

面试题总集
OSPF
1.OSPF是什么
开放最短路径优先,一种链路状态路由协议,使用SPF算法寻址
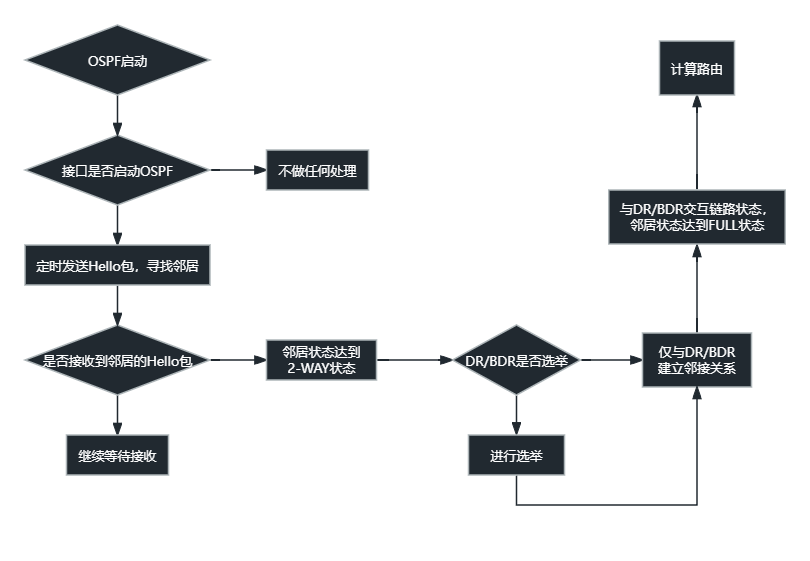
2.工作过程
先建立邻居,然后同步链路状态数据库,再计算最优路由路径
3.如何更改OSPF域中的Route ID
#clear IP OSPF process authority
4.关键属性
- Equal Cost Routes管理: CEF Load对应
- 协议类型:链路状态
- 传输:IP(89)
- 度量:const(带宽)
- 标准:RFC2328(OSPFv2)、RFC2740(OSPFv3/IPv6)
5.邻居关系变为邻接关系 - LSR数据包、链路状态、LSU数据包
- 双向通告
- 数据库同步,描述数据包的切换、链接
- 数据库同步完成,两个Router被测量为相邻
6.哪四种路由器类型 - 自治系统边界路由器,将外部路由通告到OSPF域的路由器
- 内部路由器,所有接口都属于同一区域的路由器
- 区域边界路由器,在多个区域中具有接口的路由器
- 骨干路由器,在区域0的路由器内部的路由器
7.特点是什么 - OSPF使用成本作为其度量,它是根据链路的带宽计算的
- OSPF是一个支持VLSM和CIDR的无类路由过程
- OSPF路由的距离为110
- 没有跳数限制
- 允许创建区域和独立系统
8.解释不同OSPF的功能和工作原理,并且什么类型用于OSPF中的协议间通信 - 使用LSA(Link-State Advertisements)通告直接相关链路状态
- 其中一个链接发生更改时,OSPF会通知更新,并且只会通过更新发送差异,LSA每30分钟额外刷新一次
- 使用SPF算法决定最短路径
- Type 3 LSA 用于区域间通信,其他协议和外部路由的通信使用Type4和5
9.是否可以让一侧编号而另一侧未编号 - 不能,不起作用,会导致数据库不一致,从而阻止将路由安装在引导表中
10.DR和BDR解决了什么 - 过渡LSA泛洪
- 邻接数高
11.邻接是什么意思 - 邻接指的是到邻居的理论上的链路,可以通过链路发送链路状态通告
12.链路状态重传间隔是什么 - OSPF必须发送对每个新的常规LSA的识别,LSA被重新传输,直到它们被批准,链路状态重传间隔定义重传之间的时间
-
IP OSPF retransmit-interval
13.说出五种OSPF数据包类型
- DBD、HELLO、LSU、LSR、LSack
14.子网关键字有什么用 - 没有子网关键字,则只会重新分配未直接连接到路由器的主网络地址
15.有几种LSA - External LSA、Network LSA、ASBR Summary LSA、Network Summary LSA、Router LSA
16.将优先级设为“0”的Route会发生什么 - 不参与DR/BDR的选举
17.没有骨干区域能使用OSPF吗 - 可以,但只有区域内通信,没有骨干区域就无法实现区域之间的通信
18.多播地址 - 224.0.0.5和224.0.0.6
19.Route ID是什么 - 用于识别路由器的标识符,是一个32位数字
20.OSPF定时器 - Dead Interval:定义了扩展路由器在宣布邻居死亡之前将如何等待hello数据包
- Hello Interval:定义了OSPF路由器向其他OSPF路由器发送hello数据包的频率
Kubernetes
一个目标:容器操作
自动化容器操作的开源平台。这些容器操作包括:部署、调度和节点集群间扩展。
具体功能:
- 自动化容器部署和复制。
- 实时弹性收缩容器规模。
- 容器编排成组,并提供容器间的负载均衡。
- 调度:容器在哪个机器上运行。
组成:
- kubectl:客户端命令行工具,作为整个系统的操作入口。
- kube-apiserver:以 REST API 服务形式提供接口,作为整个系统的控制入口。
- kube-controller-manager:执行整个系统的后台任务,包括节点状态状况、Pod 个数、Pods 和Service 的关联等。
- kube-scheduler:负责节点资源管理,接收来自 kube-apiserver 创建 Pods 任务,并分配到某个节点。
- etcd:负责节点间的服务发现和配置共享。
- kube-proxy:运行在每个计算节点上,负责 Pod 网络代理。定时从 etcd 获取到 service 信息来做相应的策略。
