

最近博主在做个 kaggle 竞赛,有个 Kernel 的数据探索分析非常值得借鉴,博主也学习了一波操作,搬运过来借鉴,原链接如下:
https://www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction
1 数据介绍
数据由Home Credit提供,该服务致力于向无银行账户的人群提供信贷(贷款)。预测客户是否偿还贷款或遇到困难是一项重要的业务需求,Home Credit将在Kaggle上举办此类竞赛,以了解机器学习社区可以开展哪些模式以帮助他们完成此任务。
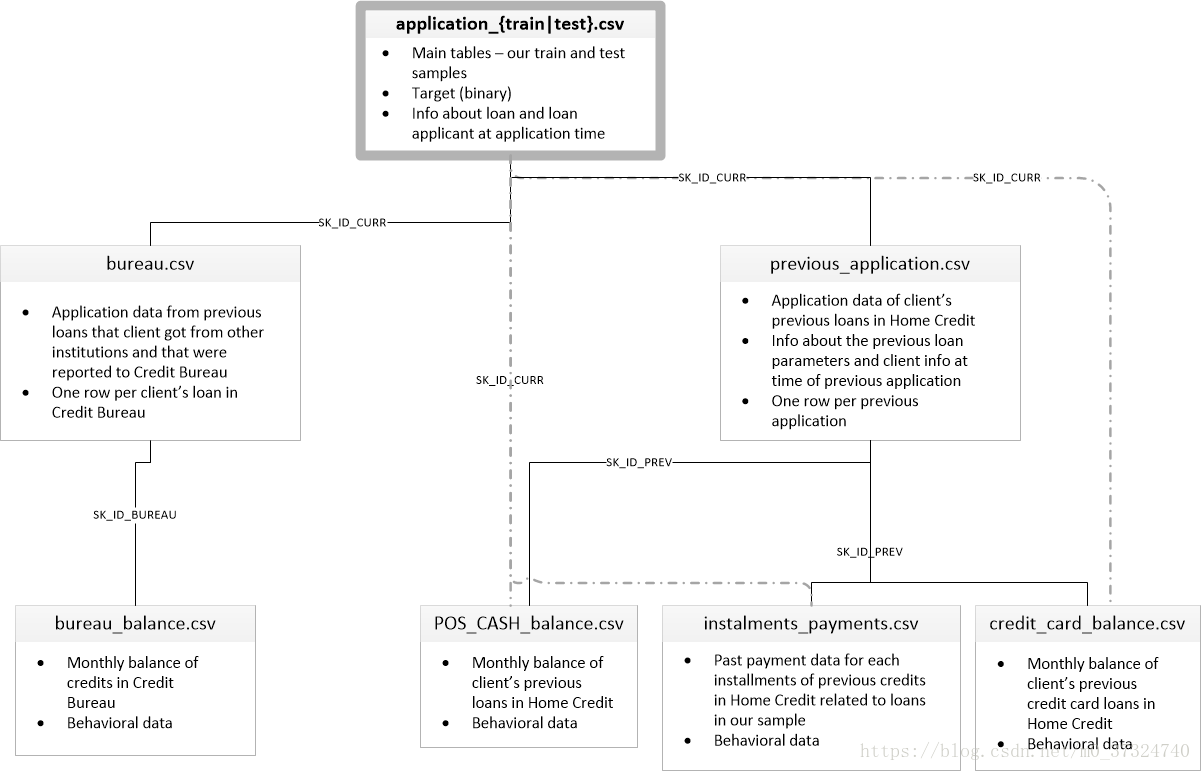
有7种不同的数据来源:
application_train / application_test:
主要的培训和测试数据以及关于Home Credit每个贷款申请的信息。每笔贷款都有自己的行,并由功能SK_ID_CURR标识。培训申请数据附带TARGET表示0:贷款已还清或1:贷款未还清。
bureau:
有关客户之前来自其他金融机构的信贷的数据。以前的每一笔信贷都有自己的分行,但申请数据中的一笔贷款可能有多笔先前信贷。
bureau_balance:
关于主管局以前信用的月度数据。每一行都是上一个信用的一个月,并且一个先前的信用可以有多个行,每个信用额度的每个月有一个行。
previous_application:
之前在申请数据中拥有贷款的客户的Home Credit贷款申请。申请数据中的每个当前贷款都可以有多个以前的贷款。每个以前的应用程序都有一行,并由功能SK_ID_PREV标识。
POS_CASH_BALANCE:关于客户以前的销售点或现金贷款与住房贷款有关的每月数据。每一行都是前一个销售点或现金贷款的一个月,以前的一笔贷款可以有多行。
credit_card_balance:
有关之前的信用卡客户与Home Credit有关的每月数据。每行都是信用卡余额的一个月,一张信用卡可以有多行。
installments_payment:
Home Credit以前贷款的付款记录。每笔付款都有一行,每笔未付款都有一行。
下图显示了所有数据是如何相关的:
2 数据初探索
2.1 读取数据
# numpy and pandas for data manipulation
import numpy as np
import pandas as pd
# sklearn preprocessing for dealing with categorical variables
from sklearn.preprocessing import LabelEncoder
# File system manangement
import os
