
CNN综述
卷积神经网络CNN是对BP神经网络的改进,与BP一样,都采用了前向传播计算输出值,反向传播调整权重和偏置,卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层(池化层)构成的特征抽取器。CNN相邻层之间的神经单元也并不是全连接,而是部分连接,某个神经单元的感知区域来自于上层的部分神经单元,而不是像BP那样与所有的上层神经单元相连接。
在CNN的一个卷积层中,通常包含若干个特征平面(Feature Map),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。
共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样(池化)可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数,提高了模型的泛化能力。
CNN模型
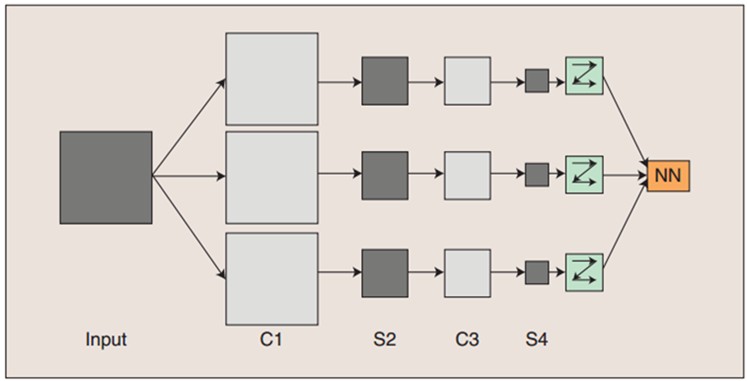
卷积神经网络由三部分构成。第一部分是输入层。第二部分由n个卷积层(C)和池化层(S)的组合组成。第三部分由一个全连结的多层感知机分类器构成,在这一部分,像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
局部感受野
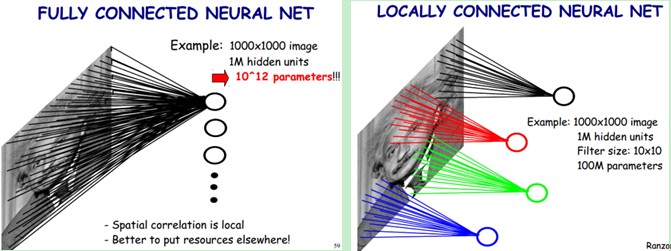
局部感受野是卷积核窗口在上一层图像上的映射,为了降低参数的维度以及防止过拟合出现,CNN中神经元并不是对上一层图像的全局进行感知,而是每个神经元只对卷积核窗口大小的局部区域进行感知,然后在更高层将局部的信息综合起来得到全局的信息,如下图,全连接和局部链接的区别:
权值共享
CNN中每一层由多个map(特征图)组成,每个map由多个神经单元组成,同一个map所有的神经单元共用一个卷积核(即权重),卷积核跟上一层图像卷积往往得到图像的一个特征,权值共享策略减少了需要训练的参数,使得训练出来的模型的泛化能力更强。
权值共享也实现了特征与位置无关性,图像的一部分的统计特性与其他部分是一样的。意味着在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,都能使用同样的学习特征。
如下展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都代表了一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
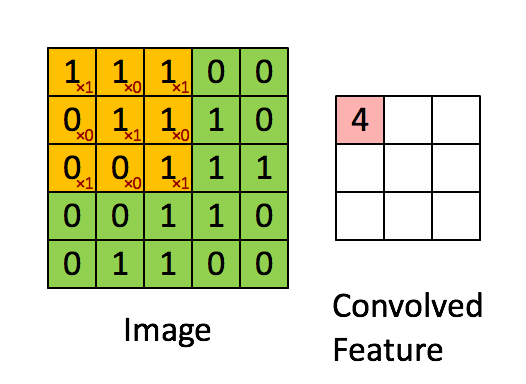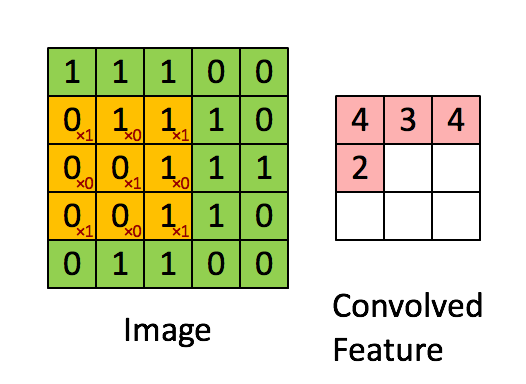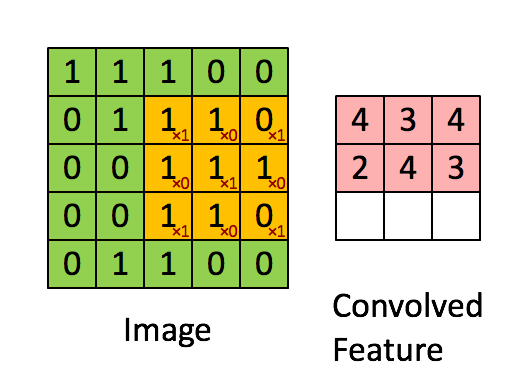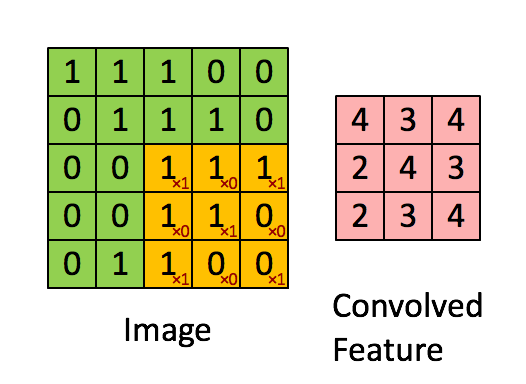
局部感受野其实是一个滤波的过程,也是一个对图像降维的过程。
多卷积核
在上边提到过一个卷积核代表了对图像上一个隐含特征的提取,为了充分理解和表达图像,需要使用多个卷积核,比如32个卷积核,可以提取并学习到32种图像的隐含特征。
