

odoo揭露不为人知的env
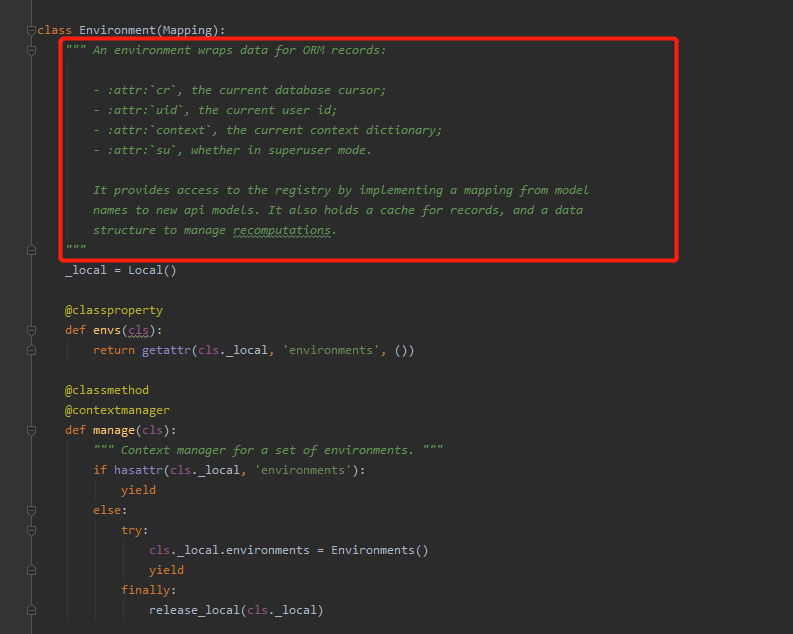
背景:env是odoo里最常用的工具类之一,类名全称environment,
里面提供了ORM对象的封装,我们最常用的就是执行SQL和利用ORM操作模型以及使用模型中的方法。
ORM是一个完整关系对象映射层,开发人员不用编写基础的SQL语句。
在运行代码之前先建立环境,函数的执行是在环境中进行的,env就是当前的环境,在环境中执行函数,环境中的方法自然也是能够直接使用的。
工具类包括常常使用的cr:当前数据库游标;
在使用原始的数据库层面操作时,执行SQL语句,取到查询的返回数据,提交事务,等等操作都离不开 self.env.cr 创建的游标对象,
self.env.cr.execute(SQL)执行sql语句,self.env.cr.commit()提交事务。相关操作是开发人员常用的操作。
uid:当前用户id;self.env.uid查询当前用户的id,
我们在后台同样是利用用户的id,判断该用户是否有访问某某页面,创建某某问题的权限的。
context前后文字典;self.context.get('key'),
上下文数据的传输在同一个页面上使用不多,在跳转页面,页面与页面的联动时,效果显著,
比如从页面A编辑进入页面B,从页面B查看进入页面C,以简单的三层页面嵌套来讲,从页面C返回页面B时仍然是从A进入B的编辑样式,
这一点从页面C返回到页面B是不知道的,所以就需要我们使用页面的上下文来记录页面的状态,更多更复杂的页面结构,都缺少不了这种状态的记录。
同样还有最简单的字段显示,重写了name_get方法的字段,如果没有上下文字典无法显示完成的字段信息。
su设置超级管理员权限执行;self(su=True)['res.users'].search(),在一些重要信息的执行时,我们可以使用超级管理员权限执行,放到最高优先级。
除了上述最常用的功能之外,env几乎包揽了所有有可能需要的功能
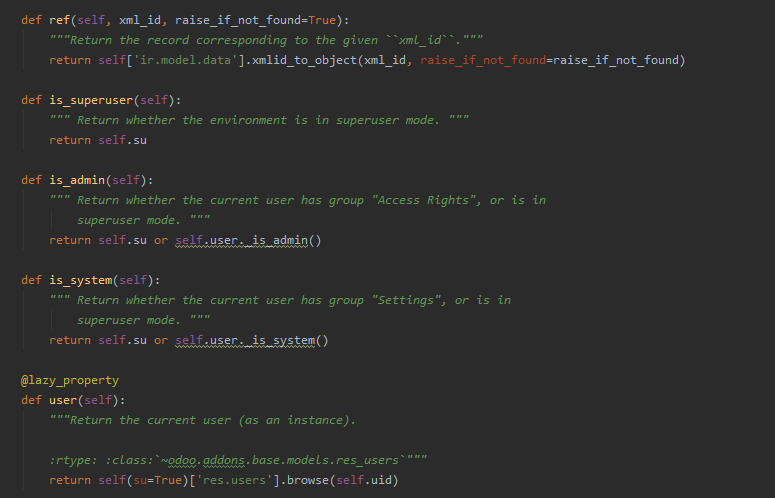
ref:查询视图在数据库中的id,
方便跳转视图的时候时候,self.env.ref('模型下的视图id').id,查询视图id,可以直接跳转,
也可以使用重定向调到指定id的视图,也可以使用url跳转,把到指定视图的id拼到url中。
我们使用odoo系统每次页面跳转的时候,url里拼接的参数就是这次跳转行为的终点,
使用ref方法能查询到视图的id和动作的id,从这一方面来讲,没有页面是拼接不了的
self.env.is_superuser() 查询是否有处于超级管理员模式;返回布尔类型。权限查询涉及的方面多是权限操作,特别是等级分明的业务场景上例如银行,权限的要求更加严格。
