
基础知识-GO语言部分
(240307,已更新到GORM)
资料参考
Go 语言教程 | runoob
golang的类型推断 | jb51
Golang-100-Days | Github | rubyhan
Go 语言基础之 Context 详解 | zhihu | 程序员祝融
Go 语言 bytes.Buffer 源码详解之1 | 稀土掘金 | CodePlayer竟然被占用了
Go 语言 bytes.Buffer 源码详解 2 | 稀土掘金 | CodePlayer竟然被占用了
cobra package | pkg.go.dev
golang工程组件之命令行框架cobra | CSDN | SMILY12138
Cobra用户手册 | github | spf13(必看)
GORM手册
GORM Package | pkg.go.dev
基础
基本语法
Go 程序可以由多个标记组成,可以是关键字,标识符,常量,字符串,符号。
fmt.Println("Hello, World!")
6 个标记是(每行一个):
1. fmt
2. .
3. Println
4. (
5. "Hello, World!"
6. )
在 Go 程序中,一行代表一个语句结束。
注释不会被编译,每一个包应该有相关注释。
单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾。
数据类型
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型 布尔型的值只可以是常量 true 或者 false. |
| 2 | 数字类型 整型 int 和浮点型 float32、float64,Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 3 | 字符串类型 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 4 | 派生类型 包括:(a) 指针类型(Pointer) (b) 数组类型 (c) 结构化类型(struct) (d) Channel 类型 (e) 函数类型 (f) 切片类型 (g) 接口类型(interface) (h) Map 类型 |
数字类型
| uint8 | 无符号 8 位整型 (0 到 255) |
|---|---|
| uint16 | 无符号 16 位整型 (0 到 65535) |
| uint32 | 无符号 32 位整型 (0 到 4294967295) |
| uint64 | 无符号 64 位整型 (0 到 18446744073709551615) |
| int8 | 有符号 8 位整型 (-128 到 127) |
| int16 | 有符号 16 位整型 (-32768 到 32767) |
| int32 | 有符号 32 位整型 (-2147483648 到 2147483647) |
| int64 | 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
| float32 | IEEE-754 32位浮点型数 |
| float64 | IEEE-754 64位浮点型数 |
| complex64 | 32 位实数和虚数 |
| complex128 | 64 位实数和虚数 |
| byte | 类似 uint8 |
| rune | 类似 int32 |
| uint | 32 或 64 位 |
| int | 与 uint 一样大小 |
| uintptr | 无符号整型,用于存放一个指针 |
变量
//定义一个名称为“valName”,类型为"type"的变量
var valName type
//定义三个类型都是“type”的变量
var vname1, vname2, vname3 type
//定义三个类型都是"type"的变量,并且分别初始化为相应的值
//vname1为v1,vname2为v2,vname3为v3
var vname1, vname2, vname3 type= v1, v2, v3
var vname1, vname2, vname3 = v1, v2, v3
vname1, vname2, vname3 := v1, v2, v3
/*
:=这个符号直接取代了var和type,这种形式叫做简短声明。不过它有一个限制,那就是它只能用在函数内部;
在函数外部使用则会无法编译通过,所以一般用var方式来定义全局变量。
*/
//_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃。在这个例子中,我们将值2赋予b,并同时丢弃1:
_, b := 1, 2
如果变量为私有,且特有名词为首个单词,则使用小写,如 appService
若变量类型为 bool 类型,则名称应以 Has, Is, Can 或 Allow 开头
var isExist bool
var hasConflict bool
var canManage bool
var allowGitHook bool
条件语句
if 语句
if 语句的基本语法如下:
if condition {
// 如果条件成立,执行这里的代码块
}
其中,condition 表示一个布尔表达式,如果 condition 为真,则执行 if 后面的代码块,否则不执行。
package main
import "fmt"
func main() {
num := 10
if num < 20 {
fmt.Println("num is less than 20")
}
}
在上面的代码中,我们使用 if 语句判断变量 num 是否小于 20,如果成立,则打印出相应的信息。
除了基本的 if 语句外,Go 语言还支持在条件语句前面添加一个简短的语句,用于初始化变量。例如:
package main
import "fmt"
func main() {
if num := 10; num < 20 {
fmt.Println("num is less than 20")
}
}
在上面的代码中,我们在 if 语句前面添加了一个简短的语句 num := 10,用于初始化变量 num 的值。然后我们判断 num 是否小于 20,如果成立,则打印出相应的信息。
if condition {
// 如果条件成立,执行这里的代码块
} else {
// 如果条件不成立,执行这里的代码块
}
condition 是一个布尔表达式,如果为真,则执行if语句后面的代码块,否则执行else后面的代码块。可以看出,if...else语句只有两种情况,要么执行if代码块,要么执行else代码块。
除了基本的if...else语句外,Go语言还支持if...else if...else语句,用于根据不同的条件执行不同的代码块。if...else if...else语句的基本语法如下:
if condition1 {
// 如果条件1成立,执行这里的代码块
} else if condition2 {
// 如果条件1不成立,且条件2成立,执行这里的代码块
} else {
// 如果条件1和条件2都不成立,执行这里的代码块
}
condition1 和 condition2 都是布尔表达式,如果 condition1 为真,则执行第一个代码块;如果 condition1 不为真,且 condition2 为真,则执行第二个代码块;否则执行第三个代码块。
除了if...else语句和if...else if...else语句外,Go语言还支持if嵌套语句,用于根据多个条件执行不同的代码块。if嵌套语句的基本语法如下:
if condition1 {
// 如果条件1成立,执行这里的代码块
if condition2 {
// 如果条件1和条件2都成立,执行这里的代码块
}
} else {
// 如果条件1不成立,执行这里的代码块
}
在上面的代码中,我们使用了一层嵌套的if语句,根据两个条件来执行不同的代码块。首先判断 condition1 是否成立,如果成立,则继续判断 condition2 是否成立,如果成立,则执行第二个代码块;否则执行第一个代码块。如果 condition1 不成立,则执行else后面的代码块。
switch 语句
switch 语句的基本语法如下:
switch expression {
case value1:
// 如果 expression 的值等于 value1,执行这里的代码块
case value2:
// 如果 expression 的值等于 value2,执行这里的代码块
default:
// 如果 expression 的值都不等于上面的值,执行这里的代码块
}
其中,expression 表示一个表达式,可以是任何类型,而 value1、value2 等则表示具体的值。当 expression 的值等于某个 case 后面的值时,就会执行相应的代码块。如果 expression 的值都不等于上面的值,则执行 default 后面的代码块。
package main
import "fmt"
func main() {
num := 3
switch num {
case 1:
fmt.Println("one")
case 2:
fmt.Println("two")
case 3:
fmt.Println("three")
default:
fmt.Println("other")
}
}
在上面的代码中,我们使用 switch 语句判断变量 num 的值,并根据不同的值执行不同的代码块。
与 if 语句类似,switch 语句也支持在条件语句前面添加一个简短的语句,用于初始化变量。例如:
package main
import "fmt"
func main() {
switch num := 3; num {
case 1:
fmt.Println("one")
case 2:
fmt.Println("two")
case 3:
fmt.Println("three")
default:
fmt.Println("other")
}
}
在上面的代码中,我们在 switch 语句前面添加了一个简短的语句 num := 3,用于初始化变量 num 的值。
select 语句
select 语句用于处理通道(Channel)的发送和接收操作。其基本语法如下:
select {
case msg1 := <-channel1:
// 从 channel1 接收数据,并将数据赋值给变量 msg1
// 如果 channel1 没有数据可接收,则阻塞在这里
case channel2 <- msg2:
// 向 channel2 发送数据 msg2
// 如果 channel2 没有空间可发送,则阻塞在这里
default:
// 如果所有的 case 都没有匹配到,则执行这里的代码块
}
其中,channel1 和 channel2 表示通道变量,msg1 和 msg2 表示通道中的数据。当 select 语句执行时,会从多个通道中选择一个有数据可读或者有空间可写的通道执行相应的操作。如果所有的通道都没有数据可读或者没有空间可写,则执行 default 后面的代码块。
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
ch2 := make(chan int)
go func() {
ch1 <- "hello"
}()
go func() {
ch2 <- 10
}()
select {
case str := <-ch1:
fmt.Println(str)
case num := <-ch2:
fmt.Println(num)
}
}
在上面的代码中,我们定义了两个通道 ch1 和 ch2,并将字符串 "hello" 和整数 10 分别发送到这两个通道中。然后我们使用 select 语句从多个通道中选择一个有数据可读的通道,并打印出其结果。由于通道中的数据是异步发送和接收的,因此输出的结果可能是字符串 "hello" 或者整数 10 中的任意一个。
循环语句
for循环
for循环是Go语言中最基本的循环语句,用于重复执行一定的代码块。它的基本语法如下:
for 初始化语句; 条件表达式; 后置语句 {
// 循环体
}
其中,初始化语句用于初始化循环变量,条件表达式用于判断是否继续执行循环,后置语句用于更新循环变量。循环体是需要重复执行的代码块。
循环嵌套
循环嵌套是指在一个循环语句中嵌套另一个循环语句,以实现更复杂的循环逻辑。例如,下面的代码展示了一个简单的循环嵌套:
for i := 0; i < 10; i++ {
for j := 0; j < 5; j++ {
fmt.Print(i * j, " ")
}
fmt.Println()
}
/*
0 0 0 0 0
0 1 2 3 4
0 2 4 6 8
0 3 6 9 12
0 4 8 12 16
0 5 10 15 20
0 6 12 18 24
0 7 14 21 28
0 8 16 24 32
0 9 18 27 36
*/
在上面的代码中,我们使用了两个for循环,一个是外层的循环,一个是内层的循环。内层的循环会在每次外层循环执行时重复执行,以实现更复杂的循环逻辑。
break语句
break语句用于跳出循环,即在循环体中使用break语句会立即退出循环。例如,下面的代码展示了如何使用break语句:
for i := 0; i < 10; i++ {
if i == 5 {
break
}
fmt.Print(i, " ")
}
//0 1 2 3 4
在上面的代码中,当i等于5时,使用break语句跳出循环,不再执行后面的代码。
continue语句
continue语句用于跳过循环中的某一次迭代,即在循环体中使用continue语句会立即跳过本次循环,进入下一次循环。例如,下面的代码展示了如何使用continue语句:
for i := 0; i < 10; i++ {
if i%2 == 0 {
continue
}
fmt.Print(i, " ")
}
//1 3 5 7 9
在上面的代码中,当i是偶数时,使用continue语句跳过本次循环,不再执行后面的代码。
goto语句
goto语句用于无条件跳转到指定的标签,即在循环体中使用goto语句可以跳转到指定的标签处执行代码。例如,下面的代码展示了如何使用goto语句:
for i := 0; i < 10; i++ {
if i == 5 {
goto LABEL
}
fmt.Print(i, " ")
}
LABEL:
fmt.Println("Jumped to label")
在上面的代码中,当i等于5时,使用goto语句跳转到标签LABEL处执行代码。注意,使用goto语句会增加代码的复杂度和阅读难度,因此应该尽量避免使用。
包,导入导出
Package(包):Go语言中的包是多个Go源代码的集合,用于组织源代码。每个包都有一个唯一的包名,这个包名是其源文件所在目录的名称。包的定义可以通过package关键字完成,例如package main或package src/main,其中src是源文件的目录路径。Go语言提供了多种内置包,如fmt、os、io等,这些包可以被其他代码引用。
Imports(导入):导入包是Go语言中引用其他包代码的基本方法。使用import关键字,可以在代码中直接引用其他包的内容。导入的方式有多种,包括点操作、相对路径和绝对路径等。例如,import "fmt"会从标准库目录$GOROOT/src/fmt加载fmt模块,而import "./test"则导入同一目录下的test包中的内容。导入支持单行导入和多行导入,当多行导入时,包名在import中的顺序不影响导入效果。
Exports(导出):在Go语言中,一个包的内容可以通过其导出标识符来访问。导出标识符通常位于包的头部,并以引号括起来。例如,fmt.Print("hello world")调用了fmt模块中的函数,该函数返回一个字符串,然后打印到控制台上。
在Go语言中,导入包的最佳实践主要包括以下几点:
单行导入与多行导入:Go语言中一个包可以包含多个.go文件,这些文件必须在同一级文件夹中。导入包主要有两种方式:单行导入和多行导入。单行导入是直接使用import "包名";而多行导入则是通过括号(包名)来导入多个包。
使用别名避免冲突:在导入多个具有同一包名的包时,可能会产生冲突。为了避免这种情况,可以为其中一个包定义一个别名,例如import ( "crypto/rand" mrand "math/rand"),这样就可以将冲突的包名替换为别名。
正确导入包:仅导入需要的包,并格式化导入部分以对标准库包、第三方包和自己的包进行分组。这有助于保持代码的整洁和可维护性。
使用go module导入本地包:对于本地包的导入,可以使用go module命令。这意味着不需要将项目目录放在GOPATH中,也不使用vendor目录。而是统一安装到$GOPATH/pkg/mod/cache中,在build/run时,自动析出项目import的包并安装。
格式化导入部分:为了更好地组织和管理包,应该格式化导入部分以将标准库包、第三方包和自己的包分组。这样做可以帮助开发者更快地找到所需的包,同时也便于团队成员之间的协作。
函数,多返回值,命名返回值
Go语言中的函数是一种可重用的代码块,用于封装特定的功能。函数定义格式如下:
func 函数名(参数列表) 返回值类型 {
函数体
}
其中,参数列表可以为空,也可以包含多个参数,每个参数包含名称和类型。返回值类型可以是单个类型或多个类型组成的元组。函数体中实现了函数的具体功能,并通过return语句返回结果。
下面是一些常见的函数用法:
函数调用
函数调用格式如下:
函数名(参数列表)
参数列表中需要传递与函数定义中参数列表相同类型和数量的参数。例如:
package main
import "fmt"
func add(a int, b int) int {
return a + b
}
func main() {
res := add(1, 2)
fmt.Println(res) // 输出 3
}
返回多值
函数可以返回多个值,这些值可以是不同类型的。例如:
func divide(a, b float64) (float64, error) {
if b == 0 {
return 0, fmt.Errorf("division by zero")
}
return a / b, nil
}
func main() {
res, err := divide(10, 2)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(res) // 输出 5
}
}
这个例子中,我们定义了一个名为divide的函数,该函数接收两个float64类型的参数a和b,并返回两个值:a/b和一个error类型的值(用于处理除数为0的情况)。在主函数中,我们调用了divide函数,并使用res和err两个变量分别接收其返回值。如果err不为nil,则说明除数为0,需要进行错误处理;否则,我们可以使用res变量来获取计算结果。
函数参数
函数可以接收多种参数类型,包括:
- 值类型:函数接收的参数是值的副本,对参数的修改不会影响原始值;
- 指针类型:函数接收的参数是指向值的指针,对参数的修改会影响原始值;
- 可变参数:函数接收的参数数量是可变的,可以接收任意数量的参数。
例如:
func changeValue(a int) {
a = 10
}
func changePointer(a *int) {
*a = 10
}
func sum(nums ...int) int {
res := 0
for _, num := range nums {
res += num
}
return res
}
func main() {
num := 5
changeValue(num)
fmt.Println(num) // 输出 5
changePointer(&num)
fmt.Println(num) // 输出 10
res := sum(1, 2, 3, 4, 5)
fmt.Println(res) // 输出 15
}
这个例子中,我们定义了三个函数changeValue、changePointer和sum,分别演示了值类型、指针类型和可变参数的用法。在主函数中,我们先定义了一个变量num,然后分别调用了changeValue和changePointer函数,分别修改了其值。最后,我们调用了sum函数,传递了5个参数,并将结果赋给了res变量。
(接收一个可变参数nums,类型为int类型的切片。使用for循环遍历nums中的每个元素,并将它们加起来,最后返回总和。range遍历nums切片中的每个元素,通过_忽略了每个元素的索引,只保留了元素本身。
...int表示可变参数列表,也称为不定参数。这意味着函数可以接受任意数量的int类型参数,并将它们视为一个int类型的切片。)
func sum(nums ...int) int { // 定义一个名为sum的函数,参数为int类型的可变参数nums,返回值为int类型
res := 0 // 定义一个变量res,初始值为0
for i := range nums { // 使用for循环遍历nums切片中的每个元素,其中i表示当前元素的索引,num表示当前元素的值
res += nums[i] // 将当前元素加到变量res中
}
return res // 返回变量res的值,表示所有元素的和
}
func main() {
res := sum(1, 2, 3, 4, 5) // 调用sum函数,传递5个int类型的参数,并将返回值赋给res变量
fmt.Println(res) // 在控制台输出res的值,即所有参数的和
}
在这个例子中,我们将循环改为使用变量i表示当前元素的索引,这样可以访问nums切片中的任意元素。在循环体中,我们使用nums[i]访问当前元素的值,并将其加到变量res中。
需要注意的是,在这种情况下,我们不能使用_来忽略索引,因为我们需要访问每个元素的值和索引。因此,我们需要显式地将索引变量命名为i或其他名称。
这个函数仍然接受任意数量的int类型参数,并将它们视为一个int类型的切片。
defer
defer是Go语言的一个关键字,它可以让我们在函数执行完毕之后再执行一些特定的操作。无论函数是通过return正常返回,还是触发了panic异常,defer语句都能够确保在函数退出前被执行。
下面是一个简单的例子,演示defer语句的使用:
func main() {
defer fmt.Println("deferred statement")
fmt.Println("hello")
}
在这个例子中,我们在main函数中使用了defer语句,将一条语句fmt.Println("deferred statement")推迟到函数返回前执行。在函数体中,我们先输出了一条hello语句,然后函数执行完毕,defer语句被执行,输出了deferred statement。最终,程序退出。
defer语句的执行顺序是后进先出,也就是说,最后一个defer语句会最先执行,而第一个defer语句会最后执行。例如:
func main() {
defer fmt.Println("deferred statement 1")
defer fmt.Println("deferred statement 2")
defer fmt.Println("deferred statement 3")
fmt.Println("hello")
}
在这个例子中,我们使用了三个defer语句,分别输出了三条deferred statement语句。在函数体中,我们先输出了一条hello语句。最终,程序退出时,defer语句会按照后进先出的顺序执行,先输出deferred statement 3,然后是deferred statement 2,最后是deferred statement 1。
func foo() (string, int) {
a, b := 3, 5
c := a + b
defer fmt.Println("deferred statement 1", c)
defer fmt.Println("deferred statement 2", c)
defer func() {
defer fmt.Println("deferred statement 3", c)
}()
c = 100
fmt.Println("hello")
return "result:", c
}
func main(){
foo()
}
/*
hello
deferred statement 3 100
deferred statement 2 8
deferred statement 1 8
*/
defer语句中的变量c的值是在调用defer语句时确定的,而不是在执行defer语句时确定的。因此,第一个和第二个defer语句中输出的变量c的值都是8,而第三个defer语句中输出的变量c的值是100。这是因为在第三个defer语句中,我们使用了一个匿名函数,延迟了defer语句的执行,使得变量c的值在执行时已经被修改为了100。
数组
声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var arrayName [size]dataType
其中,arrayName 是数组的名称,size 是数组的大小,dataType 是数组中元素的数据类型。
以下定义了数组 balance 长度为 10 类型为 float32:
var balance [10]float32
package main
import "fmt"
func main() {
var n [10]int /* n 是一个长度为 10 的数组 */
var i,j int
/* 为数组 n 初始化元素 */
for i = 0; i < 10; i++ {
n[i] = i + 100 /* 设置元素为 i + 100 */
}
/* 输出每个数组元素的值 */
for j = 0; j < 10; j++ {
fmt.Printf("Element[%d] = %d\n", j, n[j] )
}
}
Element[0] = 100
Element[1] = 101
Element[2] = 102
Element[3] = 103
Element[4] = 104
Element[5] = 105
Element[6] = 106
Element[7] = 107
Element[8] = 108
Element[9] = 109
package main
import "fmt"
func main() {
var i,j,k int
// 声明数组的同时快速初始化数组
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
/* 输出数组元素 */ ...