# Suppress warnings
import warnings
warnings.filterwarnings('ignore')
# matplotlib and seaborn for plotting
import matplotlib.pyplot as plt
import seaborn as snsapp_train = pd.read_csv('../input/application_train.csv')
app_test = pd.read_csv('../input/application_test.csv')2.2 检查目标列的分布
app_train['TARGET'].value_counts()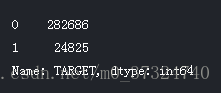
app_train['TARGET'].astype(int).plot.hist();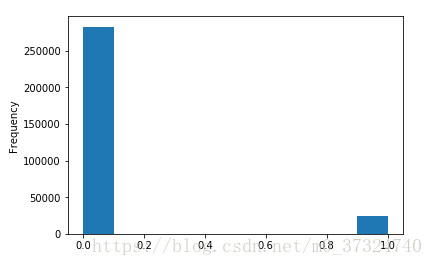
根据这些信息,我们发现这是一个不平衡的课堂问题。 按时还款的贷款远远多于未还款的贷款。 一旦我们进入更复杂的机器学习模型,我们可以通过它们在数据中的表示来对类进行加权以反映这种不平衡。
2.3 检查缺损值
# Function to calculate missing values by column# Funct
def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns# Missing values statistics
missing_values = missing_values_table(app_train)
missing_values.head(20)
当需要建立我们的机器学习模型时,我们将不得不填写这些缺失值(称为插补)。 在以后的工作中,我们将使用XGBoost等模型,可以处理缺失值而不需要插补。 另一种选择是删除缺失值比例较高的列,但如果这些列对我们的模型有帮助,则不可能提前知道。 因此,我们现在将保留所有列。
2.4 查看列类型
# Number of each type of column
app_train.dtypes.value_counts()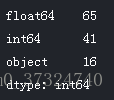
现在我们来看看每个对象(分类)列中唯一条目的数量。
app_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0)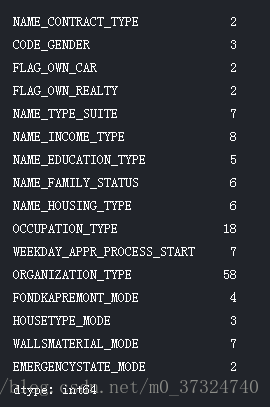
大多数分类变量的唯一条目数量相对较少。 我们需要找到一种方法来处理这些分类变量!
