::
::
::
::
::
卷积神经网络CNN(YannLecun,1998年)通过构建多层的卷积层自动提取图像上的特征,一般来说,排在前边较浅的卷积层采用较小的感知域,可以学习到图像的一些局部的特征(如纹理特征),排在后边较深的卷积层采用较大的感知域,可以学习到更加抽象的特征(如物体大小,位置和方向信息等)。CNN在图像分类和图像检测领域取得了广泛应用。
CNN提取的抽象特征对图像分类、图像中包含哪些类别的物体,以及图像中物体粗略位置的定位很有效,但是由于采用了感知域,对图像特征的提取更多的是以“一小块临域”为单位的,因此很难做到精细(像素级)的分割,不能很准确的划定物体具体的轮廓。
针对CNN在图像精细分割上存在的局限性,UC Berkeley的Jonathan Long等人2015年在其论文 “Fully convolutional networks for semantic segmentation”(用于语义分割的全卷积神经网络)中提出了Fully Convolutional Networks (FCN)用于图像的分割,要解决的核心问题就是图像像素级别的分类。论文链接: https://arxiv.org/abs/1411.4038
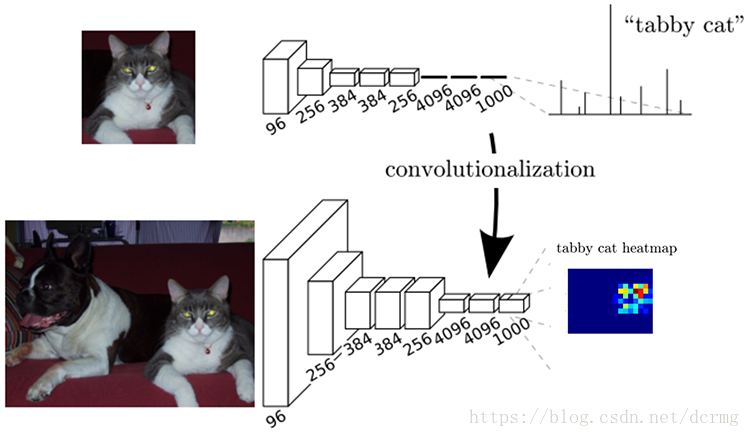
FCN与CNN的核心区别就是FCN将CNN末尾的全连接层转化成了卷积层:
![]()
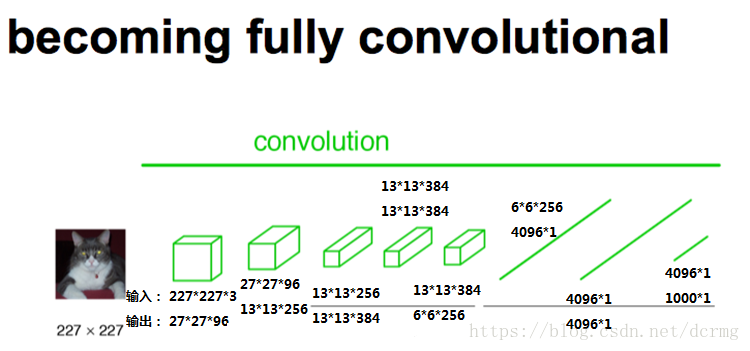
以Alexnet为例,输入是227*227*3的图像,前5层是卷积层,第5层的输出是256个特征图,大小是6*6,即256*6*6,第6、7、8层分别是长度是4096、4096、1000的一维向量。
![]()
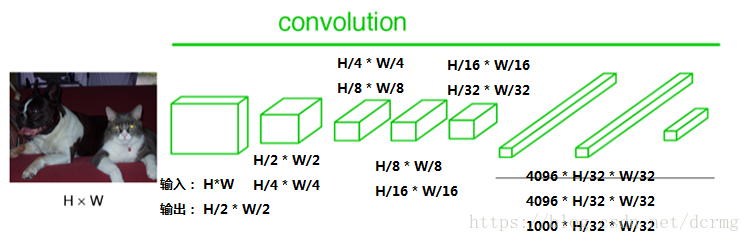