for i = 0; i < 5; i++ {
fmt.Printf("balance[%d] = %f\n", i, balance[i] )
}
balance2 := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
/* 输出每个数组元素的值 */
for j = 0; j < 5; j++ {
fmt.Printf("balance2[%d] = %f\n", j, balance2[j] )
}
// 将索引为 1 和 3 的元素初始化
balance3 := [5]float32{1:2.0,3:7.0}
for k = 0; k < 5; k++ {
fmt.Printf("balance3[%d] = %f\n", k, balance3[k] )
}
}
balance[0] = 1000.000000
balance[1] = 2.000000
balance[2] = 3.400000
balance[3] = 7.000000
balance[4] = 50.000000
balance2[0] = 1000.000000
balance2[1] = 2.000000
balance2[2] = 3.400000
balance2[3] = 7.000000
balance2[4] = 50.000000
balance3[0] = 0.000000
balance3[1] = 2.000000
balance3[2] = 0.000000
balance3[3] = 7.000000
balance3[4] = 0.000000
多维数组
二维数组
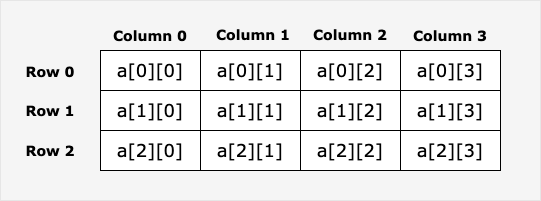
二维数组是最简单的多维数组,二维数组本质上是由一维数组组成的。二维数组定义方式如下:
var arrayName [ x ][ y ] variable_type
variable_type 为 Go 语言的数据类型,arrayName 为数组名,二维数组可认为是一个表格,x 为行,y 为列,下图演示了一个二维数组 a 为三行四列:
package main
import "fmt"
func main() {
// Step 1: 创建数组
values := [][]int{}
// Step 2: 使用 append() 函数向空的二维数组添加两行一维数组
row1 := []int{1, 2, 3}
row2 := []int{4, 5, 6}
values = append(values, row1)
values = append(values, row2)
// Step 3: 显示两行数据
fmt.Println("Row 1")
fmt.Println(values[0])
fmt.Println("Row 2")
fmt.Println(values[1])
// Step 4: 访问第一个元素
fmt.Println("第一个元素为:")
fmt.Println(values[0][0])
}
Row 1
[1 2 3]
Row 2
[4 5 6]
第一个元素为:
1
初始化二维数组
多维数组可通过大括号来初始值。以下实例为一个 3 行 4 列的二维数组:
a := [3][4]int{
{0, 1, 2, 3} , /* 第一行索引为 0 */
{4, 5, 6, 7} , /* 第二行索引为 1 */
{8, 9, 10, 11}, /* 第三行索引为 2 */
}
package main
import "fmt"
func main() {
// 创建二维数组
sites := [2][2]string{}
// 向二维数组添加元素
sites[0][0] = "Google"
sites[0][1] = "Runoob"
sites[1][0] = "Taobao"
sites[1][1] = "Weibo"
// 显示结果
fmt.Println(sites)
}
[[Google Runoob] [Taobao Weibo]]
访问二维数组
二维数组通过指定坐标来访问。如数组中的行索引与列索引,例如:
val := a[2][3]
或
var value int = a[2][3]
package main
import "fmt"
func main() {
/* 数组 - 5 行 2 列*/
var a = [5][2]int{ {0,0}, {1,2}, {2,4}, {3,6},{4,8}}
var i, j int
/* 输出数组元素 */
for i = 0; i < 5; i++ {
for j = 0; j < 2; j++ {
fmt.Printf("a[%d][%d] = %d\n", i,j, a[i][j] )
}
}
}
结构体
在Go语言中,结构体(struct)是一种自定义的数据类型,它可以包含多个字段,每个字段都有自己的类型和值。结构体的定义和使用也非常简单。例如,我们可以定义一个名为Dog的结构体,它包含了两个字段:Name和Age。
type Dog struct {
Name string
Age int
}
在这个例子中,我们定义了一个名为Dog的结构体,它包含了两个字段:Name和Age。这个结构体可以用来表示一只狗的信息,包括它的名字和年龄。
切片
Go语言中的切片是一种灵活、动态的数据结构,它与数组类似,但长度是可变的。切片函数是用于操作切片的一系列内置函数,包括len()、cap()、nil、append()、copy()等等。
len()函数
len()函数用于获取切片的长度,即切片中元素的个数。例如,下面的代码展示了如何使用len()函数获取切片的长度:
s := []int{1, 2, 3, 4, 5}
fmt.Println(len(s)) // 输出:5
这是一个包含5个整数的切片,切片名为s,元素为1、2、3、4、5。可以通过下标访问切片中的元素,例如s[0]表示获取第一个元素,即1。
在上面的代码中,使用len()函数获取切片s的长度,即5。
cap()函数
cap()函数用于获取切片的容量,即切片可以容纳的元素个数。例如,下面的代码展示了如何使用cap()函数获取切片的容量:
s := make([]int, 5, 10)
fmt.Println(cap(s)) // 输出:10
在上面的代码中,使用make()函数创建一个切片,长度为5,容量为10,使用cap()函数获取切片s的容量,即10。
容量表示切片底层数组的长度,长度表示切片中元素的个数。
(make函数,像是规定一个盒子,盒子大小是能放10个东西,长度是你放了5个东西在能放10个东西的盒子里面)
nil切片
nil切片是指没有分配任何数据空间的切片,它的长度和容量为0。在Go语言中,切片的零值就是nil切片。例如,下面的代码展示了如何创建一个nil切片:
var s []int
fmt.Println(s == nil) // 输出:true
在上面的代码中,定义一个变量s,它的类型为[]int,由于没有分配任何数据空间,s就是一个nil切片。
append()函数
append()函数用于向切片中追加元素,可以一次追加一个或多个元素。如果切片容量不足以容纳新元素,则会自动扩容。例如,下面的代码展示了如何使用append()函数向切片中追加元素:
s := []int{1, 2, 3}
s = append(s, 4, 5, 6)
fmt.Println(s) // 输出:[1 2 3 4 5 6]
在上面的代码中,定义一个切片s,包含元素1、2、3,使用append()函数向切片s中追加元素4、5、6,最终s包含元素1、2、3、4、5、6。
copy()函数
copy()函数用于将一个切片的内容复制到另一个切片中。例如,下面的代码展示了如何使用copy()函数复制切片:
s1 := []int{1, 2, 3}
s2 := make([]int, len(s1))
copy(s2, s1)
fmt.Println(s2) // 输出:[1 2 3]
在上面的代码中,定义一个切片s1,包含元素1、2、3,使用make()函数创建一个长度与s1相同的切片s2,使用copy()函数将s1中的内容复制到s2中,最终s2包含元素1、2、3。
集合
Go语言中的map是一种无序的键值对集合,其中每个键唯一对应一个值。map中的所有键和所有值的类型必须相同,可以是任何内置或自定义类型。下面是一个简单的例子,代码中注释有详细说明:
package main
import "fmt"
func main() {
// 创建一个空的map,键为string类型,值为int类型
m1 := make(map[string]int)
// 向map中添加键值对
m1["a"] = 1
m1["b"] = 2
m1["c"] = 3
// 获取map中指定键的值
fmt.Println("m1[a] =", m1["a"]) // 输出 m1[a] = 1
// 获取map的长度
fmt.Println("len(m1) =", len(m1)) // 输出 len(m1) = 3
// 判断map中是否存在指定键
val, ok := m1["d"]
if ok {
fmt.Println("m1[d] =", val)
} else {
fmt.Println("m1[d] does not exist")
}//m1[d] does not exist
// 删除map中的指定键值对
delete(m1, "c")
// 遍历map中的键值对
for k, v := range m1 {
fmt.Println(k, v)
}
/*
a 1
b 2
*/
}
- 这个例子中,我们首先创建了一个空的map,键为string类型,值为int类型。
- 然后我们向map中添加了三个键值对,分别是"a":1、"b":2和"c":3。我们可以通过指定键来获取map中的值,例如m1["a"]返回1。我们可以使用len()函数获取map的长度,例如len(m1)返回3。
- 我们可以通过判断第二个返回值来判断map中是否存在指定的键,例如val, ok := m1["d"],如果键"d"不存在,ok将为false,否则将为true,并且val将为键"d"对应的值。
- 我们可以使用delete()函数删除map中的指定键值对,例如delete(m1, "c")将删除键"c"对应的值3。
- 最后我们使用for循环遍历map中的所有键值对,并输出它们的键和值。
(可以看作SQL里面的建表,create table test ( string int );,insert into test (string,int) values (a,1))
(ok := 就是判断是否有这个值)
范围
package main
import "fmt"
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
以上实例运行输出结果为:
2**0 = 1
2**1 = 2
2**2 = 4
2**3 = 8
2**4 = 16
2**5 = 32
2**6 = 64
2**7 = 128
for 循环的 range 格式可以省略 key 和 value
package main
import "fmt"
func main() {
map1 := make(map[int]float32)
map1[1] = 1.0
map1[2] = 2.0
map1[3] = 3.0
map1[4] = 4.0
// 读取 key 和 value
for key, value := range map1 {
fmt.Printf("key is: %d - value is: %f\n", key, value)
}
// 读取 key
for key := range map1 {
fmt.Printf("key is: %d\n", key)
}
// 读取 value
for _, value := range map1 {
fmt.Printf("value is: %f\n", value)
}
}
key is: 4 - value is: 4.000000
key is: 1 - value is: 1.000000
key is: 2 - value is: 2.000000
key is: 3 - value is: 3.000000
key is: 1
key is: 2
key is: 3
key is: 4
value is: 1.000000
value is: 2.000000
value is: 3.000000
value is: 4.000000
package main
import "fmt"
func main(){
nums := []int{1,2,3,4}
for i,num := range nums {
fmt.Printf("索引是%d,长度是%d\n",i, num)
}
}
索引是0,长度是1
索引是1,长度是2
索引是2,长度是3
索引是3,长度是4
make函数
s := make([]int, 5, 10)
fmt.Println(cap(s)) // 输出:10
(make函数,像是规定一个盒子,盒子大小是能放10个东西,长度是你放了5个东西在能放10个东西的盒子里面)
类型转换
Go 语言类型转换基本格式如下:
type_name(expression)
type_name 为类型,expression 为表达式。
数值类型转换
以下实例中将整型转化为浮点型,并计算结果,将结果赋值给浮点型变量:
package main
import "fmt"
func main() {
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
fmt.Printf("mean 的值为: %f\n",mean)
}
mean 的值为: 3.400000
字符串类型转换
将一个字符串转换成另一个类型,可以使用以下语法:
var str string = "10"
var num int
num, _ = strconv.Atoi(str)
以上代码将字符串变量 str 转换为整型变量 num。strconv.Atoi 函数返回两个值,第一个是转换后的整型值,第二个是可能发生的错误,我们可以使用空白标识符 _ 来忽略这个错误
package main
import (
"fmt"
"strconv"
)
func main() {
str := "123"
num, err := strconv.Atoi(str)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转换为整数为:%d\n", str, num)
}
}
以上实例执行输出结果为:
字符串 '123' 转换为整数为:123
package main
import (
"fmt"
"strconv"
)
func main() {
num := 123
str := strconv.Itoa(num)
fmt.Printf("整数 %d 转换为字符串为:'%s'\n", num, str)
}
以上实例执行输出结果为:
整数 123 转换为字符串为:'123'
package main
import (
"fmt"
"strconv"
)
func main() {
str := "3.14"
num, err := strconv.ParseFloat(str, 64)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转为浮点型为:%f\n", str, num)
}
}
以上实例执行输出结果为:
字符串 '3.14' 转为浮点型为:3.140000
package main
import (
"fmt"
"strconv"
)
func main() {
num := 3.14
str := strconv.FormatFloat(num, 'f', 2, 64)
fmt.Printf("浮点数 %f 转为字符串为:'%s'\n", num, str)
}
以上实例执行输出结果为:
浮点数 3.140000 转为字符串为:'3.14'
接口类型转换
类型断言和类型转换
类型断言用于将接口类型转换为指定类型,其语法为:
value.(type)
或者
value.(T)
其中 value 是接口类型的变量,type 或 T 是要转换成的类型。
如果类型断言成功,它将返回转换后的值和一个布尔值,表示转换是否成功。
package main
import "fmt"
func main() {
var i interface{} = "Hello, World"
str, ok := i.(string)
if ok {
fmt.Printf("'%s' is a string\n", str)
} else {
fmt.Println("conversion failed")
}
}
以上实例中,我们定义了一个接口类型变量 i,并将它赋值为字符串 "Hello, World"。然后,我们使用类型断言将 i 转换为字符串类型,并将转换后的值赋值给变量 str。最后,我们使用 ok 变量检查类型转换是否成功,如果成功,我们打印转换后的字符串;否则,我们打印转换失败的消息。
类型转换用于将一个接口类型的值转换为另一个接口类型,其语法为:
T(value)
T 是目标接口类型,value 是要转换的值。
在类型转换中,我们必须保证要转换的值和目标接口类型之间是兼容的,否则编译器会报错。
package main
import "fmt"
type Writer interface {
Write([]byte) (int, error)
}
type StringWriter struct {
str string
}
func (sw *StringWriter) Write(data []byte) (int, error) {
sw.str += string(data)
return len(data), nil
}
func main() {
var w Writer = &StringWriter{}
sw := w.(*StringWriter)
sw.str = "Hello, World"
fmt.Println(sw.str)
}
以上实例中,我们定义了一个 Writer 接口和一个实现了该接口的结构体 StringWriter。然后,我们将 StringWriter 类型的指针赋值给 Writer 接口类型的变量 w。接着,我们使用类型转换将 w 转换为 StringWriter 类型,并将转换后的值赋值给变量 sw。最后,我们使用 sw 访问 StringWriter 结构体中的字段 str,并打印出它的值。
类型推断
a := 123
var a = 123
var a int = 123.0
上述三个语句是等效的。但编译阶段的执行细节是不同的。
1.a := 123 会显式的触发类型推断,编译器解析右边的每一个字符为十进制数字(IntLit),然后构建为一个整型节点,在类型检查的时候,将其类型赋值给左边的节点变量a。
2.由于var a = 123左边的a未显式指定其类型,因此仍然会触发类型推断,ir.AssignStmt.Def=false,过程同上,依然在类型检查的时候,将123的类型赋值给左边的a。
3.对于var a int = 123.0, 由于123.0包含小数点'.',编译器解析右边的每一个字符为十进制浮点数(FloatLit),由于赋值操作符=左边显式定义了a的类型为int, 因此在类型检查阶段,右边的123.0会发生隐式类型转换,因为类型兼容,会转换为整型123。因此对于显式指定类型的表达式不会发生类型推断。
错误处理
- 错误处理的原则就是不能丢弃任何有返回err的调用,不要使用 _ 丢弃,必须全部处理。接收到错误,要么返回err,或者使用log记录下来
- 尽早return:一旦有错误发生,马上返回
- 尽量不要使用panic,除非你知道你在做什么
- 错误描述如果是英文必须为小写,不需要标点结尾
- 采用独立的错误流进行处理
// 错误写法
if err != nil {
// error handling
} else {
// normal code
}
// 正确写法
if err != nil {
// error handling
return // or continue, etc.