self.env.is_admin() 查询是否在‘access rights’组中,返回布尔类型。
self.env.is_system() 查询是否在‘setting’组中,返回布尔类型,权限类型依次降低。
self.user获取当前用户的作为一个对象,该对象的属性都可以按需要取到。
用户id有什么用?查询到当前登录人信息,一般在类似创建表单的业务场景下常常使用到,带出申请人的姓名,itcode,部门等信息。
或者是在系统需要管理个人信息时,用户信息可以呈现在系统的每一处,登录信息,浏览记录,创建记录,操作记录,严格到点击记录都能跟踪到。
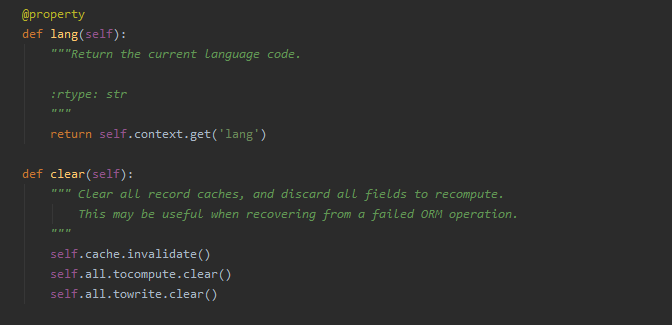
除此之外,查询语言类型self.env.lang(),查询语言的方法封装的是self中默认的上下文语言信息。
清除缓存,self.env.clear(),在一次失败的ORM中恢复操作可以使用。
如果执行了错误的操作,并且上次操作中修改过的属性会影响到后续操作的进行,
这个时候就有必要清除缓存,在一个无干扰的环境下执行操作
self.env.in_draft查看是不是草稿状态,
self.env.in_onchange查看是不是处于onchange状态
self.env[模型名],我们在开发中最常用的方法,从env中注册的模型,从而使用该模型中的方法。
模型中默认的查询 创建 更新 删除方法,以及自定义的方法函数都能使用。
在管理重计算的数据结构方面,env中提供了很多种方法。
self.env.clear_upon_failure()清除环境上下文管理器(字段缓存再计算)
is_protected,返回记录是否了保护字段;字段被保护之后不能重新计算,
对于需要onchange的关联字段如果不能出发计算,要考虑到是不是因为字段被保护了
protected,保护字段不能失效或重新计算,
protecting, 防止记录上的字段失效或者重新计算。
fields_to_compute() 返回要计算的字段的视图;
records_to_compute() 返回要计算字段的记录表;
is_to_compute() 返回是否必须在记录中计算的字段
not_to_compute() 返回记录的子集,其中字段不能被计算
add_to_compute() 标记字段要在记录上计算
remove_to_compute() 返回是否必须在记录中计算的字段

ps:上下文信息可以被替换self.with_context(),完整替换当前运行环境with_env()
当有多个任务同时进行时,各个任务分配相同的环境,基础设置相同的前提下,又相互隔离相互独立。
----------------已在公司公众号推送----------------


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下