会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
未雨愁眸
tensorflow群469331966
博客园
::
首页
::
新随笔
::
联系
::
订阅
::
管理
公告
TensorFlow 学习(八)—— 梯度计算(gradient computation)
maxpooling 的 max 函数关于某变量的偏导也是分段的,关于它就是 1,不关于它就是 0;
BP 是反向传播求关于参数的偏导,SGD 则是梯度更新,是优化算法;
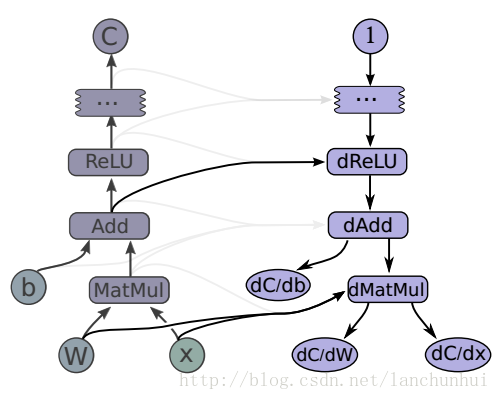
1. 一个实例
relu = tf.nn.relu(tf.matmul(x, W) + b) C = [
...
] [db, dW, dx] = tf.gradient(C, [b, w, x])
posted on
2017-03-16 11:29
未雨愁眸
阅读(
1193
) 评论(
0
)
收藏
举报
刷新页面
返回顶部



 浙公网安备 33010602011771号
浙公网安备 33010602011771号