}
// normal code
type User struct {
username string
password string
}
// 初始化User对象的方法
func (p *User) init(username string ,password string) (*User, string) {
// 检查用户名和密码是否为空
if "" == username || "" == password {
return p, p.Error()
}
// 初始化User对象的属性
p.username = username
p.password = password
return p, ""
}
// 返回错误消息字符串的方法
func (p *User) Error() string {
return "Username or password shouldn't be empty!"
}
func main() {
var user User
user1, _ := user.init("", "")
fmt.Println(user1)
}
结果:
Usernam or password shouldn't be empty!
这段代码定义了一个名为User的结构体,包含username和password两个属性。
这是User结构体的init方法,通过指针接收者(*User)来关联该方法与结构体。该方法接受username和password作为参数,并将其赋值给结构体的属性。如果其中任意一个参数为空字符串,则返回当前的User指针和一个错误字符串。否则,将参数赋值给结构体的属性,并返回当前的User指针和一个空字符串。
这是User结构体的Error方法,同样使用指针接收者来关联该方法与结构体。该方法返回一个错误字符串,指示用户名或密码不应为空。
在main函数中,首先声明了一个User类型的变量user。然后调用user.init方法,并将空字符串作为参数传递给该方法。返回的结果被存储在user1变量中,但由于使用了空标识符 _,忽略了第二个返回值。最后,使用fmt.Println打印出user1的值。
总体上,该程序的功能是创建一个User对象并初始化其属性。如果传递的用户名或密码为空,则返回错误消息。在示例中,由于传递了空字符串作为参数,因此输出的结果将是一个指向未初始化的User对象的指针。
panic()和recover()
Golang中引入两个内置函数panic和recover来触发和终止异常处理流程,同时引入关键字defer来延迟执行defer后面的函数。 一直等到包含defer语句的函数执行完毕时,延迟函数(defer后的函数)才会被执行,而不管包含defer语句的函数是通过return的正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。 当程序运行时,如果遇到引用空指针、下标越界或显式调用panic函数等情况,则先触发panic函数的执行,然后调用延迟函数。调用者继续传递panic,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。如果一路在延迟函数中没有recover函数的调用,则会到达该协程的起点,该协程结束,然后终止其他所有协程,包括主协程(类似于C语言中的主线程,该协程ID为1)。
panic: 1、内建函数 2、假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行 3、返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行,这里的defer 有点类似 try-catch-finally 中的 finally 4、直到goroutine整个退出,并报告错误
recover: 1、内建函数 2、用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为 3、一般的调用建议 a). 在defer函数中,通过recever来终止一个gojroutine的panicking过程,从而恢复正常代码的执行 b). 可以获取通过panic传递的error
简单来讲:go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
错误和异常从Golang机制上讲,就是error和panic的区别。很多其他语言也一样,比如C++/Java,没有error但有errno,没有panic但有throw。
Golang错误和异常是可以互相转换的:
错误转异常,比如程序逻辑上尝试请求某个URL,最多尝试三次,尝试三次的过程中请求失败是错误,尝试完第三次还不成功的话,失败就被提升为异常了。
异常转错误,比如panic触发的异常被recover恢复后,将返回值中error类型的变量进行赋值,以便上层函数继续走错误处理流程。
以下给出异常处理的作用域(场景):
- 空指针引用
- 下标越界
- 除数为0
- 不应该出现的分支,比如default
- 输入不应该引起函数错误
错误处理实践
1.失败的原因只有一个时,不使用error
func (self *AgentContext) CheckHostType(host_type string) error {
switch host_type {
case "virtual_machine":
return nil
case "bare_metal":
return nil
}
return errors.New("CheckHostType ERROR:" + host_type)
}
我们可以看出,该函数失败的原因只有一个,所以返回值的类型应该为bool,而不是error,重构一下代码:
func (self *AgentContext) IsValidHostType(hostType string) bool {
return hostType == "virtual_machine" || hostType == "bare_metal"
}
说明:大多数情况,导致失败的原因不止一种,尤其是对I/O操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的bool,而是error。
2.没有失败时,不使用error
error在Golang中是如此的流行,以至于很多人设计函数时不管三七二十一都使用error,即使没有一个失败原因。 我们看一下示例代码:
func (self *CniParam) setTenantId() error {
self.TenantId = self.PodNs
return nil
}
对于上面的函数设计,就会有下面的调用代码:
err := self.setTenantId()
if err != nil {
// log
// free resource
return errors.New(...)
}
根据我们的正确姿势,重构一下代码:
func (self *CniParam) setTenantId() {
self.TenantId = self.PodNs
}
于是调用代码变为:
self.setTenantId()
3.error应放在返回值类型列表的最后
对于返回值类型error,用来传递错误信息,在Golang中通常放在最后一个。
resp, err := http.Get(url)
if err != nil {
return nill, err
}
bool作为返回值类型时也一样。
value, ok := cache.Lookup(key)
if !ok {
// ...cache[key] does not exist…
}
4.错误值统一定义,而不是跟着感觉走
很多人写代码时,到处return errors.New(value),而错误value在表达同一个含义时也可能形式不同,比如“记录不存在”的错误value可能为:
"record is not existed."
"record is not exist!"
"###record is not existed!!!"
...
这使得相同的错误value撒在一大片代码里,当上层函数要对特定错误value进行统一处理时,需要漫游所有下层代码,以保证错误value统一,不幸的是有时会有漏网之鱼,而且这种方式严重阻碍了错误value的重构。
于是,我们可以参考C/C++的错误码定义文件,在Golang的每个包中增加一个错误对象定义文件,如下所示:
var ERR_EOF = errors.New("EOF")
var ERR_CLOSED_PIPE = errors.New("io: read/write on closed pipe")
var ERR_NO_PROGRESS = errors.New("multiple Read calls return no data or error")
var ERR_SHORT_BUFFER = errors.New("short buffer")
var ERR_SHORT_WRITE = errors.New("short write")
var ERR_UNEXPECTED_EOF = errors.New("unexpected EOF")
5.错误逐层传递时,层层都加日志
层层都加日志非常方便故障定位。
说明:至于通过测试来发现故障,而不是日志,目前很多团队还很难做到。如果你或你的团队能做到,那么请忽略这个姿势。
6.错误处理使用defer
我们一般通过判断error的值来处理错误,如果当前操作失败,需要将本函数中已经create的资源destroy掉,示例代码如下:
func deferDemo() error {
err := createResource1()
if err != nil {
return ERR_CREATE_RESOURCE1_FAILED
}
err = createResource2()
if err != nil {
destroyResource1()
return ERR_CREATE_RESOURCE2_FAILED
}
err = createResource3()
if err != nil {
destroyResource1()
destroyResource2()
return ERR_CREATE_RESOURCE3_FAILED
}
err = createResource4()
if err != nil {
destroyResource1()
destroyResource2()
destroyResource3()
return ERR_CREATE_RESOURCE4_FAILED
}
return nil
}
当Golang的代码执行时,如果遇到defer的闭包调用,则压入堆栈。当函数返回时,会按照后进先出的顺序调用闭包。 对于闭包的参数是值传递,而对于外部变量却是引用传递,所以闭包中的外部变量err的值就变成外部函数返回时最新的err值。
根据这个结论,我们重构上面的示例代码:
func deferDemo() error {
err := createResource1()
if err != nil {
return ERR_CREATE_RESOURCE1_FAILED
}
defer func() {
if err != nil {
destroyResource1()
}
}()
err = createResource2()
if err != nil {
return ERR_CREATE_RESOURCE2_FAILED
}
defer func() {
if err != nil {
destroyResource2()
}
}()
err = createResource3()
if err != nil {
return ERR_CREATE_RESOURCE3_FAILED
}
defer func() {
if err != nil {
destroyResource3()
}
}()
err = createResource4()
if err != nil {
return ERR_CREATE_RESOURCE4_FAILED
}
return nil
}
7.当尝试几次可以避免失败时,不要立即返回错误
如果错误的发生是偶然性的,或由不可预知的问题导致。一个明智的选择是重新尝试失败的操作,有时第二次或第三次尝试时会成功。在重试时,我们需要限制重试的时间间隔或重试的次数,防止无限制的重试。
两个案例:
我们平时上网时,尝试请求某个URL,有时第一次没有响应,当我们再次刷新时,就有了惊喜。
团队的一个QA曾经建议当Neutron的attach操作失败时,最好尝试三次,这在当时的环境下验证果然是有效的。
8.当上层函数不关心错误时,建议不返回error
对于一些资源清理相关的函数(destroy/delete/clear),如果子函数出错,打印日志即可,而无需将错误进一步反馈到上层函数,因为一般情况下,上层函数是不关心执行结果的,或者即使关心也无能为力,于是我们建议将相关函数设计为不返回error。
9.当发生错误时,不忽略有用的返回值
通常,当函数返回non-nil的error时,其他的返回值是未定义的(undefined),这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read函数会返回可以读取的字节数以及错误信息。对于这种情况,应该将读取到的字符串和错误信息一起打印出来。
说明:对函数的返回值要有清晰的说明,以便于其他人使用。
异常处理实践
1.在程序开发阶段,坚持速错
速错,简单来讲就是“让它挂”,只有挂了你才会第一时间知道错误。在早期开发以及任何发布阶段之前,最简单的同时也可能是最好的方法是调用panic函数来中断程序的执行以强制发生错误,使得该错误不会被忽略,因而能够被尽快修复。
2.在程序部署后,应恢复异常避免程序终止
在Golang中,某个Goroutine如果panic了,并且没有recover,那么整个Golang进程就会异常退出。所以,一旦Golang程序部署后,在任何情况下发生的异常都不应该导致程序异常退出,我们在上层函数中加一个延迟执行的recover调用来达到这个目的,并且是否进行recover需要根据环境变量或配置文件来定,默认需要recover。 这个姿势类似于C语言中的断言,但还是有区别:一般在Release版本中,断言被定义为空而失效,但需要有if校验存在进行异常保护,尽管契约式设计中不建议这样做。在Golang中,recover完全可以终止异常展开过程,省时省力。
我们在调用recover的延迟函数中以最合理的方式响应该异常:
打印堆栈的异常调用信息和关键的业务信息,以便这些问题保留可见;
将异常转换为错误,以便调用者让程序恢复到健康状态并继续安全运行。
我们看一个简单的例子:
func funcA() error {
defer func() {
if p := recover(); p != nil {
fmt.Printf("panic recover! p: %v", p)
debug.PrintStack()
}
}()
return funcB()
}
func funcB() error {
// simulation
panic("foo")
return errors.New("success")
}
func test() {
err := funcA()
if err == nil {
fmt.Printf("err is nil\\n")
} else {
fmt.Printf("err is %v\\n", err)
}
}
我们期望test函数的输出是:
err is foo
实际上test函数的输出是:
err is nil
原因是panic异常处理机制不会自动将错误信息传递给error,所以要在funcA函数中进行显式的传递,代码如下所示:
func funcA() (err error) {
defer func() {
if p := recover(); p != nil {
fmt.Println("panic recover! p:", p)
str, ok := p.(string)
if ok {
err = errors.New(str)
} else {
err = errors.New("panic")
}
debug.PrintStack()
}
}()
return funcB()
}
3.对于不应该出现的分支,使用异常处理
当某些不应该发生的场景发生时,我们就应该调用panic函数来触发异常。比如,当程序到达了某条逻辑上不可能到达的路径:
switch s := suit(drawCard()); s {
case "Spades":
// ...
case "Hearts":
// ...
case "Diamonds":
// ...
case "Clubs":
// ...
