
[翻译]特征选择:比特征本身重要么?
[翻译]特征选择:比特征本身重要么?
翻译:Feature Selection: Beyond feature importance?
作者:Dor Amir
关键词:特征工程(feature selection)
在机器学习中,特征选择就是选择对于你的预测任务最有用的特征的过程。尽管这听起来很简单,但这是在创建一个新的机器学习模型过程中最复杂的问题之一。
在本文中,我将与你分享一些方法,这些方法是我在Fiverr公司领导的一个项目中的研究。
你将得到一些关于我尝试的基本方法和更复杂方法的一些想法,这些方法得到了最好的结果,就是移除60%的特征,同时保持准确性和实现了模型的更鲁棒性。我也将分享我们对于该算法的改进。
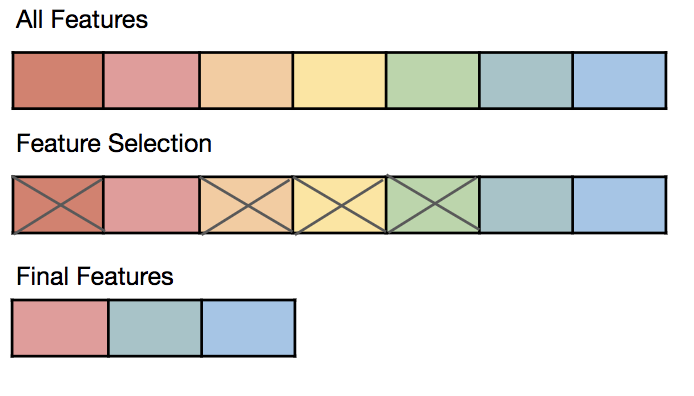
图1 通过特征选择,只保留40%的特征,可以达到相同的效果
为什么进行特征选择如此重要
如果你创建一个机器学习模型,你应该知道辨别哪些特征是重要的,哪些是噪声是很困难的。
移除噪声特征将有助于内存、计算成本和你模型的准确性。另外,通过移除一些特征,将帮忙你的模型避免过拟合。
有时,一个特征有自己业务上的含义,但是,这不意味着这个特征可以帮助你进行预测。你需要记得,特征在一个算法中有用(例如决策树),可能在另个算法中就代表性不足(例如回归模型)。并不是所有特征都是一样的。
不相关或者部分相关的特征可能对于模型的性能有负面的影响。特征选择和数据清洗应该是设计模型中的第一步,也是最重要的一步。
特征选择的方法
尽管有许多特征选择的技术,例如后向消除(backward elimination), 套索回归( lasso regression). 在本文中,我将分享3种方法,这些方法在进行更好的特征选择中是最有用的,每一个方法有它自身的优势。
“All But X”
“All But X” 方法的名字是在Fiverr时给的。这个技术简单但是有用。
-
你可以在迭代中反复训练和评估
-
在每一次迭代中,移除一个特征。
如果你有大量的特征,你可以移除一组特征 -- 在Fiver,我们通常用不同的时间聚合得到特征,如30天点击次数,60天点击次数等等,这个就是一组特征。
-
根据准则来检查你的评估指标。
这个技术的目标是检测哪一组特征对评估结果不起作用,或者甚至移除这一组特征可以提高评估结果。
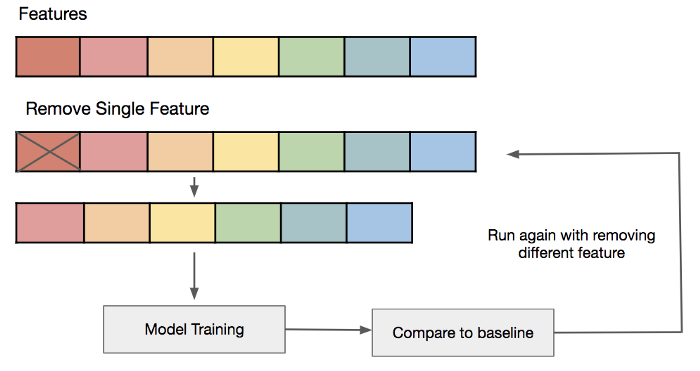
图2 “All But X”方法执行全流程的流程图。在执行完全部迭代后,我们比较哪组特征对于模型的准确性没有影响。
这个方法的问题在于通过一次移除一个特征,你不会了解特征之间的作用(非线性作用)。也许特征X和特征Y的组合在产生噪声,不仅仅是特征X.
