Optimal margin classifiers
前面我们讲过,对如下的原始的优化问题我们希望找到一个优化的边界分类器。
minγ,w,bs.t.12∥w∥2y(i)(wTx(i)+b)⩾1,i=1,...m
我们可以将约束条件改写成如下:
gi(w)=−y(i)(wTx(i)+b)+1⩽0
对于每一个训练样本,我们都有这样一个约束条件,而且从KKT条件我们知道,只有当训练样本的函数边界为1时,该训练样本的
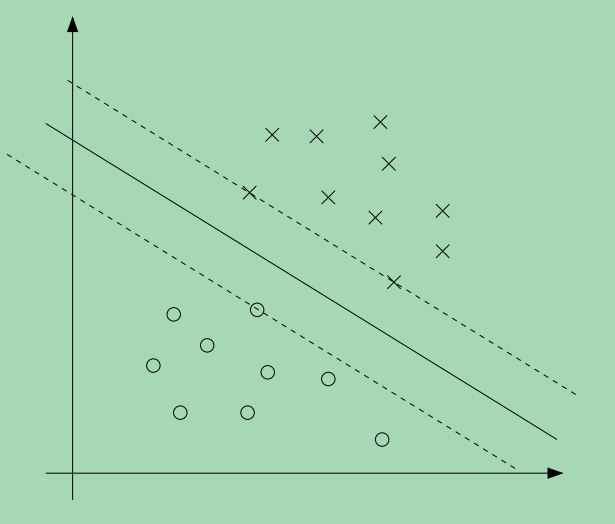
αi>0,我们看如下的一张图,其中的实线表示最大的边界分界线。
![这里写图片描述]()
从图上可以看出,离分界线最近的点他们的边界最小,图上有三个点,分布在分界线两边的虚线上,因此,只有这三个αi—换句话说,只有这三个点对应的αi—是非零的,这三个点称为\textbf{支持向量},这也说明为什么支持向量的数量只占总样本数的一小部分。这也是支持向量机的由来,这种分类器只会用到训练样本中的支持向量,其它的训练样本并不起作用。
我们继续往下看,因为之前我们讨论了这个优化问题的对偶形式,需要注意的关键一点是,我们将利用样本之间的内积<x(i),x(j)>来解决这个优化问题。
我们利用向量内积这一点,也正是稍后介绍kernel函数的关键。
我们对该优化问题建立拉格朗日表达式,我们可以得到:
L(w,b,α)=12∥w∥2−∑i=1mαi[y(i)(wTx(i)+b)−1](1)
我们先求出这个问题的对偶形式,我们要先求出
L(w,b,α)关于w,b的最小值(固定
α),为了得到
θD,我们先设
L(w,b,α)关于w,b的偏导数为0,我们有:
▽wL(w,b,α)=w−∑i=1mαiy(i)x(i)=0
这意味着:
w=∑i=1mαiy(i)x(i)(2)
而对b的偏导数,我们有:
∂∂bL(w,b,α)=∑i=1mαiy(i)=0(3)
将w的偏导数式-(2)代入拉格朗日表达式式-(1),简化后可以得到:
L(w,b,α)=∑i=1mαi−12∑i,j=1my(i)y(j)αiαj(x(i))Tx(j)−b∑i=1mαiy(i)
由式-(3)可知,上式的最后一项为0,因此我们有,
L(w,b,α)=∑i=1mαi−12∑i,j=1my(i)y(j)αiαj(x(i))Tx(j)
上式是
L(w,b,α)关于w,b的的最小值,我们引入约束条件
αi⩾0 和式-(3),可以得到如下的对偶优化函数:
maxαs.t.W(α)=∑i=1mαi−12∑i,j=1my(i)y(j)αiαj<x(i),x(j)>αi⩾0,i=1,...m∑i=1mαiy(i)=0
原来的优化问题转化为对偶优化问题之后,我们要求的是参数
α,一旦求出参数参数
α,根据式-(2)可以求出参数w,求出参数w之后(假设为
w∗),考虑原始的优化问题,我们可以得到截距b的值为:
b∗=−maxi:y(i)=−1w∗Tx(i)+mini:y(i)=1w∗Tx(i)2
得到
α,w,b之后,对于一个新的测试样本,我们可以计算
wTx(i)+b的值,如果其大于0,那么我们可以预测其为正样本,y=1。但是利用式-(2),可以得到:
wTx(i)+b=(∑i=1mαiy(i)x(i))Tx+b=∑i=1mαiy(i)<x(i),x>+b
从上式可以看出,当我们求出参数
α,那我们对于新的测试样本,只要计算测试样本和训练样本的内积就可以判断测试样本属于哪一类,而且我们知道,训练样本中的非支持向量对应的
α为0,只有支持向量对应的
α有作用,因此测试样本的预测值取决于支持向量与测试样本的内积。
Kernels
接下来,我们要介绍支持向量机中的kernel的概念,利用kernel,可以方便地处理高维甚至无穷多维的特征向量。我们先定义几个概念,我们称训练样本的原始数值为attributes (属性),而经过映射之后得到的新的数值称为features (特征),我们定义函数ϕ为feature mapping (特征映射),特征映射就是将训练样本的原始数值映射到新的数值。
