第十一篇:监督学习中关于线性回归问题的系统讨论
前言
本文将系统的介绍机器学习中监督学习的回归部分,系统的讲解如何利用回归理论知识来预测出一个分类的连续值。
显然,与监督学习中的分类部分相比,它有很鲜明的特点:输出为连续值,而不仅仅是标称类型的分类结果。
基本线性回归解决方案 - 最小二乘法
“给出一堆散点,求出其回归方程。" -> 对于这个问题,很多领域都碰到过,而其中最为经典普遍的做法通常是:
1. 用式子表示出各个散点到回归线之间的距离之和:
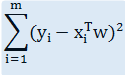
m 为散点数量,yi 为散点值,xi 为散点坐标,w 为回归系数向量。
2. 对上式以向量 w 求导,求出导数值为 0 时的回归系数 (具体求导过程涉及到对向量求导的相关法则,略):
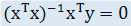
这种方法就叫做最小二乘法。
最小二乘法的具体实现
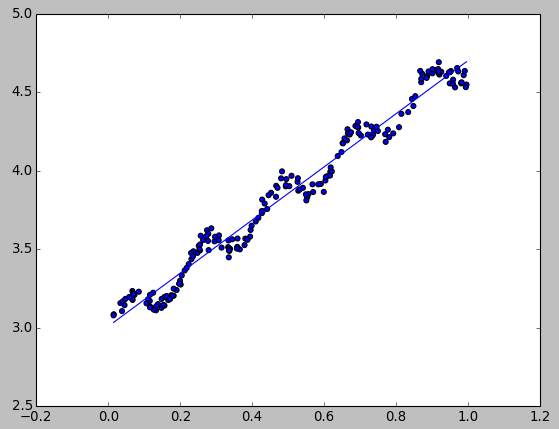
下面这个小程序从文本中读取散点,然后拟合出回归直线,并使用 matplotlib 展示出来 (注: 为了清楚直观,特征 0 没展示出来):
1 #!/usr/bin/env python 2 # -*- coding:UTF-8 -*- 3 4 ''' 5 Created on 20**-**-** 6 7 @author: fangmeng 8 ''' 9 10 from numpy import * 11 12 def loadDataSet(fileName): 13 '载入测试数据' 14 15 numFeat = len(open(fileName).readline().split('\t')) - 1 16 dataMat = []; labelMat = [] 17 fr = open(fileName) 18 for line in fr.readlines(): 19 lineArr =[] 20 curLine = line.strip().split('\t') 21 for i in range(numFeat): 22 lineArr.append(float(curLine[i])) 23 dataMat.append(lineArr) 24 labelMat.append(float(curLine[-1])) 25 return dataMat,labelMat 26 27 #=================================== 28 # 输入: 29 # xArr: 特征坐标矩阵 30 # yArr: 特征值矩阵 31 # 输出: 32 # w: 回归系数向量 33 #=================================== 34 def standRegres(xArr,yArr): 35 '采用最小二乘法求拟合系数' 36 37 xMat = mat(xArr); 38 yMat = mat(yArr).T 39 xTx = xMat.T*xMat 40 if linalg.det(xTx) == 0.0: 41 print "该矩阵无法求逆" 42 return 43 ws = xTx.I * (xMat.T*yMat) 44 return ws 45 46 def test(): 47 '展示结果' 48 49 # 采用最小二乘求出回归系数并预测出各特征点对应的特征值 50 xArr, yArr = loadDataSet('/home/fangmeng/ex0.txt') 51 ws = standRegres(xArr, yArr) 52 xMat = mat(xArr) 53 yMat = mat(yArr) 54 yHat = xMat * ws 55 56 import matplotlib.pyplot as plt 57 58 # 