特征重要性+随机特征
我们尝试的另个方法是使用特征重要性,特征重要性是大部分机器学习模型API都有的功能。
我们所做的不仅仅是选取头部N个(top N)重要的特征。我们向数据中添加了3个随机特征:
- 二进制随机特征(0或1)
- 0到1的均匀分布的随机特征
- 整数随机特征
在特征重要性列表中,我们只选择重要性比3个随机特征更高的特征。
随机特征选取不同的分布是重要的,不同的分布有不同的效果。
在树模型中,模型“更喜欢”连续型特征(因为划分),所以这些特征将位于层次结构中更高的位置。因此,你需要将每一个特征和其均匀分布的随机特征进行比较。
Boruta
Boruta是一种特征排名和选择的算法,是由Warsaw大学开发的。该算法基于随机森林,但也可以使用XGBoost和其他树算法。
在Fiverr时,我使用该算法,对于XGBoost排名和分类模型有一些改进,下面将简要介绍。
该算法是上面提到的两个方法的一种组合。
- 为数据集中每一个特征创建一个"shadow"特征,有相同的特征值,但是对行进行混洗(shuffled)
- 循环运行,直到有停止条件之一
- 没有移除任何特征
- 移除足够多的特征 -- 我们想要移除60%的特征
- 执行N次迭代 -- 我们限制迭代次数来避免陷入死循环
- 执行X次迭代 -- 我们一般用5,来消除模式中的随机性
- 使用常规特征和shadow特征来训练模型
- 保存每个特征的平均特征重要性得分
- 移除所有比其shadow特征得分低的特征
Boruta伪代码
def _create_shadow(x):
"""
Take all X variables, creating copies and randomly shuffling them
:param x: the dataframe to create shadow features on
:return: dataframe 2x width and the names of the shadows for removing later
"""
x_shadow = x.copy()
for c in x_shadow.columns:
np.random.shuffle(x_shadow[c].values) # shuffle the values of each feature to all the features
# rename the shadow
shadow_names = ["shadow_feature_" + str(i + 1) for i in range(x.shape[1])]
x_shadow.columns = shadow_names
# Combine to make one new dataframe
x_new = pd.concat([x, x_shadow], axis=1)
return x_new, shadow_names
# Set up the parameters for running the model in XGBoost
param = booster_params
df = pd.DataFrame() # initial empty dataframe
for i in range(1, n_iterations + 1):
# Create the shadow variables and run the model to obtain importances
new_x, shadow_names = _create_shadow(x)
bst, df = _run_model(new_x, y, group, weights, param, num_boost_round, early_stopping_rounds, i == 1, df)
df = _check_feature_importance(bst, df, i, importance_type)
df[MEAN_COLUMN] = df.mean(axis=1)
# Split them back out
real_vars = df[~df['feature'].isin(shadow_names)]
shadow_vars = df[df['feature'].isin(
)]
# Get mean value from the shadows
mean_shadow = shadow_vars[MEAN_COLUMN].mean() * (perc / 100)
real_vars = real_vars[(real_vars[MEAN_COLUMN] > mean_shadow)]
criteria = _check_stopping_crietria(delta, real_vars, x)
return criteria, real_vars['feature']
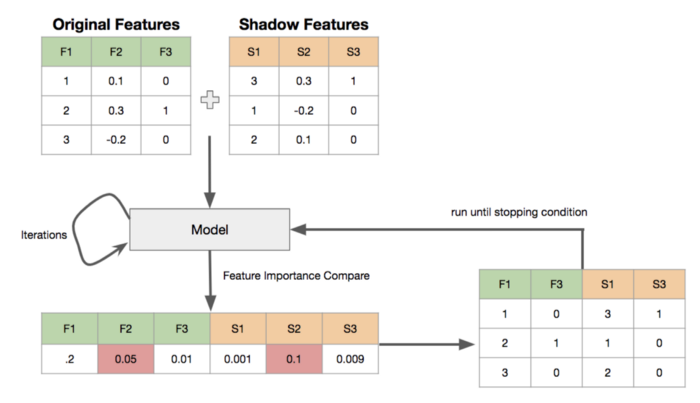
图3 Boruta执行流程图,从创建shadows -- 训练 -- 比较 -- 移除特征并返回继续。
Boruta 2.0
这是本文最好的部分,我们对于Boruta的改进。
我用原始模型的“简短版本”来运行Boruta。通过获取数据的样本和使用较少数量的树(我们使用的XGBoost),在没有降低准确性的条件下,我们改善了原始Boruta的运行时间。
另一个改进是,我们用前面提到的随机特征来执行算法。可以看到我们移除了数据集中所有的随机特征,这是一个很好的停止条件。
有了这些改进,对于模型在准确性上也没有影响,但是在运行时间上有改进。通过移除,我们能将特征从200+转变到少于70。我们能看到模型在树的数量和不同训练期间的的稳定性。
我们也能看到在训练集和验证集上,对于损失的提升。
改进的Boruta和Boruta的优势在于你在运行模型。在这种情况下,发现的有问题的特征对你的模型有问题而不是一个不同的算法。
总结
在本文中,你看到了3种不同的技术,该技术是关于对数据集进行特征选择和如何构建一个有效的预测模型的技术。你看到Boruta的实现,在运行时间上的改进和添加随机特征来进行合理性测试(sanity checks).
通过这些改进,我们的模型能运行地更快,更鲁棒以及保持同样的准确性,只用35%的原始特征。
选择最适合你的技术。请记住,特征选择(Feature Selection)能帮助改进准确性(accuracy),鲁棒性(stability)和运行时间(runtime),并避免过拟合。更重要的是,用更少的特征使调试和解释性更容易。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号