
Linux内核网络数据包处理流程
Linux内核网络数据包处理流程
from kernel-4.9:
0. Linux内核网络数据包处理流程 - 网络硬件
网卡工作在物理层和数据链路层,主要由PHY/MAC芯片、Tx/Rx FIFO、DMA等组成,其中网线通过变压器接PHY芯片、PHY芯片通过MII接MAC芯片、MAC芯片接PCI总线
PHY/MAC芯片
PHY芯片主要负责:CSMA/CD、模数转换、编解码、串并转换
MAC芯片主要负责:
-
比特流和帧的转换:7字节的前导码Preamble和1字节的帧首定界符SFD
-
CRC校验
-
Packet Filtering:L2 Filtering、VLAN Filtering、Manageability / Host Filtering
Intel的千兆网卡以82575/82576为代表、万兆网卡以82598/82599为代表
1. Linux内核网络数据包处理流程 - 网卡驱动
网卡驱动ixgbe初始化
网卡驱动为每个新的接口在一个全局的网络设备列表里插入一个数据结构.每个接口由一个结构 net_device 项来描述, 它在<linux/netdevice.h>里定义。该结构必须动态分配。
每个网卡,无论是物理还是虚拟的网卡,都必须有一个:net_device,这个struct是在网卡驱动中分配创建的,不通的网卡,对应厂商不同的驱动,那么看看ixgbe的驱动初始化; 创建net_device 的函数是: alloc_etherdev , 或者: alloc_etherdev_mq
https://www.cnblogs.com/lidp/archive/2009/05/13/1697981.html
pci设备:
在内核中,一个PCI设备,使用struct pci_driver结构来描述, 因为在系统引导的时候,PCI设备已经被识别,当内核发现一个已经检测到的设备同驱动注册的id_table中的信息相匹配时,
它就会触发驱动的probe函数,
比如,看看ixgbe 驱动:
static struct pci_driver ixgb_driver = {
.name = ixgb_driver_name,
.id_table = ixgb_pci_tbl,
.probe = ixgb_probe,
.remove = ixgb_remove,
.err_handler = &ixgb_err_handler
};
#vim drivers/net/ethernet/intel/ixgbe/ixgbe_main.c
module_init
ixgbe_init_module
pci_register_driver
当probe函数被调用,证明已经发现了我们所支持的网卡,这样,就可以调用register_netdev函数向内核注册网络设备了,注册之前,一般会调用alloc_etherdev分配一个net_device,然后初始化它的重要成员。
ixgbe_probe
struct net_device *netdev;
struct pci_dev *pdev;
pci_enable_device_mem(pdev);
pci_request_mem_regions(pdev, ixgbe_driver_name);
pci_set_master(pdev);
pci_save_state(pdev);
netdev = alloc_etherdev_mq(sizeof(struct ixgbe_adapter), indices);// 这里分配struct net_device
alloc_etherdev_mqs
alloc_netdev_mqs(sizeof_priv, "eth%d", NET_NAME_UNKNOWN, ether_setup, txqs, rxqs);
ether_setup // Initial struct net_device
SET_NETDEV_DEV(netdev, &pdev->dev);
adapter = netdev_priv(netdev);
refs: https://blog.csdn.net/shallnet/article/details/25470775
alloc_etherdev_mqs() -> ether_setup()
void ether_setup(struct net_device *dev)
{
dev->header_ops = ð_header_ops;
dev->type = ARPHRD_ETHER;
dev->hard_header_len = ETH_HLEN;
dev->min_header_len = ETH_HLEN;
dev->mtu = ETH_DATA_LEN;
dev->addr_len = ETH_ALEN;
dev->tx_queue_len = 1000; /* Ethernet wants good queues */
dev->flags = IFF_BROADCAST|IFF_MULTICAST;
dev->priv_flags |= IFF_TX_SKB_SHARING;
eth_broadcast_addr(dev->broadcast);
}
EXPORT_SYMBOL(ether_setup);
static struct pci_driver ixgbe_driver = {
.name = ixgbe_driver_name,
.id_table = ixgbe_pci_tbl,
.probe = ixgbe_probe, // 系统探测到ixgbe网卡后调用ixgbe_probe()
.remove = ixgbe_remove,
#ifdef CONFIG_PM
.suspend = ixgbe_suspend,
.resume = ixgbe_resume,
#endif
.shutdown = ixgbe_shutdown,
.sriov_configure = ixgbe_pci_sriov_configure,
.err_handler = &ixgbe_err_handler
};
static int __init ixgbe_init_module(void)
{
...
ret = pci_register_driver(&ixgbe_driver); // 注册ixgbe_driver
...