default:
panic(fmt.Sprintf("invalid suit %v", s))
}
4.针对入参不应该有问题的函数,使用panic设计
入参不应该有问题一般指的是硬编码,我们先看这两个函数(Compile和MustCompile),其中MustCompile函数是对Compile函数的包装:
func MustCompile(str string) *Regexp {
regexp, error := Compile(str)
if error != nil {
panic(`regexp: Compile(` + quote(str) + `): ` + error.Error())
}
return regexp
}
所以,对于同时支持用户输入场景和硬编码场景的情况,一般支持硬编码场景的函数是对支持用户输入场景函数的包装。 对于只支持硬编码单一场景的情况,函数设计时直接使用panic,即返回值类型列表中不会有error,这使得函数的调用处理非常方便(没有了乏味的"if err != nil {/ 打印 && 错误处理 /}"代码块)。
深入了解
依赖管理(Go Modules)
go mod init <module>:初始化一个新的模块,生成go.mod文件。go mod tidy:根据go.mod文件,检查当前模块所需的依赖,并将它们添加到go.mod文件中。go mod vendor:将当前模块所需的依赖复制到vendor/目录中。go mod download:下载当前模块所需的所有依赖。go mod graph:打印当前模块依赖关系图。go mod verify:验证依赖是否正确并且没有被篡改。go mod why <module>:解释为什么需要依赖某个模块。go list -m all:列出所有的依赖模块。
实践
(VMware Workstation,Ubuntu 22.04 LTS,FinalShell)
go version
mkdir Workspace
mkdir Workspace/Space{1..2}
mkdir Workspace/Space2/Space3
cd Workspace
go mod init Test_go
cat Test_go
(Space1,Test_main.go)
package main
import (
"fmt"
"Test_go/Space2"
math "Test_go/Space2/Space3"
"github.com/bytedance/sonic"
)
func main(){
fmt.Println(util.Name)
fmt.Println(util.Add(3,4))
fmt.Println(math.Add(1,2,3))
bytes,_ := sonic.Marshal("hello")
fmt.Println(string(bytes))
}
(Space2,a.go)
package util
import "fmt"
var Name="Mugetsu"
func Add(a,b int) int{
return a+b
}
func init(){
fmt.Println("init util package")
}
(Space3,b.go)
package maths
import "fmt"
func sub (a,b int) int{
return a-b
}
func init(){
fmt.Println("init maths package")
}
(Space3,c.go)
package maths
func Add(a,b,c int) int{
return a+sub(b,c)
}
go run Test_main.go
/*
init util package
init maths package
Mugetsu
7
0
"hello"
*/
import里用工作区相对路径,大写函数为可以跨路径调用,小写函数不能调用
json序列化
在 Go 语言中,可以使用 encoding/json 包来实现 JSON 序列化和反序列化。下面是一个示例代码,同时加上了详细的注释说明:
package main
import (
"encoding/json"
"fmt"
)
type Person struct { // 定义一个结构体类型
Name string `json:"name"` // 指定结构体字段对应的 JSON 名称
Age int `json:"age"`
}
func main() {
// JSON 序列化
p := Person{Name: "张三", Age: 18} // 创建一个 Person 类型的变量
b, err := json.Marshal(p) // 将 Person 类型的变量 p 转换为 JSON 字节切片
if err != nil { // 如果转换失败,输出错误信息并退出程序
fmt.Println("JSON 序列化失败:", err)
return
}
fmt.Println("JSON 序列化结果:", string(b)) // 如果转换成功,输出 JSON 字符串
// JSON 反序列化
var p1 Person // 定义一个 Person 类型的变量
err = json.Unmarshal(b, &p1) // 将 JSON 字节切片 b 转换为 Person 类型的变量 p1
if err != nil { // 如果转换失败,输出错误信息并退出程序
fmt.Println("JSON 反序列化失败:", err)
return
}
fmt.Printf("JSON 反序列化结果:name=%s, age=%d\n", p1.Name, p1.Age) // 如果转换成功,输出反序列化结果
}
在这个示例中,我们定义了一个 Person 结构体类型,其中包含 Name 和 Age 两个字段。我们使用 json 标签来指定结构体字段的 JSON 名称,这样在序列化和反序列化时就可以按照指定的名称进行转换。
接下来,我们使用 json.Marshal 函数将 Person 类型的变量 p 转换为 JSON 字节切片。如果转换失败,输出错误信息并退出程序。如果转换成功,输出 JSON 字符串。
然后,我们使用 json.Unmarshal 函数将 JSON 字节切片 b 转换为 Person 类型的变量 p1。如果转换失败,输出错误信息并退出程序。如果转换成功,输出反序列化结果。
需要注意的是,JSON 序列化和反序列化时,结构体的字段必须是可导出的(即首字母大写),否则无法进行转换。
接口(Interfaces)
Go语言中的接口(interface)是一种类型,它定义了一组方法的集合。实现这些方法的任何类型都可以被称为这个接口的实现类型。接口的定义和使用能够大大提高代码的灵活性和可复用性。
定义接口
在Go语言中,定义接口非常简单,只需要使用interface关键字即可。例如,我们可以定义一个名为Animal的接口,它包含两个方法:Eat()和Sleep()。
type Animal interface {
Eat()
Sleep()
}
在这个例子中,我们定义了一个名为Animal的接口,它包含了两个方法:Eat()和Sleep()。任何实现了这两个方法的类型都可以被称为Animal接口的实现类型。
接口的实现
在Go语言中,要实现一个接口,只需要实现这个接口中定义的所有方法即可。例如,我们可以定义一个名为Poodle的类型,它实现了Animal接口中的两个方法:Eat()和Sleep()。
type Poodle struct {
Name string
Age int
}
func (p *Poodle) Eat() {
fmt.Printf("%s is eating.\n", p.Name)
}
func (p *Poodle) Sleep() {
fmt.Printf("%s is sleeping.\n", p.Name)
}
在这个例子中,我们定义了一个名为Poodle的类型,它包含了两个字段:Name和Age。同时,我们实现了Animal接口中的两个方法:Eat()和Sleep()。在Eat()方法中,我们输出了一条狗正在吃的信息;在Sleep()方法中,我们输出了一条狗正在睡觉的信息。
使用接口
在Go语言中,使用接口非常简单,只需要将实现了接口的类型赋值给接口变量即可。例如,我们可以创建一个名为animal的Animal接口变量,并将一个Poodle类型的值赋值给它。
func main() {
var animal Animal
poodle := &Poodle{Name: "Fido", Age: 2}
animal = poodle
animal.Eat()
animal.Sleep()
}
在这个例子中,我们首先创建了一个名为animal的Animal接口变量。然后,我们创建了一个Poodle类型的值,并将它赋值给animal。最后,我们在animal变量上调用了接口中定义的两个方法:Eat()和Sleep()。这两个方法实际上是Poodle类型中定义的方法,但是由于Poodle类型实现了Animal接口,因此我们可以将它赋值给Animal接口变量,并在Animal接口上调用这两个方法。
我理解的例子
(网上给的例子我实在看不懂,我只能通过我学过的东西来定义)
这里假设我要用iostat命令去查看磁盘占用率。
Device tps kB_read/s kB_wrtn/s kB_dscd/s %util
sda 0.10 0.00 3.87 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00
在shell里面,使用的命令是
iostat -d -x -k | grep 'sda' | awk '{print $1,$NF}'
用-d和-x显示,grep过滤到sda,再awk格式化文本输出Device和util
用Go语言接口来体现就是如下
package main
import (
"fmt"
"os/exec"
"strings"
)
type iostat interface {
GetDevice() string
GetUtil() float64
}
type script struct {
name string
util float64
}
func (s *script) GetDevice() string {
return s.name
}
func (s *script) GetUtil() float64 {
return s.util
}
func main() {
// 执行 iostat -d -x -k | grep 'sda' | awk '{print $1,$NF}' 命令
cmd := exec.Command("sh", "-c", "iostat -d -x -k | grep 'sda' | awk '{print $1,$NF}'")
//输出的结果为sda 0.00
output, err := cmd.Output()
if err != nil {
fmt.Println("Error:", err)
return
}
// 解析 awk 命令的输出
fields := strings.Fields(string(output)) //用strings.Fields()函数切片输出结果
if len(fields) != 2 {
fmt.Println("Error: unexpected output format")
return
}
s := &script{name: fields[0]}
fmt.Sscanf(fields[1], "%f", &s.util) //占用率为浮点型
// 输出结果
fmt.Println(s.GetDevice())
fmt.Println(s.GetUtil())
}
func Fields(str string) []stringstr子字符串的切片或者如果str仅包含空格,则返回空切片。
fmt.Sscanf(fields[1], "%f", &s.util)占用率是浮点型,不能用fmt.Printf。
我的理解
将一个输出结果,用结构体(script)连接进入接口(iostat)将里面的信息提取出来(Device和%util),然后输出结果。
(用生活化的例子来说。你买了一杯珍珠奶茶,珍珠奶茶里面有珍珠(信息,Device和%util),奶茶顶上有塑封的纸(接口,iostat)。你通过吸管(结构体,script)插进你的纸,然后把珍珠吸进你的口腔里,然后吃掉(输出结果)。)
上下文(Context)
Go 语言基础之 Context 详解 | zhihu | 程序员祝融
Go语言中的Context(上下文)是一个非常重要的特性,它在Go 1.7版本中引入,主要用于在goroutine之间传递各种信息,如截止日期、取消信号、超时时间等。Context的核心在于它的接口定义,允许开发者通过特定的方法来创建和操作Context,从而在多个Goroutine之间进行有效的通信。
基本用法
在 Go 语言中,Context 被定义为一个接口类型,它包含了三个方法:
# go version 1.18.10
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}
- Deadline() 方法用于获取 Context 的截止时间;
- Done() 方法用于返回一个只读的 channel,用于通知当前 Context 是否已经被取消;
- Err() 方法用于获取 Context 取消的原因;
- Value() 方法用于获取 Context 中保存的键值对数据。
func users(ctx context.Context, request *Request) {
// ... code
}
deadline, ok := ctx.Deadline()
if ok && deadline.Before(time.Now()) {
// 超时
return
}
协程(Goroutine)
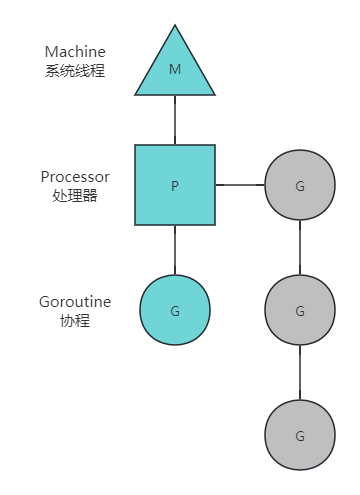
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
线程堵塞
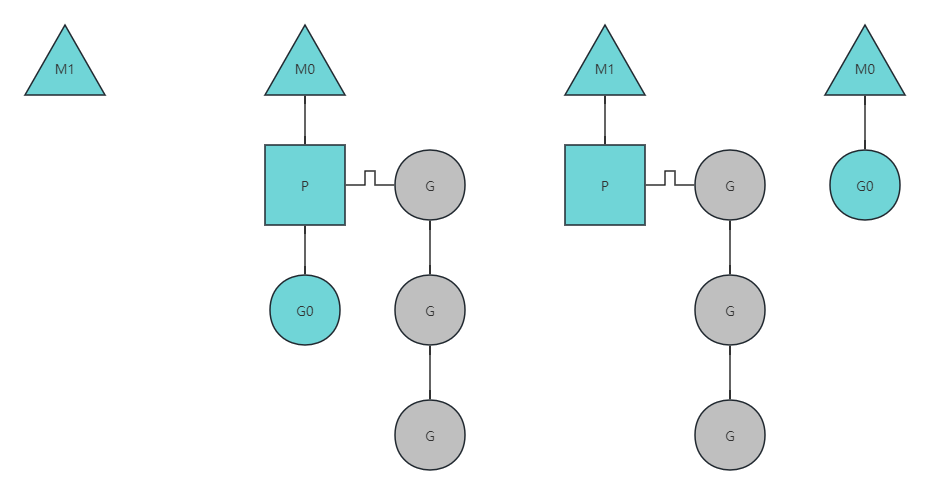
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行。
runqueue执行完成
当其中一个Processor的runqueue为空,没有goroutine可以调度。它会从另外一个上下文偷取一半的goroutine。
我的理解
场景为游乐园售票窗口(或者火车站售票窗口);
M为员工,P为处理售票的电脑,G为购买人员;
当由于紧急状况导致售票窗口堵塞时。加开一个售票窗口,把剩下的人员移到新窗口;
当原本的售票窗口完成了之后,把其他的人员平分回所有售票窗口。
runtime包
-
NumCPU:返回当前系统的 CPU 核数量
-
GOMAXPROCS:设置最大的可同时使用的 CPU 核数
通过runtime.GOMAXPROCS函数,应用程序何以在运行期间设置运行时系统中得P最大数量。但这会引起“Stop the World”。所以,应在应用程序最早的调用。并且最好是在运行Go程序之前设置好操作程序的环境变量GOMAXPROCS,而不是在程序中调用runtime.GOMAXPROCS函数。
无论我们传递给函数的整数值是什么值,运行时系统的P最大值总会在1~256之间。 -
Gosched:让当前线程让出 cpu 以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行
这个函数的作用是让当前 goroutine 让出 CPU,当一个 goroutine 发生阻塞,Go 会自动地把与该 goroutine 处于同一系统线程的其他 goroutine 转移到另一个系统线程上去,以使这些 goroutine 不阻塞。 -
Goexit:退出当前 goroutine(但是defer语句会照常执行)
-
NumGoroutine:返回正在执行和排队的任务总数
runtime.NumGoroutine函数在被调用后,会返回系统中的处于特定状态的Goroutine的数量。这里的特指是指Grunnable\Gruning\Gsyscall\Gwaition。处于这些状态的Groutine即被看做是活跃的或者说正在被调度。
注意:垃圾回收所在Groutine的状态也处于这个范围内的话,也会被纳入该计数器。 -
GOOS:目标操作系统
-
runtime.GC:会让运行时系统进行一次强制性的垃圾收集
1.强制的垃圾回收:不管怎样,都要进行的垃圾回收。
2.非强制的垃圾回收:只会在一定条件下进行的垃圾回收(即运行时,系统自上次垃圾回收之后新申请的堆内存的单元(也成为单元增量)达到指定的数值)。 -
GOROOT :获取goroot目录
-
GOOS : 查看目标操作系统 很多时候,我们会根据平台的不同实现不同的操作,就而已用GOOS了:
实践
1.获取goroot和os:
//获取goroot目录:
fmt.Println("GOROOT-->",runtime.GOROOT())
//获取操作系统
fmt.Println("os/platform-->",runtime.GOOS) // GOOS--> darwin,mac系统
2.获取CPU数量,和设置CPU数量:
func init(){
//1.获取逻辑cpu的数量
fmt.Println("逻辑CPU的核数:",runtime.NumCPU())
//2.设置go程序执行的最大的:[1,256]
n := runtime.GOMAXPROCS(runtime.NumCPU())
fmt.Println(n)
}
3.Gosched():
func main() {
go func() {
for i := 0; i < 5; i++ {
fmt.Println("goroutine。。。")
}
}()
for i := 0; i < 4; i++ {
//让出时间片,先让别的协议执行,它执行完,再回来执行此协程
runtime.Gosched()
fmt.Println("main。。")
}
}
4.Goexit的使用(终止协程)
func main() {
//创建新建的协程
go func() {
fmt.Println("goroutine开始。。。")
//调用了别的函数
fun()
fmt.Println("goroutine结束。。")
}() //别忘了()
//睡一会儿,不让主协程结束
time.Sleep(3*time.Second)
}
func fun() {
defer fmt.Println("defer。。。")
//return //终止此函数
runtime.Goexit() //终止所在的协程
fmt.Println("fun函数。。。")
}
互斥锁(Mutex)
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。一般用于处理并发中的临界资源问题。
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。
Mutex 是最简单的一种锁类型,互斥锁,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex。
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁。
在使用互斥锁时,一定要注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。
Lock()方法:
Lock()这个方法,锁定m。如果该锁已在使用中,则调用goroutine将阻塞,直到互斥体可用。
Unlock()方法
Unlock()方法,解锁解锁m。如果m未在要解锁的条目上锁定,则为运行时错误。
锁定的互斥体不与特定的goroutine关联。允许一个goroutine锁定互斥体,然后安排另一个goroutine解锁互斥体。
实践
package main
import (
"fmt"
"time"
"math/rand"
"sync"
)
//全局变量,表示票
var ticket = 10 //100张票
var mutex sync.Mutex //创建锁头
var wg sync.WaitGroup //同步等待组对象
func main() {
/*
4个goroutine,模拟4个售票口,
在使用互斥锁的时候,对资源操作完,一定要解锁。否则会出现程序异常,死锁等问题。
defer语句
*/
wg.Add(4)
go saleTickets("售票口1")
go saleTickets("售票口2")
go saleTickets("售票口3")
go saleTickets("售票口4")
wg.Wait() //main要等待
fmt.Println("程序结束了。。。")
//time.Sleep(5*time.Second)
}
func saleTickets(name string){
rand.Seed(time.Now().UnixNano())
defer wg.Done()
for{
//上锁
mutex.Lock() //g2
if ticket > 0{ //ticket 1 g1
time.Sleep(time.Duration(rand.Intn(1000))*time.Millisecond)
fmt.Println(name,"售出:",ticket) // 1
ticket-- // 0
}else{
mutex.Unlock() //条件不满足,也要解锁
fmt.Println(name,"售罄,没有票了。。")
break
}
mutex.Unlock() //解锁
}
}
售票口4 售出: 10
售票口4 售出: 9
售票口2 售出: 8
售票口1 售出: 7
售票口3 售出: 6
售票口4 售出: 5
售票口2 售出: 4
售票口1 售出: 3
售票口3 售出: 2
售票口4 售出: 1
售票口2 售罄,没有票了。。
售票口1 售罄,没有票了。。
售票口3 售罄,没有票了。。
售票口4 售罄,没有票了。。
程序结束了。。。
RWMutex(读写锁)
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。其中RWMutex是基于Mutex实现的,只读锁的实现使用类似引用计数器的功能。
RWMutex是读/写互斥锁。锁可以由任意数量的读取器或单个编写器持有。RWMutex的零值是未锁定的mutex。
如果一个goroutine持有一个rRWMutex进行读取,而另一个goroutine可能调用lock,那么在释放初始读取锁之前,任何goroutine都不应该期望能够获取读取锁。特别是,这禁止递归读取锁定。这是为了确保锁最终可用;被阻止的锁调用会将新的读卡器排除在获取锁之外。
我们怎么理解读写锁呢?当有一个 goroutine 获得写锁定,其它无论是读锁定还是写锁定都将阻塞直到写解锁;当有一个 goroutine 获得读锁定,其它读锁定仍然可以继续;当有一个或任意多个读锁定,写锁定将等待所有读锁定解锁之后才能够进行写锁定。所以说这里的读锁定(RLock)目的其实是告诉写锁定:有很多人正在读取数据,你给我站一边去,等它们读(读解锁)完你再来写(写锁定)。我们可以将其总结为如下三条:
同时只能有一个 goroutine 能够获得写锁定。
同时可以有任意多个 gorouinte 获得读锁定。
同时只能存在写锁定或读锁定(读和写互斥)。
所以,RWMutex这个读写锁,该锁可以加多个读锁或者一个写锁,其经常用于读次数远远多于写次数的场景。
读写锁的写锁只能锁定一次,解锁前不能多次锁定,读锁可以多次,但读解锁次数最多只能比读锁次数多一次,一般情况下我们不建议读解锁次数多余读锁次数。
基本遵循两大原则:
1、可以随便读,多个goroutine同时读。
2、写的时候,啥也不能干。不能读也不能写。
读写锁即是针对于读写操作的互斥锁。它与普通的互斥锁最大的不同就是,它可以分别针对读操作和写操作进行锁定和解锁操作。读写锁遵循的访问控制规则与互斥锁有所不同。在读写锁管辖的范围内,它允许任意个读操作的同时进行。但是在同一时刻,它只允许有一个写操作在进行。
并且在某一个写操作被进行的过程中,读操作的进行也是不被允许的。也就是说读写锁控制下的多个写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的。但是,多个读操作之间却不存在互斥关系。
我的理解
1.当一个协程的写锁定发动时,其余的读锁定和写锁定不能发动;
2.当一个或多个读锁定发动时,写锁定不能发动;
3.当一个读锁定发动时,其余的读锁定能发动。
RLock()方法
func (rw *RWMutex) RLock()
读锁,当有写锁时,无法加载读锁,当只有读锁或者没有锁时,可以加载读锁,读锁可以加载多个,所以适用于“读多写少”的场景。
RUnlock()方法
func (rw *RWMutex) RUnlock()
读锁解锁,RUnlock 撤销单次RLock调用,它对于其它同时存在的读取器则没有效果。若rw并没有为读取而锁定,调用RUnlock就会引发一个运行时错误。
Lock()方法:
func (rw *RWMutex) Lock()
写锁,如果在添加写锁之前已经有其他的读锁和写锁,则Lock就会阻塞直到该锁可用,为确保该锁最终可用,已阻塞的Lock调用会从获得的锁中排除新的读取锁,即写锁权限高于读锁,有写锁时优先进行写锁定。
Unlock()方法
func (rw *RWMutex) Unlock()
写锁解锁,如果没有进行写锁定,则就会引起一个运行时错误。
实践
package main
import (
"fmt"
"sync"
"time"
)
var rwMutex *sync.RWMutex
var wg *sync.WaitGroup
func main() {
rwMutex = new(sync.RWMutex)
wg = new (sync.WaitGroup)
//wg.Add(2)
//
////多个同时读取
//go readData(1)
//go readData(2)
wg.Add(3)
go writeData(1)
go readData(2)
go writeData(3)
wg.Wait()
fmt.Println("main..over...")
