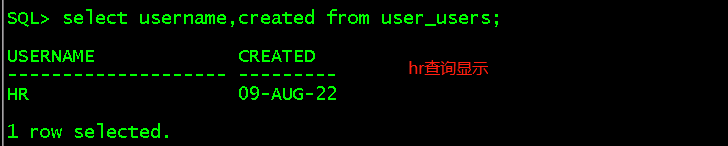
select username,default_tablespace,temporary_tablespace from user_users; //查看当前用户默认的表空间、临时表空间

三、查看所有用户的对象
select owner,object_name,object_type,created,status from dba_objects; //查询所有用户的所有对象,owner筛选用户,object_type筛选对象类型
select object_name,object_type,created,status from user_objects; //查看当前用户拥有的所有对象
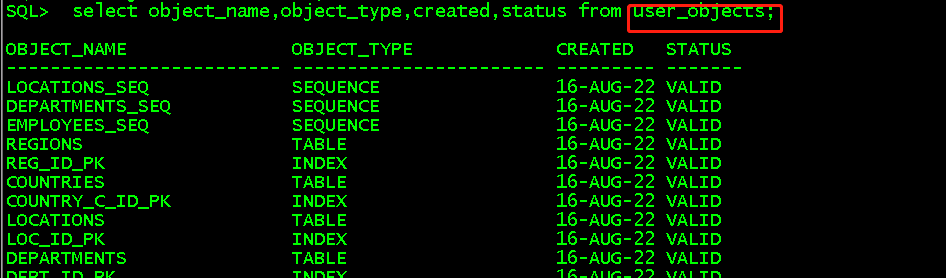
以上对象类型可包含table、view、index、procedure、trigger类型,以上对象都可从user_tables、user_views、user_indexes、user_procedures等各个分表中查询,分表中信息更详细一点。
1、sequence序列的使用(自动提供唯一的数值,共享对象)
序列创建模板(将序列值装入内存可以提高效率),序列号会在rollback、系统崩溃、被其他用户或情况使用的情况下断裂,因为生成保存进内存数据库关闭后序列开始从保存进内存的后面一个值开始;即使事务回滚了序列也不会回滚。
create sequence sequence_name start with start_num increment by increment_num maxvalue max_num|nomaxvalue minvalue min_num|nominvalue cycle|nocycle cache cache_num|nocache order|noorder //start_num是序列开始整数;increment_num是每次增加的整数;max_num是序列最大值;min_num是序列最小值;cycle是循环生产,先将循环的数生成后保存进内存;cache是保存到内存中的整数个数;order是严格按顺序生产 //alter sequence修改序列时不能修改初值;最小值不能大于最大值; //drop sequence sequence_name;删除序列
创建序列
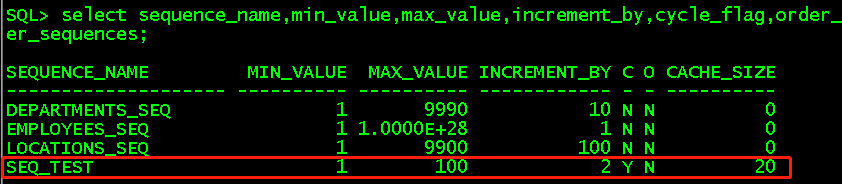
create sequence seq_test; //创建模板,使用默认值 desc user_sequences; //查看序列信息 select sequence_name,min_value,max_value,increment_by,cycle_flag,order_flag,cache_size from user_sequences; //查看序列的默认最小值、最大值、增长步长、循环标志、顺序标志、保存在内存中的个数。

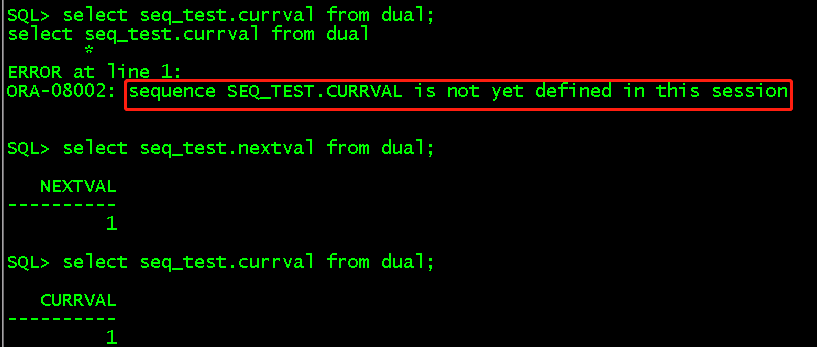
select seq_test.currval from dual; //还未使用nextval之前先使用了currval会出现 "sequence SEQ_TEST.CURRVAL is not yet defined in this session"的错误。 select seq_test.nextval from dual; //默认从1开始 select seq_test.currval from dual; //现在不会出错了 select seq_test.nextval from dual; //默认增长1
alter sequence seq_test increment by 2; //设置增长2 alter sequence seq_test maxvalue 100; //设置最大值为10,保存进内存的数必须少于一轮循环的次数 alter sequence seq_test cycle; //设置循环
select sequence_name,min_value,max_value,increment_by,cycle_flag,order_flag,cache_size from user_sequences;
2、synonym,为对象创建别名
create synonym seq for seq_test; //为seq_test设置别名seq select seq.currval from dual;
desc user_synonyms;
select synonym_name,table_name from user_synonyms;
3、index索引
primary key、unique自带索引;索引加速查询数据(益于select),但是减缓DML语句,因为索引是建立二叉树,DML语句要修改二叉树。索引类型有BTREE索引(根据索引值找rowid)、bitmap索引(位图标记)、函数索引、全文索引