}
module_init(ixgbe_init_module);
static void __exit ixgbe_exit_module(void)
{
...
pci_unregister_driver(&ixgbe_driver); // 注销ixgbe_driver
...
}
module_exit(ixgbe_exit_module);
2. Linux内核网络数据包处理流程 - 中断注册
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};
内核初始化期间,softirq_init会注册TASKLET_SOFTIRQ以及HI_SOFTIRQ相关联的处理函数。
void __init softirq_init(void)
{
......
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}
网络子系统分两种soft IRQ。NET_TX_SOFTIRQ和NET_RX_SOFTIRQ,分别处理发送数据包和接收数据包。这两个soft IRQ在net_dev_init函数(net/core/dev.c)中注册:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
收发数据包的软中断处理函数被注册为net_rx_action和net_tx_action。
其中open_softirq实现为:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
3. Linux内核网络数据包处理流程 - 重要结构体初始化
每个cpu都有队列来处理接收到的帧,都有其数据结构来处理入口和出口流量,因此,不同cpu之间没有必要使用上锁机制,。此队列数据结构为softnet_data(定义在include/linux/netdevice.h中):
/*
* Incoming packets are placed on per-cpu queues so that
* no locking is needed.
*/
struct softnet_data
{
struct Qdisc *output_queue;
struct sk_buff_headinput_pkt_queue;//有数据要传输的设备列表
struct list_headpoll_list; //双向链表,其中的设备有输入帧等着被处理。
struct sk_buff*completion_queue;//缓冲区列表,其中缓冲区已成功传输,可以释放掉
struct napi_structbacklog;
}
softnet_data 是在start_kernel 中创建的, 并且,每个cpu一个 softnet_data 变量, 这个变量中,最重要的是poll_list , 每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量softnet_data->poll_list上, 这样在软中断时,net_rx_action会遍历cpu私有变量的softnet_data->poll_list, 执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。
内核初始化流程:
start_kernel()
--> rest_init()
--> do_basic_setup()
--> do_initcall
-->net_dev_init
__init net_dev_init(){
//每个CPU都有一个CPU私有变量 _get_cpu_var(softnet_data)