- kubelet:运行在每个计算节点上,作为 agent,接收分配该节点的 Pods 任务及管理容器,周期性获取容器状态,反馈给 kube-apiserver。
- DNS:一个可选的 DNS 服务,用于为每个 Service 对象创建 DNS 记录,这样所有的 Pod 就可以通过 DNS 访问服务了。
两地三中心
两地三中心包括本地生产中心、本地灾备中心、异地灾备中心。
k8s 使用 etcd 组件作为一个高可用、强一致性的服务发现存储仓库。用于配置共享和服务发现。
它作为一个受到 Zookeeper 和 doozer 启发而催生的项目。除了拥有他们的所有功能之外,还拥有以下 4 个特点:
- 简单:基于 HTTP+JSON 的 API 让你用 curl 命令就可以轻松使用。
- 安全:可选 SSL 客户认证机制。
- 快速:每个实例每秒支持一千次写操作。
- 可信:使用 Raft 算法充分实现了分布式。
四层服务发现
k8s 提供了两种方式进行服务发现:
环境变量:当创建一个 Pod 的时候,kubelet 会在该 Pod 中注入集群内所有 Service 的相关环境变量。需要注意的是,要想一个 Pod 中注入某个 Service 的环境变量,则必须 Service 要先比该 Pod 创建。这一点,几乎使得这种方式进行服务发现不可用。 比如,一个 ServiceName 为 redis-master 的 Service,对应的 ClusterIP:Port 为 10.0.0.11:6379,则对应的环境变量为:
- REDIS_MASTER_SERVICE_HOST=10.0.0.11
- REDIS_MASTER_SERVICE_PORT=6379
- REDIS_MASTER_PORT=tcp://10.0.0.11:6379
- REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
- REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
- REDIS_MASTER_PORT_6379_TCP_PORT=6379
- REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
DNS:可以通过 cluster add-on 的方式轻松的创建 KubeDNS 来对集群内的 Service 进行服务发现。
以上两种方式,一个是基于 TCP,DNS 基于 UDP,它们都是建立在四层协议之上。
五种 Pod 共享资源
Pod 是 k8s 最基本的操作单元,包含一个或多个紧密相关的容器。
一个 Pod 可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个 Pod 中的多个容器应用通常是紧密耦合的,Pod 在 Node 上被创建、启动或者销毁;每个 Pod 里运行着一个特殊的被称之为 Volume 挂载卷,因此他们之间通信和数据交换更为高效。在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个 Pod 中。
一个 Pod 中的应用容器共享五种资源:
- PID 命名空间:Pod 中的不同应用程序可以看到其他应用程序的进程 ID。
- 网络命名空间:Pod 中的多个容器能够访问同一个IP和端口范围。
- IPC 命名空间:Pod 中的多个容器能够使用 SystemV IPC 或 POSIX 消息队列进行通信。
- UTS 命名空间:Pod 中的多个容器共享一个主机名。
- Volumes(共享存储卷):Pod 中的各个容器可以访问在 Pod 级别定义的 Volumes。
- Pod 的生命周期通过 Replication Controller 来管理;通过模板进行定义,然后分配到一个 Node 上运行,在 Pod 所包含容器运行结束后,Pod 结束。
Kubernetes 为 Pod 设计了一套独特的网络配置,包括为每个 Pod 分配一个IP地址,使用 Pod 名作为容器间通信的主机名等。
同一个 Pod 里的容器之间仅需通过 localhost 就能互相通信。
六个 CNI 常用插件
CNI(Container Network Interface)容器网络接口是 Linux 容器网络配置的一组标准和库,用户需要根据这些标准和库来开发自己的容器网络插件。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。