绘制所有样本点 59 fig = plt.figure() 60 ax = fig.add_subplot(111) 61 ax.scatter(xMat[:,1].flatten().A[0], yMat.T[:, 0].flatten().A[0]) 62 63 # 绘制回归线 64 xCopy = xMat.copy() 65 xCopy.sort(0) 66 yHat = xCopy*ws 67 ax.plot(xCopy[:, 1], yHat) 68 plt.show() 69 70 if __name__ == '__main__': 71 test()
测试结果:
观察预测与真实的相关系数:
1 print corrcoef(yHat.T, yMat)
测试结果:
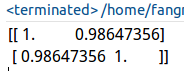
0.98+的相关系数,可见拟合的效果还是不错的。
局部加权线性回归
基本的线性回归经常会碰到一些问题。
比如由于线性回归本身导致的欠拟合问题。以最基本的一个特征的情况为例,如果散点图本身呈现一个非线性化的轮廓,而强行的将它拟合成一条直线:
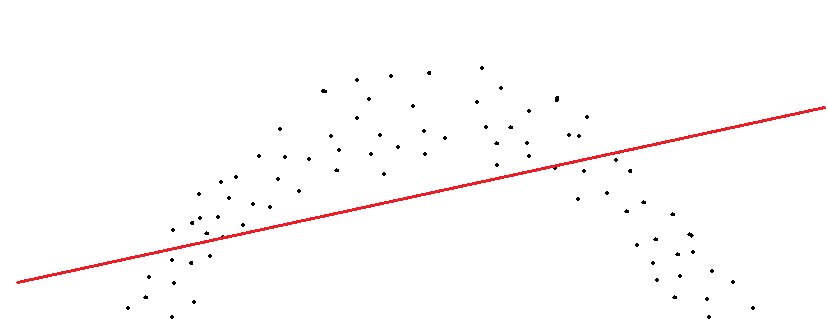
显然,两端的拟合是非常不科学的,偏离的很远。
针对这个问题,局部加权线性回归应运而生。它能够得到类似下图这样更为科学的拟合线段:
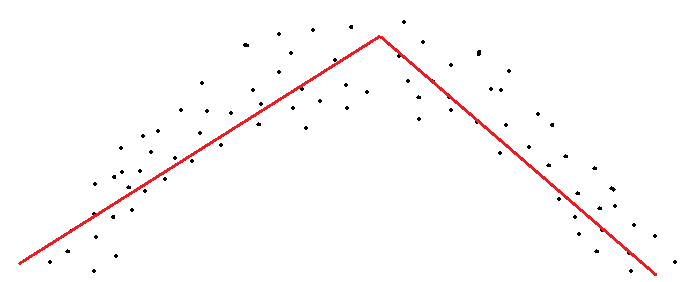
所谓局部,就是最大程度考虑待预测点附近的点,所谓加权,就是离待预测点越近,其参考系数(权重)就越大。
因此,在原先的最小二乘法中加入一个用于衡量权重的对角矩阵W。这样,回归系数的求解式就变为:
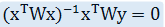
权重矩阵W又称为 "核",典型的高斯核的计算方法如下:
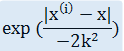
下面是采用局部加权线性回归思想的回归系数求解函数:
1 #=================================== 2 # 输入: 3 # testPoint: 测试点 4 # xArr: 特征坐标矩阵 5 # yArr: 特征值矩阵 6 # k: 高斯核权重衰减系数 7 # 输出: 8 # testPoint * ws: 测试点集对应的结果 9 #=================================== 10 def lwlr(testPoint,xArr,yArr,k=1.0): 11 '对指定点进行局部加权线性回归' 12 13 xMat = mat(xArr); 14 yMat = mat(yArr).T 15 m = shape(xMat)[0] 16 17 # 采用向量方式计算高斯核 18 weights = mat(eye((m))) 19 for j in range(m): 20 diffMat = testPoint - xMat[j,:] 21 weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2)) 22 23 xTx = xMat.T * (weights * xMat) 24 if linalg.det(xTx) == 0.0: 25 print "错误: 系数矩阵无法求逆" 26 return 27 28 ws = xTx.I * (xMat.T * (weights * yMat)) 29 return testPoint * ws 30 31 #=================================== 32 # 输入: 33 # testArr: 测试点集 34 # xArr: 特征坐标矩阵 35 # yArr: 特征值矩阵 36 # 输出: 37 # yHat: 测试点集对应的结果集 38 #=================================== 39 def lwlrTest(testArr,xArr,yArr,k=1.0): 40 '对指定点集进行局部加权回归' 41 42 m = shape(testArr)[0] 43 yHat = zeros(m) 44 45 # 求出所有测试点集的 46 for i in range(m): 47 yHat[i] = lwlr(testArr[i],xArr,yArr,k) 48 return yHat
