微服务存储实现1之冷热分离
数据库作冷备
数据库分区:
1)比起单个文件系统或硬盘,分区可以存储更多的数据。
2)在清理数据时,可以直接删除废弃数据所在的分区。同样,有新数据时,可以增加更多的分区来存储新数据。
3)可以大幅度地优化特定的查询,让这些查询语句只去扫描特定分区的数据。
MySQL的分区要求分区字段必须是唯一索引(主键也是唯一索引)的一部分。
什么是冷热分离:
冷热分离就是在处理数据时将数据库分成冷库和热库,冷库存放那些走到终态、不常使用的数据,热库存放还需要修改、经常使用的数据。
什么情况下需要使用冷热分离?
数据走到终态后只有读没有写的需求
用户能够接受新旧数据分开查询,比如有些电商网站默认只让查询3个月内的订单数据,如果查询三个月之前的,需要访问其它的页面。当然,后端可以根据时间进行适配
冷热分离操作过程中需要考虑的问题:
1)如何判断一个数据是冷数据还是热数据?
一般而言,采用主表里一个字段或多个字段的组合作为区分标识。比如时间,状态。当被判定为冷数据后,业务代码不会对其进行写操作。
2)如何触发冷热数据分离?
触发冷热分离的逻辑一般分为三种:
1 直接修改业务代码,使得每次修改数据时触发冷热分离,比如每次更改订单的状态,就去触发。
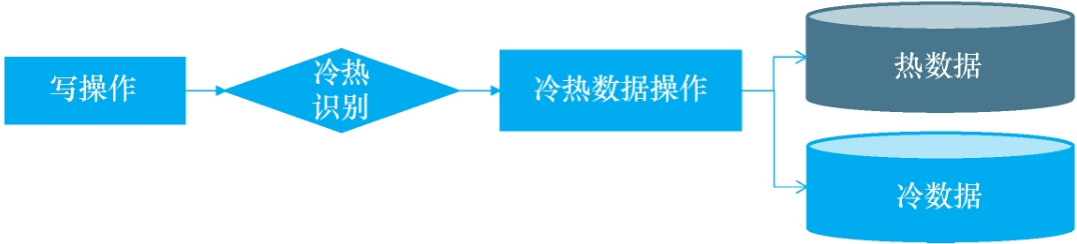
2如果不想修改原来的业务代码,可以通过监听数据库变更日志binlog的方式来触发。具体就是需要创建一个专门用来监控数据库binlog的服务,一旦发现表有变动,就将变动的数据记录发送到一个队列,这个队列的订阅者将会取出变动的数据,触发冷热分离逻辑。

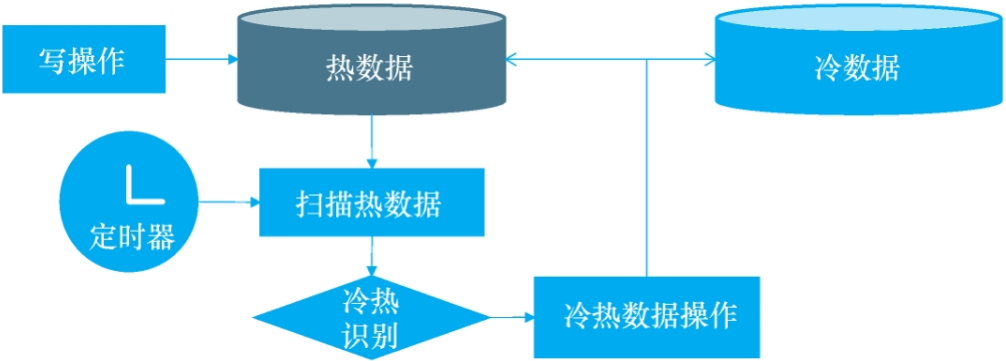
3 通过定时扫描数据库的方式,具体做法是通过quartz配置一个本地定时任务,或者类似xx-job的分布式调度平台配置一个定时任务,每间隔一段时间扫描热库里面的数据,找出符合冷数据标准的工单,进行冷热分离。
以上三种实现方案到底哪个比较好,下面给出了对比,以及适用的场景:
| 优点 | 缺点 | 使用场景 | |
| 修改写操作的业务代码 |
代码灵活
保证实时性 |
无法按照时间区分冷热,因此缓存的数据随着时间的推移变为冷数据时无法进行任何操作
需要修改所有数据库写操作的业务代码 |
业务比较简单,并且不按照时间区分冷热数据时使用 |
| 监听数据库变更日志 |
与业务代码解耦
可以做到低延时 |
无法按照时间区分冷热,因此缓存的数据随着时间的推移变为冷数据时无法进行任何操作
需要考虑数据并发操作的问题,即业务代码与冷热变更代码同时操作同一数据 |
业务代码比较复杂,不能随意变更,并且不按照时间区分冷热数据时使用 |
| 定时扫描数据库 |
与业务代码解耦 可以覆盖根据时间区分冷热数据的场景 |
不能做到实时性 | 建议在按照时间区分冷热数据时使用 |
3)如何实现冷热数据分离?
分离冷热数据一般分为三步:判断数据冷热、将要分离的数据插入冷数据库中、从热数据库中删除分离的数据。

