mybatis-基础知识
Mybatis是什么?
MyBatis 是一款半ORM的持久层框架。其内部封装了JDBC,开发时只需关注sql本身,而无需花费精力处理驱动加载、创建连接、创建statement,释放连接等繁杂的过程。避免了几乎所有的 JDBC代码和手动设置参数以及获取结果集,通过使用简单的XML或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
通过xml文件或注解的方式将要执行的各种statement配置起来,并通过java对象和statement中sql的动态参数进行映射从而生成最终执行的sql,最后由mybatis框架执行sql并将结果映射为java对象返回。
Mybatis的优点与缺点:
优点:
1 基于SQL语句编程,不会对应用程序或者数据库的现有设计造成影响。简单来说就是mapper接口与对应的mapper.xml文件。sql写在xml里,解除sql与程序代码的耦合,便于统一管理; 提供了xml标签,支持编写动态sql,并可重用。
2 与jdbc相比,消除了jdbc手动创建和释放连接等冗余代码,减少了代码量
3 因为mybatis封装了jdbc,并使用其连接数据库,所以只要jdbc能够连接的数据库,mybatis都支持,因此既有很好的数据库兼容。
4 能够很好的与spring集成
5 提供映射标签,支持对象与数据库的ORM字段关系映射。
缺点:
sql编写起来工作量大,尤其字段多,关联表多时sql的编写更加困难。
虽然可以支持多种数据库,但是数据库移植时,sql语句对数据库的依赖性的弊端就暴露了。
ORM是什么
对象-关系映射(OBJECT/RELATIONALMAPPING,简称ORM),是随着面向对象的软件开发方法发展而产生的。实现了业务型数据和数据库中关系型数据的相互转化。这样开发人员在具体的操作实体对象的时候,不需要再去和复杂的 SQL 语句打交道,只需专注于操作实体对象的属性和方法。
ORM框架与Mybatis的区别:
| 对比项 | Mybatis | Hibernate |
| 适合的行业 | 互联网、电商 | 传统的ERP CRM OA |
| 性能 | 高 | 低 |
| sql灵活性 | 高 | 低 |
| sql配置文件 | 全局配置文件,映射文件 | 全局配置文件,映射文件 |
| ORM | 半自动化 | 完全自动化 |
| 数据库无关性 | 低 | 高 |
Mybatis Mapper代理开发方式:
此处使用的是JDK的动态代理方式,延迟加载使用的cglib动态代理方式。
XML方式:只需要开发Mapper接口(dao接口)和Mapper映射文件,不需要编写实现类。
开发规范
Mapper接口开发方式需要遵循以下规范:
1、 Mapper接口的类路径与Mapper.xml文件中的namespace相同。
2、 Mapper接口方法名称和Mapper.xml中定义的每个statement的id相同。
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相
同。
4、 Mapper接口方法的返回值类型和mapper.xml中定义的每个sql的resultType的类型相同。
Mybatis全局配置文件
- properties标签:properties标签除了可以使用resource属性,引用properties文件中的属性。还可以在properties标签内定义property子标签来定义属性和属性值。需要注意的是:MyBatis 先读取properties 元素体内定义的属性。之后读取properties 元素中resource或 url 加载的属性,它会覆盖已读取的同名属性。
- typeAlias标签:别名的作用:就是为了简化映射文件中parameterType和ResultType中的POJO类型名称编写。批量别名定义时,扫描整个包下的类,别名为类名(首字母大写或小写都可以)
- mapper标签:1 <mapper resource=""/> 使用相对于类路径的资源,如:<mapper resource="sqlmap/User.xml" /> 2<mapper url=""> 使用绝对路径加载资源,如:<mapper url="file://d:/sqlmap/User.xml" 3 <mapper class=""/> 使用mapper接口类路径,加载映射文件。如:<mapper class="com.kkb.mybatis.mapper.UserMapper"/> 注意:此种方法要求mapper接口名称和mapper映射文件名称相同,且放在同一个目录中 4 <package name=""/>注册指定包下的所有mapper接口,来加载映射文件。如:<package name="com.kkb.mybatis.mapper"/> 注意:此种方法要求mapper接口文件名称和mapper映射文件名称相同,且放在同一个目录中。
输入输出映射
输入映射:parameterType属性可以映射的输入参数Java类型有:简单类型、POJO类型、Map类型、List类型(数组)。
输出映射:resultType属性可以映射的java类型有:简单类型、POJO类型、Map类型。使用resultType进行输出映射时,要求sql语句中查询的列名和要映射的pojo的属性名一致。如果sql查询列名和pojo的属性名可以不一致,通过resultMap将列名和属性名作一个对应关系,最终将查询结果映射到指定的pojo对象中。
查询
一对一查询:
association:表示进行一对一关联查询映射