如下代码展示回归结果:
1 def test(): 2 '展示结果' 3 4 # 载入数据 5 xArr, yArr = loadDataSet('/home/fangmeng/ex0.txt') 6 7 # 获取所有样本点的局部加权回归的预测值 8 yHat = lwlrTest(xArr, xArr, yArr, 0.01) 9 10 xMat = mat(xArr) 11 srtInd = xMat[:,1].argsort(0) 12 xSort = xMat[srtInd][:,0,:] 13 #print xMat[srtInd][:,0,:] 14 15 # 显示所有样本点和局部加权拟合线段 16 import matplotlib.pyplot as plt 17 fig = plt.figure() 18 ax = fig.add_subplot(111) 19 ax.plot(xSort[:,1], yHat[srtInd]) 20 ax.scatter(xMat[:,1].flatten().A[0], mat(yArr).T.flatten().A[0], s=2, c='red') 21 plt.show()
当k(衰减系数) = 1时,测试结果:

k(衰减系数) = 0.003时,测试结果:
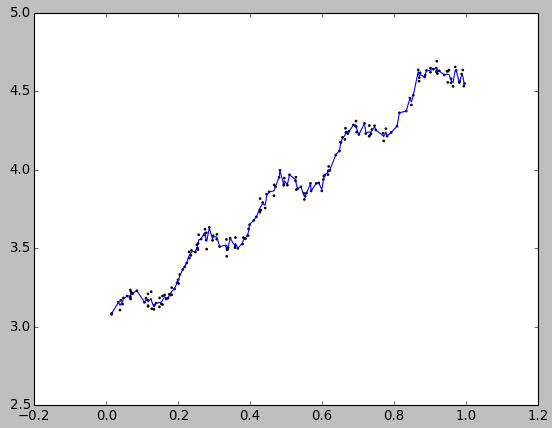
k(衰减系数) = 0.01时,测试结果:
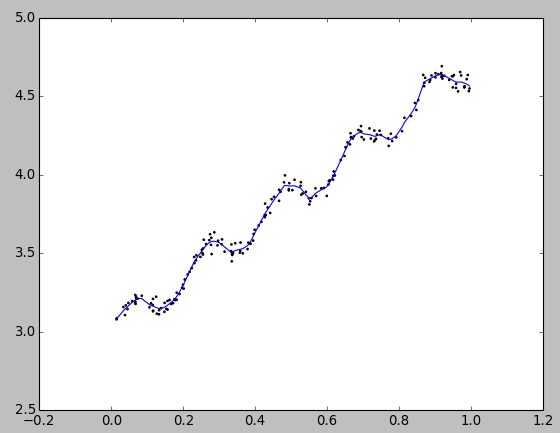
观察可以发现,k = 1就是和基本线性回归一样了 - 欠拟合;而 k = 0.003 则是过拟合了;k = 0.01 刚好,是最优的选择。
岭回归
假如碰到了这样的情况:散点个数小于特征数了。
这种情况有啥问题呢 ---- (xTx)-1 必然会求解失败!解决办法可以采用岭回归技术。
所谓岭回归,就是在回归系数求解式中的 xTx 之后加上 λI 使求逆部分可顺利求解,更改后的求解式如下:
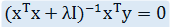
其中,I 是单位对角矩阵,看起来有点像山岭。这也是为什么这种回归方式叫做岭回归,哈哈!
具体的实现代码本文就不具体给出了,但是有两个地方要特别注意一下:
1. 需要对所有的数据进行标准化
2. 根据不同的 λ 取到不同组的回归系数之后,还需要对不同组的权重进行择优。比较常用的有 lasso 方法(和岭回归的区别在于 w 和 λ 的约束关系)。
具体方案的制定
提到了这么多种的回归方案,那么具体应该采用哪种好呢?
首先,得根据问题的特性选择合适的方案。然后,使用同一组测试集测试每组方案的相关系数情况。
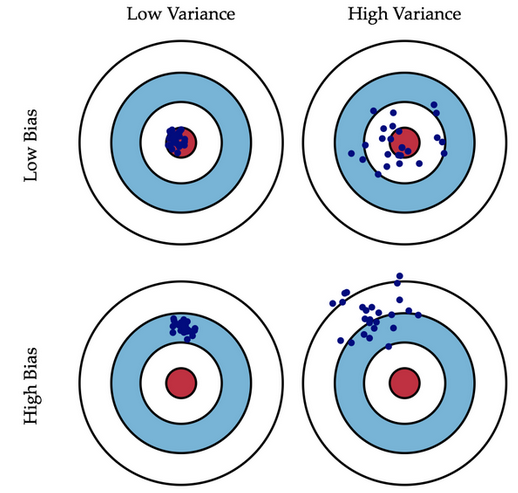
另外,实践表明在同样适用的情况下,"偏差与方差折中" 是一条很重要的经验法则。

红点位置对应的方案便是最佳方案。
另外,关于偏差和方差的区别,可参考下图:
小结
回归和分类一样,针对不同问题不同领域都有着不同算法。关键是要把握其整体思路,根据需要去进行选择。
然而,本文所讲解的都是线性回归。线性回归始终有其弊端,因为很多实际问题本身是非线性的。
因此在下篇文章中,将会专门详细地介绍一种高级的非线性回归法 - 树回归。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号