

数据分析之爬取数据
数据分析怎么分析呢
首先要获取数据
然后对目标数据进行分析,以不同的角
获取数据然后根据数据进行分析汇总
1,获取数据,
获取数据的方法很多,爬虫的实现方式也有很多,单个脚本使用requests很方便,也是我最常用的实现爬虫的方式。
不过今天使用的工具是scrapy,爬虫框架,也算是学习使用。
安装scrapy包 : pip install scrapy
打开控制台,创建一个项目 scrapy startproject 项目名称
打开就会发现整整齐齐的项目框架已经搭建完成
下面进入到spiders文件下面,创建一只小蜘蛛,它将为你工作
scrapy genspider 爬虫名 网址/api域名
然后就能看到你的刚出生的小蜘蛛了。
在公共网络中爬取数据,一般网页渲染要么是服务器渲染,要么是客户端渲染。
服务器渲染形式,右键查看网页源码,所有网页的数据都能找到,通过正则或者xpath匹配出想要的内容即可。
客户端渲染,想要的数据在某个api直接返回了,不用解析网页。
上述例子中爬取的是B站上的作品数据,客户端渲染,找到api即可拿到数据。
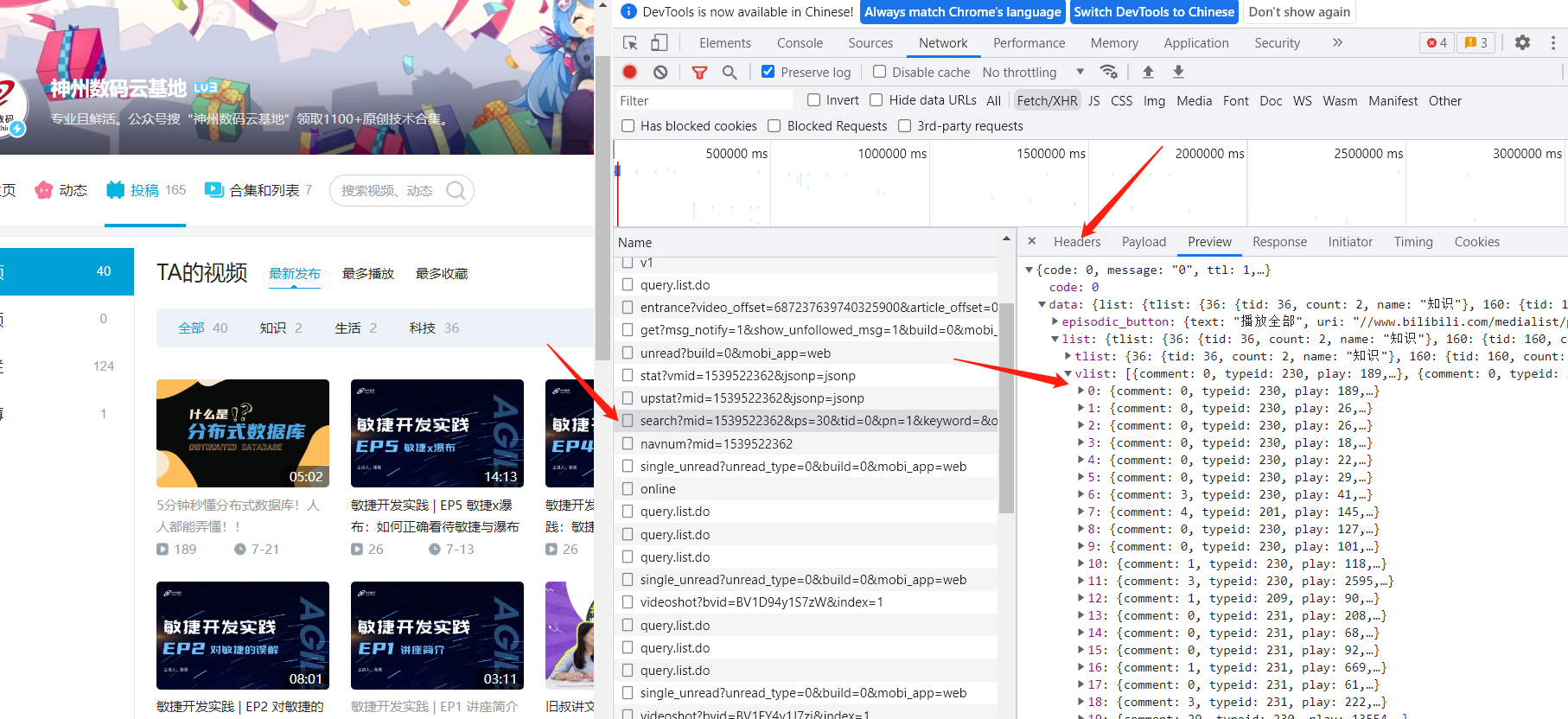
找到想要的数据,解析一下保存起来。

import scrapy import csv class XiaobaiSpider(scrapy.Spider): name = 'xiaobai' allowed_domains = ['api.bilibili.com'] start_urls = ['https://api.bilibili.com/x/space/arc/search?mid=1539522362&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'] def parse(self, response, **kwargs): resp = response.json()['data']['list']['vlist'] for i in resp: arg = { 'name': i['title'], 'time': i['length'], 'view': i['play'], } with open('dataspider.csv', 'a') as f: csv.writer(f).writerow(arg.values()) page = response.json()['data']['page'] count = page['count'] ps = page['ps'] pn = page['pn'] if pn * ps < count: pn += 1 next_page = '/x/space/arc/search?mid=1539522362&ps=30&tid=0&pn=%d&keyword=&order=pubdate&jsonp=jsonp' % pn next_url = response.urljoin(next_page) yield scrapy.Request(next_url, callback=self.parse)
下面就是让你的小蜘蛛出去觅食!
数据保存在csv文件中 scrapy crawl 爬虫名
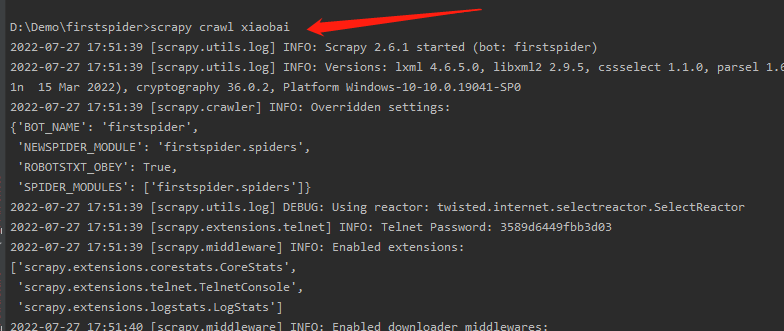
执行之后得到我们想要的数据
拿到数据之后,无论是从excel上用柱状图表示,或者是使用pyecharts进行数据可视化,分析数据的特点。
由于涉及部分隐私,只分享爬虫框架scrapy的简单使用方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下