(六) 分库分表与集群
分库分表
一、为什么要分库分表
关系型数据库以MySQL为例,单机的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。当单表数据量在百万以里时,我们还可以通过添加从库、优化索引提升性能。一旦数据量朝着千万以上趋势增长,再怎么优化数据库,很多操作性能仍下降严重。为了减少数据库的负担,提升数据库响应速度,缩短查询时间,这时候就需要进行分库分表。
二、如何分库分表
分库分表就是要将大量数据分散到多个数据库中,使每个数据库中数据量小响应速度快,以此来提升数据库整体性能。核心理念就是对数据进行切分( Sharding ),以及切分后如何对数据的快速定位与整合。针对数据切分类型,大致可以分为:垂直(纵向)切分和水平(横向)切分两种。
1、垂直切分
垂直切分又细分为"垂直分库" 和 "垂直分表"
垂直分库:垂直分库是基于业务分类的,和我们常听到的微服务治理观念很相似,每一个独立的服务都拥有自己的数据库,需要不同业务的数据需接口调用。而垂直分库也是按照业务分类进行划分,每个业务有独立数据库,这个比较好理解。
垂直分表:是基于数据表的列为依据切分的,是一种大表拆小表的模式. 数据库是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段长度也都较短,可以加载更多数据到内存中,增加查询的命中率,减少磁盘IO,以此来提升数据库性能。
垂直切分优点:
1 业务间解耦,不同业务的数据进行独立的维护、监控、扩展
2 在高并发场景下,一定程度上缓解了数据库的压力
垂直切分缺点:
1 提升了开发的复杂度,由于业务的隔离性,很多表无法直接访问,必须通过接口方式聚合数据,
2 分布式事务管理难度增加
3 数据库还是存在单表数据量过大的问题,并未根本上解决,需要配合水平切分
2、水平切分
垂直切分还是会存在单表数据量过大的问题,当我们的应用已经无法在细粒度的垂直切分时,依旧存在单库读写、存储性能瓶颈,这时就要配合水平切分一起了。
水平切分将一张大数据量的表,切分成多个表结构相同,而每个表只占原表一部分数据,然后按不同的条件分散到多个数据库中. 水平切分又分:"库内分表" 和 "分库分表"
库内分表: 虽然将表拆分,但子表都还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分布到不同机器的库上,还在竞争同一个物理机的CPU、内存、网络IO. 这种对高并发下的场景不太友好,因为数据库连接有限制,还要去竞争同一个物理机的CPU、内存、网络IO.
分库分表
分库分表则是将切分出来的子表,分散到不同的数据库中,从而使得单个表的数据量变小,达到分布式的效果。
优点:
1 解决高并发时单库数据量过大的问题,提升系统稳定性和负载能力
2 业务系统改造的工作量不是很大
缺点:
1 跨分片的事务一致性难以保证
2 跨库的join关联查询性能较差
3 扩容的难度和维护量较大。
应用场景考虑:
1 只分库不分表:当数据库的读写访问量过高,甚至数据库连接不够用的情况下,就需要考虑分库。通过增加数据库实例的方式获得更多的数据库连接,从而提升系统的并发性能。
2 只分表不分库:当单表的存储量非常大,并且并发量不高,数据库连接还够用,但是数据的写入和查询性能出现了瓶颈,这个时候可以考虑分表,以提升单表的读写效率。
3 数据库连接不够用,并且单表的数据量也很大,从而导致数据库读写速度变慢的情况下。
三、数据该往哪个库的表存?