虽然只有三个步骤,但是需要考虑同时修改多个数据库,那么如何保证数据的一致性?比如步骤2插入冷库失败,那么需要保证这些数据最终会被移到冷库。步骤3失败,最终这些数据还是会从热库中删除。这里的一致性实际是实现的最终一致性。此外,还要考虑到每一步的重试以及操作的幂等。这里我们介绍一种常见的实现方案,该方案主要分为四步:
1 在热库中给需要迁移的数据加上标识,coldFlag = WaittingForMove,以便将冷热数据标识的计算结果进行持久化。
2 利用标识找出所有带迁移的数据,这一步主要是确保之前的线程运行失败,导致有些数据没有完成迁移,通过这一步可以找到遗漏的需要迁移的数据。
3 在冷库中保存一份数据,这里需要考虑幂等性,以防止从热库删除数据时失败了,又被重复插入。
4 从热库中删除对应的数据
除了考虑数据一致性的问题,还需要考虑数据量的问题。比如数据一次处理不完,是否需要使用批量处理?又比如大到需要多线程并发时,尤其是对于之前的存量数据,第一次进行冷热分离时。
针对于批量处理其实就是从热库中根据标识找到待迁移的数据,然后分批执行后续几个步骤。但是多线程并发时,需要考虑多线程同时操作数据的问题,那么需要引入锁的概念。
4)如何使用冷热数据?
在功能设计时,一般会有一个选项选择需要查询冷数据还是热数据,当然也可以在代码中区分。不过,在决定判断是冷数据还是热数据时,需要确保用户没有同时读取冷热数据的需求。
5) 历史数据如何迁移?
通常,只要与持久化有关的架构,都需要考虑历史数据的迁移问题,即如何让旧架构的数据适用于新架构。前面我们已经提到,将热库中需要迁移的数据增加一个标识,当时是为了考虑失败重试时,
方便后面的任务把之前失败的数据完成迁移。因此针对于旧的历史数据,只需要给冷数据条件的历史数据增加该标识,后面程序会自动完成迁移。
整体架构如下图所示:

HBase作冷备
用数据库作为冷库的持久化层,如果数据量非常大,那么可能查询会非常慢,而且可能报告警。下面介绍一种更大容量的持久化存储中间件HBase
HBase的Table、Row、Column、ColumnFamily、ColumnQualifier概念介绍:
Table、Row与关系型数据库的表、行的含义一样;ColumnFamily相当于关系型数据库里面几个列的组合,属于schema的范畴。ColumnQualifier相当于某个具体的列。针对于数据库的一行记录,在HBase中可能就是分为了几个ColumnFamily,并且在物理上分开存储,这种存储结果也被称作为“列簇存储”,这也是HBase的一张表可以存放上百亿条数据的原因,毕竟存储的每条数据是数据库表一行数据的一个或者几个列而已。因此HBase在字段关联方面效果不是很好,实现不了复杂的查询,效率不是特别高。
HBase的物理存储模型:
在HBase中,数据以表的形式存储,表由很多行组成,每一行由Row key(行键)以及一个或多个的列值组成。当表有很多很多的Row时,把这个表按某些规则(比如每500条)拆分成很多部分,那么拆分后的每一部分就是所谓的HRegion,这个HRegion作为一个整体被HMaster分配到某一个RegionServer中。我们可以把HMaster想象成一个老大,他把HRegion给分配到某一个服务器上
这样一来,一个表就被分成多个HRegion并可能分配到了不同的RegionServer上。
存储关系:
一个HBase的表北水平分割成多个Region.
一个Region会包含多个Row, 拥有startkey和endkey之间所有连续的行,每个region的大小默认控制在1GB内。
一个Region会包含多个MemStore
一个MemStore会存储一个ColumnFamily
一个MemStore会把数据写入多个HFile
一个RegionServer会服务多个Region
每个RegionServer负责下面的Region的读写操作。
HBase的写操作如下:
1 客户端访问zookeeper,读取元数据。
2 根据namespace、表名、RowKey找到对应的region。
3 访问Region对应的RegionServer。
4 写入WAL(WriteAheadLog, 也叫HLog).每一个RegionServer都会维护一个WAL文件(基于Hadoop分布式文件系统HDFS) 所有的写操作先会把变动加到WAL文件末尾。
WAL会保存所有未持久化的新数据,以便用来进行数据恢复。
5 写入MemStore, MemStore相当于一个写缓存(当缓存大小达到阙值时会被持久化到HFile中),每个Region的每个列簇都有一个MemStore.数据在写入磁盘或持久化之前
,先保存到MemStore。
6 通知客户端写入完成。
HBase的读操作:
1 客户端访问zookeeper,读取元数据
2 根据namespace、表名、RowKey找到对应的region
3 访问Region对应的RegionServer
4 查找对应的Region
5 查询MemStore
6 找到BlockCache, 每个RegionServer都有BlockCache,相当于一个读缓存,扫描器会先查询BlockCache
7 如果上面都没有找到,则会到多个HFile中去查找

 浙公网安备 33010602011771号
浙公网安备 33010602011771号