

最近看了基于CNN的目标检测另外两篇文章,YOLO v1 和 YOLO v2,与之前的 R-CNN, Fast R-CNN 和 Faster R-CNN 不同,YOLO 将目标检测这个问题重新回到了基于回归的模型。YOLO v1 是一个很简单的 CNN 网络,YOLO v2 是在第一版的基础上,借鉴了其他几种检测网络的一些技巧,让检测性能得到大幅提升。下面分别介绍一下这两个网络:
YOLO v1
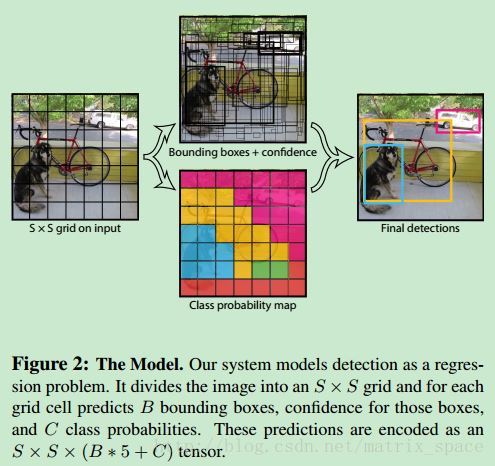
YOLO v1 的结构看起来很简单,如下图所示:

从示意图上看,似乎就是输入一张图片,经过一个CNN 网络,最后就能给出目标的检测框以及分类的概率,很高效的样子。
输入一张
每个 bounding box 有5个参数,
最后个值反应了,bounding box 中出现某一类物体的概率,以及这个 bounding box 检测的准确度。如下图所示:
YOLO-v1 的网络结构是基于 GoogleNet 的有一个深层的,一个浅层的,深层的含有 24 个卷积层,浅层的含有 9 个卷积层,网络结构如下所示:

基本上就是
网络的训练,先是用这个网络再 ImageNet 上训练一遍,大概 20 层的卷积层,这个时候训练的输入尺寸是
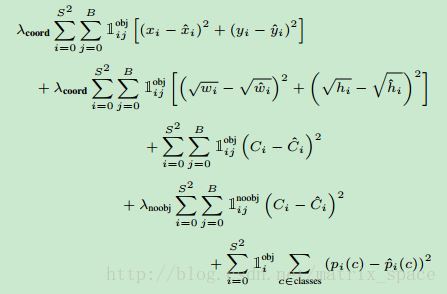
这个函数基本将分类的准确率以及检测的精度都考虑了。不过这个网络的性能还是有局限,正如论文中所说:
因为采用固定的 grid cell, 并且每个 grid cell 只识别一个类,所以如果这个 grid cell 如果有多个物体,这是识别不了的,也就是说对小物体,这个网络的识别性能较差。
因为检测是用 bound box 做的,bounding box 是固定的形状,所以这个网络对形变或者不同的尺寸比适应性较差。
最后,loss function 对 bounding box 的 error 是一视同仁的,不同大小的bounding box 的 error 应该要区别对待。同样的error,对小的bounding box 的影响会比大的bounding box的影响要大很多。
具体的细节讨论,实验结果可以看论文。后面我们再介绍 YOLO-v2
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, “You Only Look Once: Unified, Real-Time Object Detection”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号