CREATE INDEX emp_department_ix ON employees (department_id); //单一索引:索引列为一列的情况 CREATE INDEX emp_name_ix ON employees (last_name, first_name); //复合索引:索引列为多列的情况 desc user_indexes; //查看索引信息 select index_name,table_name,status from user_indexes;

select index_name,table_name,column_name from user_ind_columns; //查看索引列,以JOB_ID_PK为例
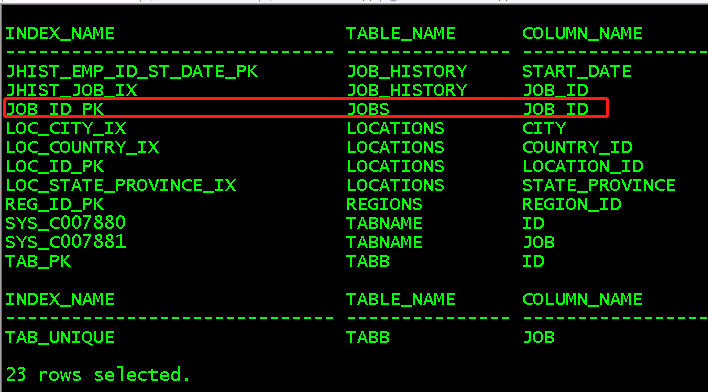
索引可用性,索引可设置为usable和unusable两种状态,当索引是unusable状态时会删除段,优化器不可见,不被dml维护。
select table_name, index_name, status, visibility from user_indexes where index_name = 'JOB_ID_PK'; //查看JOB_ID_PK索引状态时usable select segment_name,segment_type,bytes from user_segments where segment_name='JOB_ID_PK'; //索引的段大小是65536 set autot trace explain; //打印执行性能 select * from jobs where job_id='AD_VP'; //通过索引ID搜索表
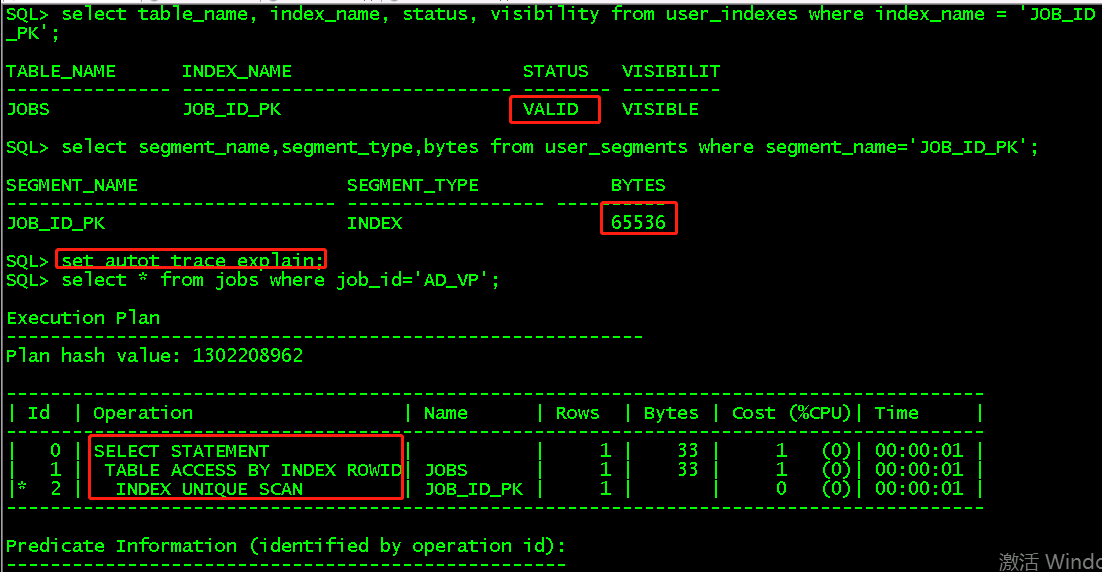
set autot off; //先关闭搜索打印 alter index JOB_ID_PK unusable;//将索引调整成unusable状态,此时对优化器不可见,不被dml维护 select table_name, index_name, status, visibility from user_indexes where index_name = 'JOB_ID_PK'; //查看状态 select segment_name,segment_type,bytes from user_segments where segment_name='JOB_ID_PK'; //查看段大小,发现没有段信息 set autot trace explain; select * from jobs where job_id='AD_VP';
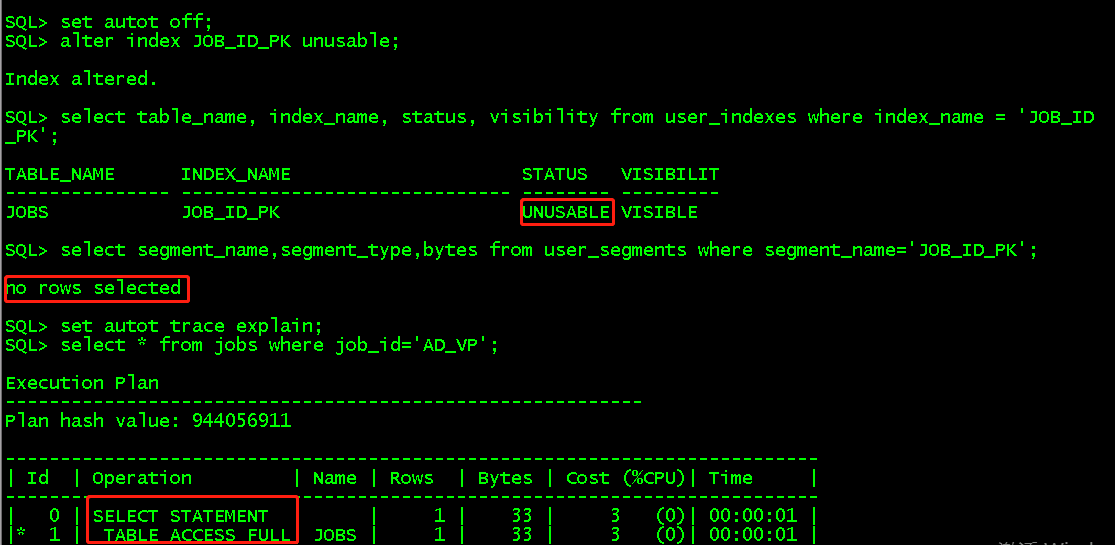
如果需要重新使用索引即将状态从unusable->valid就要重建,这时候有段大小(不可以通过alter index JOB_ID_PK usable将其变成usable状态,会出现错误)。
alter index JOB_ID_PK rebuild; //对索引进行重建 select table_name, index_name, status, visibility from user_indexes where index_name = 'JOB_ID_PK'; //变成valid状态 select segment_name,segment_type,bytes from user_segments where segment_name='JOB_ID_PK'; //有段大小
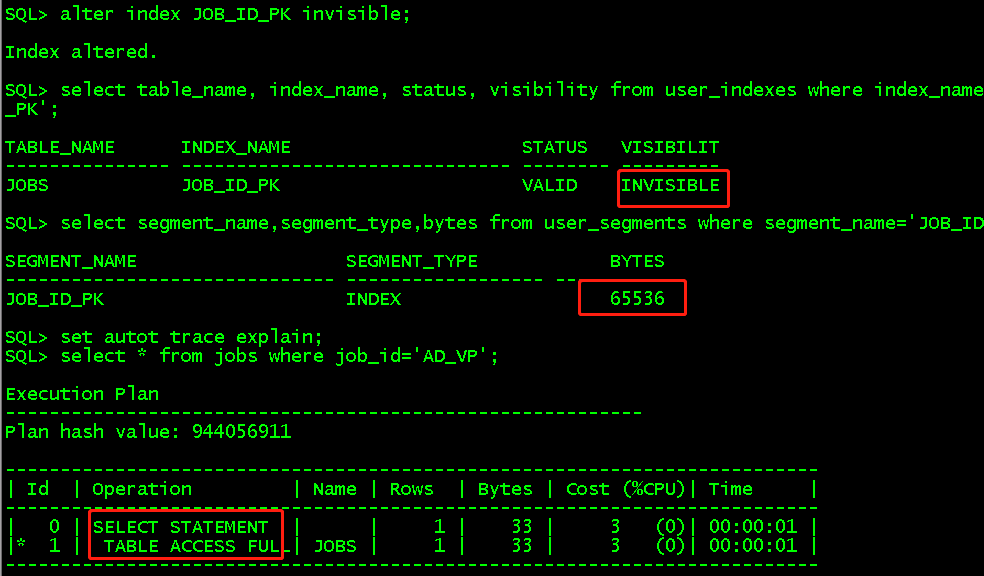
索引可见性,索引可设置为invisible和visible两种状态,invisible状态时段还在,降低删除索引或禁用索引带来的风险,对优化器不可见但继续维护(可通过alter index JOB_ID_PK visible将其变成可视状态)
alter index JOB_ID_PK invisible; select table_name, index_name, status, visibility from user_indexes where index_name = 'JOB_ID_PK'; select segment_name,segment_type,bytes from user_segments where segment_name='JOB_ID_PK'; set autot trace explain; select * from jobs where job_id='AD_VP'; //invisible状态是全表扫描,与unusable不同的是索引段还存在
删除表employees之后连带的约束和index也会被更名,从回收站恢复表之后index命名还是以BIN开头,可以对index进行重命名或者删除重建。检索的行少于大型表的15%,在关联的字段上建议创建索引,在插入数据之后创建索引。适合创建索引的列:值在列中试相对唯一的(如主键);值的范围很广(适合常规索引);有一个小范围的值(适合位图索引);列中包含许多空值,但查询通常选择具有值的所有行。不适合创建索引的列:列中有许多空值而要查找空值的时候,不需要对非空值进行搜索;选择性很差的列,不适合创建常规的btree索引。