2.5 编码分类变量
在我们继续前进之前,我们需要处理讨厌的分类变量。 不幸的是,机器学习模型不能处理分类变量(除了LightGBM等一些模型)。 因此,我们必须找到一种将这些变量编码(表示)为数字的方式,然后再将它们交给模型。 有两种主要的方法来执行这个过程:- 标签编码:使用整数分配分类变量中的每个唯一类别。 没有创建新列。 一个例子如下所示:

- 单热编码:为分类变量中的每个唯一类别创建一个新列。 每个观察结果在其相应类别的列中收到1,在所有其他新列中收到0。
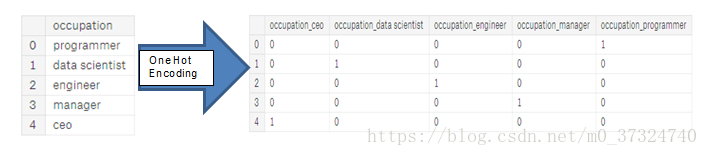
关于这些方法的相对优点存在一些争议,并且一些模型可以处理标签编码的分类变量而没有问题。 这是一个很好的Stack Overflow讨论。 我认为(这只是一种个人观点)对于有很多类的分类变量,单热编码是最安全的方法,因为它不会对类别强加任意值。 单热编码唯一的缺点是特征的数量(数据的维数)会随着分类变量的分类而爆炸。 为了解决这个问题,我们可以执行一个热门的编码,然后是 PCA 或其他降维方法,以减少维数(同时仍试图保留信息)。
我们将使用标签编码来处理任何仅有2个类别的分类变量,对于超过2个类别的任何分类变量使用单向编码。
2.6 标签编码和单热编码
让我们实现上面描述的策略:对于具有2个唯一类别的任何分类变量(dtype ==对象),我们将使用标签编码,对于具有多于2个唯一类别的任何分类变量,我们将使用单热编码。
对于标签编码,我们使用Scikit-Learn LabelEncoder和一个热门编码,即熊猫get_dummies(df)函数。
# Create a label encoder object
le = LabelEncoder()
le_count = 0
# Iterate through the columns
for col in app_train:
if app_train[col].dtype == 'object':
# If 2 or fewer unique categories
if len(list(app_train[col].unique())) <= 2:
# Train on the training data
le.fit(app_train[col])
# Transform both training and testing data
app_train[col] = le.transform(app_train[col])
app_test[col] = le.transform(app_test[col])
# Keep track of how many columns were label encoded
le_count += 1
print('%d columns were label encoded.' % le_count)
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)
2.7 对齐训练集和测试集
训练和测试数据中都需要具有相同的特征(列)。 一次性编码在训练数据中创建了更多列,因为有一些分类变量的类别未在测试数据中表示。 要删除训练数据中不在测试数据中的列,我们需要对齐数据框。 首先,我们从训练数据中提取目标列(因为这不在测试数据中,但我们需要保留这些信息)。 当我们进行对齐时,我们必须确保将axis = 1设置为基于列而不是在行上对齐数据框!train_labels = app_train['TARGET']
# Align the training and testing data, keep only columns present in both dataframes
app_train, app_test = app_train.align(app_test, join = 'inner', axis = 1)
# Add the target back in
app_train['TARGET'] = train_labels
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape) 训练和测试数据集现在具有机器学习所需的相同特征。 由于单热编码,功能数量显着增加。 在某些情况下,我们可能会尝试降维(删除不相关的功能)以减小数据集的大小。
训练和测试数据集现在具有机器学习所需的相同特征。 由于单热编码,功能数量显着增加。 在某些情况下,我们可能会尝试降维(删除不相关的功能)以减小数据集的大小。3 数据分析及可视化
3.1 异常数据
在探索数据的时候需要注意的一个问题是数据中的异常情况。 这可能是由于错误的数字,测量设备的错误,或者它们可能是有效的,但极端的测量。 定量支持异常的一种方法是使用描述方法查看列的统计数据。 DAYS_BIRTH列中的数字是负数,因为它们是相对于当前贷款申请记录的。 要查看这些年份的统计数据,我们可以用-1来多项式除以一年中的天数:
(app_train['DAYS_BIRTH'] / -365).describe()
那些年龄看起来合理。 高端或低端的年龄没有异常值。 就业日期如何?
app_train['DAYS_EMPLOYED'].describe()
这看起来不正确! 最大值(除了正值)大约是1万年!