- Loopback
- Bridge
- PTP
- MACvlan
- IPvlan
- 3rd-party
七层负载均衡
提负载均衡就不得不先提服务器之间的通信。
IDC(Internet Data Center)也可称数据中心、机房,用来放置服务器。IDC 网络是服务器间通信的桥梁。
路由器、交换机、MGW/NAT 都是网络设备,按照性能、内外网划分不同的角色。
-
内网接入交换机:也称为 TOR(top of rack),是服务器接入网络的设备。每台内网接入交换机下联 40-48 台服务器,使用一个掩码为 /24 的网段作为服务器内网网段。
-
内网核心交换机:负责 IDC 内各内网接入交换机的流量转发及跨 IDC 流量转发。
-
MGW/NAT:MGW 即 LVS 用来做负载均衡,NAT 用于内网设备访问外网时做地址转换。
-
外网核心路由器:通过静态互联运营商或 BGP 互联美团统一外网平台。
-
二层负载均衡:基于 MAC 地址的二层负载均衡。
-
三层负载均衡:基于 IP 地址的负载均衡。
-
四层负载均衡:基于 IP+端口 的负载均衡。
-
七层负载均衡:基于 URL 等应用层信息的负载均衡。
上面四层服务发现讲的主要是 k8s 原生的 kube-proxy 方式。k8s 关于服务的暴露主要是通过 NodePort 方式,通过绑定 minion 主机的某个端口,然后进行 Pod 的请求转发和负载均衡,但这种方式有下面的缺陷:
- Service 可能有很多个,如果每个都绑定一个 Node 主机端口的话,主机需要开放外围的端口进行服务调用,管理混乱。
- 无法应用很多公司要求的防火墙规则。
理想的方式是通过一个外部的负载均衡器,绑定固定的端口,比如 80;然后根据域名或者服务名向后面的 Service IP 转发。
Kubernetes 给出的方案就是 Ingress(1.30.x版本改为Gateway API)。这是一个基于七层的方案。
八种隔离维度
Bash
find
找出/test.dir目录下的文件名中包含test关键字的文件并将其全部删除
方法一:使用 find 命令和通配符配合删除文件
find /test.dir -type f -name '*test*' -exec rm {} +
解释:
find /test.dir:在/test.dir目录下进行查找。-type f:只查找普通文件。-name '*test*':查找文件名中包含关键字 "test"。-exec rm {} +:删除找到的文件。
方法二:使用 grep 命令和 xargs 命令配合删除文件
ls /test.dir | grep 'test' | xargs -I {} rm /test.dir/{}
解释:
ls /test.dir:列出/test.dir目录下的所有文件。grep 'test':筛选包含关键字 "test" 的文件名。xargs -I {} rm /test.dir/{}:通过管道将文件名传递给 xargs 命令,并使用{}表示文件名,执行rm删除文件。
请注意,在使用以上方法删除文件之前,一定要确保你理解并验证了要删除的文件,并且确保没有重要文件会被误删除。
查找/etc目录下以tions结尾的目录或者文件然后把其详细信息保存到/tmp/下的test.txt文件下
find /etc -type d -name '*tions' -o -type f -name '*tions' -exec ls -l {} \; > /tmp/test.txt
解释:
find /etc:在/etc目录下进行查找。-type d:查找目录。-name '*tions':查找名字以 "tions" 结尾的目录。-o:表示“或”的逻辑操作符。-type f:查找文件。-exec ls -l {} \;:对于找到的目录或文件,使用ls -l命令显示详细信息。> /tmp/test.txt:将详细信息输出到/tmp/test.txt文件中。
请注意,在运行该命令之前,请确保你有足够的权限来访问/etc目录和创建/写入/tmp/test.txt文件。
查找/etc/下大于5M的文件或目录并显示其详细信息
你可以使用 find 命令来查找 /etc 目录下大于 5M 的文件或目录,并显示其详细信息。以下是示例命令:
find /etc -size +5M -exec ls -lh {} \;
解释:
find /etc:在/etc目录下进行查找。-size +5M:查找大于 5M 的文件或目录。-exec ls -lh {} \;:对于找到的文件或目录,使用ls -lh命令显示详细信息。
请注意,查找和显示/etc目录下大于 5M 的文件或目录可能需要较长的时间,具体取决于目录层次结构的大小和系统性能。也可以根据自己的需要调整文件大小的表示方式,如使用G表示 GB 或K表示 KB。
查找并删除/etc目录下小于1M大小的文件或目录
find /etc -size -1M -delete
查找/var目录下属主为root,且属组为mail的所有文件或目录
find /var -user root -group mail
find /var -user root -group mail -ls
find /var -maxdepth 1 -user root -group mail
查找/usr目录下不属于root、bin、.或hadoop的所有文件和目录
find /usr -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop
find来遍历/usr目录下的文件和目录。-type d表示查找目录,-type f表示查找文件。
! -user root ! -user bin ! -user . ! -user hadoop表示排除属主为root、bin、.或hadoop的文件和目录。
-o表示或运算,将目录和文件的查找结果合并在一起。
这将显示不属于root、bin、.或hadoop的所有文件和目录。
find /usr -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop -ls
find /usr -maxdepth 1 -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop
查找/etc目录中一周以来内容被修改过,并且属主不为root和hadoop的所有文件和目录
find /etc -type d -not -user root -not -user hadoop -or -type f -not -user root -not -user hadoop -mtime -7
find来遍历/etc目录下的文件和目录。-type d表示查找目录,-type f表示查找文件。
-not -user root -not -user hadoop表示排除属主为root和hadoop的文件和目录。
-mtime -7表示查找一周以来内容被修改过的文件和目录。这里的"7"表示7天,也可以根据需要进行调整。
这将显示满足这些条件的所有文件和目录。
find /etc -type d -not -user root -not -user hadoop -or -type f -not -user root -not -user hadoop -mtime -7 -ls
查找当前系统中没有属主和属组,并且最近一个周被访问过的文件和目录
find / -nouser -nogroup -atime -7
find来遍历整个系统中的文件和目录。-nouser表示查找没有属主的文件和目录,-nogroup表示查找没有属组的文件和目录。
-atime -7表示查找最近一个周内被访问过的文件和目录。这里的"7"表示7天,也可以根据需要进行调整。
查找/etc/目录下大于1M且类型为普通文件(regular file)的文件或目录
find /etc -type f -size +1M
find来遍历/etc/目录下的文件和目录。-type f表示仅查找普通文件,-size +1M表示查找大小大于1M的文件。
这将显示满足这些条件的所有文件和目录。
find /etc -maxdepth 1 -type f -size +1M
查找/etc目录下所有用户都没有写权限的文件
find /etc -type f -not -perm /u=w
find来遍历/etc目录下的文件。-type f表示查找普通文件,-not -perm /u=w表示排除用户拥有写权限的文件。
查找/etc/init.d目录下所有用户都有执行权限,且其它用户有写权限的文件
find /etc/init.d -type f -perm /u=x,g=w,o=w
find来遍历/etc/init.d目录下的文件。-type f表示查找普通文件,-perm /u=x,g=w,o=w表示查找用户有执行权限且其它用户有写权限的文件。