4、view视图
视图对基表进行划分,将employees表根据不同部门划分,不同部门用户对不同视图操作,相当于划分了权限。视图对数据进行限定;逻辑数据独立性;查询简化。
简单视图包含一个表,不包含函数,不包含组合数据,可以DML;复杂视图包含一个或多个表,包含函数,包含组合数据,不一定能DML。
创建视图模板
create or replace [force|noforce] view view_name as subquery with check option constraint with read only; //or replace如果存在同名视图就替换 //force表示强制创建视图,不管基表存不存在或者有无基表的权限 //with check option constraint表示对基表的DML必须满足视图子查询的权限,即DML的数据必须是select查询能够查到的数据 //with read only只允许查询数据,不允许DML
create or replace view viewname as subquery; //创建视图,subquery不能包含order by select * from session_privs where privilege like '%VIEW%'; //查看用户是否具有创建视图的权限,或者通过user_sys_privs查看 grant create view to username; //如果没有权限就授予权限 //在视图上的限制,在视图上 //使用分组函数、group by、distinct、rownum伪列后不能delete视图行数据 //使用分组函数、group by、distinct、rownum伪列、表达式(加减乘除)后不能update视图行数据 //使用分组函数、group by、distinct、rownum伪列、表达式(加减乘除)、非空约束后不能insert视图行数据 select view_name,read_only from user_views; //查看视图
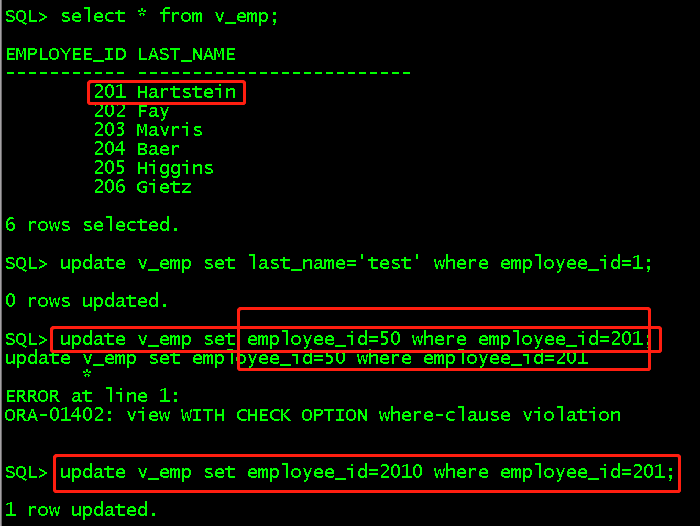
with check option constraint的测试(建立视图查询i大于200的员工)
create or replace view v_emp as select employee_id,last_name from employees where employee_id >200 with check option constraint v_emp_ck; select * from v_emp; update v_emp set employee_id=50 where employee_id=201; //将id从201修改成50就会出现错误,因为50不在大于200范围 update v_emp set employee_id=2010 where employee_id=201; //修改成2010就成功,数据插入也是一样的
5、constraint约束
约束有五种:not null(行级约束)、unique、primary key、foreign key、check,同一用户下约束不能重名;表删除时该表的约束也一并删除;
行级约束:建表时,声明字段与字段属性的同时紧跟其后声明约束
表级约束:建表时,声明字段与字段属性后再单独声明约束
create table tabname(id number(6) primary key, lastname varchar2(10) not null, eid number(6) references employees(employee_id),salary number(8,2) check(salary>0),job varchar(20) unique);
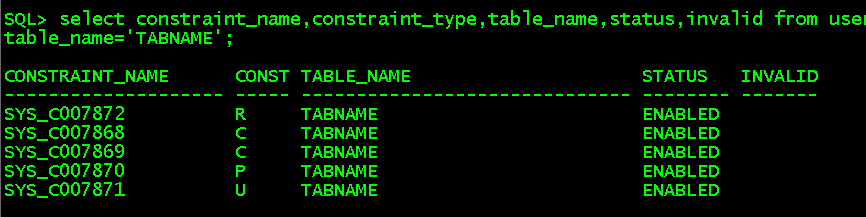
//行级约束语法,not null不能写成表级约束 select constraint_name,constraint_type,table_name,status,invalid from user_constraints where table_name='TABNAME';
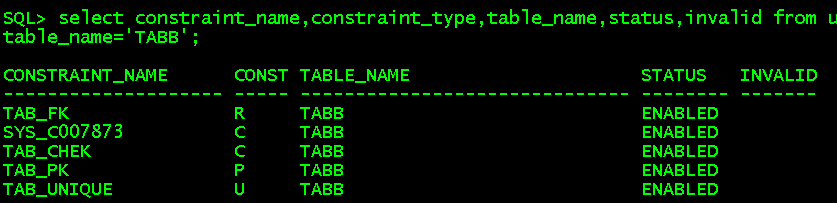
//未指定命名就系统默认SYS_开头,R是foreign key;C是check或not null;P是primary key;U是unique create table tabB(id number(6),constraint tab_pk primary key(id), lastname varchar2(10) not null, eid number(6), constraint tab_fk foreign key(eid) references employees(employee_id),salary number(8,2), constraint tab_chek check(salary>0), job varchar(20),constraint tab_unique unique(job));