在FCN中第6、7、8层都是通过卷积得到的,卷积核的大小全部是1*1,第6层的输出是4096*7*7,第7层的输出是4096*7*7,第8层的输出是1000*7*7(7是输入图像大小的1/32),即1000个大小是7*7的特征图(称为heatmap)。
![]()
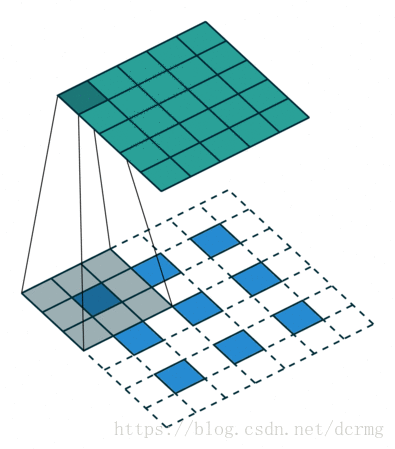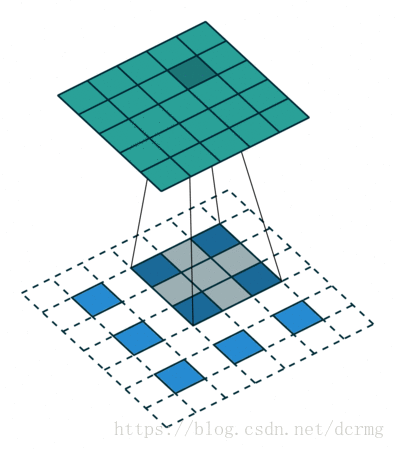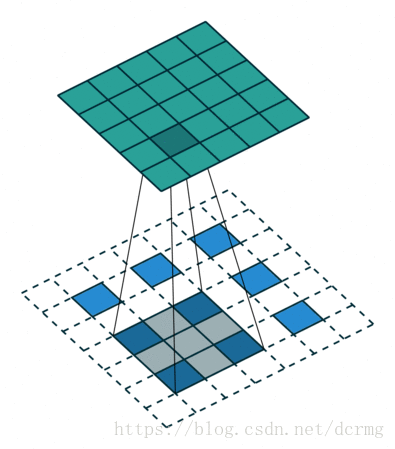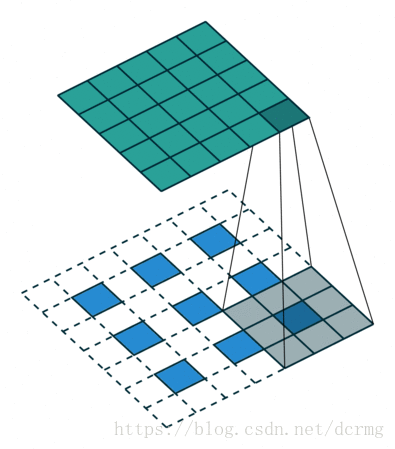
经过多次卷积后,图像的分辨率越来越低,,为了从低分辨率的heatmap恢复到原图大小,以便对原图上每一个像素点进行分类预测,需要对heatmap进行反卷积,也就是上采样。论文中首先进行了一个上池化操作,再进行反卷积,使得图像分辨率提高到原图大小:
![]()
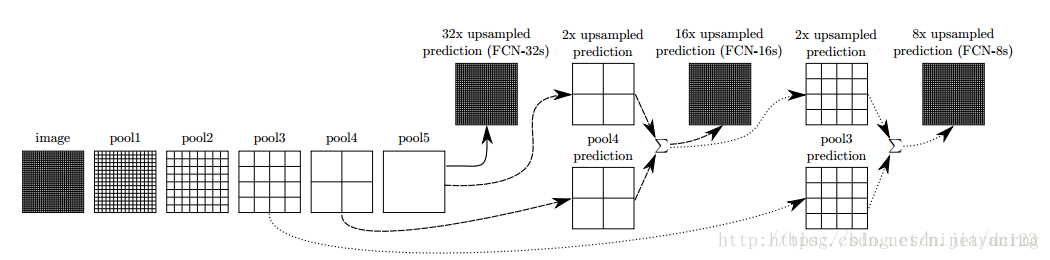
对第5层的输出执行32倍的反卷积得到原图,得到的结果不是很精确,论文中同时执行了第4层和第3层输出的反卷积操作(分别需要16倍和8倍的上采样),再把这3个反卷积的结果图像融合,提升了结果的精确度:
![]()
最后像素的分类按照该点在1000张上采样得到的图上的最大的概率来定。
FCN可以接受任意大小的输入图像,但是FCN的分类结果还是不够精细,对细节不太敏感,再者没有考虑到像素与像素之间的关联关系,丢失了部分空间信息。
posted on
2018-07-19 14:49
未雨愁眸
阅读(
2092)
评论()
收藏
举报



 浙公网安备 33010602011771号
浙公网安备 33010602011771号