基于Word2Vec的诗词生成器
 基于Word2Vec制作的诗词生成器
基于Word2Vec制作的诗词生成器
基于Word2Vec制作的诗词生成器
1、什么是Word2Vec?
Word2vec 是 Word Embedding 方式之一,属于 NLP 领域。它是从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。
Word2Vec是将词转化为“可计算”“结构化”的向量的过程,是用来生成词向量的工具,而词向量与语言模型有着密切的关系。
2、基于Word2Vec的诗词生成器的结构
|——GUI诗词生成器.py
|——w_poem.py
|——mo.txt
|——诗词库.txt
GUI诗词生成器.py :GUI界面,用来获取用户输入关键字和作者名,和获取w_poem.py生成的诗词并转换成标签显示在GUI界面
w_poem.py :两个函数,save_model函数用来保存训练数据,write_poem函数调用Word2Vec生成的训练数据,查找与用户输入的关键字相似度最高的词语,根据要求组装成诗词。
mo.txt :保存训练数据
诗词库.txt :原始数据
3、成品
还没有加别的规则和算法,所以得到的诗词并不优美。
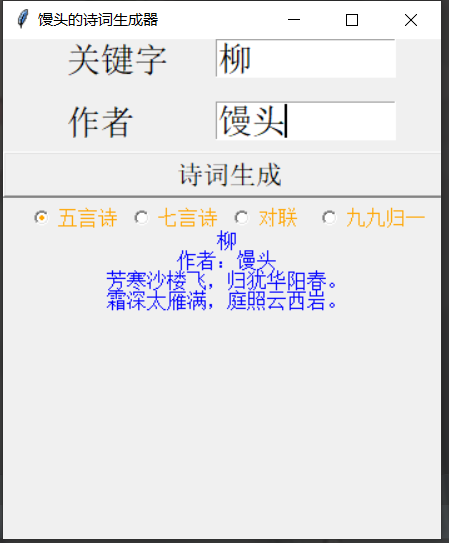
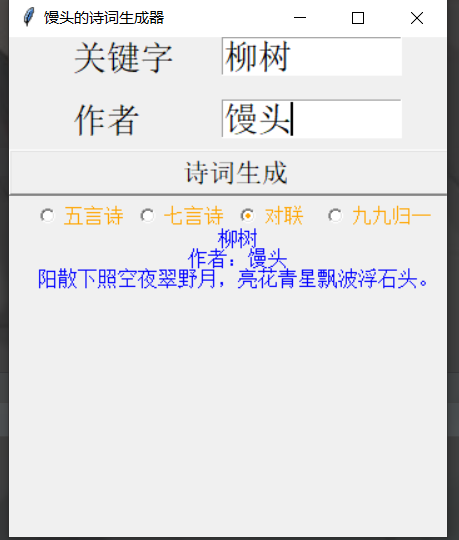
4、代码
GUI诗词生成器.py
from tkinter import *
import w_poem
# 创建窗口:实例化一个窗口对象。
class TKK:
def __init__(self):
self.root = Tk()
# 窗口大小
self.root.geometry("350x400+374+182")
# 窗口标题
self.root.title("馒头的诗词生成器")
# 添加关键字标签控件
label = Label(self.root, text=" 关键字 ", font=("宋体", 20))
label.place(x=20,y=0)
# 关键字输入框
self.entry1 = Entry(self.root, font=("宋体", 20), width=10 )
self.entry1.place(x=170,y=0)
#添加作者标签
label = Label(self.root, text=" 作者 ", font=("宋体", 20))
label.place(x=20,y=50)
# 作者输入框
self.entry2 = Entry(self.root, font=("宋体", 20), width=10)
self.entry2.place(x=170,y=50)
# 添加点击按钮
button = Button(self.root, text="诗词生成", width=32,font=("宋体", 16), command=self.getpoem) # command=textt
button.place(x=0,y=90)
# 单选按钮
self.radio = IntVar()
r1 = Radiobutton(self.root, text="五言诗", font=("宋体", 12), fg="orange", variable=self.radio, value=0)
r1.place(x=20,y=130)
r2 = Radiobutton(self.root, text="七言诗", font=("宋体", 12), fg="orange", variable=self.radio, value=1)
r2.place(x=100,y=130)
r3 = Radiobutton(self.root, text="对联", font=("宋体", 12), fg="orange", variable=self.radio, value=2)
r3.place(x=180,y=130)
r5 = Radiobutton(self.root, text="九九归一", font=("宋体", 12), fg="orange", variable=self.radio, value=3)
r5.place(x=250,y=130)
# 显示窗口
self.root.mainloop()
def getpoem(self):
list_radio = ["五言诗", "七言诗", "对联", "九九归一"]
types = (list_radio[self.radio.get()])
kw = self.entry1.get()
xx = [20 if types=="对联" else 80]
poem_name = self.entry2.get()
te = w_poem.witer_poem(kw ,types,poem_name)
text = Label(text=te,font=("宋体", 12),fg="blue")
text.place(x=xx, y=150)
if __name__ == '__main__':
tkk = TKK
tkk()
w_poem.py
from random import choice
from gensim.models import Word2Vec
def save_model():
# 保存训练数据
with open("诗词库.txt", 'r', encoding='utf-8') as f:
words = [list(line.strip()) for line in f]
##window=16滑窗大小, min_count = 60过滤低频字
model = Word2Vec(sentences=words, min_count=60, vector_size=200, window=16,)
model.save("mo.txt")
def witer_poem(kw, types, poem_name):
typp = {"五言诗": (4, 5), "七言诗": (4, 7), "九九归一": (9, 9), "对联": (2, 9)}
types = typp[types]
shici = list(kw)
# 调用训练数据
model = Word2Vec.load("mo.txt")
for row in range(types[0]):
for col in range(types[1]):
# 查找相似度最高的100个字-topn
pred = model.predict_output_word(context_words_list=shici, topn=100)
# 去除特殊符号
fu = [",", ".","?","‘","“","-","+","=","。","/",";",";",":","[","]",
"{","}","!","@","#","$","%","^","&","*","(",")","、","《","》"]
number = ["1","2","3","4","5","6","7","8","9","0"," ","!"]
rs = [w[0] for w in pred if w[0] not in shici + fu + number]
char = choice([c for c in rs if c not in kw])
shici.append(char)
# 添加标点符号
shici.append("," if row % 2 == 0 and types[0] % 2 == 0 else "。\n")
# 分段显示
sclen = types[0] * (types[1] + 1) # 计算诗词的长度,然后使用-sclen,来找到诗词标题的位置
# 如果是偶数句,则两句一行,否则一行一句
if types[0] % 2 == 0:
# 排版----->第一行题目 第二行作者 剩下的为诗词
last = "%s" % "".join(shici[:-sclen]) + "\n" + \
"作者:" + poem_name + "\n" + \
"".join(shici[-sclen:])
else:
last = "%s" % "".join(shici[:-sclen]) + "\n" + \
"作者:" + poem_name + "\n" + \
"".join(shici[-sclen:])
return last


 浙公网安备 33010602011771号
浙公网安备 33010602011771号