//表级约束 select constraint_name,constraint_type,table_name,status,invalid from user_constraints where table_name='TABB';
以上约束也可以通过alter table tabname add constraint 来创建
alter table tabname add constraint con_fk foreign key(eid) references employees(employee_id) ;on delete cascade |on delete set null,on delete cascade表示删除主键,参照该主键的外键表的数据也被删除了;on delete set null表示删除主键,参照该主键的外键表的数据被设置成null(前提是该字段允许为null)。
select constraint_name,constraint_type,table_name,status,validated from user_constraints where table_name='TABB'; //查看约束的status、validated状态 status validate参数如下: enable validate 约束新数据并验证已有数据 enable novalidate 约束新数据,但不验证已有数据 disable validate 关闭约束,不能进行DML disable novalidate 关闭约束,不验证已有数据
defferable表示约束是否可以在deferred和immediate之间转换,deferrable可以转换,not deferrable不可以转换;
initially immediate deferrable每条子句结束后验证,且immediate可以转换为deferred;initially deferred deferrable在事务提交时验证,且deferred可以转换为immediate;
6、table多表插入
无条件的insert all,将数据源的每一行插入所有目标表中
create table empinfo as select employee_id,first_name,last_name from employees where 1=2; //个人信息表,保存工号、姓名 create table empwork as select employee_id,hire_date,salary from employees where 1=2; //工作信息表,保存工号、聘用日期、薪资 insert all into empinfo values(employee_id,first_name,last_name) into empwork values(employee_id,hire_date,salary) select employee_id,first_name,last_name,hire_date,salary,department_id from employees where department_id=50;
有条件的insert all,将数据源中满足条件的行插入目标表中,一行能满足多个条件,所以可能插入多个目标表
insert all
when department_id<100 then into empinfo values(employee_id,first_name,last_name) when hire_date is null then into empwork values(employee_id,hire_date,salary) select employee_id,first_name,last_name,hire_date,salary,department_id from employees;
有条件的insert first,将数据源中的行插入满足条件第一个目标表中,之后不再判断
insert first when salary <5000 then into empinfo values(employee_id,first_name,last_name) else into empwork values(employee_id,hire_date,salary) select employee_id,first_name,last_name,hire_date,salary from employees;
pivot insert 将列表示的数据换成行来表示