查看/etc/目录下修改时间是三天前的文件或目录
find /etc -mtime +3
find来遍历/etc/目录下的文件和目录。-mtime +3表示查找修改时间是三天前的文件和目录。这里的"3"表示三天,也可以根据需要进行调整。
find /etc -mtime +3 -ls
sed
只显示处理过的行
sed -n -f script.sed input.txt
在这里,-n选项告诉sed只打印被脚本处理的行。-f script.sed指定使用名为script.sed的脚本文件。input.txt是要处理的输入文件。
在script.sed中,你可以使用不同的sed命令来对行进行处理。在行的处理结束之前,使用p命令来打印它。
每一行打印出行内容
#!/bin/sed -nf
p
支持扩展的正则表达式
sed -n -r -f script.sed input.txt
在这里,-r选项告诉sed使用扩展的正则表达式语法。-f script.sed指定使用名为script.sed的脚本文件。input.txt是要处理的输入文件。
此外,如果你使用的是macOS上的BSD版sed,则-r选项不可用,你需要使用-E选项代替。例如:
sed -n -E -f script.sed input.txt
更改文件内容
sed -i -f script.sed input.txt
在这里,-i选项告诉sed直接修改input.txt文件。-f script.sed指定使用名为script.sed的脚本文件。
请注意,这种原位修改文件的方式是不可逆的,请在使用之前备份你的文件。如果你想保留原始文件,并将修改后的内容输出到另一个文件中,可以使用重定向操作符>。
sed -f script.sed input.txt > output.txt
显示文件中的特定行
要显示第二行,可以使用以下命令:
sed -n '2p' file.txt
要显示第二行和第三行,可以使用以下命令:
sed -n '2,3p' file.txt
要显示最后一行,可以使用以下命令:
sed -n '$p' file.txt
在这些命令中,-n选项用于关闭默认输出,以便只输出所需行。2p表示打印第二行,2,3p表示打印第二行和第三行,$p表示打印最后一行。file.txt是要处理的文件。
请注意,这些命令仅显示特定行,并不会修改文件本身。如果你想将结果保存到新文件中而不是直接显示在终端上,可以使用重定向操作符>将输出重定向到新文件中。
sed -n '2p' file.txt > output.txt
sed -n '2,3p' file.txt > output.txt
sed -n '$p' file.txt > output.txt
找出 /etc/passwd 文件中以"test"关键字开头的行
sed -n '/^test/p' /etc/passwd
在这里,/^test/p是正则表达式,并且它匹配以"test"开头的行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是要处理的文件。
请注意,^是正则表达式中的元字符,用于匹配行的开始位置。这样,只会匹配以"test"开头的行。如果你想寻找包含"test"的任意位置,而不仅限于行首,可以省略^。
找出 /etc/passwd 文件中以"/bin/bash"结尾的行
sed -n '/\/bin\/bash$/p' /etc/passwd
在 sed 脚本中,/\/bin\/bash$/p是一个正则表达式,用于匹配以 "/bin/bash" 结尾的行。使用 -n 选项关闭 sed 的默认输出,然后使用 p 命令打印匹配的行。/etc/passwd 是待处理的文件。
请注意,正斜杠/是正则表达式中的特殊字符,需要用反斜杠\进行转义。因此,\/bin\/bash$ 匹配一行结尾是 "/bin/bash" 的行。
找出 /etc/passwd 文件中以"root"或"test"开头的行
sed -n '/^root\|^test/p' /etc/passwd
在sed脚本中,/^root\|^test/p是一个正则表达式,用于匹配以"root"或"test"开头的行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是待处理的文件。