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment');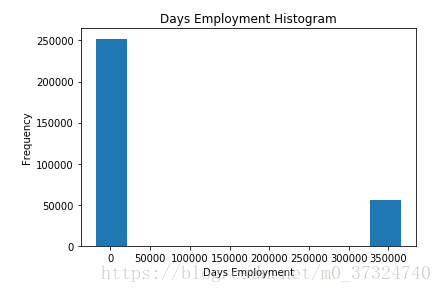
出于好奇,让我们对异常客户进行分类,看看他们是否倾向于比其他客户的违约率更高或更低。
anom = app_train[app_train['DAYS_EMPLOYED'] == 365243]
non_anom = app_train[app_train['DAYS_EMPLOYED'] != 365243]
print('The non-anomalies default on %0.2f%% of loans' % (100 * non_anom['TARGET'].mean()))
print('The anomalies default on %0.2f%% of loans' % (100 * anom['TARGET'].mean()))
print('There are %d anomalous days of employment' % len(anom))
非常有趣! 事实证明,异常情况的违约率较低。
处理异常情况取决于具体情况,没有设置规则。 最安全的方法之一就是将异常设置为缺失值,然后在机器学习之前填充(使用插补)。 在这种情况下,由于所有的异常都具有完全相同的价值,我们希望用相同的价值填充它们以防所有这些贷款共享相同的东西。 异常值似乎有一些重要性,所以我们想告诉机器学习模型,如果我们确实填写了这些值。 作为一个解决方案,我们将用不是一个数字(np.nan)填充异常值,然后创建一个新的布尔列来指示值是否异常。
# Create an anomalous flag column
app_train['DAYS_EMPLOYED_ANOM'] = app_train["DAYS_EMPLOYED"] == 365243
# Replace the anomalous values with nan
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment');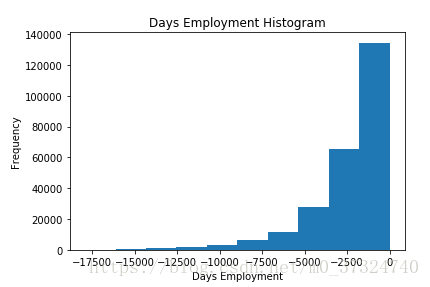
这个分布看起来更符合我们的预期,而且我们还创建了一个新的列,告诉模型这些值最初是异常的(因为我们将不得不用一些值填补nans,可能是中值的列)。 数据框中DAYS的其他列看起来与我们所期望的没有明显的异常值有关。
作为一个非常重要的笔记,我们对训练数据所做的任何事情,我们也必须对测试数据进行处理。 让我们确保创建新列,并在测试数据中用np.nan填充现有列。
app_test['DAYS_EMPLOYED_ANOM'] = app_test["DAYS_EMPLOYED"] == 365243
app_test["DAYS_EMPLOYED"].replace({365243: np.nan}, inplace = True)