create table sal(empid number,weekid number,sal_mon number,sal_tues number,sal_wed number,sal_thur number,sal_fri number); insert into sal values(300,6,2000,3000,4000,5000,6000); create table sale_info(empid number,week number,sales number); insert all into sale_info values(empid,weekid,sal_mon) into sale_info values(empid,weekid,sal_tues) into sale_info values(empid,weekid,sal_wed) into sale_info values(empid,weekid,sal_thur) into sale_info values(empid,weekid,sal_fri) select empid,weekid,sal_mon,sal_tues,sal_wed,sal_thur,sal_fri from sal;
临时表有全局临时表和私有临时表,全局临时表分基于事务临时表和基于会话临时表,其他会话可见,表定义存在数据字典中,事务或会话删除时数据删除,但是表定义还存在。私有临时表存储在内存中,仅对创建它的会话可见,在事务或会话结束时自动删除数据和表定义,必须以ORA$PTT_为前缀,这个前缀由private_tmp_table_prefix控制,表定义仅存在内存中,不能在sys用户下创建私有临时表,否则会出现“unsupported feature with temporary table”这样的错误。
全局临时表的创建
CREATE GLOBAL TEMPORARY TABLE cart(n NUMBER,d DATE) ON COMMIT DELETE ROWS; //基于事务临时表,后面写的commit delete rows就是在事务提交之后删除所有行 select * from tab; insert into cart values(1,sysdate); select * from cart; commit; select * from cart;
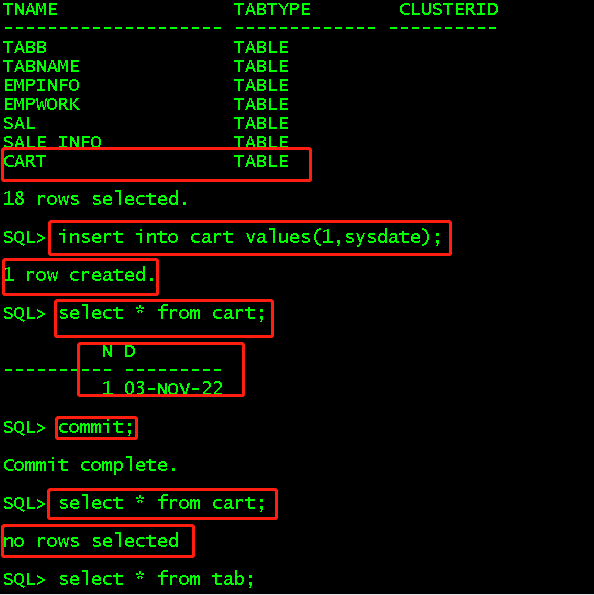
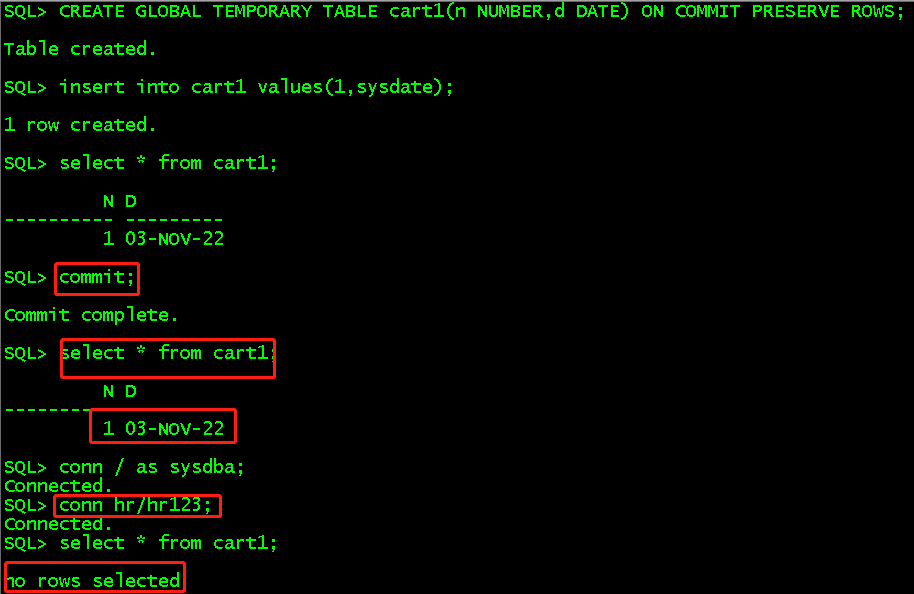
CREATE GLOBAL TEMPORARY TABLE cart1(n NUMBER,d DATE) ON COMMIT PRESERVE ROWS; //基于会话临时表,在commit之后保存行,但是会话结束之后删除行 insert into cart1 values(1,sysdate); select * from cart1; commit; select * from cart1; //commit只有查询还是有数据 conn / as sysdba; //退出会话 conn hr/hr123; //创建新会话 select * from cart1; //查询没有数据了,但是这时候表结构还存在
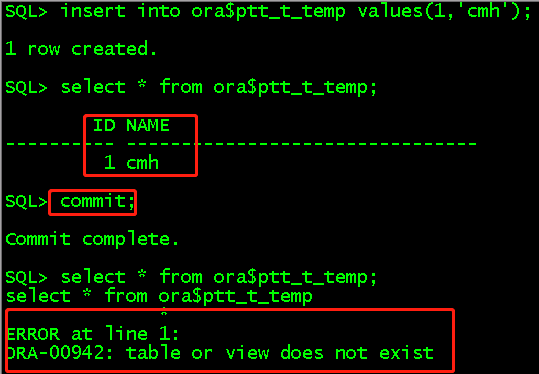
create private temporary table ora$ptt_t_temp(id int,name varchar2(32)) on commit drop definition; //创建私有临时表,基于事务的临时表,在commit之后删除数据和表结构 select * from tab; //tab查询不出来表名 insert into ora$ptt_t_temp values(1,'cmh'); select * from ora$ptt_t_temp; cimmit; select * from ora$ptt_t_temp; //commit之后查表会报错,因为表不存在
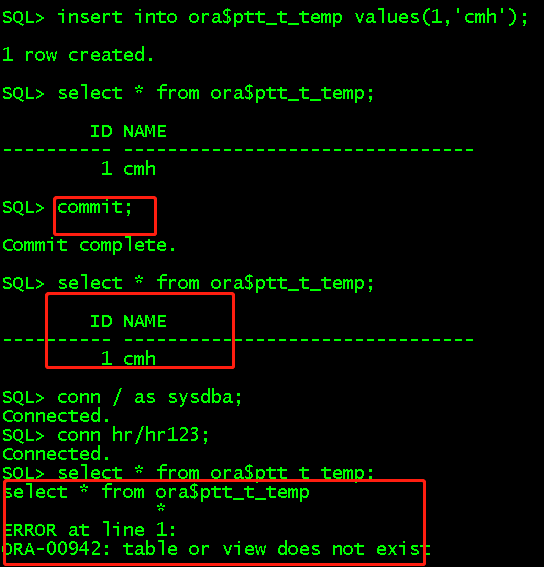
create private temporary table ora$ptt_t_temp(id int,name varchar2(32)) on commit preserve definition; //创建基于会话的私人临时表,在commit之后保存表结构和数据,但是打开新会话后查询不到该表 insert into ora$ptt_t_temp values(1,'cmh'); select * from ora$ptt_t_temp; commit; select * from ora$ptt_t_temp; //commit之后表和数据都还存在 conn / as sysdba; conn hr/hr123; //打开新会话 select * from ora$ptt_t_temp; //查询数据报错
外部表:是一种只读表,它的表定义存储在数据库中,但数据存储在数据库外部的文件中。外部表不能是临时文件、不能指定约束、不能创建索引、不能包含虚拟列或不可见列不能执行DML语句,包含ORACLE_LOADER(默认)和ORACLE_DATADUMP两种驱动。语法是create table tablename ...organization external。type是设置的驱动类型,默认ORACLE_LOADER,只能是文本文件,可将数据从外部表加载到内部表,不能从内到外,即不同通过该驱动导出数据。ORACLE_DATADUMP执行数据的加载和卸载,数据必须来自二进制文件,可以通过这种方式导出数据。DEFAULT DIRECTORY是所有输入输出使用的默认目录。LOCATION是指定外部表的数据文件。
