spark实验五
1.Spark SQL 基本操作
将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并保存命名为 employee.json。
{ "id":1 ,"name":" Ella","age":36 }
{ "id":2,"name":"Bob","age":29 }
{ "id":3 ,"name":"Jack","age":29 }
{ "id":4 ,"name":"Jim","age":28 }
{ "id":5 ,"name":"Damon" }
{ "id":5 ,"name":"Damon" }
首先为
employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
创建 DataFrame

查询 DataFrame 的所有数据:
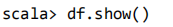
查询所有数据,并去除重复的数据:

查询所有数据,打印时去除 id 字段:

筛选 age>20 的记录:

将数据按 name 分组:

将数据按 name 升序排列:
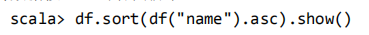
取出前 3 行数据:
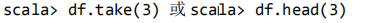
查询所有记录的 name 列,并为其取别名为 username:

查询年龄 age 的平均值:
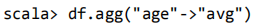
查询年龄 age 的最小值:

是多疑还是去相信
谎言背后的忠心
或许是自己太执迷
命题游戏
沿着他的脚步 呼吸开始变得急促
就算看清了面目 设下埋伏
真相却居无定处
I swear I'll never be with the devil
用尽一生孤独 没有退路的路
你看不到我
眉眼焦灼却不明下落
命运的轮轴
伺机而动 来不及闪躲
沿着他的脚步 呼吸开始变得急促
就算看清了面目 设下埋伏
真相却居无定处
I swear I'll never be with the devil
用尽一生孤独 没有退路的路
你看不到我
眉眼焦灼却不明下落
命运的轮轴
伺机而动 来不及闪躲
你看不到我
眉眼焦灼却不明下落
命运的轮轴
伺机而动 来不及闪躲
黑夜和白昼
你争我夺 真相被蛊惑
心从不退缩
这天堂荒漠 留给孤独的猎手