}
func writeData(i int){
defer wg.Done()
fmt.Println(i,"开始写:write start。。")
rwMutex.Lock()//写操作上锁
fmt.Println(i,"正在写:writing。。。。")
time.Sleep(3*time.Second)
rwMutex.Unlock()
fmt.Println(i,"写结束:write over。。")
}
func readData(i int) {
defer wg.Done()
fmt.Println(i, "开始读:read start。。")
rwMutex.RLock() //读操作上锁
fmt.Println(i,"正在读取数据:reading。。。")
time.Sleep(3*time.Second)
rwMutex.RUnlock() //读操作解锁
fmt.Println(i,"读结束:read over。。。")
}
3 开始写:write start
3 正在写:writing
2 开始读:read start
1 开始写:write start
3 写结束:write over
2 正在读:reading
2 读结束:read over
1 正在写:writing
1 写结束:write over
main..over...
总结
1.读锁不能阻塞读锁
2.读锁需要阻塞写锁,直到所有读锁都释放
3.写锁需要阻塞读锁,直到所有写锁都释放
4.写锁需要阻塞写锁
Sync包
基本同步原语:sync包提供了基本的同步原语,如互斥锁(sync.Mutex)、读写锁(RWMutex)、等待组(WaitGroup)、一次执行锁(Once)和条件变量(Cond)等。这些原语主要用于实现资源的访问控制和数据的同步操作,确保多个线程或goroutine之间不会发生冲突。
互斥锁(Mutex):互斥锁是一种简单的同步原语,用于控制一个线程对某个共享资源的访问权限。通过设置互斥锁,可以防止其他线程同时访问该资源,从而保证了资源的独占访问。使用sync.Mutex的方法包括Lock()和Unlock(),其中Lock()用于锁定资源,而Unlock()则用于释放锁。
读写锁(RWMutex):与互斥锁相反,读写锁允许两个线程同时对同一资源进行访问,但每个线程只能读取不允许写入。这种机制适用于需要在两个线程之间共享数据的情况。
等待组(WaitGroup):等待组是一种更复杂的同步机制,它允许多个线程等待一个事件的发生。当所有线程都等待到这个事件时,它们会被唤醒并继续执行。等待组的实现依赖于互斥锁,但它允许线程在没有获得锁的情况下等待事件。
一次执行锁(Once):Once是一种特殊的锁,它要求线程在执行一次操作后立即释放锁。这是一种轻量级的同步机制,适用于那些需要快速响应但又不希望频繁重新初始化锁的场景。
条件变量(Cond):条件变量是一种高级的同步机制,它允许线程在满足特定条件时触发执行。例如,sync.Cond可以用来实现等待条件的检查,或者在满足条件时执行特定的代码块。
等待组(WaitGroup)
type WaitGroup struct{
//
}
func (wg *WaitGroup) Add(delta int)
func (wg *WaitGroup) Done()
func (wg *WaitGroup) Wait()
实践
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup // 创建同步等待组对象
func main() {
/*
WaitGroup:同步等待组
可以使用Add(),设置等待组中要 执行的子goroutine的数量,
在main 函数中,使用wait(),让主程序处于等待状态。直到等待组中子程序执行完毕。解除阻塞
子gorotuine对应的函数中。wg.Done(),用于让等待组中的子程序的数量减1
*/
//设置等待组中,要执行的goroutine的数量
wg.Add(2)
go fun1()
go fun2()
fmt.Println("main进入阻塞状态。。。等待wg中的子goroutine结束。。")
wg.Wait() //表示main goroutine进入等待,意味着阻塞
fmt.Println("main,解除阻塞。。")
}
func fun1() {
for i:=1;i<=10;i++{
fmt.Println("fun1.。。i:",i)
}
wg.Done() //给wg等待中的执行的goroutine数量减1.同Add(-1)
}
func fun2() {
defer wg.Done()
for j:=1;j<=10;j++{
fmt.Println("\tfun2..j,",j)
}
}
fun1.。。i: 1
fun1.。。i: 2
fun1.。。i: 3
fun1.。。i: 4
fun1.。。i: 5
fun1.。。i: 6
fun1.。。i: 7
fun1.。。i: 8
fun1.。。i: 9
fun1.。。i: 10
main进入阻塞状态。。。等待wg中的子goroutine结束。。
fun2..j, 1
fun2..j, 2
fun2..j, 3
fun2..j, 4
fun2..j, 5
fun2..j, 6
fun2..j, 7
fun2..j, 8
fun2..j, 9
fun2..j, 10
main,解除阻塞。。
通道(Channels)
通道可以被认为是Goroutines通信的管道。类似于管道中的水从一端到另一端的流动,数据可以从一端发送到另一端,通过通道接收。
在前面讲Go语言的并发时候,我们就说过,当多个Goroutine想实现共享数据的时候,虽然也提供了传统的同步机制,但是Go语言强烈建议的是使用Channel通道来实现Goroutines之间的通信。
Go语言中,要传递某个数据给另一个goroutine(协程),可以把这个数据封装成一个对象,然后把这个对象的指针传入某个channel中,另外一个goroutine从这个channel中读出这个指针,并处理其指向的内存对象。Go从语言层面保证同一个时间只有一个goroutine能够访问channel里面的数据,为开发者提供了一种优雅简单的工具,所以Go的做法就是使用channel来通信,通过通信来传递内存数据,使得内存数据在不同的goroutine中传递,而不是使用共享内存来通信。
通道的概念
通道是什么,通道就是goroutine之间的通道。它可以让goroutine之间相互通信。
每个通道都有与其相关的类型。该类型是通道允许传输的数据类型。(通道的零值为nil。nil通道没有任何用处,因此通道必须使用类似于map和切片的方法来定义。)
通道的声明
声明一个通道和定义一个变量的语法一样:
//声明通道
var 通道名 chan 数据类型
//创建通道:如果通道为nil(就是不存在),就需要先创建通道
通道名 = make(chan 数据类型)
package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel 是 nil 的, 不能使用,需要先创建通道。。")
a = make(chan int)
fmt.Printf("数据类型是: %T", a)
}
}
channel 是 nil 的, 不能使用,需要先创建通道。。
数据类型是: chan int
也可以简短的声明:
a := make(chan int)
channel的数据类型
channel是引用类型的数据,在作为参数传递的时候,传递的是内存地址。
package main
import (
"fmt"
)
func main() {
ch1 := make(chan int)
fmt.Printf("%T,%p\n",ch1,ch1)
test1(ch1)
}
func test1(ch chan int){
fmt.Printf("%T,%p\n",ch,ch)
}
通道的使用语法
通道的注意点
Channel通道在使用的时候,有以下几个注意点:
1.用于goroutine传递消息的。
2.通道,每个都有相关联的数据类型, nil chan,不能使用,类似于nil map,不能直接存储键值对
3.使用通道传递数据:<- chan <- data,发送数据到通道。向通道中写数据 data <- chan,从通道中获取数据。从通道中读数据
4.阻塞: 发送数据:chan <- data,阻塞的,直到另一条goroutine,读取数据来解除阻塞 读取数据:data <- chan,也是阻塞的。直到另一条goroutine,写出数据解除阻塞。
5.本身channel就是同步的,意味着同一时间,只能有一条goroutine来操作。
最后:通道是goroutine之间的连接,所以通道的发送和接收必须处在不同的goroutine中。
发送和接收
发送和接收的语法:
data := <- a // read from channel a
a <- data // write to channel a
在通道上箭头的方向指定数据是发送还是接收。
另外:
v, ok := <- a //从一个channel中读取
发送和接收默认是阻塞的
一个通道发送和接收数据,默认是阻塞的。当一个数据被发送到通道时,在发送语句中被阻塞,直到另一个Goroutine从该通道读取数据。相对地,当从通道读取数据时,读取被阻塞,直到一个Goroutine将数据写入该通道。
这些通道的特性是帮助Goroutines有效地进行通信,而无需像使用其他编程语言中非常常见的显式锁或条件变量。
package main
import "fmt"
func main() {
var ch1 chan bool //声明,没有创建
fmt.Println(ch1) //<nil>
fmt.Printf("%T\n", ch1) //chan bool
ch1 = make(chan bool) //0xc0000a4000,是引用类型的数据
fmt.Println(ch1)
go func() {
for i := 0; i < 10; i++ {
fmt.Println("子goroutine中,i:", i)
}
// 循环结束后,向通道中写数据,表示要结束了。。
ch1 <- true
fmt.Println("结束。。")
}()
data := <-ch1 // 从ch1通道中读取数据
fmt.Println("data-->", data)
fmt.Println("main。。over。。。。")
}
<nil>
chan bool
0xc0000a4000
子goroutine中,i: 0
子goroutine中,i: 1
子goroutine中,i: 2
子goroutine中,i: 3
子goroutine中,i: 4
子goroutine中,i: 5
子goroutine中,i: 6
子goroutine中,i: 7
子goroutine中,i: 8
子goroutine中,i: 9
结束。。
data--> true
main。。over。。。。
在上面的程序中,我们先创建了一个chan bool通道。然后启动了一条子Goroutine,并循环打印10个数字。然后我们向通道ch1中写入输入true。然后在主goroutine中,我们从ch1中读取数据。这一行代码是阻塞的,这意味着在子Goroutine将数据写入到该通道之前,主goroutine将不会执行到下一行代码。因此,我们可以通过channel实现子goroutine和主goroutine之间的通信。当子goroutine执行完毕前,主goroutine会因为读取ch1中的数据而阻塞。从而保证了子goroutine会先执行完毕。这就消除了对时间的需求。在之前的程序中,我们要么让主goroutine进入睡眠,以防止主要的Goroutine退出。要么通过WaitGroup来保证子goroutine先执行完毕,主goroutine才结束。
以下代码加入了睡眠,可以更好的理解channel的阻塞
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
done := make(chan bool) // 通道
go func() {
fmt.Println("子goroutine执行。。。")
time.Sleep(3 * time.Second)
data := <-ch1 // 从通道中读取数据
fmt.Println("data:", data)
done <- true
}()
// 向通道中写数据。。
time.Sleep(5 * time.Second)
ch1 <- 100
<-done
fmt.Println("main。。over")
}
子goroutine执行。。。
data: 100
main。。over
再一个例子,这个程序将打印一个数字的个位数的平方和。
package main
import (
"fmt"
)
func calcSquares(number int, squareop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit
number /= 10
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit * digit
number /= 10
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares + cubes)
}
运行结果:
Final output 1536
死锁
使用通道时要考虑的一个重要因素是死锁。如果Goroutine在一个通道上发送数据,那么预计其他的Goroutine应该接收数据。如果这种情况不发生,那么程序将在运行时出现死锁。
类似地,如果Goroutine正在等待从通道接收数据,那么另一些Goroutine将会在该通道上写入数据,否则程序将会死锁。
package main
func main() {
ch := make(chan int)
ch <- 5
}
报错:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/Users/test/go/src/l_goroutine/demo08_chan.go:5 +0x50
关闭通道
close(ch)
接收者可以在接收来自通道的数据时使用额外的变量来检查通道是否已经关闭。
语法结构:
v, ok := <- ch
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
go sendData(ch1)
/*
子goroutine,写出数据10个
每写一个,阻塞一次,主程序读取一次,解除阻塞
主goroutine:循环读
每次读取一个,堵塞一次,子程序,写出一个,解除阻塞
发送发,关闭通道的--->接收方,接收到的数据是该类型的零值,以及false
*/
//主程序中获取通道的数据
for{
time.Sleep(1*time.Second)
v, ok := <- ch1 //其他goroutine,显示的调用close方法关闭通道。
if !ok{
fmt.Println("已经读取了所有的数据,", ok)
break
}
fmt.Println("取出数据:",v, ok)
}
fmt.Println("main...over....")
}
func sendData(ch1 chan int) {
// 发送方:10条数据
for i:=0;i<10 ;i++ {
ch1 <- i//将i写入通道中
}
close(ch1) //将ch1通道关闭了。
}
取出数据: 0 true
取出数据: 1 true
取出数据: 2 true
取出数据: 3 true
取出数据: 4 true
取出数据: 5 true
取出数据: 6 true
取出数据: 7 true
取出数据: 8 true
取出数据: 9 true
已经读取了所有的数据, false
main...over....
通道上的范围循环
我们可以循环从通道上获取数据,直到通道关闭。for循环的for range形式可用于从通道接收值,直到它关闭为止。
使用range循环,示例代码:
package main
import (
"time"
"fmt"
)
func main() {
ch1 :=make(chan int)
go sendData(ch1)
// for循环的for range形式可用于从通道接收值,直到它关闭为止。
for v := range ch1{
fmt.Println("读取数据:",v)
}
fmt.Println("main..over.....")
}
func sendData(ch1 chan int) {
for i:=0;i<10 ; i++ {
time.Sleep(1*time.Second)
ch1 <- i
}
close(ch1)//通知对方,通道关闭
}
读取数据: 0
读取数据: 1
读取数据: 2
读取数据: 3
读取数据: 4
读取数据: 5
读取数据: 6
读取数据: 7
读取数据: 8
读取数据: 9
main..over.....
非缓冲通道
之前学习的所有通道基本上都没有缓冲。发送和接收到一个未缓冲的通道是阻塞的。
一次发送操作对应一次接收操作,对于一个goroutine来讲,它的一次发送,在另一个goroutine接收之前都是阻塞的。同样的,对于接收来讲,在另一个goroutine发送之前,它也是阻塞的。
缓冲通道
缓冲通道就是指一个通道,带有一个缓冲区。发送到一个缓冲通道只有在缓冲区满时才被阻塞。类似地,从缓冲通道接收的信息只有在缓冲区为空时才会被阻塞。
可以通过将额外的容量参数传递给make函数来创建缓冲通道,该函数指定缓冲区的大小。
语法:
ch := make(chan type, capacity)
package main
import (
"fmt"
"strconv"
"time"
)
func main() {
/*
非缓存通道:make(chan T)
缓存通道:make(chan T ,size)
缓存通道,理解为是队列:
非缓存,发送还是接受,都是阻塞的
缓存通道,缓存区的数据满了,才会阻塞状态。。
*/
ch1 := make(chan int) //非缓存的通道
fmt.Println(len(ch1), cap(ch1)) //0 0
//ch1 <- 100//阻塞的,需要其他的goroutine解除阻塞,否则deadlock
ch2 := make(chan int, 5) //缓存的通道,缓存区大小是5
fmt.Println(len(ch2), cap(ch2)) //0 5
ch2 <- 100 //
fmt.Println(len(ch2), cap(ch2)) //1 5
//ch2 <- 200
//ch2 <- 300
//ch2 <- 400
//ch2 <- 500
//ch2 <- 600
fmt.Println("--------------")
ch3 := make(chan string, 4)
go sendData3(ch3)
for {
time.Sleep(1*time.Second)
v, ok := <-ch3
if !ok {
fmt.Println("读完了,,", ok)
break
}
fmt.Println("\t读取的数据是:", v)
}
fmt.Println("main...over...")
}
func sendData3(ch3 chan string) {
for i := 0; i < 10; i++ {
ch3 <- "数据" + strconv.Itoa(i)
fmt.Println("子goroutine,写出第", i, "个数据")
}
close(ch3)
}
0 0
0 5
1 5
--------------
子goroutine,写出第 0 个数据
子goroutine,写出第 1 个数据
子goroutine,写出第 2 个数据
子goroutine,写出第 3 个数据
读取的数据是: 数据0
子goroutine,写出第 4 个数据
子goroutine,写出第 5 个数据
读取的数据是: 数据1
读取的数据是: 数据2
子goroutine,写出第 6 个数据
读取的数据是: 数据3
子goroutine,写出第 7 个数据
读取的数据是: 数据4
子goroutine,写出第 8 个数据
读取的数据是: 数据5
子goroutine,写出第 9 个数据
读取的数据是: 数据6
读取的数据是: 数据7
读取的数据是: 数据8
读取的数据是: 数据9
读完了,, false
main...over...
双向通道
通道,channel,是用于实现goroutine之间的通信的。一个goroutine可以向通道中发送数据,另一条goroutine可以从该通道中获取数据。截止到现在我们所学习的通道,都是既可以发送数据,也可以读取数据,我们又把这种通道叫做双向通道。
data := <- a // read from channel a
a <- data // write to channel a
单向通道
单向通道,也就是定向通道。
之前我们学习的通道都是双向通道,我们可以通过这些通道接收或者发送数据。我们也可以创建单向通道,这些通道只能发送或者接收数据。
双向通道,实例代码:
package main
import "fmt"
func main() {
/*
双向:
chan T -->
chan <- data,写出数据,写
data <- chan,获取数据,读
单向:定向
chan <- T,
只支持写,
<- chan T,
只读
*/
ch1 := make(chan string) // 双向,可读,可写
done := make(chan bool)
go sendData(ch1, done)
data := <- ch1 //阻塞
fmt.Println("子goroutine传来:", data)
ch1 <- "我是main。。" // 阻塞
<- done
fmt.Println("main...over....")