在/tmp/test.txt文件中放入三条测试数据
1,chen,5000 2,mu,6000 3,yang,7000
ORACLE_LOADER驱动
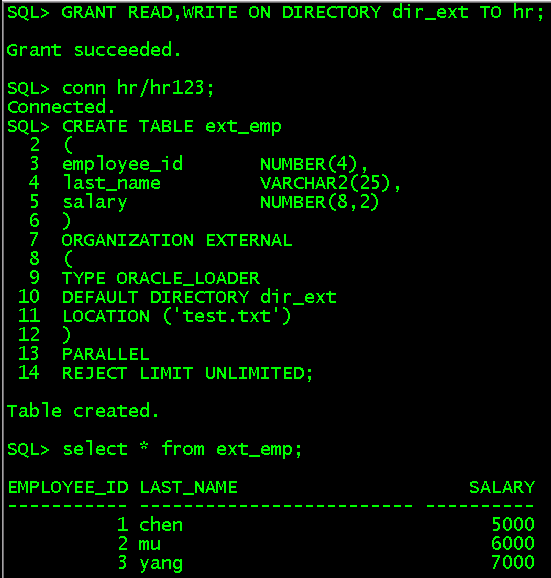
CREATE OR REPLACE DIRECTORY dir_ext AS '/tmp'; //在sys用户下创建目录指向/tmp GRANT READ,WRITE ON DIRECTORY dir_ext TO hr; //授权hr读写这个目录的权限 conn hr/hr123; CREATE TABLE ext_emp ( employee_id NUMBER(4), last_name VARCHAR2(25), salary NUMBER(8,2) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_LOADER DEFAULT DIRECTORY dir_ext LOCATION ('test.txt') ) PARALLEL REJECT LIMIT UNLIMITED;

ORACLE_DATADUMP驱动,将上面的数据通过ORACLE_DATADUMP驱动导出二进制数据,因为该驱动只支持二进制。
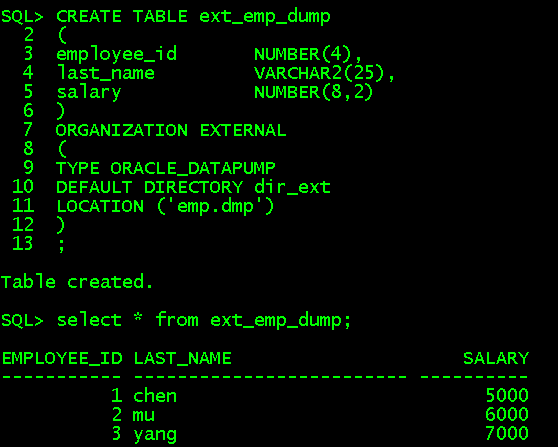
CREATE TABLE out_emp ORGANIZATION EXTERNAL ( TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY dir_ext LOCATION ('emp.dmp') ) as select * from ext_emp;
更换表名exp_emp_dump、TYPE=ORACLE_DATAPUMP、LOCATION=('emp.dmp')即刚刚导出的二进制文件
CREATE TABLE ext_emp_dump ( employee_id NUMBER(4), last_name VARCHAR2(25), salary NUMBER(8,2) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY dir_ext LOCATION ('emp.dmp') ) ;
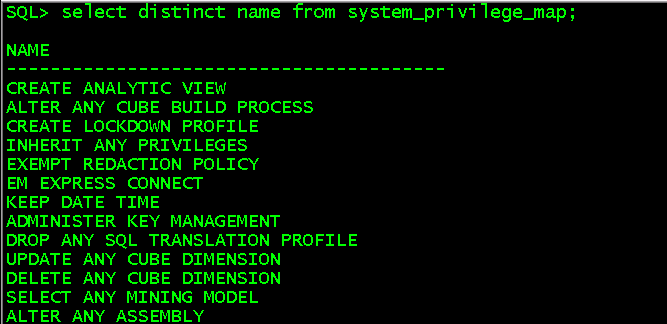
四、查看用户、角色拥有的系统权限(系统权限是对oracle系统的操作权限,比如开库和关库、创建表和删除表等DDL语句)
select distinct name from system_privilege_map; //查看所有的系统权限种类,当用户没有被授予session权限时不可登录
select * from dba_sys_privs; //查看所有用户拥有的系统权限

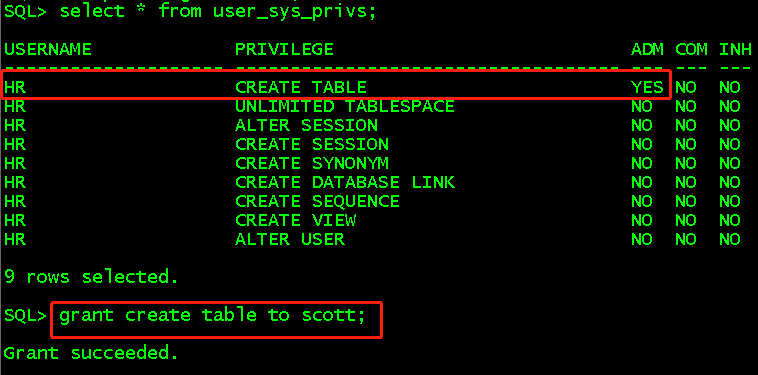
系统权限包括create table、create view、alter user、drop table等,在进行某些操作如果没有这些权限会报权限不足。
admin_option是表示当前用户是否有权利把该权限授予其他用户,grant create table to hr with admin option,权限不会被级联回收,在sys用户下授予hr用户create table权限,并且允许hr将这个权限授予其他用户。
select 'revoke '||privilege||' on '||owner||'.'||table_name||' from '||grantee||';' revSQL from dba_tab_privs where grantee='HR'; //收回授予hr在用户owner的table_name上的权限的语句

select * from dba_sys_privs where grantee='RESOURCE'; //查看resource拥有的系统权限
//等价于select * from role_sys_privs where role='RESOURCE';
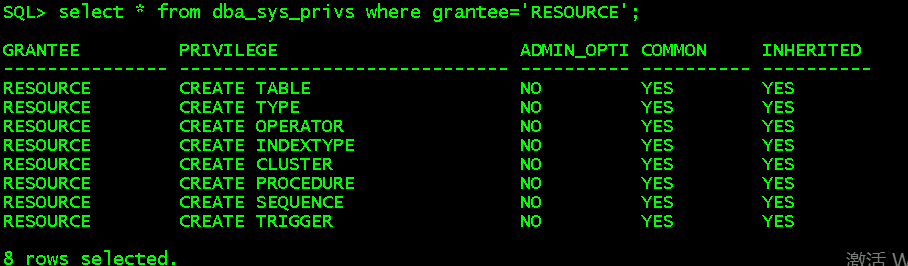
select * from user_sys_pribs; //查看用户自己拥有的系统权限

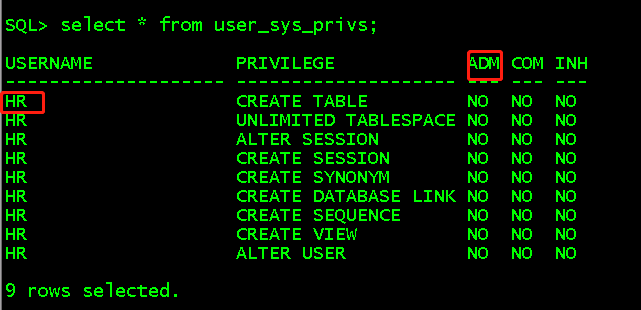
select * from role_sys_privs; //查看hr用户所有角色拥有的系统权限
注意:分配权限在满足需求的前提下应该遵守最小原则:回收public下不必要的权限;限制用户可访问的目录;限制用户的管理权限;限制远程数据库身份验证,remote_os_authent=false;acl访问控制。通过工具DBMS_PRIVILEGE_CAPTURE进行权限捕获,通过分析得到报告,对用户从未使用的权限进行回收。G_DATABASE分析除了SYS用户使用的其他权限;G_ROLE分析指定角色的权限;实验步骤如下:
第一步:创建角色、用户并授权
