

-###Learning
前面,我们介绍了神经网络的构成,数据的预处理,权值的初始化等等。这一讲,我们将要介绍神经网络参数学习的过程。
Gradient Checks
梯度的运算,在理论上是简单的,但是在实际的应用中,却非常容易出错,梯度的运算常见的有如下两种形式:
形式一:
形式二:
利用这个表达式,需要我们对loss function做两次评估,但是这样求得的梯度会更加精确。而我们在比较梯度的解析解与数值解时,会使用如下的表达式:
我们利用两者的相对误差,来衡量两种计算结果的接近程度。如果相对误差大于
梯度运算不准确的另外一个隐患就是非平滑函数的引入,有些激励函数并非处处可导,比如RLU 函数,Leak ReLU 函数等,他们存在一些不可导的“拐点”,而在数值运算的时候,有可能会越过这些拐点,而导致梯度的运算出现偏差。
由于目标函数的loss包括两部分,一个是data loss,还有一个是regularization loss,我们需要注意,不能让regularization loss部分完全盖过了data loss,以免data loss完全不起任何作用,检查梯度的时候,可以先屏蔽掉regularization loss,先检查data loss的梯度部分,然后再反过来,检查regularization loss的梯度。做梯度检查的时候,可以先关掉drop out的功能,保证所有的神经元都处于active的状态。实际的运算中,梯度可能有几百万个变量,我们可以检查其中的一部分,并且假设剩下的部分也是正确的,而且做检查的时候,可以用少量的训练样本做检查。
在正式训练网络之前,我们对目标函数的loss要有一个大概的估计,我们可以先去掉regularization loss,让data loss的值符合我们大致的预期,如果loss未能到达我们的预期,可能权值的初始化有问题。另外一个trick就是先训练一个小的训练集,保证训练的error能到0,这个可以用来检测网络是否正常运行。
Babysitting the learning process
在训练的过程中,我们要利用一些合理的指标来检测训练是否有效,我们可以用二维图来表示这些指标,一般来说图的x坐标总是训练周期,一个周期表示每个训练样本都已经在网络中出现过一次,周期的次数,就表示训练样本在网络中出现的次数。我们不用迭代次数来表示x坐标,因为迭代次数与训练集的大小以及每个batch的大小有关。
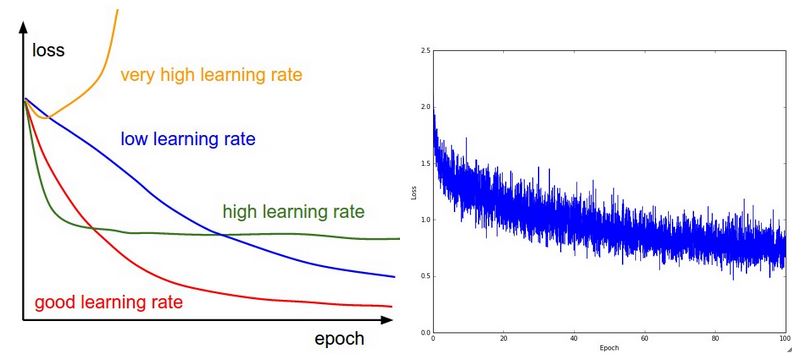
第一个指标是loss function,它直接反应了训练的误差,如上图所示。左图给出了loss与learning rate之间的关系,并且告诉了我们什么是合适的learning rate。我们可以看到,太低的learning rate会使loss几乎层线性下降,而太高的learning rate会使loss反而上升。而learning rate稍微偏高的话,loss下降会很快,但是最后会收敛到一个较高的loss。右图给出了在CIFRA-10上的训练结果,这是一个看起来比较合理的loss,虽然有可能batch size可能偏小,因为loss看起来随机抖动的有点剧烈。一般来说,loss中的起伏和batch size有关,batch size太小,loss的起伏会很大。
第二个指标是训练与验证的正确率,如下图所示:

这个告诉了我们网络是否有可能出现overfitting的问题,根据这个指标,可以考虑调整regularization loss的比重,或者收集更多的训练样本。
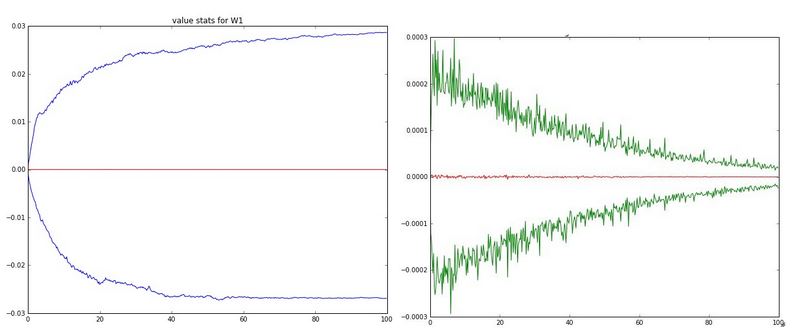
最后一个指标是权重与权值更新的比率,如下图所示。神经网络的每一层都有权值,这些权值的更新幅度与learning rate有关,通过查看权值与权值更新的比率,可以看到learning rate的大小。下图给出了一个两层的神经网络中,W1的权值与权值更新随训练周期的变化,左图给出的是每个训练周期里,W1的最大值与最小值的变化,右图是最大值与最小值对应的权值更新的变化,权值的幅度在0.02左右,而权值更新的幅度在0.0002左右,所以他们的比率为0.01。