每个卷积核跟图像卷积后,生成另一幅图像,即特征图(Feature Map)。对输入图像的第一个卷积层,包含N个特征图像,不同特征图像是使用不同卷积核与原图像卷积的结果,每个卷积核代表了一种特征提取方式。
池化
池化是对特征向量的下采样,进一步降低了特征的维度,减少了计算量,并且使训练不容易出现过拟合现象。
一般有两种池化方式,一种是平均池化(mean-pooling),一种是最大值池化(max-pooling)。池化也是一种滤波。
多卷积层
CNN一般采用卷积层与池化层交替设置,先用卷积层提取出特征,再通过池化层(采样层)组合成更抽象的特征,然后再经过卷积和池化的过程,如此执行多次之后把特征光栅化,组合成一个列向量,传入到全连接层进行训练。
单个卷积层学到的特征是局部的,一般情况下,层数越高,学到的特征就越全局化,越能代表对象的共有特征,泛化能力越强。
CNN的训练流程
卷积神经网络的训练任然遵循“前向传输,逐层波浪式的传递输出值;逆向反馈,反向逐层调整权重和偏置”的规则,所不同的是,传统神经网络训练的目的是为了获取神经元间传递的权重和偏置,卷积神经网络训练的目的是为了获取神经元间卷积核的形式和偏置,即卷积神经网络中卷积层的权重更新过程本质是卷积核的更新过程。
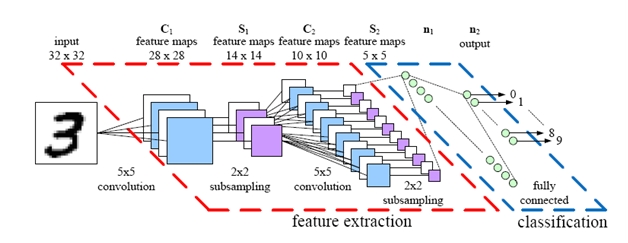
上图是一个典型的卷积神经网络的模型架构图,训练过程可以大致分为以下几步:
- 1. 对32*32的原始图像使用4个不同的卷积核(大小都为5*5)进行卷积,得到第一个卷积层C1,C1里4个特征图的大小都是28*28(N*N的图像使用n*n的卷积核卷积,结果图像维度是(N-n+1)*(N-n+1));
- 2. 对第一卷积层C1的4个特征图分别做池化处理,池化模板是2*2,即C1中的特征图上的2*2共4个像素映射到池化层S1中的一个像素,所以28*28的特征图经过池化后大小变成14*14
- 3. 对S1池化层的4个特征图进一步做卷积处理,产生第二卷积层C2。本次卷积使用卷积核大小为5*5,但是引入了12个卷积核,产生了C2卷积层中的12个特征图,每个特征图的大小是10*10;
- 4. 对第二卷积层C2的12个特征图执行池化处理,池化模板是2*2,生成第二池化层S2,S2包含12个特征图,每个特征图的大小是5*5;
- 5. 对第二池化层执行光栅化,把所有特征图展开组合成一个列向量,一共是5*5*12=300维的一个抽象向量,形成一个全连接层,参与到最终的数据训练分类中。
CNN的优点
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
PS:
泛化是指学习到的模型遇到训练时没有遇到过的样本时的表现。好的模型的泛化能力强,能够对陌生测试样本做出正确率较高的预测。泛化能力弱的模型的主要特征表现为过拟合或欠拟合。
拟合在统计学中用来描述函数和目标函数逼近或吻合的程度,过拟合是指模型对于训练数据拟合程度过当的情况。
当某个模型过度的学习到训练数据中的细节和噪声,以至于模型在新的数据上表现很差,这种情况称为过拟合。这意味着训练数据中的噪音或者随机波动也被当做概念被模型学习了,而这些概念并不适用于新的数据,从而导致模型泛化能力变差。
欠拟合是指模型在训练和预测样本上表现都不佳的情况,实际碰到的情况一般都是过拟合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号