}
//子goroutine-->写数据到ch1通道中
//main goroutine-->从ch1通道中取
func sendData(ch1 chan string, done chan bool) {
ch1 <- "我是小明"// 阻塞
data := <-ch1 // 阻塞
fmt.Println("main goroutine传来:",data)
done <- true
}
子goroutine传来: 我是小明
main goroutine传来: 我是main。。
main...over....
创建仅能发送数据的通道,示例代码:
package main
import "fmt"
func main() {
/*
单向:定向
chan <- T,
只支持写,
<- chan T,
只读
用于参数传递:
*/
ch1 := make(chan int)//双向,读,写
//ch2 := make(chan <- int) // 单向,只写,不能读
//ch3 := make(<- chan int) //单向,只读,不能写
//ch1 <- 100
//data :=<-ch1
//ch2 <- 1000
//data := <- ch2
//fmt.Println(data)
// <-ch2 //invalid operation: <-ch2 (receive from send-only type chan<- int)
//ch3 <- 100
// <-ch3
// ch3 <- 100 //invalid operation: ch3 <- 100 (send to receive-only type <-chan int)
//go fun1(ch2)
go fun1(ch1)
data:= <- ch1
fmt.Println("fun1中写出的数据是:",data)
//fun2(ch3)
go fun2(ch1)
ch1 <- 200
fmt.Println("main。。over。。")
}
//该函数接收,只写的通道
func fun1(ch chan <- int){
// 函数内部,对于ch只能写数据,不能读数据
ch <- 100
fmt.Println("fun1函数结束。。")
}
func fun2(ch <-chan int){
//函数内部,对于ch只能读数据,不能写数据
data := <- ch
fmt.Println("fun2函数,从ch中读取的数据是:",data)
}
fun1函数结束。。
fun1中写出的数据是: 100
fun2函数,从ch中读取的数据是: 200
main。。over。。
time包中的通道相关函数
主要就是定时器,标准库中的Timer让用户可以定义自己的超时逻辑,尤其是在应对select处理多个channel的超时、单channel读写的超时等情形时尤为方便。
Timer是一次性的时间触发事件,这点与Ticker不同,Ticker是按一定时间间隔持续触发时间事件。
Timer常见的创建方式:
t:= time.NewTimer(d)
t:= time.AfterFunc(d, f)
c:= time.After(d)
虽然说创建方式不同,但是原理是相同的。
Timer有3个要素:
定时时间:就是那个d
触发动作:就是那个f
时间channel: 也就是t.C
time.NewTimer()
NewTimer()创建一个新的计时器,该计时器将在其通道上至少持续d之后发送当前时间。
func NewTimer(d Duration) *Timer
// NewTimer creates a new Timer that will send
// the current time on its channel after at least duration d.
func NewTimer(d Duration) *Timer {
c := make(chan Time, 1)
t := &Timer{
C: c,
r: runtimeTimer{
when: when(d),
f: sendTime,
arg: c,
},
}
startTimer(&t.r)
return t
}
通过源代码我们可以看出,首先创建一个channel,关联的类型为Time,然后创建了一个Timer并返回。
用于在指定的Duration类型时间后调用函数或计算表达式。
如果只是想指定时间之后执行,使用time.Sleep()
使用NewTimer(),可以返回的Timer类型在计时器到期之前,取消该计时器
直到使用<-timer.C发送一个值,该计时器才会过期
package main
import (
"time"
"fmt"
)
func main() {
/*
1.func NewTimer(d Duration) *Timer
创建一个计时器:d时间以后触发,go触发计时器的方法比较特别,就是在计时器的channel中发送值
*/
//新建一个计时器:timer
timer := time.NewTimer(3 * time.Second)
fmt.Printf("%T\n", timer) //*time.Timer
fmt.Println(time.Now()) //2019-08-15 10:41:21.800768 +0800 CST m=+0.000461190
//此处在等待channel中的信号,执行此段代码时会阻塞3秒
ch2 := timer.C //<-chan time.Time
fmt.Println(<-ch2) //2019-08-15 10:41:24.803471 +0800 CST m=+3.003225965
}
*time.Timer
2019-08-15 10:41:21.800768 +0800 CST m=+0.000461190
2019-08-15 10:41:24.803471 +0800 CST m=+3.003225965
timer.Stop
package main
import (
"time"
"fmt"
)
func main() {
/*
1.func NewTimer(d Duration) *Timer
创建一个计时器:d时间以后触发,go触发计时器的方法比较特别,就是在计时器的channel中发送值
*/
//新建一个计时器:timer
//timer := time.NewTimer(3 * time.Second)
//fmt.Printf("%T\n", timer) //*time.Timer
//fmt.Println(time.Now()) //2019-08-15 10:41:21.800768 +0800 CST m=+0.000461190
//
////此处在等待channel中的信号,执行此段代码时会阻塞3秒
//ch2 := timer.C //<-chan time.Time
//fmt.Println(<-ch2) //2019-08-15 10:41:24.803471 +0800 CST m=+3.003225965
fmt.Println("-------------------------------")
//新建计时器,一秒后触发
timer2 := time.NewTimer(5 * time.Second)
//新开启一个线程来处理触发后的事件
go func() {
//等触发时的信号
<-timer2.C
fmt.Println("Timer 2 结束。。")
}()
//由于上面的等待信号是在新线程中,所以代码会继续往下执行,停掉计时器
time.Sleep(3*time.Second)
stop := timer2.Stop()
if stop {
fmt.Println("Timer 2 停止。。")
}
}
-------------------------------
Timer 2 停止。。
time.After()
在等待持续时间之后,然后在返回的通道上发送当前时间。它相当于NewTimer(d).C。在计时器触发之前,垃圾收集器不会恢复底层计时器。如果效率有问题,使用NewTimer代替,并调用Timer。如果不再需要计时器,请停止。
package main
import (
"time"
"fmt"
)
func main() {
/*
func After(d Duration) <-chan Time
返回一个通道:chan,存储的是d时间间隔后的当前时间。
*/
ch1 := time.After(3 * time.Second) //3s后
fmt.Printf("%T\n", ch1) // <-chan time.Time
fmt.Println(time.Now()) //2019-08-15 09:56:41.529883 +0800 CST m=+0.000465158
time2 := <-ch1
fmt.Println(time2) //2019-08-15 09:56:44.532047 +0800 CST m=+3.002662179
}
<-chan time.Time
2019-08-15 09:56:41.529883 +0800 CST m=+0.000465158
2019-08-15 09:56:44.532047 +0800 CST m=+3.002662179
缓冲区(Buffer)
Go 语言 bytes.Buffer 源码详解之1 | 稀土掘金 | CodePlayer竟然被占用了
首先我们声明了一个 buffer 变量,然后调用 WriteString() 方法往缓冲区内写入了一个字符串,返回值为31,nil,表示写入的字节长度和产生的 error
然后我们想打印出缓冲区的长度和容量,调用了 Len() 和 Cap() 方法,返回了 31 和 64,这和我们的认知应该相符,毕竟我们写入了字节长度为 31 的字符串,同时可能有扩容策略,容量为 64
接下来我们调用 Read() 方法读取数据,将数据读入了字节切片中,同时打印出了读取的数据及长度,和写入的均相符
最后我们再次调用 Len() 和 Cap() 方法,发现返回的长度和容量分别为 0 和 64。
var buffer bytes.Buffer
n, err := buffer.WriteString("this is a test for bytes buffer")
fmt.Println(n, err) // 31 nil
fmt.Println(buffer.Len(), buffer.Cap()) // 31 64
s := make([]byte, 1000)
n, err = buffer.Read(s)
fmt.Println(n, err) // 31 nil
fmt.Println(string(s)) // this is a test for bytes buffer
fmt.Println(buffer.Len(), buffer.Cap()) // 0 64
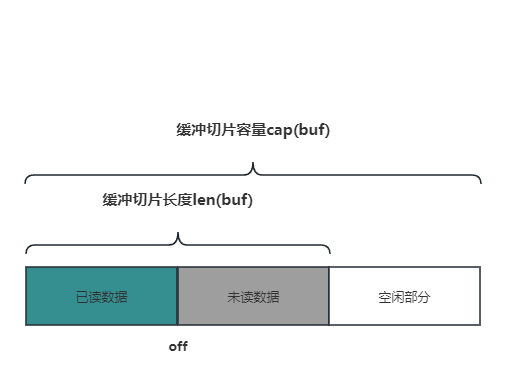
Buffer 是集读写功能于一身,缓冲区大小可变的字节缓冲区,结构中有如下三个变量:
- buf: 底层的缓冲字节切片,用于保存数据。len(buf)表示字节切片长度,cap(buf)表示切片容量
- off: 已读计数,在该位置之前的数据都是被读取过的,off表示下次读取时的开始位置。因此未读数据部分为buf[off:len(buf)]
- lastRead: 保存上次的读操作类型,用于后续的回退操作
type Buffer struct {
buf []byte
off int
lastRead readOp
}
下面是bytes.Buffer 中定义的一些常量:
// 初始化底层缓冲字节数组容量时,分配的最小值
const smallBufferSize = 64
// readOp 常量表示上次的操作类型,用于后续使用 UnreadRune 和 UnreadByte 回退时检查操作是否合法
// 有四种 opReadRuneX,表示上次读 rune 时对应的字节大小
type readOp int8
const (
opRead readOp = -1 // 任意读操作
opInvalid readOp = 0 // 非读操作
opReadRune1 readOp = 1 // 长度为 1 的 rune
opReadRune2 readOp = 2 // 长度为 2 的 rune
opReadRune3 readOp = 3 // 长度为 3 的 rune
opReadRune4 readOp = 4 // 长度为 4 的 rune
)
// 在扩容时会用到,如果缓冲字节切片太大,内存不够分配时会panic,并给出该提示
var ErrTooLarge = errors.New("bytes.Buffer: too large")
// 读到的数据量为负值时提示该错误
var errNegativeRead = errors.New("bytes.Buffer: reader returned negative count from Read")
// 缓冲字节切片的最大容量
const maxInt = int(^uint(0) >> 1)
方法定义
Bytes()
- Bytes() 方法返回未读的字节数据,即从已读计数 off 开始,到 len(off) 结束,也就是上图中的绿色部分。
- 由于返回的是字节切片,存在内容泄露的风险,因为通过切片,我们可以直接访问和操纵它的底层数组。不论这个切片是基于某个数组得来的,还是通过对另一个切片做切片操作获得的。
- 同时,由于返回的是从 off 位置开始的切片,因此得到的数据是有有效期的。如果调用Read()、Write()、 Reset()、 Truncate() 等类似会修改 off 变量值的方法,Bytes()方法得到的数据就失效了。
func (b *Buffer) Bytes() []byte { return b.buf[b.off:] }
String()
String() 方法返回未读数据的字符串的形式,不会存在内容泄露的风险。
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
empty()
empty() 方法返回是否还有未读数据,即上图中的绿色部分。如果已读计数 off >= len(b.buf) ,说明没有未读数据了,返回 true
func (b *Buffer) empty() bool { return len(b.buf) <= b.off }
Len()
Len() 方法返回未读数据部分的长度,即上图绿色部分的长度。 Bytes() 方法返回的是未读部分的数据,即 b.Len() == len(b.Bytes())
func (b *Buffer) Len() int { return len(b.buf) - b.off }
Cap()
Cap() 方法返回底层缓冲字节切片 buf 的容量,由于底层的缓冲切片会扩容,因此该值是可变的。
func (b *Buffer) Cap() int { return cap(b.buf) }
Reset()
Reset() 重置整个结构,把缓冲字节切片长度修改为0,已读计数设置为0,相当于上图中的灰色已读数据部分与绿色未读数据部分长度均被设置为0。
虽然缓冲区 buf 底层数组中的数据没有清空,但对于结构来说,通过 off 字段的控制,这些数据都是不可见的,读取不到数据,后续再写入数据会直接覆盖这些脏数据。
func (b *Buffer) Reset() {
b.buf = b.buf[:0]
b.off = 0
b.lastRead = opInvalid
}
Truncate()
Truncate 会 保留未读部分前n个字节 的数据,丢弃其余部分,即只保留上图绿色部分的 前n个 字节。
该方法只是修改缓冲切片的长度 len(buf),因为有效数据部分是 buf[off:len(buf)]
func (b *Buffer) Truncate(n int) {
// 对我们有用的数据只有未读数据,如果 n==0,说明不需要保留未读数据了
// 不保留相当于缓冲字节切片的数据都没用了,直接重置
if n == 0 {
b.Reset()
return
}
// 设置上次操作类型
b.lastRead = opInvalid
// 如果要保留的长度小于0,或者 保留的长度大于未读数据的长度,不合法,直接panic
if n < 0 || n > b.Len() {
panic("bytes.Buffer: truncation out of range")
}
// 保留n个未读字节,也就是直接修改切片长度 len
b.buf = b.buf[:b.off+n]
}
tryGrowByReslice()
在向缓冲切片中写 n 个字节之前,我们要确保至少有n个空白位置可以存放数据。
从下图可以看出,在 len(buf) 到 cap(buf) 之间本身就有空闲部分,如果 cap(buf) - len(buf) >= n,说明空闲部分可以写入n个字节,那么我们就可以将len(buf) 后移n位,将新增数据保存在这n个位置中。
否则的话,就需要进行数据平移甚至扩容了,这些工作是下一个要介绍的 grow() 方法要做的事情,因此我们可以说 tryGrowByReslice() 是 grow() 的快速情况(fase-case),在成本最低的情况下满足需求。
调用 grow() 方法前都会先尝试调用下 tryGrowByReslice(),不成功的话才会调用 grow()。
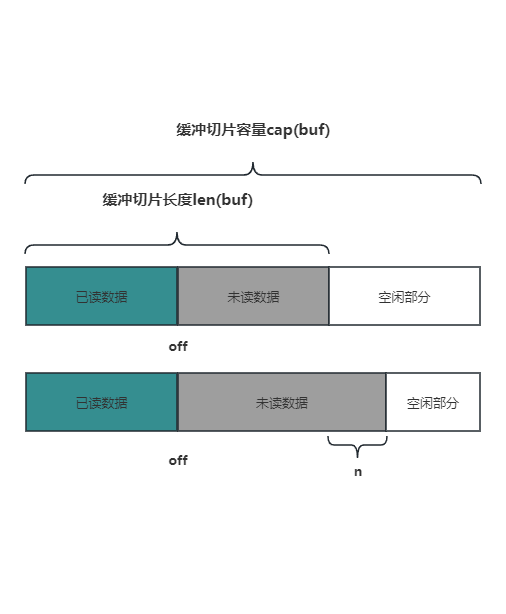
本次操作成功,字节切片 buf 的长度被增大了,但是新增的 n 个字节还没有数据,只是空出来了,用于调用者直接填充数据。
入参 n:表示要增长的字节长度
返回值:增长后写入数据的起始位置(调整前的 len(buf));本次快速增长是否成功
func (b *Buffer) tryGrowByReslice(n int) (int, bool) {
// 判断容量与长度的差额,是否大于要增长的长度n,如果大于则满足增长需求
if l := len(b.buf); n <= cap(b.buf)-l {
// 修改buf 的长度
b.buf = b.buf[:l+n]
// 写入的起始位置为l,本次操作成功
return l, true
}
// 快速增长失败
return 0, false
}
grow()
grow() 通过对缓冲字节切片进行调整,甚至进行扩容,来确保有 n 个空闲位置供调用者写入,方法返回写入的开始位置。如果在扩容中,缓冲切片长度超过最大长度,会产生 ErrTooLarge 的panic。
1.先进行数据整理,如果 buf 中没有未读数据,且已读计数大于0,重置,此时的整个缓冲切片都是空闲的,如下图:
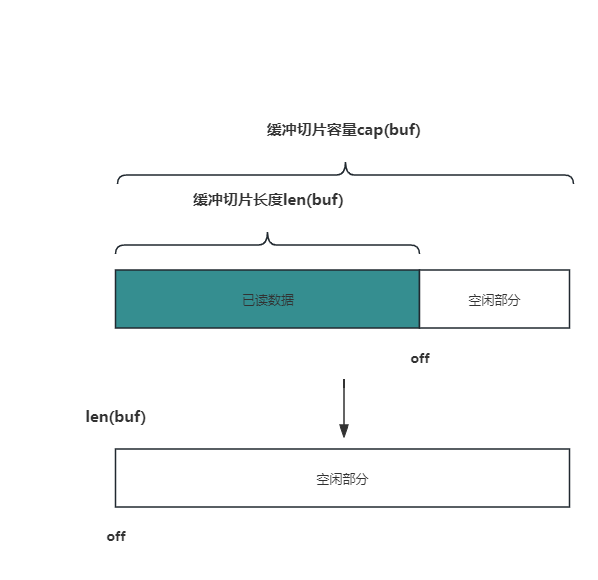
2.调用 tryGrowByReslice,判断通过 fast-case 是否满足需求,如果满足直接返回了,不满足再进行下一步。
3.当前的 buf 可能还没有初始化(声明变量后,直接调用Grow()方法,手动扩容),如果 buf == nil,判断最小缓冲大小是否满足需求,满足需求的话,创建一个字节切片返回即可。
4.数据平移。考虑下面这种情况,如果 未读数据的长度 + 所需字节数 n <= 缓冲切片容量 cap(buf),可以将未读数据平移到 buf 的顶端,覆盖已读数据,这样就可以至少留出来 n 个字节了。
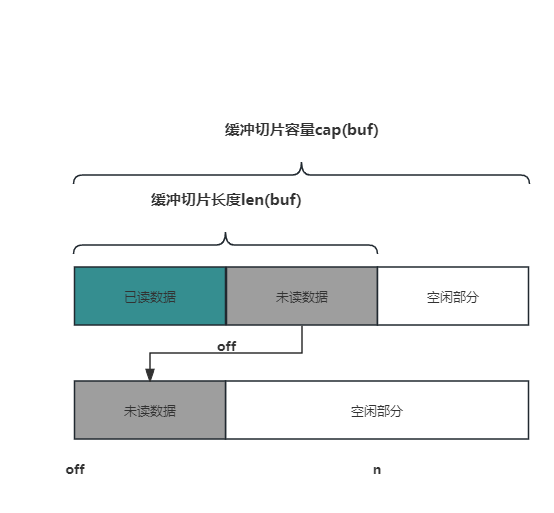
可是在实际的源码实现中,条件更加严苛点,要求 未读数据的长度 + 所需字节数 n <= cap(buf)/2,即两者加起来要小于一半的容量,这样做的原因是为了防止频繁的数据复制。
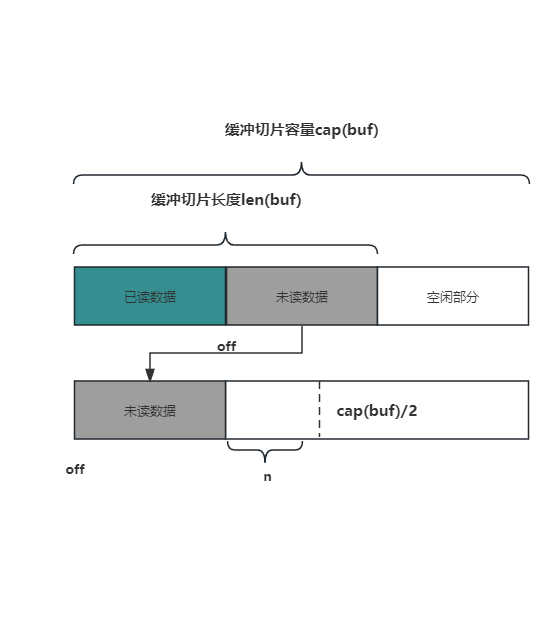
5.扩容。上面的条件都不满足,只能扩容, 新容器的容量 = 2 * 原有容量 + 所需字节数。然后将原缓冲切片中的未读数据,拷贝到新的缓冲切片头部。
6.方法最后设置已读计数为 0,设置缓冲切片的长度为 未读数据长度 + 所需字节数 n
func (b *Buffer) grow(n int) int {
// m: 当前未读字节的数量
m := b.Len()
// 未读数据为0,且off!=0,说明off位置之前的数据已经没用了,白白占用空间,可以首先 Reset 重置,
if m == 0 && b.off != 0 {
b.Reset()
}
// 通过reslice 的方式,判断当前 len到cap部分 的空余空间,是否满足数据需求
if i, ok := b.tryGrowByReslice(n); ok {
return i
}
// 初始化结构体的时候,可能当前的 buf 是 nil,如果当前 buf 是 nil,且需要的空间小于定义的最小缓冲大小,
// 那么就初始化缓冲数组容量为smallBufferSize,长度为 n
if b.buf == nil && n <= smallBufferSize {
b.buf = make([]byte, n, smallBufferSize)
return 0
}
// 上面的一些快速满足的方式,如果都达不到要求,那么下面就需要通过整理数据,或者重新分配内存的方式,来满足需求:
c := cap(b.buf)
// 数据平移,将所有的有用数据,平移到缓冲切片头部,类似于数据整理
// 按理来说,当 未读数据m + 需要新增字节数n < 切片容量 c时,就可以完成平移,但是为了防止下次再次grow时,频繁的数据拷贝,设置的条件为 m+n < n/2
if n <= c/2-m {
copy(b.buf, b.buf[b.off:])
} else if c > maxInt-c-n { // 重新分配内存的大小为 2*切片容量c + 新增容量 n,如果需要重新分配的大小超出了最大容量,直接panic
panic(ErrTooLarge)
} else {
// 重新分配内存,然后将之前的数据拷贝到新的切片中
buf := makeSlice(2*c + n)
copy(buf, b.buf[b.off:])
// 新的切片作为缓冲切片
b.buf = buf
}
// 重置已读计数为0,同时长度设置为 m+n。
// 需要注意的是,[0,m)这段数据是历史数据,[m,n)没有数据,是空余出来给调用方放数据的,如果调用方不需要放数据,需要修改buf的len,可以参考 Grow方法
b.off = 0
b.buf = b.buf[:m+n]
// 返回写数据的开始位置
return m
}
makeSlice()
创建一个容量为 n 的字节切片,如果分配失败,产生 ErrTooLarge 的 panic,grow()方法调用到了该方法。
//
func makeSlice(n int) []byte {
// If the make fails, give a known error.