Activation / Gradient distributions per layer
一个糟糕的初始化将会导致一个很糟糕的训练结果,反应初始化最好的指标就是每一层激励函数的方差和梯度的方差,一个不合理的初始化将导致方差逐渐减少,这对梯度的传递时非常不利的,一个合理的初始化应该保证每一层的方差比较接近。如果每一层的权值都是简单的从高斯分布中随机抽取,会导致方差逐渐减少,更加有效的初始化是对每一层的权值做一个尺度变换。
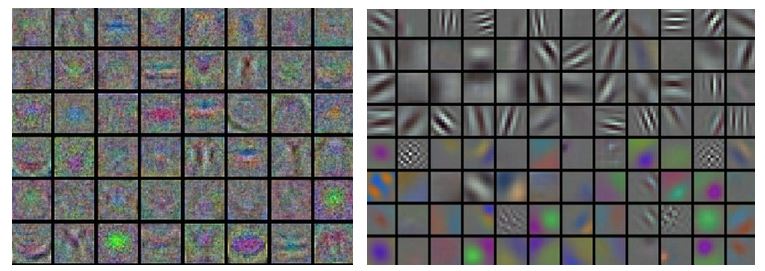
最后,如果我们是处理图像,一个简单有效的方法是将图像可视化,如下图所示:左边的图表明噪声很多,说明网络可能没有收敛地很好,而右边的图看起来要平滑地多,说明网络很好地收敛了。
Parameters Updates
下面我们介绍几种参数跟新的方式,我们假设
Vanilla update:
Momentum update 是另外一种更新方式,而且在深度神经网络中的收敛性能很好,它在物理学上有一个直观的解释,我们可以假设将一个粒子放在一个山坡的某处,那么loss就是山坡的高度,而网络的初始化相当于将粒子放置在山坡的某处,并且让其初始速度为0,那么粒子沿着山坡滚下来的过程就类似网络的优化过程,我们假设粒子受到的力为F,粒子受到的力就相当于loss函数的梯度,因为
Momentum update:
这里
Nesterov Momentum与Momentum update略有不同,Nesterov Momentum的核心思想是,当权值处在某个位置时,利用上面介绍的Momentum update,我们知道权值下一步的位置会是
Nesterov Momentum:
在实际使用的时候,有人也会将Nesterov Momentum做一些改变,使得与前两种形式接近,比如:
在参数更新中,也可以用二阶导数做更新,就是牛顿法,但是这种方法目前并不常见,比起一阶梯度下降,二阶要复杂地多,所以这里不再详细介绍。
Annealing the learning rate
在深度神经网络的训练中,learning rate的调整是非常重要的,随着训练周期的延长,网络越来越靠近最优解,所以learning rate要随着训练能够做出调整,目前比较常用的有三种调整方法:
1:Step decay 这种方法就是每隔几个训练周期对learning rate做一次调整,比如减少一半。这些都取决于具体的问题。
2:Exponential decay 这种方法就是让learning rate以指数形式调整,
3:1/t decay
Per-parameter adaptive learning rate methods
前面介绍的参数更新都是用统一的learning rate,有学者尝试对每个参数利用不同的learning rate做更新。Adagrad 是一种自适应的参数更新方法,如下所示:
Adagrad:
简单来说,Adagrad就是通过引入
另外一种是RMSprop,形式如下:
RMSprop:
Hyperparameter optimization
大规模的神经网络的训练是非常耗时的,需要设计到很多参数的设置,比如权值的初始化,learning rate的设定,regularization loss的比重,以及drop out的比重。下面简单介绍一下在神经网络训练中会使用到的一些技巧。
我们可以随机抽取一些数据做验证,而避免交叉验证,这样可以节省训练时间。
hyperparameter 可以在一个范围内进行设定。
对hyperparameter的搜寻可以利用随机搜寻,而不用grid search。
对处在边缘的hyperparameter要谨慎,有的时候我们发现hyperparameter取某个区间靠近边界的值效果很好,意味着有可能更加好的hyperparameter在这个边界附近。
hyperparameter的搜寻可以由粗到细,先在大范围寻找,然后缩小寻找范围。
利用贝叶斯对hyperparameter做优化。
声明:lecture notes里的图片都来源于该课程的网站,只能用于学习,请勿作其它用途,如需转载,请说明该课程为引用来源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号