//第一步:创建角色并授权 create role capt; //创建角色 grant connect,resource to capt; grant select,update on hr.employees to capt; create user capt_user identified by capt_user quota 10M on users; //用户名不能与角色名相同 grant capt to capt_user;
第二步:sys用户下建立权限捕获策略,capt_priv是捕获策略的名称;description是描述
begin dbms_privilege_capture.create_capture(name => 'CAPT_PRIV', description => 'Policy to record privilege use by capt', type=> dbms_privilege_capture.g_role, roles=> role_name_list('CAPT')); end; /
第三步:启动捕获策略并登录capt_user,执行select、update操作
begin dbms_privilege_capture.enable_capture(name=>'CAPT_PRIV'); end; / conn capt_user/capt_user; select last_name,salary from hr.employees; update hr.employees set salary=20000 where last_name='Gietz';
第四步:停止捕获策略并生成权限捕获结果
conn / as sysdba; //切换回sys用户 begin dbms_privilege_capture.disable_capture(name=>'CAPT_PRIV'); end; / begin dbms_privilege_capture.generate_result(name=>'CAPT_PRIV'); end; /
第五步:查看捕获结果
select capture,username,object_owner,object_name,OBJ_PRIV from dba_used_objprivs; //查看已使用的对象权限 select capture,username,sys_priv from dba_used_sysprivs; //查看已使用过的系统权限 select capture,username,obj_priv from dba_unused_objprivs; //查看未使用的对象权限 select capture,username,rolename,sys_priv from dba_unused_sysprivs; //查看未使用的系统权限
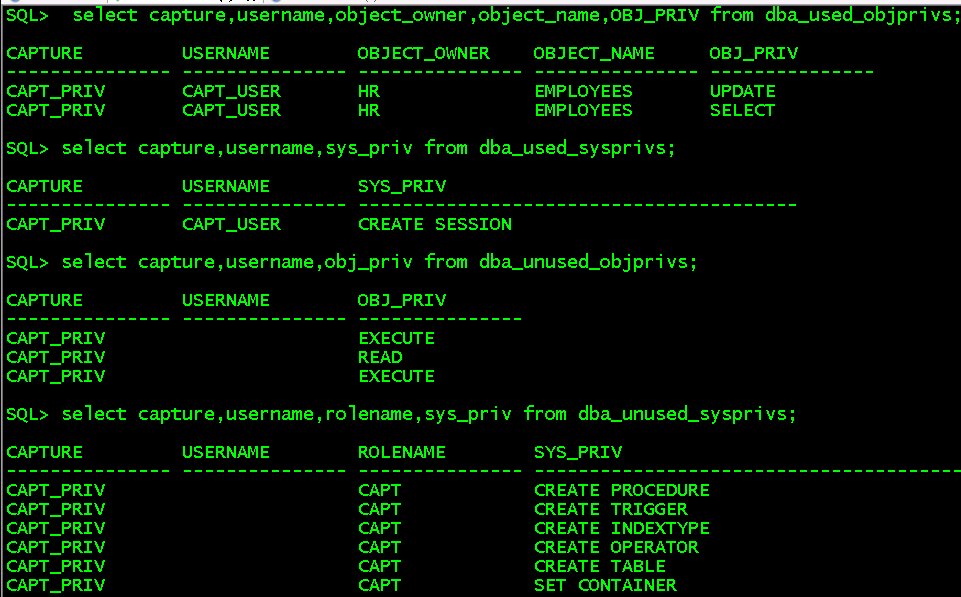
第六步:删除捕获权限,上面sql都查不出数据
begin dbms_privilege_capture.drop_capture(name=>'CAPT_PRIV'); end; /
五、查看用户或角色拥有的对象权限(对象权限是对对象的操作权限,比如对表的增删改等DML语句)
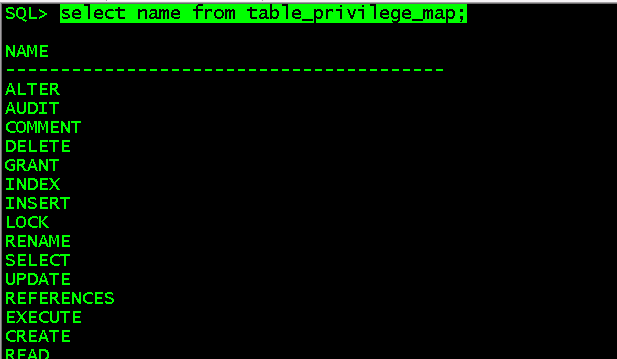
select name from table_privilege_map; //查看所有对象权限种类
select * from dba_tab_privs; //查看所有用户拥有的对象权限 select * from dba_tab_privs where grantee='PUBLIC'; //查看PUBLIC用户拥有的对象权限 select * from role_tab_privs; //查看当前用户所有角色拥有的对象权限
对象权限包括slecet,insert,delete,exec等,grantable时表示当前用户是否有权利把该权限授予其他用户,grant select on scott.emp to hr with grant option,权限会被级联回收。
select * from user_tab_privs; select * from all_tab_privs;

六、查看所有角色(最常见的是connect、resource、dba,角色是一系列权限的集合)
select * from dba_roles;

create role test; //在sys用户下创建test角色 select * from dba_roles; drop role test; //在sys用户下删除test角色 select * from dba_roles;


查看用户拥有的角色
select * from dba_role_privs; //查看所有用户拥有的角色

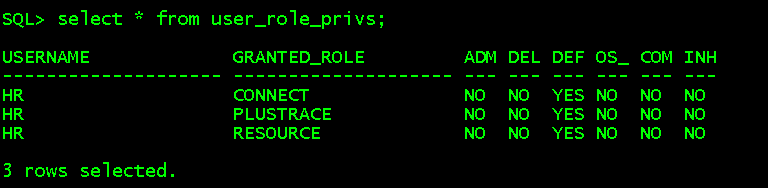
select * from user_role_privs; //查看当前用户拥有的角色
七、查看用户表的相关信息
1、查看表的所有字段
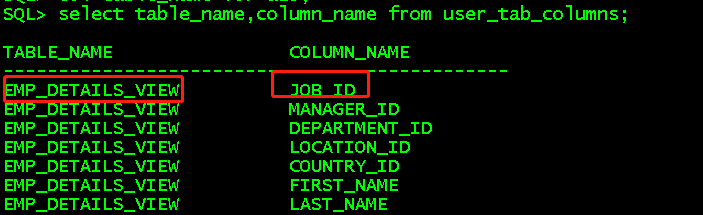