我们使用SVM的时候,可能不想使用训练样本的原始数值x,我们想利用一些新的特征ϕ(x),这个对SVM的优化问题没有造成任何影响,我们只需要将前面式子里的x,换成ϕ(x)就行了。
既然SVM的算法,可以表示所有的训练样本的内积<x,z>,意味着我们只要将所有的内积替换成:<ϕ(x),ϕ(z)>。特别地,给定一个特征映射ϕ,我们定义相应的kernel 为
k(x,z)=ϕ(x)Tϕ(z)
那么,之前我们算法中用到
<x,z>的地方,只要替换成
k(x,z),那么我们的SVM算法可以利用特征
ϕ来学习。
现在,给定特征映射ϕ,我们可以先找到特征ϕ(x),ϕ(z),然后通过求两个特征向量的内积可以很容易得到k(x,z),但是更有趣的是,一般来说k(x,z)的运算要比特征ϕ(x),ϕ(z)的运算更加高效,这样,我们可以利用SVM在特征映射ϕ得到的特征空间里直接计算,而不用计算特征向量ϕ(x)。
现在,我们从另外一个稍微不同的角度来看这个kernel,直观上,如果ϕ(x),ϕ(z)比较靠近,我们希望k(x,z)=ϕ(x)Tϕ(z)是一个比较大的值,相反地,如果ϕ(x),ϕ(z)离得比较远,那么我们希望k(x,z)=ϕ(x)Tϕ(z)的值会比较小,所以我们希望k(x,z)可以用来衡量ϕ(x),ϕ(z)的相似程度,或者说x,z的相似程度。
考虑到这一点,一个比较合理的kernel函数可以是高斯函数,
k(x,z)=exp(−∥x−z∥22σ2)
这个函数可以合理地估计x,z的相似度,当x,z比较靠近,则函数值为1,当x,z离得比较远,则值为0,在SVM中,这个称为gaussian kernel。一般来说,我们需要通过一些观察来确定给定的kernel是不是合理的kernel。
一个有效的kernel应该具备某些性质,现在假设k对于特征映射ϕ来说是一个合理的kernel,考虑有限的m个点,{x(1),...x(m)},我们定义一个m×m的方阵K,方阵K中的元素为:Kij=k(x(i),x(j)),这个矩阵称为kernel matrix。
如果k是一个合理的kernel,那么,Kij=k(x(i),x(j))=ϕ(x(i))Tϕ(x(j))=ϕ(x(j))Tϕ(x(i))=k(x(j),x(i))=Kji,因此,K一定是对称的,更进一步,假设ϕk(x)表示特征向量ϕ(x)的第k个分量,我们发现,对于任何的向量z,存在以下的关系:
zTKz=∑i∑jziKijzj=∑i∑jziϕ(x(i))Tϕ(x(j))zj=∑i∑jzi∑kϕk(x(i))Tϕk(x(j))zj=∑k∑i∑jziϕk(x(i))Tϕk(x(j))zj=∑k(∑iziϕk(x(i)))2⩾0
从上式可以看出,矩阵K是半正定的,因此说,如果k是一个合理的kernel,则矩阵K是对称的半正定矩阵,Mercer定理给出了一个kernel是否合理的判断:
Marcer定理:假设kernel k满足映射关系 Rn×Rn→R,那么如果kernel k是一个合理的kernel,对于任意的有限的一组点{x(1),...x(m)},其对应的kernel 矩阵必须是对称半正定的。
将kernel应用到SVM,其好处是显而易见的,不过我们需要意识到,kernel的概念不仅仅可以用在SVM上,换句话说,如果一个学习算法需要用到输入向量的内积,即<x,z>,那么这个算法就可以利用kernel,今后我们会介绍到的一些算法都可以利用kernel,这个可以称为kernel trick。
参考文献
Andrew Ng, “Machine Learning”, Stanford University.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号