defer func() {
if recover() != nil {
panic(ErrTooLarge)
}
}()
return make([]byte, n)
}
Grow()
对外暴露的用于手动扩容的方法。Grow() 通过调整底层的缓冲切片,确保可写入n个字节的数据。
func (b *Buffer) Grow(n int) {
// 如果 n<0,会直接panic
if n < 0 {
panic("bytes.Buffer.Grow: negative count")
}
// m 是下次写入的开始位置,根据 grow 方法,当前 buf 的长度为 m+n,由于不需要写数据,更新buf 的长度为 m
m := b.grow(n)
b.buf = b.buf[:m]
}
源码分析
Go 语言 bytes.Buffer 源码详解 2 | 稀土掘金 | CodePlayer竟然被占用了
Write()
Write 方法将字节切片 p 中的数据写入到 缓冲切片中,返回写入的字节长度和产生的error
由于Write 调用了grow 方法,如果底层的缓冲切片太大无法重新分配,会产生 ErrTooLarge 的panic
func (b *Buffer) Write(p []byte) (n int, err error) {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入len(p)个字节。
m, ok := b.tryGrowByReslice(len(p))
if !ok {
m = b.grow(len(p))
}
// 走到这里,说明 buf 从m位置开始已经有了 len(p)个空闲字节,调用copy方法,将p中的数据复制过去
return copy(b.buf[m:], p), nil
}
WriteString()
WriteString 和 Write 方法类似,将传入的字符串 s 写入到底层的缓冲切片 buf 中,返回成功写入的字节数 n 和产生的 error
func (b *Buffer) WriteString(s string) (n int, err error) {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 len(s) 个字节。
m, ok := b.tryGrowByReslice(len(s))
if !ok {
m = b.grow(len(s))
}
// 到这里说明buf 从m位置开始已经有了 len(s) 个空闲字节,调用copy方法,将 s 复制到底层缓冲切片中
return copy(b.buf[m:], s), nil
}
WriteByte()
和 Write 方法类似,写入单个字节,而非字节切片
func (b *Buffer) WriteByte(c byte) error {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 1 个字节
m, ok := b.tryGrowByReslice(1)
if !ok {
m = b.grow(1)
}
// m 表示扩容后写入的开始位置,直接赋值为要写入的字节
b.buf[m] = c
return nil
}
WriteRune()
和 Write 方法类似,区别是写入 rune,而非字节切片
func (b *Buffer) WriteRune(r rune) (n int, err error) {
// 如果r < utf8.RuneSelf,说明 r 就是一个字节,那么直接调用 WriteByte 方法
if r < utf8.RuneSelf {
b.WriteByte(byte(r))
return 1, nil
}
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 utf8.UTFMax 个字节
m, ok := b.tryGrowByReslice(utf8.UTFMax)
if !ok {
m = b.grow(utf8.UTFMax)
}
// 此时的buf 长度,变成了 len(buf)+ utf8.UTFMax,utf8.UTFMax 是rune 可能的最大长度,但是当前 rune 的大小可能小于这个值
// 调用 utf8.EncodeRune() 方法,将 rune r 写入到 buf 中,返回写入的字节数
n = utf8.EncodeRune(b.buf[m:m+utf8.UTFMax], r)
// 更新 buf 的长度,因为 n<= utf8.UTFMax
b.buf = b.buf[:m+n]
return n, nil
}
ReadFrom()
ReadFrom 方法从 Reader r 读取数据,写入底层的缓冲切片 buf 中,返回写入的字节数和产生的error
在读取数据并写入缓冲切片过程中,如果缓冲切片容量不足,会调用 grow 方法增大缓冲切片大小
读取写入这个过程一直循环,直至产生 error,如果最终产生的时 EOF error,即 reader r 读取数据到了文件结尾,方法最终返回的 error 为 nil,因为任务已经完成了
// 缓冲切片留出的最小空闲空间
// ReadFrom 方法会用到该参数,即从一个 Reader 写入数据到底层缓冲切片 buf 时,buf 留出的最小空闲空间
const MinRead = 512
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
// for 循环,不断读取写入数据,直至遇到Reader 读取数据完毕产生 EOF error 或者 其他 error
for {
// 保证至少留出 MinRead 个空闲字节空间,并返回写入开始位置 i
i := b.grow(MinRead)
// grow 方法将长度变为了 i+MinRead,改回来
b.buf = b.buf[:i]
// i 位置开始,到 cap(buf) 结束的空间,即从 i位置 开始的底层数组所有空间都供 reader r 读取数据写入
// Read 方法会返回读取的字节数和产生的error,根据Read方法的定义,应该先处理m,再处理e
m, e := r.Read(b.buf[i:cap(b.buf)])
if m < 0 {
panic(errNegativeRead)
}
// 如果 m 大于等于0,说明读取并写入数据到buf 中了,修改buf 的长度
b.buf = b.buf[:i+m]
// 已读字节数n 加 m
n += int64(m)
// 如果Reader r 读取过程中遇到了EOF error,说明读取数据完毕了,返回 error=nil
if e == io.EOF {
return n, nil // e is EOF, so return nil explicitly
}
// 遇到了其他error,返回error
if e != nil {
return n, e
}
}
}
上面介绍的是写入缓冲区的相关操作,接下来我们来看读取相关的操作。
WriteTo()
WriteTo 方法,读取字节缓冲切片中的数据,交由 Writer w 去消费使用,最终返回 Writer w 消费的字节量和产生的error
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error) {
b.lastRead = opInvalid
// nBytes:未读数据的长度
if nBytes := b.Len(); nBytes > 0 {
// 如果未读数据的长度大于0,将从已读计数 off 到len()部分的未读数据,写入到Writer w 中
// Write 返回消费的字节数,以及产生的error
m, e := w.Write(b.buf[b.off:])
// 如果消费的长度,大于可用长度,不符合逻辑,panic
if m > nBytes {
panic("bytes.Buffer.WriteTo: invalid Write count")
}
// 被消费了 m 个字节,已读计数相应增加 m
b.off += m
// 消费的字节量 n = int64(m)
n = int64(m)
// 如果产生了 error,返回
if e != nil {
return n, e
}
// 根据 io.Writer 接口对 Write 方法的定义,如果写入的数量 m != nBytes,一定会返回error!=nil
// 因此上一步的 e!=nil 一定成立,会直接返回,导致到不了这一步,这一步相当于做了个double check
if m != nBytes {
return n, io.ErrShortWrite
}
}
// 到这一步,说明缓冲切片中的未读数据被读完了,直接调用Reset()方法重置
b.Reset()
return n, nil
}
Read()
Read 方法,读取底层缓冲字节切片 buf 中的数据,写入到字节切片 p 中
// 方法读取的字节数,和产生的 error
func (b *Buffer) Read(p []byte) (n int, err error) {
b.lastRead = opInvalid
// 如果 buf 中无数据可读,且len(p)=0,返回 error=nil,否则返回 error=EOF
// 如果未读数据部分为空,没有数据可读
if b.empty() {
// 首先将字节缓冲切片重置
b.Reset()
// len(p)=0,返回的 error=nil
if len(p) == 0 {
return 0, nil
}
// 读取的数据小于 len(p),返回 EOF error
return 0, io.EOF
}
// 存在未读数据,调用 copy 方法,从 off 位置开始复制数据到 p 中,返回复制的字节数
n = copy(p, b.buf[b.off:])
// 更新已读计数
b.off += n
// 读取到数据了,此次是一次合法的读操作,更新 lastRead 为 opRead
if n > 0 {
b.lastRead = opRead
}
// 返回读取的字节数 n,error=nil
return n, nil
}
Next()
Next 方法返回未读数据的前 n 个字节,如果未读数据长度小于n个字节,那么就返回所有的未读数据。由于方法返回的数据是基于buf的切片,存在数据泄露的风险,且数据的有效期在下次调用read 或 write 方法前,因为调用read、write方法会修改底层数据。
func (b *Buffer) Next(n int) []byte {
b.lastRead = opInvalid
// m:未读数据长度
m := b.Len()
// 如果需要的字节数 n,大于未读数据长度m,那么n=m
if n > m {
n = m
}
// 赋值 data 为所需的n个字节
data := b.buf[b.off : b.off+n]
// 已读计数增加 n
b.off += n
if n > 0 {
b.lastRead = opRead
}
return data
}
ReadByte()
类似 Read 方法,ReadByte 读取一个字节,返回读取的字节和产生的error
func (b *Buffer) ReadByte() (byte, error) {
// 如果没有未读数据,重置,返回 EOF error
if b.empty() {
// Buffer is empty, reset to recover space.
b.Reset()
return 0, io.EOF
}
// 读取一个字节,然后修改已读计数
c := b.buf[b.off]
b.off++
b.lastRead = opRead
return c, nil
}
ReadRune()
类似 Read 方法,ReadRune 读取一个utf-8编码的 rune,返回 rune 的值、大小以及产生的 error
func (b *Buffer) ReadRune() (r rune, size int, err error) {
// 如果没有数据可读,重置,返回 EOF error
if b.empty() {
b.Reset()
return 0, 0, io.EOF
}
// c 代表开始读取的第一个字节
c := b.buf[b.off]
// 如果 c < utf8.RuneSelf,表示 c 是一个单字节的 rune,直接返回这个 rune,已读计数加一即可
if c < utf8.RuneSelf {
b.off++
b.lastRead = opReadRune1
return rune(c), 1, nil
}
// 从已读计数位置开始,调用utf8.DecodeRune,方法返回从已读计数位置开始的rune,以及对应的字节数
r, n := utf8.DecodeRune(b.buf[b.off:])
// 修改已读计数
b.off += n
// 修改lastRead
b.lastRead = readOp(n)
return r, n, nil
}
UnreadRune()
回退一个 rune,只能在 ReadRune 后调用该方法才有效,其他 read 方法之后后调用该方法非法,因为其他相关的 read 方法记录的 lastRead = opRead,而不是 opReadRune*
func (b *Buffer) UnreadRune() error {
// lastRead <= opInvalid,表示上一次调用为非ReadRune 方法,不能进行回退
if b.lastRead <= opInvalid {
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune")
}
// 回退
if b.off >= int(b.lastRead) {
b.off -= int(b.lastRead)
}
// 只能回退一次,不能再次回退
b.lastRead = opInvalid
return nil
}
UnreadByte()
回退一个字节,该方法的要求比 UnreadRune 方法要低,只要是 read 相关的方法都能回退一个字节
var errUnreadByte = errors.New("bytes.Buffer: UnreadByte: previous operation was not a successful read")
func (b *Buffer) UnreadByte() error {
// 只有 lastRead == opInvalid 才不能回退( ReadRune 也可以回退 )
if b.lastRead == opInvalid {
return errUnreadByte
}
// 只能回退一次
b.lastRead = opInvalid
// 已读计数减一
if b.off > 0 {
b.off--
}
return nil
}
readSlice()
私有方法,readSlice 读取未读数据,直至找到 delim 这个字符停止,然后返回遍历到的数据。返回的数据是基于底层缓冲切片的引用,存在数据泄露的风险。
func (b *Buffer) readSlice(delim byte) (line []byte, err error) {
// 调用 IndexByte(),从 off 位置开始查找,找到第一个出现 delim 的索引,如果没找到会返回 -1
i := IndexByte(b.buf[b.off:], delim)
// 因为上一步索引从0开始,所以要再加 1
end := b.off + i + 1
// 没有找到,需要返回所有未读数据,因此 end 赋值为 缓冲数组长度,err 为 EOF
if i < 0 {
end = len(b.buf)
err = io.EOF
}
// 返回遍历过的数据,更新已读计数
line = b.buf[b.off:end]
b.off = end
// 此次操作也是 opRead
b.lastRead = opRead
// 返回数据和error
return line, err
}
ReadBytes()
ReadBytes 遍历未读数据,直至遇到一个字节值为 delim 的分隔符,然后返回遍历过的数据(包括该分隔符)和产生的 error。
ReadBytes 直接调用的 readSlice,因此只有一种情况会返回error!=nil,即在未读数据中,遍历完所有数据但没有找到该分隔符时,此时会返回所有未读数据和EOF error。
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error) {
// 直接调用 readSlice() 方法,但是该方法返回的是底层切片的引用
// readSlice() 方法已经修改了 已读计数和 lastRead
slice, err := b.readSlice(delim)
// 由于readSlice() 返回的是引用,数据可能因为其他方法调用被修改,因此拷贝一份数据
line = append(line, slice...)
