

深度神经网络一般由卷积部分和全连接部分构成。卷积部分一般包含卷积(可以有多个不同尺寸的核级联组成)、池化、Dropout等,其中Dropout层必须放在池化之后。全连接部分一般最多包含2到3个全连接,最后通过Softmax得到分类结果,由于全连接层参数量大,现在倾向于尽可能的少用或者不用全连接层。神经网络的发展趋势是考虑使用更小的过滤器,如1*1,3*3等;网络的深度更深(2012年AlenNet8层,2014年VGG19层、GoogLeNet22层,2015年ResNet152层);减少全连接层的使用,以及越来越复杂的网络结构,如GoogLeNet引入的Inception模块结构。
VGGNet获得2014年ImageNet亚军,VGG是牛津大学 Visual Geometry Group(视觉几何组)的缩写,以研究机构命名。
VGG在AlexNet基础上做了改进,整个网络都使用了同样大小的3*3卷积核尺寸和2*2最大池化尺寸,网络结果简洁。一系列VGG模型的结构图:

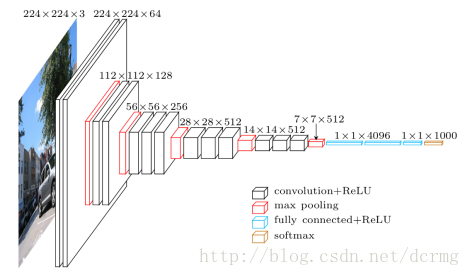
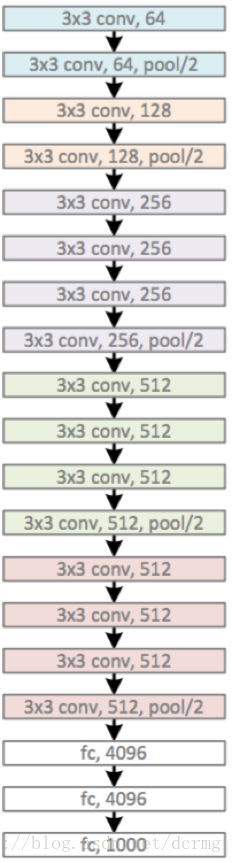
VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
AlexNet中每层卷积层中只包含一个卷积,卷积核的大小是7*7,。在VGGNet中每层卷积层中包含2~4个卷积操作,卷积核的大小是3*3,卷积步长是1,池化核是2*2,步长为2,。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面作者认为相当于进行了更多的非线性映射,增加了网络的拟合表达能力。
VGGNet的图片预处理
VGG的输入224*224的RGB图像,预处理就是每一个像素减去了均值。
VGG的多尺度训练
VGGNet使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224′224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。VGG作者在尝试使用LRN之后认为LRN的作用不大,还导致了内存消耗和计算时间增加。
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,主要因为:
(1)使用小卷积核和更深的网络进行的正则化;
(2)在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
VGGNet改进点总结
一、使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的(3*3*3)/(7*7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
二、在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
三、训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
四、采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号