print('There are %d anomalies in the test data out of %d entries' % (app_test["DAYS_EMPLOYED_ANOM"].sum(), len(app_test)))
3.2 相关性分析
现在我们已经处理了分类变量和异常值, 尝试和理解数据的一种方法是通过查找特征和目标之间的相关性。 我们可以使用.corr数据框方法计算每个变量和目标之间的 Pearson 相关系数。
相关系数并不是表示某个要素“相关性”的最佳方法,但它确实给了我们一个关于数据内可能关系的想法。 对相关系数绝对值的一些一般解释是:
- .00-.19 “very weak”
- .20-.39 “weak”
- .40-.59 “moderate”
- .60-.79 “strong”
- .80-1.0 “very strong”
# Find correlations with the target and sort
correlations = app_train.corr()['TARGET'].sort_values()
# Display correlations
print('Most Positive Correlations:\n', correlations.tail(15))
print('\nMost Negative Correlations:\n', correlations.head(15))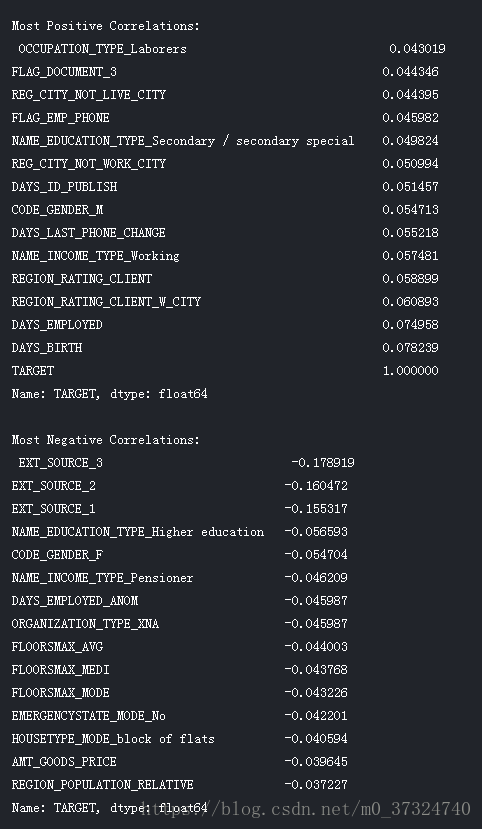
我们来看看更重要的一些相关性:DAYS_BIRTH是最正相关的。 (TARGET除外,因为变量与其本身的相关性始终为1!)查看文档,DAYS_BIRTH是负数日期内客户在贷款时间的天数(无论出于何种原因!)。 这种相关性是正向的,但是这个特征的价值实际上是负的,这意味着随着客户年龄的增长,他们不太可能违约(即目标== 0)。 这有点令人困惑,因此我们将采用该特征的绝对值,然后相关性将为负值。
3.3 年龄对还款的影响
# Find the correlation of the positive days since birth and target
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
app_train['DAYS_BIRTH'].corr(app_train['TARGET'])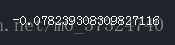
# Set the style of plots
plt.style.use('fivethirtyeight')
# Plot the distribution of ages in years
plt.hist(app_train['DAYS_BIRTH'] / 365, edgecolor = 'k', bins = 25)