//_get_cpu_var(softnet_data).poll_list很重要,软中断中需要遍历它的
for_each_possible_cpu(i) {
struct softnet_data *queue;
queue = &per_cpu(softnet_data, i);
skb_queue_head_init(&queue->input_pkt_queue);
queue->completion_queue = NULL;
INIT_LIST_HEAD(&queue->poll_list);
queue->backlog.poll = process_backlog;
queue->backlog.weight = weight_p;
}
//在软中断上挂网络发送handler
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
//在软中断上挂网络接收handler
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
}
4. Linux内核网络数据包处理流程 - 收发包过程图
ixgbe_adapter包含ixgbe_q_vector数组(一个ixgbe_q_vector对应一个中断),ixgbe_q_vector包含napi_struct:
硬中断函数把napi_struct加入CPU的poll_list,软中断函数net_rx_action()遍历poll_list,执行poll函数
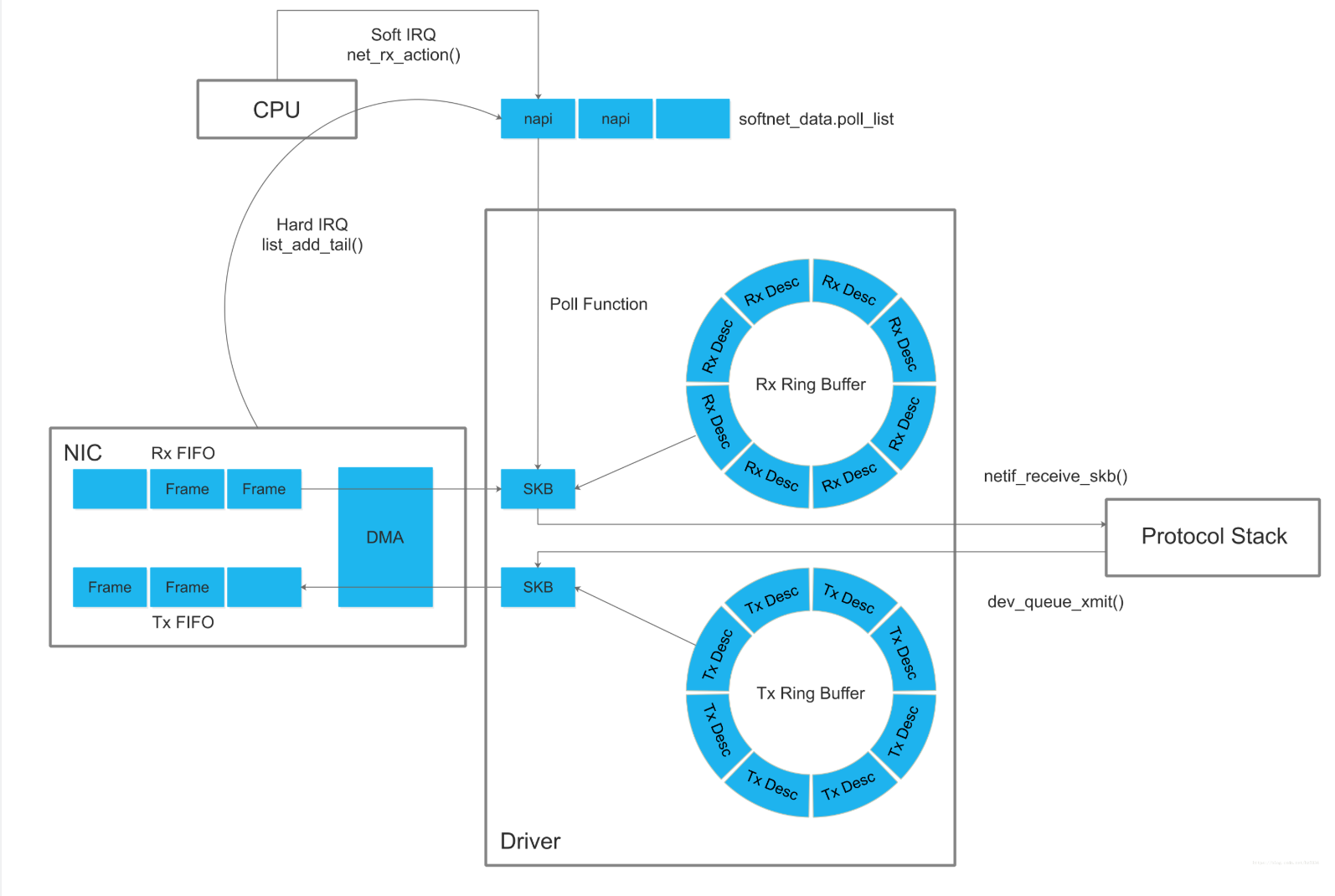
发包过程
1、网卡驱动创建tx descriptor ring(一致性DMA内存),将tx descriptor ring的总线地址写入网卡寄存器TDBA
2、协议栈通过dev_queue_xmit()将sk_buff下送网卡驱动
3、网卡驱动将sk_buff放入tx descriptor ring,更新TDT
4、DMA感知到TDT的改变后,找到tx descriptor ring中下一个将要使用的descriptor
5、DMA通过PCI总线将descriptor的数据缓存区复制到Tx FIFO
6、复制完后,通过MAC芯片将数据包发送出去
7、发送完后,网卡更新TDH,启动硬中断通知CPU释放数据缓存区中的数据包
收包过程
1、网卡驱动创建rx descriptor ring(一致性DMA内存),将rx descriptor ring的总线地址写入网卡寄存器RDBA
2、网卡驱动为每个descriptor分配sk_buff和数据缓存区,流式DMA映射数据缓存区,将数据缓存区的总线地址保存到descriptor
3、网卡接收数据包,将数据包写入Rx FIFO
4、DMA找到rx descriptor ring中下一个将要使用的descriptor
5、整个数据包写入Rx FIFO后,DMA通过PCI总线将Rx FIFO中的数据包复制到descriptor的数据缓存区
6、复制完后,网卡启动硬中断通知CPU数据缓存区中已经有新的数据包了,CPU执行硬中断函数:
-
NAPI(以e1000网卡为例):
e1000_intr() -> __napi_schedule() -> __raise_softirq_irqoff(NET_RX_SOFTIRQ) -
非NAPI(以dm9000网卡为例):
dm9000_interrupt() -> dm9000_rx() -> netif_rx() -> napi_schedule() -> __napi_schedule() -> __raise_softirq_irqoff(NET_RX_SOFTIRQ)