select owner,table_name,column_name from dba_tab_columns; //查看所有用户所有表的所有字段 select table_name,column_name from user_tab_columns; //查看当前用户所有表的所有字段
2 、查看表的所有备注
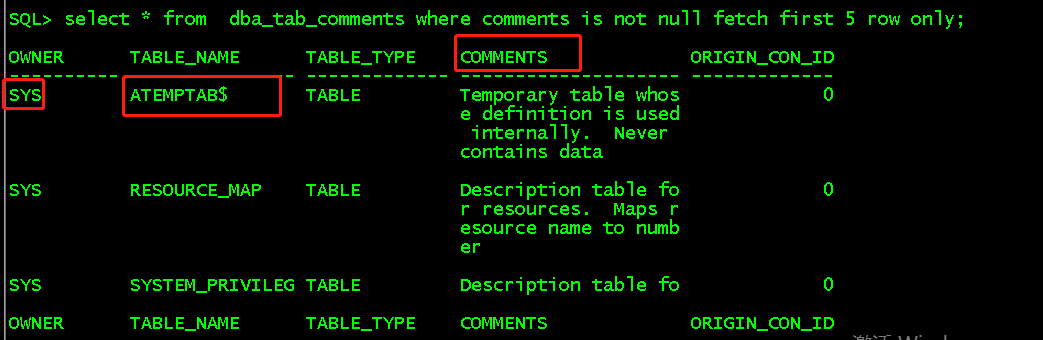
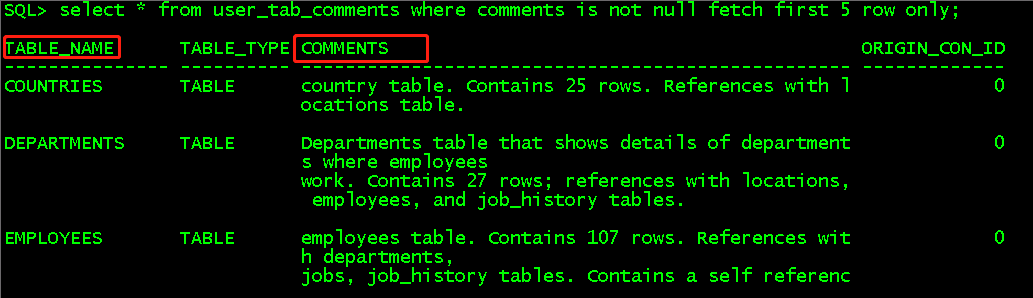
select * from dba_tab_comments where comments is not null fetch first 5 row only; //显示所有用户所有表的备注,这里取备注非空的前5行显示 select * from user_tab_comments where comments is not null fetch first 5 row only; //显示当前用户所有表的备注,这里取备注非空的前5行显示
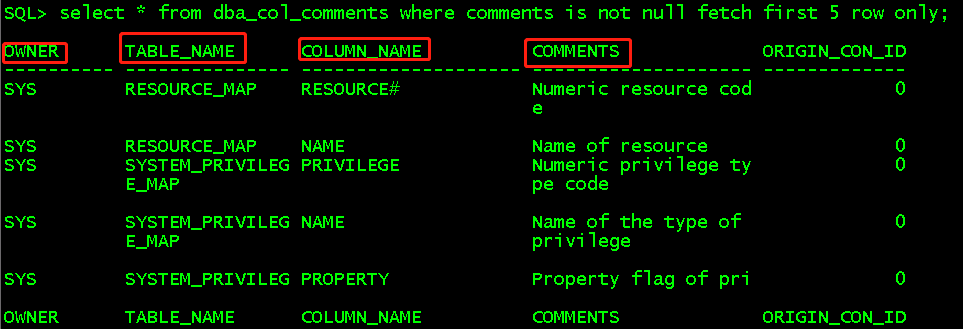
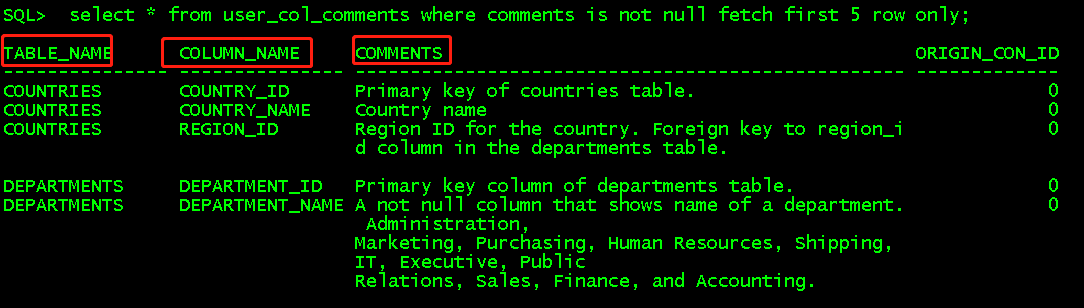
select * from dba_col_comments where comments is not null fetch first 5 row only; //显示所有用户所有表的所有字段备注,这里取备注非空的前5行显示 select * from user_col_comments where comments is not null fetch first 5 row only; //显示当前用户所有表的所有字段备注,这里取备注非空前5行显示
八、查看表空间或数据文件
select tablespace_name from dba_tablespaces; //查看所有表空间
select file_name,tablespace_name from dba_data_files; //查看数据文件及其表空间
九、profile控制用户使用的资源(概要文件)
每个用户只有一个概要文件,对用户能使用的数据库资源进行限制,且resource_limit=true概要文件限制才会生效,但密码相关的配置不受resource_limit限制,默认的profile不能被删除。
show parameter resource_limit; //查看参数,true表示启用资源限制 select * from dba_profiles; //查看概要文件信息,有会话级别资源限制、调用级别资源限制、用户安全限制
1、会话级别资源限制(如果超出了这些限制,oracle会断开会话的连接)
CPU_PER_SESSION :会话所能使用的CPU时间总量。单位是百分之一秒。
SESSIONS_PER_USER :同一用户所能的开的最多会话数。
CONNECT_TIME :以分钟计算的会话持续连接时间。
IDLE_TIME :以分钟计算的空闲时间。
LOGICAL_READS_PER_SESSION :会话所能读取的数据块数。
PRIVATE_SGA :在共享服务器模式下,每个用户连接所能使用的SGA中的空间,单位是字节。
2、调用级别资源限制
CPU_PER_CALL :每次调用所能占用的CPU时间,单位百分之一秒
LOGICAL_READS_PER_CALL :每次调用所能读取的数据块数。
3、用户安全限制(和密码相关)
FAILED_LOGIN_ATTEMPTS n :当用户登录N次后仍没有输入正确的密码,用户被自动的锁定。
PASSWORD_LOCK_TIME n :用户被锁定后,用户被锁定的天数。
PASSWORD_LIFE_TIME n :设置密码的有效期,单位是天数。
PASSWORD_GRACE_TIME n :宽限期。密码无效后,在指定的宽限期内每登录一次,就会收到一条警告信息。如果用户在宽限期仍没有更换密码,用 户将无法登录。
PASSWORD_REUSE_TIME :当设置新密码后,给定的时间内不能再复用该密码。
PASSWORD_REUSE_MAX :密码最多能被复用的次数。
4、创建概要文件语法
CREATE PROFILE app_user LIMIT SESSIONS_PER_USER UNLIMITED CPU_PER_SESSION UNLIMITED CPU_PER_CALL 3000 CONNECT_TIME 45 LOGICAL_READS_PER_SESSION DEFAULT LOGICAL_READS_PER_CALL 1000 PRIVATE_SGA 15K COMPOSITE_LIMIT 5000000 FAILED_LOGIN_ATTEMPTS 5 PASSWORD_LIFE_TIME 60 PASSWORD_REUSE_TIME 60 PASSWORD_REUSE_MAX 5 PASSWORD_LOCK_TIME 1/24 PASSWORD_GRACE_TIME 10;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号