1 按照"时间区间" 或 "ID区间"来切分,举个栗子:假如我们切分的是用户表,可以定义每个库的 User表里只存10000条数据,第一个库userId从1 ~ 9999,第二个库10000 ~ 20000,第三个库20001~ 30000......以此类推。
优点:
单表数据量是可控的
水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移
能快速定位要查询的数据在哪个库
缺点:
由于连续分片可能存在数据热点,如果按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
2、hash取模
hash取模mod(对hash结果取余数 (hash() mod N))的切分方式比较常见,还拿 User表 举例,对数据库从0到N-1进行编号,对 User表 中 userId 字段进行取模,得到余数 i , i=0 存第一个库, i=1 存第二个库, i=2 存第三个库....以此类推。
这样同一个用户的数据都会存在同一个库里,用 userId 作为条件查询就很好定位了。
优点:
数据分片相对比较均匀,不易出现某个库并发访问的问题。
缺点:
但这种算法存在一些问题,当某一台机器宕机,本应该落在该数据库的请求就无法得到正确的处。理,这时宕掉的实例会被踢出集群,此时算法变成hash(userId) mod N-1,用户信息可能就不再在同一个库中。
集群
1、主从复制原理
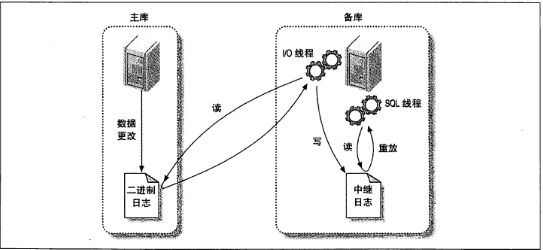
MySQL的复制是通过binlog功能实现的,具体分为3个线程。
- 主节点:dump 线程,负责采集 binlog 数据与同步库 IO 线程交互。
- 从节点:IO 线程将获取到的数据转储成 relaylog 文件(relaylog内部存储的内容与binlog一致)
- 从节点:slave 线程将 relaylog 的数据读取出来,然后写入到数据库中。
2 bin log日志和replay日志
bin log:记录所有数据得更改,可用于本机数据恢复与主从同步
relay log中继日志:
1 Mysql主节点将binlog写入本地,从节点定时请求增量binlog, 主节点将binlog同步到从节点;
2 从节点单独进程会将binlog拷贝至本地relaylog中
3 从节点定时重放relay log
1) bin log 的三种模式:
1.statement level模式
每一条会修改数据的sql都会记录到master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行
优点:statement level下的优点,首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约io,提高性能。因为他只需要记录在master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于它是记录的执行语句,所以为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端被执行的时候能够得到和在master端执行时候相同的结果。还有修改数据的时候使用了某些特定的函数或者功能,复制时比较困难。
2.row level模式
日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
优点:bin log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以row level的日志的内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function, 以及trigger的调用和触发无法被正确复制的问题。
缺点:row level下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改记录,这样可能会产生大量的日志内容,比如有这样一条update语句:update product set owner_member_id='d' where owner_member_id='a',执行之后,日志中记录的不是这条update语句所对应的事件(mysql是以事件的形式来记录bin-log日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多事件。自然,bin-log日志的量会很大
3.mixed模式
实际上就是前两种模式的结合,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete 等修改数据的语句,那么还是会记录所有行的变更
主从同步延迟的原因及解决办法
mysql 用主从同步的方法进行读写分离,减轻主服务器的压力的做法现在在业内做的非常普遍。一个服务器开放N个链接给客户端来连接的, 这样有会有大并发的更新操作, 但是从服务器的里面读取binlog 的线程仅有一个, 当某个SQL在从服务器上执行的时间稍长 或者由于某个SQL要进行锁表就会导致,主服务器的SQL大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
2、主从同步延迟的解决办法
实际上主从同步延迟根本没有什么一招制敌的办法, 因为所有的SQL必须都要在从服务器里面执行一遍,但是主服务器如果不断的有更新操作源源不断的写入, 那么一旦有延迟产生, 那么延迟加重的可能性就会原来越大。
当然我们可以做一些缓解的措施。
a. 我们知道因为主服务器要负责更新操作, 他对安全性的要求比从服务器高, 所有有些设置可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog,innodb_flush_log_at_trx_commit 也可以设置为0来提高sql的执行效率 这个能很大程度上提高效率。另外就是使用比主库更好的硬件设备作为slave。
b.一台从服务器当度作为备份使用, 而不提供查询, 那边他的负载下来了, 执行relay log里面的SQL效率自然就高了。
c. 增加从服务器喽,这个目的还是分散读的压力, 从而降低服务器负载。
注:
[innodb_flush_log_at_trx_commit]参数是commit操作时写redolog的行为:
* 当属性值为0时,事务提交时,不会对重做日志进行写入操作,而是等待主线程按时写入每秒写入一次;
* 当属性值为1时,事务提交时,会将重做日志写入文件系统缓存,并且调用文件系统的fsync,将文件系统缓冲中的数据真正写入磁盘存储,确保不会出现数据丢失;(默认值)
* 当属性值为2时,事务提交时,也会将日志文件写入文件系统缓存,但是不会调用fsync,而是让文件系统自己去判断何时将缓存写入磁盘。
当然事务在最终commit的时候binlog是否马上写入到磁盘中是由参数 sync_binlog 配置来决定的。
1、sync_binlog=0 的时候,表示每次提交事务binlog不会马上写入到磁盘,而是先写到page cache,相对于磁盘写入来说写page cache要快得多,不过在Mysql 崩溃的时候会有丢失日志的风险。
2、sync_binlog=1 的时候,表示每次提交事务都会执行 fsync 写入到磁盘 ;
3、sync_binlog的值大于1 的时候,表示每次提交事务都先写到page cach,只有等到积累了N个事务之后才fsync 写入到磁盘,同样在此设置下Mysql 崩溃的时候会有丢失N个事务日志的风险。
很显然三种模式下,sync_binlog=1 是强一致的选择,选择0或者N的情况下在极端情况下就会有丢失日志的风险,具体选择什么模式还是得看系统对于一致性的要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号