
本篇博客的目的是展示 GoogLeNet 的 Inception-v1 中的结构,顺便温习里面涉及的思想。
Going Deeper with Convolutions:http://arxiv.org/abs/1409.4842
1 版本主要思想详述
1.1 Inception v1
Inception V1 在ILSVRC 2014的比赛中,以较大优势取得了第一名,top-5错误率6.67%。Inception V1降低参数量的目的有两点,第一,参数越多模型越庞大,需要供模型学习的数据量就越大,而目前高质量的数据非常昂贵;第二,参数越多,耗费的计算资源也会更大。Inception V1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:一是去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它(用全局平均池化层取代全连接层的做法借鉴了NetworkI n Network(以下简称NIN)论文)。在相同尺寸的感受野中叠加更多的卷积,能提取到更加丰富的特征,也采用了 NIN 中的观点。
这里对传统的卷积层结构做个介绍,原理如下所示:
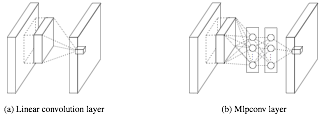
左侧是是传统的卷积层结构(线性卷积),在一个尺度上只有一次卷积;右图是Network in Network结构(NIN结构),先进行一次普通的卷积(比如3x3),紧跟再进行一次1x1的卷积,对于某个像素点来说1x1卷积等效于该像素点在所有特征上进行一次全连接的计算,所以右侧图的1x1卷积画成了全连接层的形式,需要注意的是NIN结构中无论是第一个3x3卷积还是新增的1x1卷积,后面都紧跟着激活函数(比如relu)。将两个卷积串联,就能组合出更多的非线性特征。举个例子,假设第1个3x3卷积+激活函数近似于f1(x)=ax2+bx+c,第二个1x1卷积+激活函数近似于f2(x)=mx2+nx+q,那f1(x)和f2(f1(x))比哪个非线性更强,更能模拟非线性的特征?答案是显而易见的。
1.1.1 结构原理
Inception架构的主要想法是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。注意假设转换不变性,这意味着我们的网络将以卷积构建块为基础。我们所需要做的是找到最优的局部构造并在空间上重复它。
为了避免块校正的问题,目前Inception架构形式的滤波器的尺寸仅限于1×1、3×3、5×5,这个决定更多的是基于便易性而不是必要性。另外,由于池化操作对于目前卷积网络的成功至关重要,因此建议在每个这样的阶段添加一个替代的并行池化路径应该也应该具有额外的有益效果。其原理如下图所示:

第一个分支对输入进行1*1的卷积,它可以进行跨通道的特征变换,提高网络的表达能力,同时可以对输出通道升维和降维;
第二个分支先使用了1*1卷积,然后连接3*3卷积,相当于进行了两次特征变换;
第三个分支先是1*1的卷积,然后连接5*5卷积;
第四个分支则是3*3最大池化后直接使用1*1卷积;
Inception Module的4个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。
其中:
在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。
1*1的卷积作用:
- 可以进行跨通道的特征变换,把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,提高网络的表达能力;
- 同时可以对输出通道升维(拉伸)和降维(压缩),计算量小。
多尺度卷积再聚合的作用:
- 直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。
- 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
- Hebbin赫布原理。用在inception结构中就是要把相关性强的特征汇聚到一起。有点像上面提到的这点。
总的来说,Inception Module中包含了3种不同尺寸的卷积和1个最大池化,增加了网络对不同尺度的适应性,让网络的深度和宽度高效率地扩充,提升准确率且不致于过拟合。
1.1.2 网络结构
Inception Net有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化(实际上这在低级的层级上处理用处不大),对于整个Inception Net的训练很有裨益。其完整结构如下所示:

参考资料:
https://blog.csdn.net/marsjhao/article/details/73088850
https://www.zhihu.com/people/zhang-lei-63-74-59/posts
Going Deeper with Convolutions:http://arxiv.org/abs/1409.4842

 浙公网安备 33010602011771号
浙公网安备 33010602011771号