

介绍链表前我们先了解下什么是列表。
在对基本数据结构的讨论中,我们使用 Python 列表来实现所呈现的抽象数据类型。列表是一个强大但简单的收集机制,为程序员提供了各种各样的操作。然而,不是所有的编程语言都包括列表集合。在这些情况下,列表的概念必须由程序员实现。
列表是项的集合,其中每个项保持相对于其他项的相对位置。更具体地,我们将这种类型的列表称为无序列表。我们可以将列表视为具有第一项,第二项,第三项等等。我们还可以引用列表的开头(第一个项)或列表的结尾(最后一个项)。为了简单起见,我们假设列表不能包含重复项。
例如,整数 54,26,93,17,77 和 31 的集合可以表示考试分数的简单无序列表。请注意,我们将它们用逗号分隔,这是列表结构的常用方式。当然,Python 会显示这个列表为 [54,26,93,17,77,31]。
1 无序列表抽象数据类型
如上所述,无序列表的结构是项的集合,其中每个项保持相对于其他项的相对位置。下面给出了一些可能的无序列表操作。
- List() 创建一个新的空列表。它不需要参数,并返回一个空列表。
- add(item) 向列表中添加一个新项。它需要 item 作为参数,并不返回任何内容。假定该 item 不在列表中。
- remove(item) 从列表中删除该项。它需要 item 作为参数并修改列表。假设项存在于列表中。
- search(item) 搜索列表中的项目。它需要 item 作为参数,并返回一个布尔值。
- isEmpty() 检查列表是否为空。它不需要参数,并返回布尔值。
- size()返回列表中的项数。它不需要参数,并返回一个整数。
- append(item) 将一个新项添加到列表的末尾,使其成为集合中的最后一项。它需要 item
作为参数,并不返回任何内容。假定该项不在列表中。 - index(item) 返回项在列表中的位置。它需要 item 作为参数并返回索引。假定该项在列表中。
- insert(pos,item) 在位置 pos 处向列表中添加一个新项。它需要 item作为参数并不返回任何内容。假设该项不在列表中,并且有足够的现有项使其有 pos 的位置。
- pop() 删除并返回列表中的最后一个项。假设该列表至少有一个项。
- pop(pos) 删除并返回位置 pos 处的项。它需要 pos 作为参数并返回项。假定该项在列表中。
2 python实现无序列表
为了实现无序列表,我们将构造通常所知的链表,外部引用通常被称为链表的头。
2.1 Node类
节点(Node)是链表实现的基本构造,由列表项(item,数据字段)和对下一个节点的引用组成。Node 类包括访问,修改数据和访问下一个引用等常用方法。类的代码如下:
class Node:
def __init__(self,initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self,newdata):
self.data = newdata
def setNext(self,newnext):
self.next = newnext我们创建一个 Node 对象
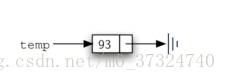
temp = Node(93)Python 引用值 None 将在 Node 类和链表本身发挥重要作用。引用 None 代表没有下一个节点。请注意在构造函数中,最初创建的节点 next 被设置为 None。有时这被称为 接地节点,因此我们使用标准接地符号表示对 None 的引用,如下图:
2.2 Unordered List 类
如上所述,无序列表将从一组节点构建,每个节点通过显式引用链接到下一个节点。只要我们知道在哪里找到第一个节点(包含第一个项),之后的每个项可以通过连续跟随下一个链接找到。考虑到这一点,UnorderedList 类必须保持对第一个节点的引用,如下图所示,实现代码如下:
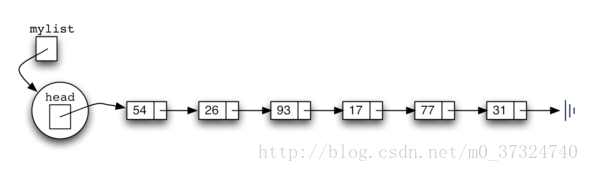
class UnorderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
def add(self,item):
temp = Node(item)
#更改新节点的下一个引用以引用旧链表的第一个节点
temp.setNext(self.head)
#赋值语句设置列表的头
self.head = temp
#访问和赋值的顺序不能颠倒,因为head是链表节点唯一的外部引用,颠倒将导致所有原始节点丢失并且不能再被访问
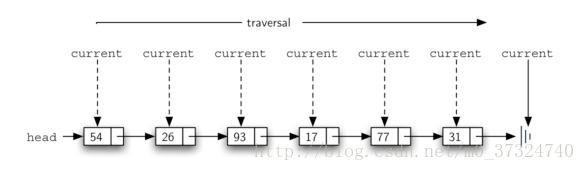
def size(self):
current = self.head
count = 0
while current != None:
count = count + 1
current = current.getNext()
return count
def search(self,item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self,item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
#previous 必须先将一个节点移动到 current 的位置。此时,才可以移动current
else:
previous = current
current = current.getNext()
#如果要删除的项目恰好是链表中的第一个项,链表的 head 需要改变
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())2.2.1 add function
链表结构只为我们提供了一个入口点,即链表的头部。所有其他节点只能通过访问第一个节点,然后跟随下一个链接到达。这意味着添加新节点的最简单的地方就在链表的头部。 换句话说,我们将新项作为链表的第一项,现有项将需要链接到这个新项后。
2.2.2 链表遍历技术——size,search,remove方法
size方法实现思路如下图:
remove方法实现思路如下图:
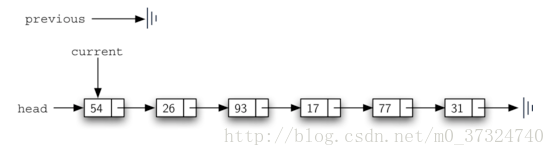
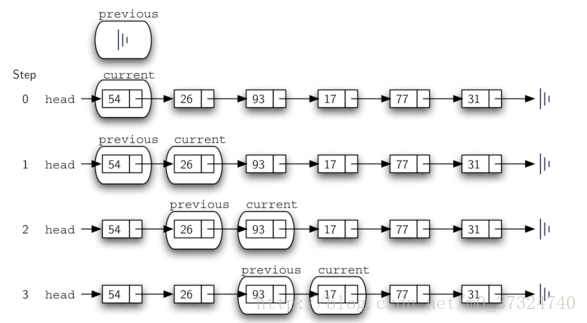
remove 方法需要两个逻辑步骤。
第一步搜索,第二部删除。
但是current实际指向的是目标节点的引用,直接删除会删除前一个节点,因此引入previous这个外部引用。
参考资料:《problem-solving-with-algorithms-and-data-structure-using-python》
http://www.pythonworks.org/pythonds

 浙公网安备 33010602011771号
浙公网安备 33010602011771号