plt.title('Age of Client'); plt.xlabel('Age (years)'); plt.ylabel('Count');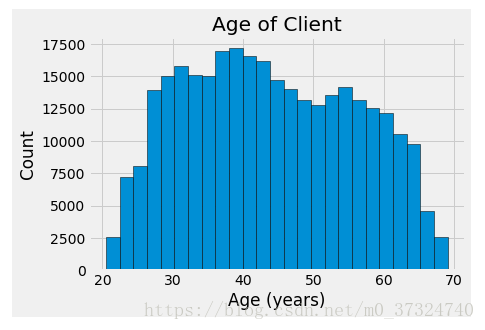
plt.figure(figsize = (10, 8))
# KDE plot of loans that were repaid on time
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'DAYS_BIRTH'] / 365, label = 'target == 0')
# KDE plot of loans which were not repaid on time
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'DAYS_BIRTH'] / 365, label = 'target == 1')
# Labeling of plot
plt.xlabel('Age (years)'); plt.ylabel('Density'); plt.title('Distribution of Ages');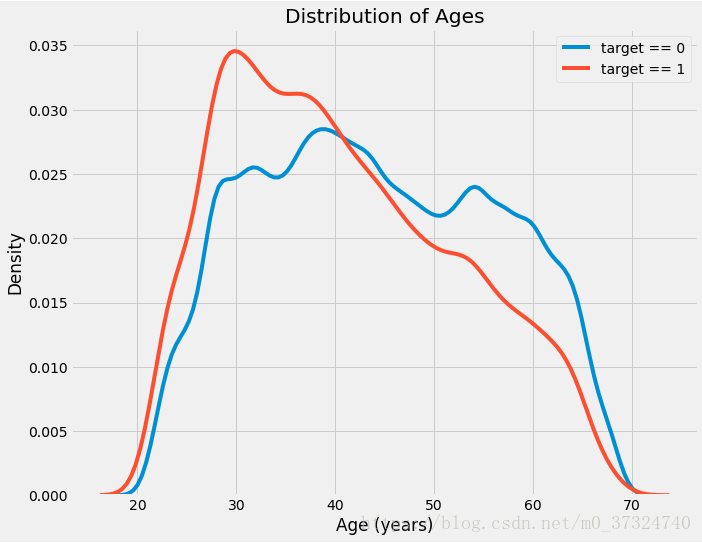
为了制作这个图表,我们首先将年龄类别分为5年的垃圾箱。 然后,对于每个垃圾箱,我们计算目标的平均值,它告诉我们在每个年龄段中没有偿还的贷款的比例。
# Age information into a separate dataframe
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365
# Bin the age data
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
age_data.head(10)
age_groups = age_data.groupby('YEARS_BINNED').mean()
age_groups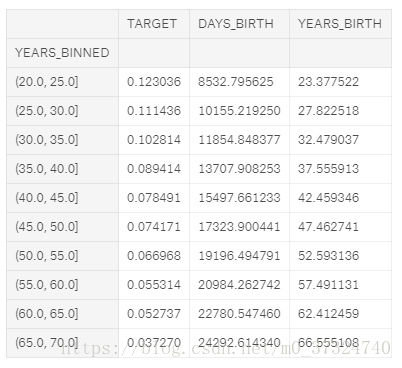
plt.figure(figsize = (8, 8))
# Graph the age bins and the average of the target as a bar plot
plt.bar(age_groups.index.astype(str), 100 * age_groups['TARGET'])
# Plot labeling
plt.xticks(rotation = 75); plt.xlabel('Age Group (years)'); plt.ylabel('Failure to Repay (%)')
