
web安全之自己写一个扫描器
 第一次写扫描器,技术很菜,还请师傅们多多指教
第一次写扫描器,技术很菜,还请师傅们多多指教
web安全之自己写一个扫描器
自己来写一个简单的目录扫描器,了解扫描器的运转机制和原理,因为python写脚本比较容易所以用python写一个网站目录扫描器。
第一步:我们需要导入所需要的库
1 import threading 2 import argparse 3 import requests 4 import linecache
第二步:定义一些循环变量和字典,方便多进程使用
number_c=0 dir = open("dicc.txt", "r", encoding="UTF-8") len = len(dir.readlines()) print("二十个线程--开始运行......")
第三步:编写class,导入网页url和线程的
1 class dirscan: 2 def __init__(self,url): 3 self.url = url
第四步:请求,返回状态吗为200的打印出来

1 def run(self): 2 global number_c 3 global len 4 while number_c<len: 5 number_c += 1 6 i = linecache.getline(r'dicc.txt',number_c) 7 self.lurl = self.url+i 8 html_result = requests.get(self.lurl) 9 if (html_result.status_code == 200): 10 print("存在",self.lurl)
第五步:使用命令行获取网站url,并开始多线程扫描
1 if __name__ == '__main__': 2 parser = argparse.ArgumentParser() 3 parser.add_argument('url') # add_argument()指定程序可以接受的命令行选项 4 args = parser.parse_args() # parse_args()从指定的选项中返回一些数据 5 vehicles = [] 6 for num in range(20): # 设置线程 7 scan = dirscan(args.url) 8 vehicle = threading.Thread(target=scan.run,) # 新建线程 9 vehicles.append(vehicle) 10 for vehicle in vehicles: 11 vehicle.start() # 分别启动线程 12 for vehicle in vehicles: 13 vehicle.join() # 分别检查结束线程 14 print("运行结束")
成品展示
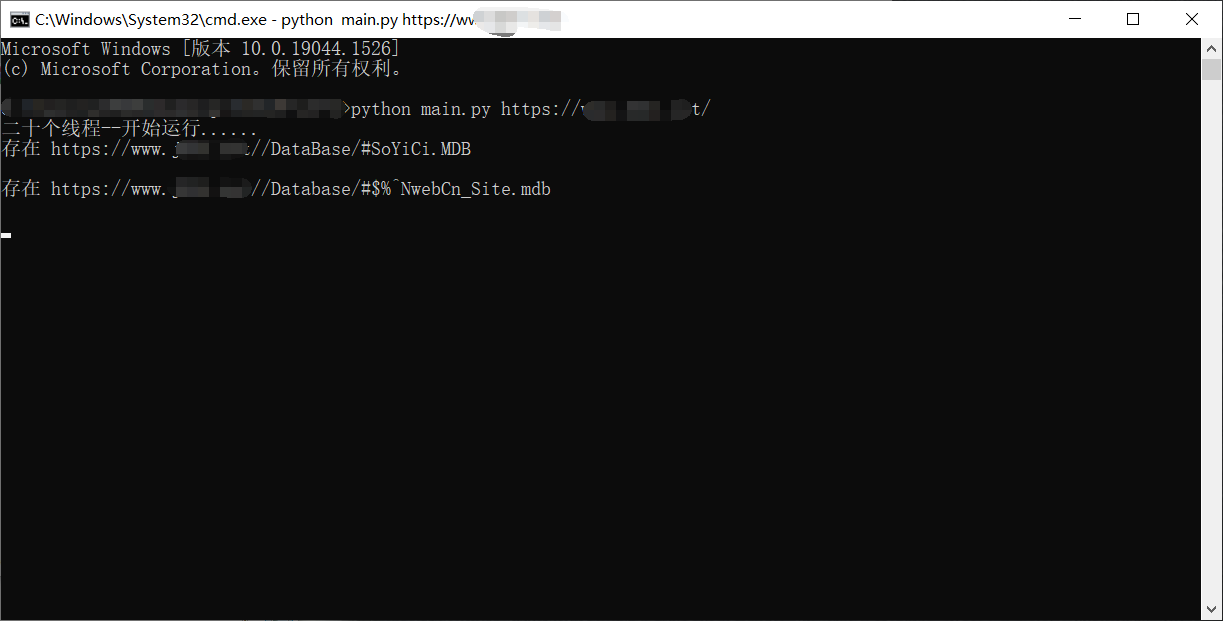
第一次写扫描器,技术很菜,还请师傅们多多指教

如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。
本文作者:mt0u的Blog
本文链接:https://www.cnblogs.com/mt0u/p/15972639.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步