property="xxxx"**表示关联查询的结果存储在目标对象的哪个属性中
javaType:表示关联查询的映射结果类型
比如订单关联用户查询信息,对于用户来说,是一对一查询。
一对多查询:
Collection标签:定义了一对多关联的结果映射。
property="xxxx":关联查询的结果集存储在目标对象的上哪个属性。
ofType="xxx"**:指定关联查询的结果集中的对象类型。此处可以使用别名,也可以使用全限定名。
Mybatis延迟加载
什么是延迟加载:
- MYyBatis中的延迟加载,也称为懒加载,是指在进行关联查询时,按照设置延迟规则推迟对关联对象的select查询。延迟加载可以有效的减少数据库压力。
- Mybatis的延迟加载,需要通过resultMap标签中的association和collection子标签才能演示成功。
- Mybatis的延迟加载,也被称为是嵌套查询,对应的还有嵌套结果的概念,可以参考一对多关联的案例。
- MyBatis的延迟加载只是对关联对象的查询有延迟设置,对于主加载对象都是直接执行查询语句的
延迟加载的分类:
MyBatis根据对关联对象查询的select语句的执行时机,分为三种类型:直接加载、侵入式加载与深度延迟加载
- 直接加载: 执行完对主加载对象的select语句,马上执行对关联对象的select查询。
- 侵入式延迟:执行对主加载对象的查询时,不会执行对关联对象的查询。但当要访问主加载对象的某个属性(该属性不是关联对象的属性)时,就会马上执行关联对象的select查询。
- 深度延迟:执行对主加载对象的查询时,不会执行对关联对象的查询。访问主加载对象的详情时也不会执行关联对象的select查询。只有当真正访问关联对象的详情时,才会执行对关联对象的select查询。
延迟加载策略需要在Mybatis的全局配置文件中,通过标签进行设置。
直接加载配置:
<settings>
<!-- 延迟加载总开关 -->
<setting name="lazyLoadingEnabled" value="false"/>
</settings>
侵入式延迟:
<settings>
<!-- 延迟加载总开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 侵入式延迟加载开关 -->
<setting name="aggressiveLazyLoading" value="true"/>
</settings>
深度延迟:
<settings>
<!-- 延迟加载总开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 侵入式延迟加载开关 -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
N+1问题(参考文章:MyBatis 延迟加载 & N+1问题 MyBatis延迟加载原理剖析)
- 深度延迟加载的使用会提升性能。
- 如果延迟加载的表数据太多,此时会产生N+1问题,主信息加载一次算1次,而从信息是会根据主信息传递过来的条件,去查询从表多次
动态SQL:
动态SQL的思想:就是使用不同的动态SQL标签去完成字符串的拼接处理、循环判断。
"if"标签:
<select id="findUserList" parameterType="queryVo" resultType="user"> SELECT * FROM user where 1=1 <if test="user != null"> <if test="user.username != null and user.username != ''"> AND username like '%${user.username}%' </if> </if> </select>
"where"标签:
<select id="findUserList" parameterType="queryVo" resultType="user"> SELECT * FROM user <!-- where标签会处理它后面的第一个and --> <where> <if test="user != null"> <if test="user.username != null and user.username != ''"> AND username like '%${user.username}%' </if> </if> </where> </select>
sql片段(在映射文件中可使用sql标签将重复的sql提取出来,然后使用include标签引用即可,最终达到sql重用的目的)
<!-- 使用包装类型查询用户 使用ognl从对象中取属性值,如果是包装对象可以使用.操作符来 取内容部的属性 --> <select id="findUserList" parameterType="queryVo" resultType="user"> SELECT * FROM user <!-- where标签会处理它后面的第一个and --> <where> <include refid="query_user_where"></include> </where> </select>
<sql id="query_user_where"> <if test="user != null"> <if test="user.username != null and user.username != ''"> AND username like '%${user.username}%' </if> </if> </sql>