plt.title('Failure to Repay by Age Group');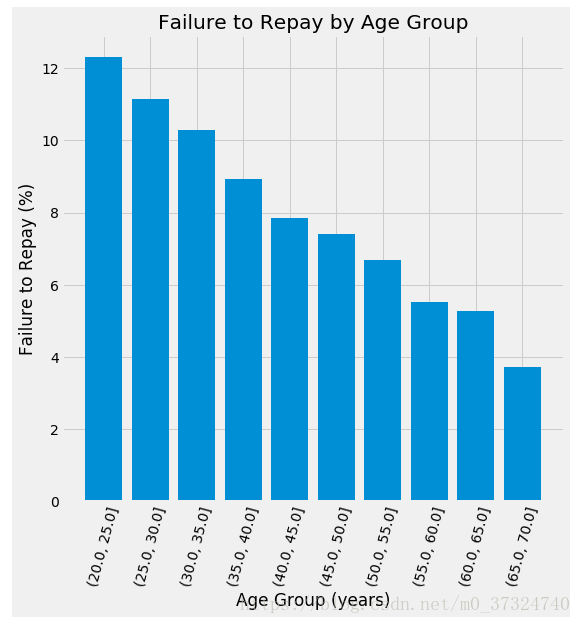
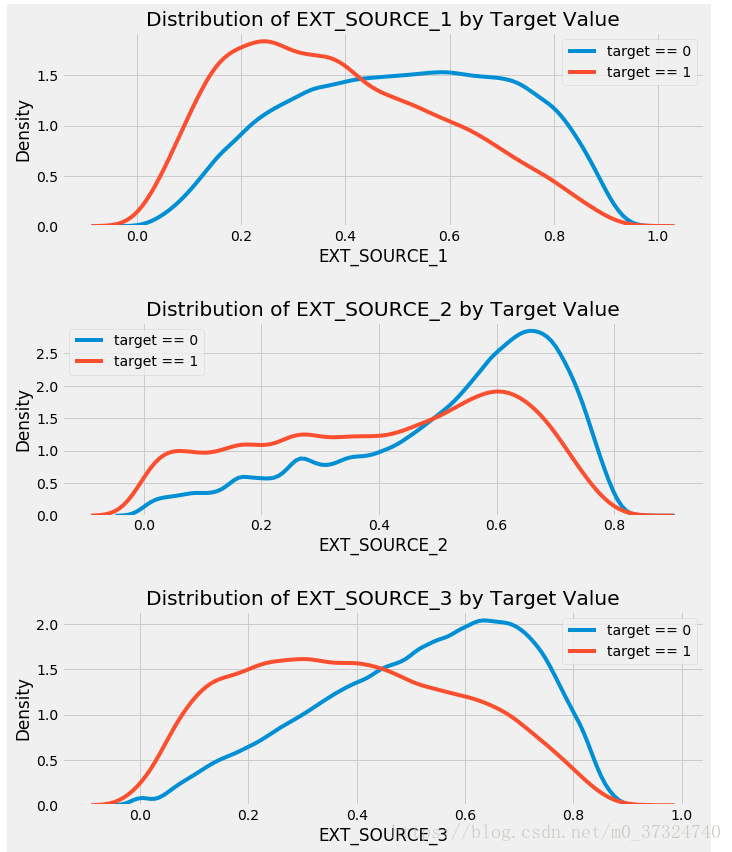
3.4 外部来源数据
我们来看看这些变量。首先,我们可以显示“EXT_SOURCE”特征与目标和相互之间的相关性。
# Extract the EXT_SOURCE variables and show correlations
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
ext_data_corrs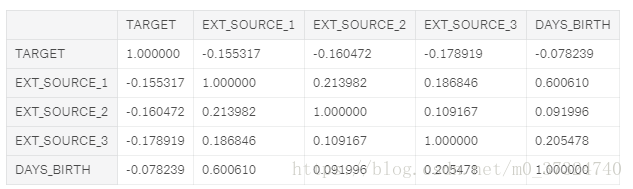
# Extract the EXT_SOURCE variables and show correlations
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
ext_data_corrs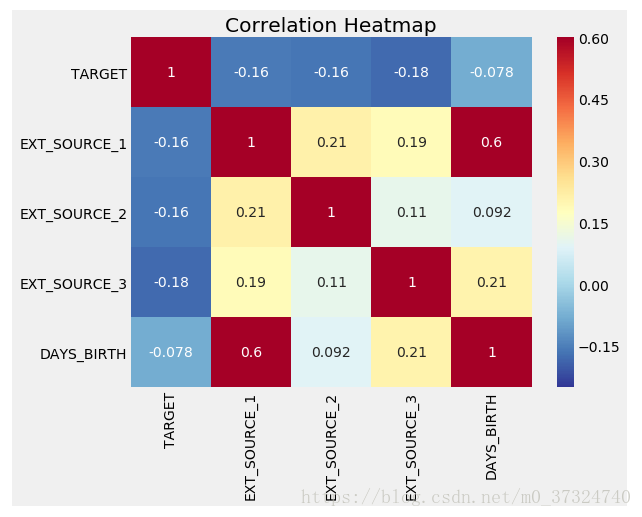
所有三个EXT_SOURCE特征与目标都有负相关,表明随着EXT_SOURCE的价值增加,客户更有可能偿还贷款。 我们还可以看到,DAYS_BIRTH与EXT_SOURCE_1正相关,表明可能是此分数中的一个因素是客户年龄。
接下来我们可以看一下这些目标值的颜色的分布。 这将让我们可视化这个变量对目标的影响。
plt.figure(figsize = (10, 12))
# iterate through the sources
for i, source in enumerate(['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']):
# create a new subplot for each source
plt.subplot(3, 1, i + 1)
# plot repaid loans
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, source], label = 'target == 0')
# plot loans that were not repaid
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, source], label = 'target == 1')
# Label the plots
plt.title('Distribution of %s by Target Value' % source)
plt.xlabel('%s' % source); plt.ylabel('Density');
plt.tight_layout(h_pad = 2.5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号