请注意,^是正则表达式中的开始位置元字符,用于匹配行的开头。由于管道符|是特殊字符,需要用反斜杠\进行转义。因此,/^root\|^test/匹配以"root"或"test"开头的行。
找出从以"root"开头的行开始到以"nologin"结尾的行之间的行
sed -n '/^root/,/nologin/p' /etc/passwd
在这里,/^root/,/nologin/p表示匹配以"root"开头的行和以"nologin"结尾的行之间的所有行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是要处理的文件。
运行命令后,sed将会输出从以"root"开头的行到以"nologin"结尾的行之间的所有行。
请注意,^和/是正则表达式中的特殊字符,在使用sed命令时需要进行转义。
在文本的第3行下面添加两行内容
sed '3a\
Line1\
Line2' file.txt
在开头是root的行下面添加两行内容test,test
sed '/^root/a\
test\
test' file.txt
把第一行整体替换成test,这是替换的一整行
sed '1s/.*/test/' file.txt
在/etc/passwd文件里面匹配到以root开头的行,然后这一行的下一行添加/tmp/text.txt里面的内容
sed '/^root/{n;r /tmp/text.txt' -e '}' /etc/passwd
/^root/{n;r /tmp/text.txt表示匹配以"root"开头的行,然后n命令读取并跳过该行,r /tmp/text.txt命令在匹配的行的下一行插入/tmp/text.txt文件的内容。-e是一个选项,用于指定紧跟其后的命令,是sed的编辑命令。
把text.txt文件里面包括my的行放置到text2.txt里面,注意这里面的顺序
sed -n '/my/p' text.txt > text2.txt
/my/p表示匹配包含"my"的行
将前10行当中的所有小写的s转换成大写的S
sed '1,10s/s/S/g' file.txt
1,10s/s/S/g表示替换文件的第1行到第10行中的所有小写字母"s"为大写字母"S"。
将全文所有小写的s转换成大写的S
sed 's/s/S/g' file.txt
s/s/S/g表示替换文件中所有的小写字母"s"为大写字母"S"。
删除第一行
sed '1d' file.txt
1d表示删除文件的第一行。
删除1、2、3行
sed '1,3d' file.txt
1,3d表示删除文件的第1行到第3行。
删除开头的root的行一直到结尾是nologin的行
sed '/^root/,/nologin/d' file.txt
/^root/,/nologin/d表示删除匹配以"root"开头的行和以"nologin"结尾的行之间的所有行。
删除开头是#号的行
sed '/^#/d' file.txt
/^#/d表示删除匹配以"#"开头的行。
删除空白行
sed '/^\s*$/d' file.txt
/^\s*$/d表示删除空白行,包括只包含空格、制表符或空白字符的行。
^表示行的开始\s*表示匹配零个或多个空白字符(例如,空格、制表符等)$表示行的结束
删除带空格的假空行
sed '/^[[:space:]]*$/d' file.txt
/^[[:space:]]*$/d表示删除带有空格的空行,包括只包含空格、制表符或空白字符的行。
将一个文本中所有的大写字母替换为小写字母
sed 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' file.txt
y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/ 使用 sed 命令中的 y 命令将大写字母转换为小写字母。
将一个文件中所有的小写 root 替换为大写 ROOT
sed 's/root/ROOT/g' file.txt
s/root/ROOT/g 使用 sed 命令中的 s 命令将文件中的所有小写 root 替换为大写 ROOT。
整行替换,将第二行无论什么内容都替换为 888
sed '2c\888' file.txt
2c\888 使用 sed 命令中的 c 命令替换文件的第二行为 888。
仅替换第三列的某些内容
sed 's/\(\([^[:blank:]]\+[[:blank:]]\+\)\{2\}\)\(old_value\)/\1new_value/' file.txt