return line, err
}
ReadString()
ReadString 和 ReadBytes 类似,区别是该方法返回的是字符串形式。
func (b *Buffer) ReadString(delim byte) (line string, err error) {
// 直接调用 readSlice()方法,但是该方法返回的是底层切片的引用
// readSlice() 方法已经修改了 已读计数和 lastRead
slice, err := b.readSlice(delim)
// 转为字符串返回
return string(slice), err
}
NewBuffer()
实例化一个 Buffer,使用传入的字节切片 buf 作为底层的缓冲字节切片,也可以传入 nil
在初始化完成后,调用者不能再操作传入的字节切片 buf 了,否则会影响数据正确性
传入的切片数组作用:供 read 方法读取切片中的已有数据,或者供 write 方法写入数据,因此传入的字节切片的容量尽量避免为0
bytes.Buffer 是开箱即用的,大多数情况下,直接 new(Buffer) 或者声明一个变量就可以了,没必要调用 NewBuffer() 方法
func NewBuffer(buf []byte) *Buffer { return &Buffer{buf: buf} }
NewBufferString()
NewBufferString 传入一个字符串用于初始化bytes.Buffer,因此底层的字节缓冲切片就有了初始值,就有了数据用于读取。
bytes.Buffer 是开箱即用的,大多数情况下,直接 new(Buffer) 或者声明一个变量就可以了,没必要调用 NewBufferString() 方法
func NewBufferString(s string) *Buffer {
return &Buffer{buf: []byte(s)}
}
使用示例
下面的示例,使用了 bytes.Buffer 作为缓冲区,完成了一个文件复制的操作。
func main() {
var buffer bytes.Buffer
srcFile, _ := os.OpenFile("test.txt", os.O_RDWR, 0666)
n, err := buffer.ReadFrom(srcFile)
fmt.Println(n, err) // 303190 <nil>
fmt.Println(buffer.Len(), buffer.Cap()) // 303190 523776
targetFile, _ := os.OpenFile("target.txt", os.O_RDWR|os.O_CREATE|os.O_TRUNC, 0666)
n, err = buffer.WriteTo(targetFile)
fmt.Println(n, err) // 303190 <nil>
fmt.Println(buffer.Len(), buffer.Cap()) // 0 523776
}
构建CLIs(Building CLIs)
Cobra
cobra package | pkg.go.dev
golang工程组件之命令行框架cobra | CSDN | SMILY12138
Cobra用户手册 | github | spf13(必看)
我的理解
Cobra就是一个给你的app或软件弄一个命令行的输入界面。
下面以docker为例子。
docker run -d --name mynginx nginx:latest
docker是命令(Commands),但它是根命令。也就是rootCmd,你应用的所有命令都这单词开始。run是命令,但它是子命令。也就是SubCmd,通常都是用AddCommand()添加到rootCmd里。-d和--name是选项(flags),代表对命令行为的改变。nginx:latest是参数(arguments)。
安装Cobra
go get -u github.com/spf13/cobra@latest
import "github.com/spf13/cobra"
如何创建一个命令
package main
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
// rootCmd表示应用程序的根命令
var rootCmd = &cobra.Command{
Use: "myapp", // 使用`myapp`作为应用程序的名称
Short: "A brief description of my app", // 应用程序的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 应用程序的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当rootCmd运行时执行的逻辑,打印"Hello, Cobra!"
fmt.Println("Hello, Cobra!")
},
}
func main() {
// 执行根命令rootCmd,如果出现错误则打印错误信息并退出程序
if err := rootCmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
子命令
package main
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
// rootCmd 表示应用程序的根命令
var rootCmd = &cobra.Command{
Use: "myapp", // 使用`myapp`作为应用程序的名称
Short: "A brief description of my app", // 应用程序的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 应用程序的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 rootCmd 运行时执行的逻辑,打印"Hello, Cobra!"
fmt.Println("Hello, Cobra!")
},
}
// subCmd 表示应用程序的子命令
var subCmd = &cobra.Command{
Use: "sub", // 使用`sub`作为子命令的名称
Short: "A brief description of sub command", // 子命令的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 子命令的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 subCmd 运行时执行的逻辑,打印"Hello, Sub Command!"
fmt.Println("Hello, Sub Command!")
},
}
func init() {
// 将 subCmd 添加为 rootCmd 的子命令
rootCmd.AddCommand(subCmd)
}
func main() {
// 执行根命令 rootCmd,如果出现错误则打印错误信息并退出程序
if err := rootCmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
添加选项(Flags)
package main
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
// rootCmd 表示应用程序的根命令
var rootCmd = &cobra.Command{
Use: "myapp", // 使用`myapp`作为应用程序的名称
Short: "A brief description of my app", // 应用程序的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 应用程序的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 rootCmd 运行时执行的逻辑
name, _ := cmd.Flags().GetString("name") // 从命令行参数中获取名为"name"的值
age, _ := cmd.Flags().GetInt("age") // 从命令行参数中获取名为"age"的值
fmt.Printf("Name: %s, Age: %d\n", name, age) // 打印获取到的姓名和年龄
},
}
func init() {
// 为 rootCmd 添加名为"name"的字符串类型标志,短标志为"-n",默认值为空,描述为"Your name"
rootCmd.Flags().StringP("name", "n", "", "Your name")
// 为 rootCmd 添加名为"age"的整数类型标志,短标志为"-a",默认值为0,描述为"Your age"
rootCmd.Flags().IntP("age", "a", 0, "Your age")
}
func main() {
// 执行根命令 rootCmd,如果出现错误则打印错误信息并退出程序
if err := rootCmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
嵌套
package main
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
// rootCmd 表示应用程序的根命令
var rootCmd = &cobra.Command{
Use: "myapp", // 使用`myapp`作为应用程序的名称
Short: "A brief description of my app", // 应用程序的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 应用程序的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 rootCmd 运行时执行的逻辑
fmt.Println("Hello, Cobra!")
},
}
// subCmd 表示一个子命令
var subCmd = &cobra.Command{
Use: "sub", // 子命令的名称
Short: "A brief description of sub command", // 子命令的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 子命令的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 subCmd 运行时执行的逻辑
fmt.Println("Hello, Sub Command!")
},
}
// nestedCmd 表示 subCmd 的嵌套命令
var nestedCmd = &cobra.Command{
Use: "nested", // 嵌套命令的名称
Short: "A brief description of nested command", // 嵌套命令的简短描述
Long: `A longer description that spans multiple lines and likely contains examples`, // 嵌套命令的详细描述,可以跨多行
Run: func(cmd *cobra.Command, args []string) {
// 当 nestedCmd 运行时执行的逻辑
fmt.Println("Hello, Nested Command!")
},
}
func init() {
// 将子命令 subCmd 添加到根命令 rootCmd 中
rootCmd.AddCommand(subCmd)
// 将嵌套命令 nestedCmd 添加到子命令 subCmd 中
subCmd.AddCommand(nestedCmd)
}
func main() {
// 执行根命令 rootCmd,如果出现错误则打印错误信息并退出程序
if err := rootCmd.Execute(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
参数和钩子函数
Cobra用户手册 | github | spf13(必看)
搭建ORM框架
GORM
GORM手册
GORM Package | pkg.go.dev
用处
ORM=对象关系映射 Object Relational Mapping
把对象和数据库的表对联
好的地方
- 代码工整
- 减少工作量
- 通用系统部署方便
- 解耦数据库和数据层
不好的地方 - 数据层不会显著减少
- 使用大量的反射
- 需要SQL基础
- 提供大量的表关系接口
安装
go get -u gorm.io/gorm
go get -u gorm.io/driver/sqlite
实践
main.go
package main
func main() {
_case.Crud()
}
conn.go
package _case
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
var DB *gorm.DB
// 数据库连接信息
var dsn := "username:password@tcp(127.0.0.1:3306)/database_name?charset=utf8mb4&parseTime=True&loc=Local"
func init() {
var err error
// 使用 GORM 打开数据库连接,并设置连接池
db, err := gorm.Open(mysql.New(mysql.Config{
DSN: "gorm:gorm@tcp(127.0.0.1:3306)/gorm?charset=utf8&parseTime=True&loc=Local", // 数据源
DefaultStringSize: 256, // 字符串字段的默认大小
DisableDatetimePrecision: true, // 禁用日期时间精度,不支持 MySQL 5.6 之前的版本
DontSupportRenameIndex: true, // 重命名索引时使用删除和创建索引的方式,不支持 MySQL 5.7 之前的版本和 MariaDB
DontSupportRenameColumn: true, // 在重命名列时使用 `change`,不支持 MySQL 8 之前的版本和 MariaDB
SkipInitializeWithVersion: false, // 根据当前 MySQL 版本自动配置
}), &gorm.Config{
Logger: logger.Default.LogMode(logger.Info),// 日志等级为Info
PrepareStmt: true, // 控制是否使用准备语句,优化执行相同 SQL 语句的性能
SkipDefaultTransaction: false, // 控制是否跳过 GORM 默认的事务处理机制
DisableAutomaticPing: false, // 控制是否禁用自动 ping 数据库连接
FullSaveAssociations: false, // 控制是否保存所有关联数据
SkipNotNullColumns: false, // 控制是否跳过非空字段
AllowGlobalUpdate: false, // 控制是否允许全局更新
DisableNestedTransaction: false, // 控制是否禁用嵌套事务
NamingStrategy: nil, // 设置命名策略,可以自定义命名规则
})
if err != nil {
log.Println(err)
return
}
setPool(DB)
}
func setPool() {
// 设置连接池配置
sqlDB, err := db.DB()
if err != nil {
log.Println(err)
return
}
sqlDB.SetMaxIdleConns(10) // 设置连接池中的最大空闲连接数
sqlDB.SetMaxOpenConns(100) // 设置数据库的最大连接数量
sqlDB.SetConnMaxLifetime(time.Hour) // 不限制连接的存活时间
}
models.go
package _case
import "gorm.io/gorm"
func init() {
// 在应用启动时,通过 DB.Migrator().AutoMigrate() 方法自动迁移数据库表结构
// 这会根据 Teacher 结构体定义的规则自动创建对应的数据库表
DB.Migrator().AutoMigrate(Teacher{})
}
// Roles 自定义类型,表示教师的角色列表
type Roles []string
// Teacher 结构体定义,用于映射教师信息到数据库表
type Teacher struct {
gorm.Model // 内嵌 gorm.Model 结构体,用于自动添加 ID、CreatedAt、UpdatedAt、DeletedAt 字段
Name string `gorm:"size:256"` // 姓名字段,限制长度为 256
Email string `gorm:"size:256"` // 邮箱字段,限制长度为 256
Salary float64 `gorm:"scale:2;precision:7"` // 薪水字段,设置精度为7位,保留小数点后两位
Age unit8 `gorm:"check:age>30"` // 年龄字段,设置检查约束,仅允许大于30的值
Birthday int64 `gorm:"serializer:unixtime;type:time"` // 生日字段,设置序列化为Unix时间戳存储,并存储为时间类型
Roles Roles `gorm:"serializer:json"` // 角色字段,使用JSON序列化存储
}
crud.go
package _case
import (
"time"
"fmt"
)
func Crud() {
// 创建数据
temp := Teacher{
Name: "nick",
Age: 40,
Roles: []string{"普通用户", "讲师"},
Birthday: time.Now().Unix(),
Salary: 12345.1234,
Email: "nick@email.com",
}
t := temp
// 将教师对象写入数据库
res := DB.Create(&t)
fmt.Println("Create Result:")
fmt.Println("Rows Affected:", res.RowsAffected)
fmt.Println("Error:", res.Error)
fmt.Println("Teacher ID:", t.ID)
// 查询数据
t1 := Teacher{}
DB.First(&t1)
fmt.Println("\nQuery Result:")
fmt.Println("Teacher Found:")
fmt.Println(t1)
// 高级查询
t2 := Teacher{}
DB.Where("age > ?", 30).First(&t2)
fmt.Println("\nAdvanced Query Result:")
fmt.Println("Teacher with Age > 30:")
fmt.Println(t2)
// 更新数据
t1.Name = "king"
t1.Age = 31
DB.Save(&t1)
fmt.Println("\nUpdate Result:")
fmt.Println("Updated Teacher:")
fmt.Println(t1)
// 删除数据
DB.Delete(&t1)
fmt.Println("\nDelete Result:")
fmt.Println("Teacher Deleted")
// SQL生成器
var teachers []Teacher
DB.Raw("SELECT * FROM teachers WHERE age > ?", 30).Scan(&teachers)
fmt.Println("\nSQL Builder Result:")
fmt.Println("Teachers with Age > 30:")
fmt.Println(teachers)
}
hook.go
package _case
// BeforeSave 在保存数据之前触发的钩子函数,输出日志信息 "hook BeforeSave"
func (t *Teacher) BeforeSave(tx &gorm.DB) error {
fmt.Println("hook BeforeSave")
return nil
}
// AfterSave 在保存数据之后触发的钩子函数,输出日志信息 "hook AfterSave"
func (t *Teacher) AfterSave(tx &gorm.DB) error {
fmt.Println("hook AfterSave")
return nil
}
// BeforeCreate 在创建新数据之前触发的钩子函数,输出日志信息 "hook BeforeCreate"
func (t *Teacher) BeforeCreate(tx &gorm.DB) error {
fmt.Println("hook BeforeCreate")
return nil
}
// AfterCreate 在创建新数据之后触发的钩子函数,输出日志信息 "hook AfterCreate"
func (t *Teacher) AfterCreate(tx &gorm.DB) error {
fmt.Println("hook AfterCreate")
return nil
}
// BeforeUpdate 在更新数据之前触发的钩子函数,输出日志信息 "hook BeforeUpdate"
func (t *Teacher) BeforeUpdate(tx &gorm.DB) error {
fmt.Println("hook BeforeUpdate")
return nil
}
// AfterUpdate 在更新数据之后触发的钩子函数,输出日志信息 "hook AfterUpdate"
func (t *Teacher) AfterUpdate(tx &gorm.DB) error {
fmt.Println("hook AfterUpdate")
return nil
}
// BeforeDelete 在删除数据之前触发的钩子函数,输出日志信息 "hook BeforeDelete"
func (t *Teacher) BeforeDelete(tx &gorm.DB) error {
fmt.Println("hook BeforeDelete")
return nil
}
// AfterDelete 在删除数据之后触发的钩子函数,输出日志信息 "hook AfterDelete"
func (t *Teacher) AfterDelete(tx &gorm.DB) error {
fmt.Println("hook AfterDelete")
return nil
}
// AfterFind 在查询数据之后触发的钩子函数,输出日志信息 "hook AfterFind"
func (t *Teacher) AfterFind(tx &gorm.DB) error {
fmt.Println("hook AfterFind")
return nil
}
session.go
package _case
import (
"time"
"fmt"
)
func Session() {
// 创建一个具有特定配置的事务会话
tx := DB.Session(&gorm.Session{
PrepareStmt: true, // 执行预处理语句以提高性能
SkipHooks: true, // 跳过钩子函数的执行
DisableNestedTransaction: true, // 禁用嵌套事务
Logger: DB.Logger.LogMode(logger.Error), // 设置日志记录器,只记录错误信息
})
// 创建一个教师对象
t := Teacher{
Name: "nick",
Age: 40,
Roles: []string{"普通用户", "讲师"},
Birthday: time.Now().Unix(),
Salary: 12345.1234,
Email: "nick@email.com",
}
// 在事务会话中创建教师对象
tx.Create(&t)
}
tx.go
import "gorm.io/gorm"
func Transaction() {
t := teacherTemp // 定义一个教师对象 t
t1 := teacherTemp // 定义另一个教师对象 t1
// 开启数据库事务
DB.Transaction(func(tx *gorm.DB) error {
// 在事务中创建教师对象 t
if err := tx.Create(&t).Error; err != nil {
return err // 如果创建过程中出现错误,回滚事务并返回错误
}
// 在事务中创建教师对象 t1
if err := tx.Create(&t1).Error; err != nil {
return err // 如果创建过程中出现错误,回滚事务并返回错误
}
return nil // 事务操作成功,提交事务
})
}
func NestTransaction() {
t := teacherTemp
t1 := teacherTemp
t2 := teacherTemp
t3 := teacherTemp
DB.Transaction(func(tx *gorm.DB) error {
if err := tx.Create(&t).Error; err != nil {
return err // 如果创建过程中出现错误,回滚事务并返回错误
}
// 嵌套事务1
tx.Transaction(func(tx1 *gorm.DB) error {
tx1.Create(t1)
return errors.New("rollback t1") // 回滚嵌套事务1并返回错误信息
})
// 嵌套事务2
tx.Transaction(func(tx2 *gorm.DB) error {
if err := tx.Create(&t2).Error; err != nil {
return err // 如果创建过程中出现错误,回滚嵌套事务2并返回错误
}
return err
})
// 创建教师对象 t3
if err := tx.Create(&t3).Error; err != nil {
return err // 如果创建过程中出现错误,回滚事务并返回错误
}
return nil // 所有操作成功,提交事务
})
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)