SELECT * FROM USER WHERE username LIKE '%老郭%' AND id IN (1,10,16) 通过foreach实现,如下所示为使用foreach的样例:
<sql id="query_user_where">
<if test="user != null">
<if test="user.username != null and user.username != ''">
AND username like '%${user.username}%'
</if>
</if>
<if test="ids != null and ids.size() > 0">
<!-- collection:指定输入的集合参数的参数名称 -->
<!-- item:声明集合参数中的元素变量名 -->
<!-- open:集合遍历时,需要拼接到遍历sql语句的前面 -->
<!-- close:集合遍历时,需要拼接到遍历sql语句的后面 -->
<!-- separator:集合遍历时,需要拼接到遍历sql语句之间的分隔符号 -->
<foreach collection="ids" item="id" open=" AND id IN ( " close=" ) " separator=","> #{id}
</foreach>
</if>
</sql>
Mybatis缓存:
缓存总体结构如下图所示:
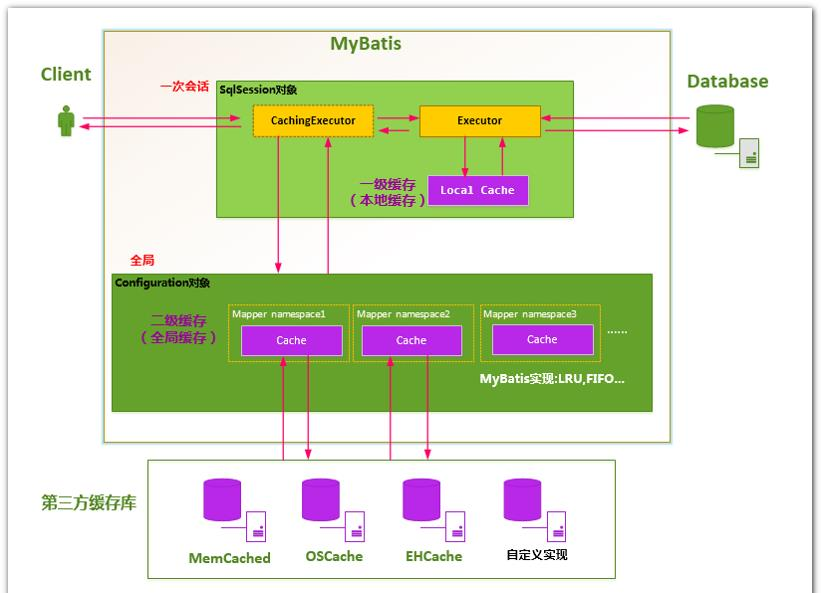
一级缓存 :
一级缓存:sqlSession级别,生命周期与sqlSession的生命周期相同。
一级缓存的初始化:在sqlSessionfactory执行openSession方法中,创建executor的时候完成初始化。具体方方法:
rg.apache.ibatis.executor.BaseExecutor#BaseExecutor(), 通过new 一个PerpetualCache对象赋值给BaseExecutor的localCache字段。
一级缓存生成:在查询时会先查询一级缓存(默认开启),如果没有查询到会查询数据库,之后将从数据库的结果存入一级缓存。
一级缓存销毁:localCacheScope缓存的作用域有SESSION和STATEMENT2个配置选项,如果配置为STATEMENT,则会每次清空缓存。此外executor执行update()、commit()、rollback()、close()都会销毁一级缓存。
二级缓存:
二级缓存构建在一级缓存之上,一级缓存是和SqlSession绑定,而二级缓存是和Mapper具体的命名空间绑定,二级缓存是全局性的,一个Mapper中有一个Cache,相同的Mapper中多个不同的MappedStatement共用一个Cache。二级缓存解决了同一个Mapper,不同sqlSession之间的数据不一致的问题。(在分布式场景下,无法解决)
一级缓存默认是开启的,而二级缓存默认不开启,可以通过配置进行开启:
1. 开启全局二级缓存配置
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
2. 在需要使用二级缓存的sqlMapConfig Mapper配置文件中配置标签
<cache></cache>
3. 在CURDmapper标签中配置useCache=true
<select id="findById" resultType="com.mryan.pojo.User" useCache="true">
select * from user where id = #{id}
</select>
二级缓存的初始化: xmlMapperBuilder#cacheElement(XNode context)方法实现初始化。
二级缓存的生成:数据查询时,通过mapperStatement中获取二级缓存(mapper配置文件中配置了<cache>,并且useCache为true),如果二级缓存中没有,则查一级缓存,如果一级缓存也没有则查数据库。最后将查询的结果放入二级缓存中。
需要注意的是二级缓存是从MappedStatement中获取,是存在于全局配置,如果被多个CachingExecutor获取到(也就是多个sqlSession),则一定会出现线程安全问题导致脏读,所以MyBatis为解决这个问题,在查询的过程中提供了TransactionalCacheManager作为事务缓存管理器。exexutor在查询到结果后,放到TransactionalCacheManager中的TransactionalCache的map集合entriesToAddOnCommit中,只有在exexutor执行commit操作后,才会将entriesToAddOnCommit的对象保存到TransactionalCache的delegate二级缓存中。而每次查询的时候是直接从TransactionalCache.delegate中查询。正是由于exexutor(sqlSession)执行commit、rollback、close操作,达到了TransactionalCache的delegate二级缓存的刷新,进而强制性地达到了不同sqlSession之间对于同一个二级缓存的可见性。
二级缓存的销毁:exexutor(sqlSession)执行close操作时销毁二级缓存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号