7、ksoftirqd执行软中断函数net_rx_action():
- NAPI(以e1000网卡为例):
net_rx_action() -> e1000_clean() -> e1000_clean_rx_irq() -> e1000_receive_skb() -> netif_receive_skb() - 非NAPI(以dm9000网卡为例):
net_rx_action() -> process_backlog() -> netif_receive_skb()
8、网卡驱动通过netif_receive_skb()将sk_buff上送协议栈
5. 中断上下部
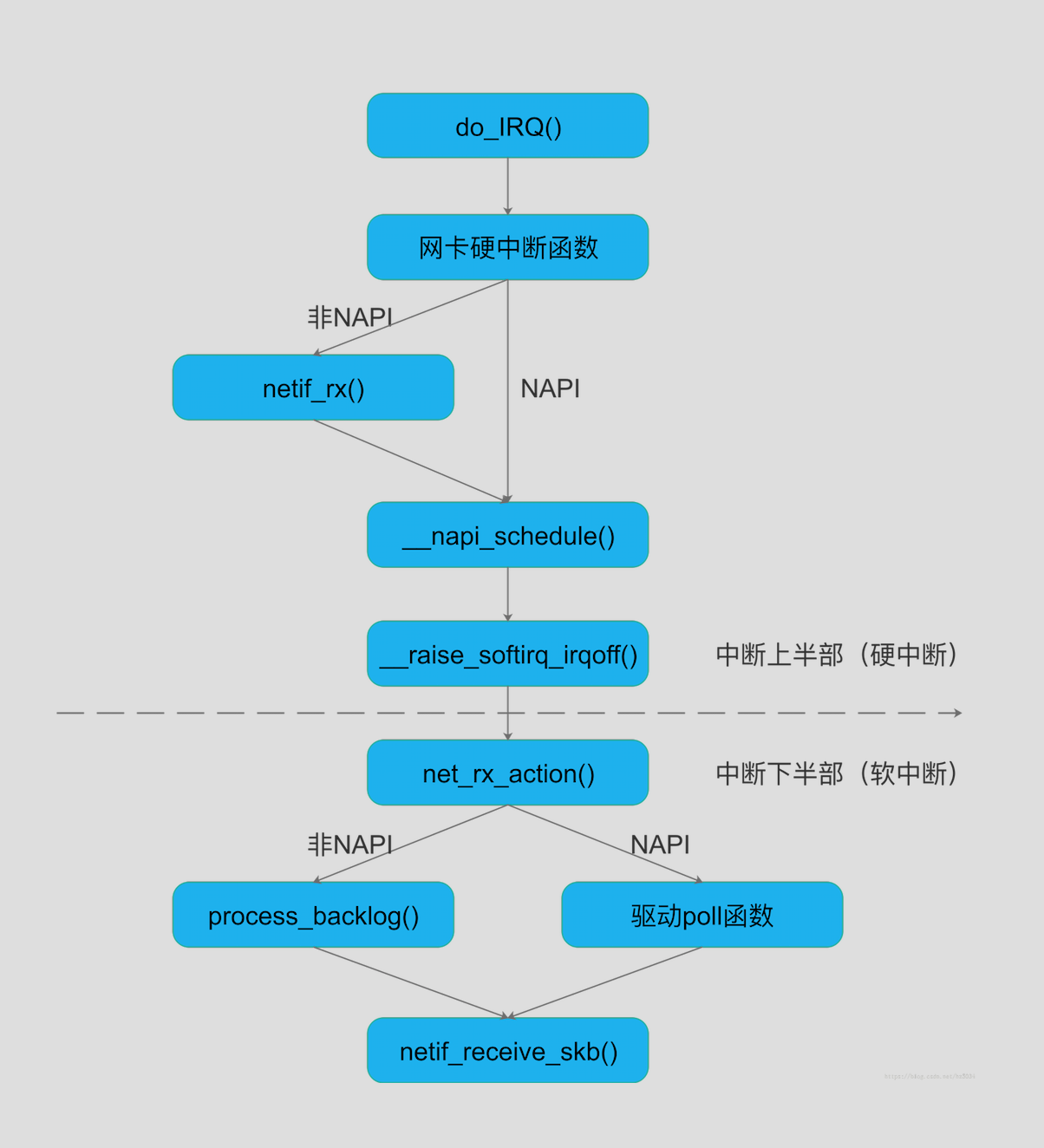
硬中断中的netif_rx()函数:把skb加入CPU的softnet_data-> input_pkt_queue队列
netif_rx(skb); // 在 硬中断中,处理skb
netif_rx_internal(skb);
trace_netif_rx(skb);
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow); // 通过rps,获得cpu id
enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
struct softnet_data *sd;
sd = &per_cpu(softnet_data, cpu); // 根据cpu id,获得sd
rps_lock(sd);
__skb_queue_tail(&sd->input_pkt_queue, skb); // enqueue 动作
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags)
return NET_RX_SUCCESS
rcu_read_unlock();
preempt_enable();
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable(); // 关闭抢占
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail); // 加入队列
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
enqueue_to_backlog()主要工作,就是将skb挂到一个cpu下的softnet_data-> input_pkt_queue队列里,
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu);
local_irq_save(flags);
rps_lock(sd);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb); // 将skb加入到sd-> input_pkt_queue队列
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog); // napi方式处理skb
}
goto enqueue;
}
drop:
sd->dropped++;
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
____napi_schedule
list_add_tail(&napi->poll_list, &sd->poll_list);
