爬虫过程中需要注意的问题
一.存储数据库
1.问题:
当保存指定字段存入数据库的时候,如果仔细查看数据库会发现,主键id是不连续的值,即使设置了失败后事务回滚,也无济于事
也就是说,不管数据是否插入成功,id都会自增1
原因:
innodb的自增是缓存在内存字典中的,分配方式是先预留,然后再插入的。所以插入失败不会回滚内存字典
解决:
让innodb识别到当前最大id的方法是重启server 更新AUTO_INCREMENT缓存
在插入失败的时候,将主键重新赋值为1,数据库就会将下一个自增id设置为当前表中最大的id加1
alter table haowai auto_increment=1 #haowai只是表名
例:scrapy框架的pipelines.py文件
class HaowaiPipeline(object): def open_spider(self,spider): self.db = pymysql.connect('127.0.0.1','root','123456','reptile',charset="utf8") self.cursor = self.db.cursor() def process_item(self, item, spider): sql = 'insert into haowai(url,title,author,content,puttime,readnum,imagepath) values(%s,%s,%s,%s,%s,%s,%s)' data = (item['url'],item['title'],item['author'],item['content'],item['puttime'],item['readNum'],item['imagePath']) try: self.cursor.execute(sql,data) self.db.commit() except Exception as e: # 插入失败则将主键自增设置为1,否则插入数据失败id也会自增,就会出现主键增长不连续的情况 self.cursor.execute('alter table haowai auto_increment=1') self.db.rollback() print('存储失败',e) return item def close_spider(self,spider): self.cursor.close() self.db.close()
二.请求百度首页返回一个错误的页面,如下:
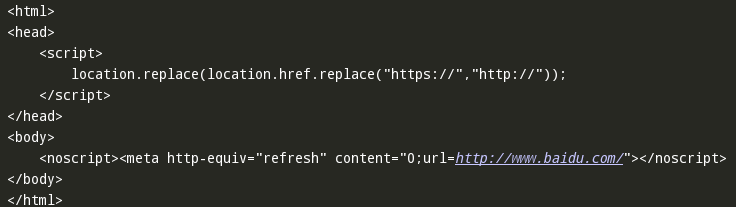
源代码如下:
from urllib import request url = 'https://www.baidu.com' response = request.urlopen(url) html = response.read().decode('utf-8') print(html)
原来以为是ssl验证的问题,后来加上了也不对,最后竟然是一个请求头的事
修改后的源代码如下:
from urllib import request url = 'https://www.baidu.com' head = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36" } req = request.Request(url,headers=head) response = request.urlopen(req) html = response.read().decode('utf-8') print(html)
添加请求头后,返回了百度首页
唉!·······

 浙公网安备 33010602011771号
浙公网安备 33010602011771号