使用 sed 命令中的 s 命令和正则表达式来选择第三列的内容。将 old_value 替换为 new_value。
s/是 sed 命令的替换操作符。\(和\)是用来定义一个捕获组,它可以保存匹配的内容供后续引用。[^[:blank:]]匹配任意非空白字符(空格、制表符等)。+表示匹配一个或多个前面的字符。[[:blank:]]匹配一个空白字符。\{2\}表示前面的模式匹配出现两次。\1引用第一个捕获组,即匹配前两列的内容。old_value是要替换的旧值。new_value是替换后的新值。
利用 sed 命令删除 history 开头的空白字符
sed 's/^[[:blank:]]*history/history/' file.txt
使用 sed 命令中的 s 命令和正则表达式来选择以空白字符开头的 history 并将其替换为 history。这将删除 history 开头的所有空白字符。
删除 /etc/grub.conf 文件中行首的空白字符
sed 's/^[[:blank:]]*//' /etc/grub.conf
s/^[[:blank:]]*// 表达式,将行首的任何空白字符替换为空,从而删除了行首的空白字符。
替换 /etc/inittab 文件中 id:3:initdefault: 行中的数字为 5
sed 's/\(id:3:initdefault:\)[0-9]/\15/' /etc/inittab
s/\(id:3:initdefault:\)[0-9]/\15/ 表达式,捕获了 id:3:initdefault: 这个文本,并在替换时引用了它(\1),将后面的数字替换为 5。
删除 /etc/inittab 文件中的空白行
sed '/^[[:blank:]]*$/d' /etc/inittab
/^[[:blank:]]*$/d 表达式,匹配空白行并将其删除(d)。
删除 /etc/inittab 文件中以 # 开头的行
sed '/^#/d' /etc/inittab
/^#/d 表达式,匹配以 # 开头的行并将其删除(d)。
删除某文件中开头的 # 及后面的空白字符的行,但要求 # 号后面必须有空白字符
sed '/^#[[:blank:]]*$/d' file.txt
/^#[[:blank:]]*$/d 表达式,匹配以 # 开头,并且后面跟零个或多个空白字符的行,并将其删除(d)。
删除某文件中以空白字符后面跟 # 号的行中开头的空白字符及 #
sed 's/^[[:blank:]]*\(#\)//' file.txt
s/^[[:blank:]]*\(#\)// 表达式,匹配以零个或多个空白字符开头,并且后面跟 # 号的行,并将开头的空白字符及 # 替换为空。
取出一个文件路径的目录名称
echo "/path/to/directory/file.txt" | sed 's|\(.*/\).*|\1|'
这个命令将输出 /path/to/directory/,使用 s|\(.*/\).*|\1| 表达式,捕获了从开头到最后一个斜杠之间的内容,并使用后向引用 (\1) 将其输出。
取出一个目录的基名和目录名
dirname="/path/to/directory"
echo "$dirname" | sed 's|\(.*\)/\(.*\)|Directory: \1\nBase Name: \2|'
这个命令的含义是,通过 sed 命令的替换操作 (s),使用正则表达式匹配目录路径中的内容并进行捕获,然后将其替换为格式化的输出。
\(.*\)/\(.*\):使用括号\( \)来捕获内容。第一个.*表示匹配任意字符(除换行符外)零次或多次,表示目录路径部分(即目录名和基名之前的部分),/表示斜杠分隔,第二个.*表示匹配任意字符(除换行符外)零次或多次,表示基名部分。
因此,该命令将输出以下内容:
Directory: /path/to
Base Name: directory
使用 dirname 命令可以获取目录的路径,然后使用 basename 命令获取目录的基名。
把 /etc/fstab 文件中的空行和开头是空格的、开头是 # 号的行都删除掉
sed '/^[[:blank:]]*$/d' /etc/fstab | sed '/^[[:blank:]]\|#/d'
两个 sed 命令,首先 /^[[:blank:]]*$/d 会删除空行,然后 /^[[:blank:]]\|#/d 会删除开头是空格或 # 号的行。