上述,就是硬中断需要做的工作,然后, 软中断net_rx_action()会遍历这个list,进行进一步操作。
中断处理上,处理skb,包含两种方式:
硬中断就是上半部,在上半部,有netif_rx 中对napi进行判断,在下半部的softirq (net_rx_action()) 中,同样对napi和非napi进行了判断 !
- 非NAPI
- 非NAPI设备驱动会为其所接收的每一个帧产生一个中断事件,在高流量负载下,会花掉大量时间处理中断事件,造成资源浪费。而NAPI驱动混合了中断事件和轮询,在高流量负载下其性能会比旧方法要好。
- NAPI
- NAPI主要思想是混合使用中断事件和轮询,而不是仅仅使用中断事件驱动模型。当收到新的帧时,关中断,再一次处理完所有入口队列。从内核观点来看,NAPI方法因为中断事件少了,减少了cpu负载。
默认是napi?还是非napi?
在初始化时,默认是非napi的模式,poll函数默认是: process_backlog ,如下:
net_dev_init
for_each_possible_cpu(i) {
sd->backlog.poll = process_backlog;
}
net_rx_action中将会调用设备的poll函数, 如果没有, 就是默认的process_backlog函数
process_backlog函数里面将skb出队列之后, netif_receive_skb处理此skb
软中断中,使用net_rx_action(),处理skb:
7、ksoftirqd执行软中断函数`net_rx_action()`:
* NAPI(以e1000网卡为例):`net_rx_action() -> e1000_clean() -> e1000_clean_rx_irq() -> e1000_receive_skb() -> netif_receive_skb()`
* 非NAPI(以dm9000网卡为例):`net_rx_action() -> process_backlog() -> netif_receive_skb()`
8、网卡驱动通过`netif_receive_skb()`将`sk_buff`上送协议栈
最后,通过netif_receive_skb(), 将skb送上协议栈;
软中断中,对napi和非napi的处理: process_backlog
net_rx_action
process_backlog
__netif_receive_skb
__netif_receive_skb_core
非NAPI vs NAPI
- (1) 支持NAPI的网卡驱动必须提供轮询方法
poll()。 - (2) 非NAPI的内核接口为
netif_rx(),
NAPI的内核接口为napi_schedule()。 - (3) 非NAPI使用共享的CPU队列
softnet_data->input_pkt_queue,
NAPI使用设备内存(或者设备驱动程序的接收环)。

6. 参考:
- 网卡驱动收发包过程图解: https://blog.csdn.net/jiangganwu/article/details/83037139
- 收包软中断和netif_rx (linux网络子系统学习 第四节 )
: https://blog.51cto.com/yaoyang/1263842 - ixgbe 网卡初始化及收发数据概览: https://blog.csdn.net/weixin_34026276/article/details/87273481

 浙公网安备 33010602011771号
浙公网安备 33010602011771号