Python-多线程之消费者模式和GIL全局锁
一.生产者和消费者模式
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,
所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当
于一个缓冲区,平衡了生产者和消费者的处理能力。基于队列实现生产者消费者模型
定义:
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。
模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
案例:
厨师做包子和顾客吃包子问题。
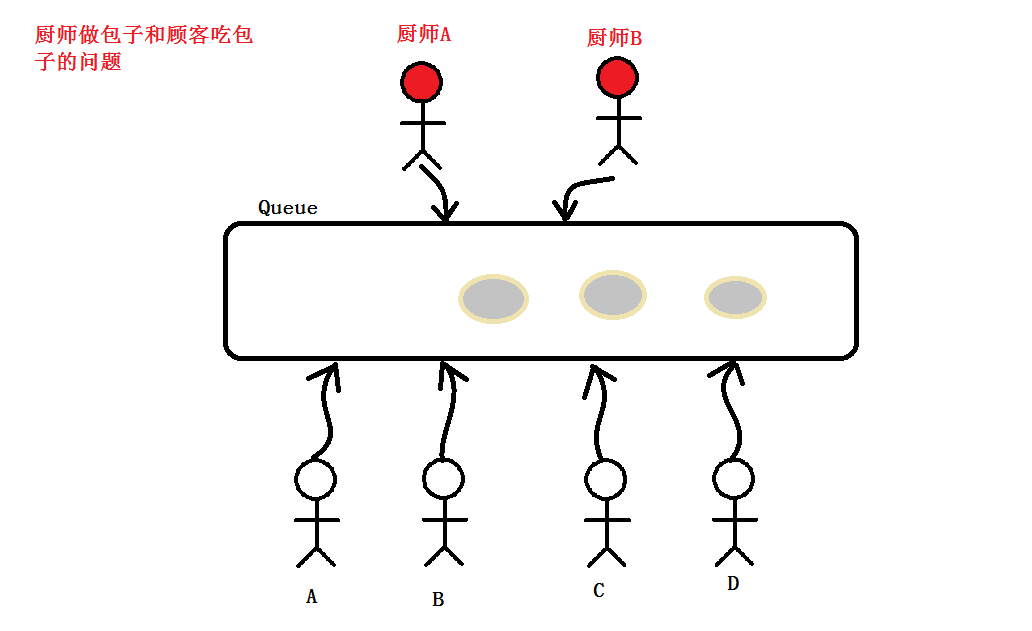
# 一对多 一个大厨对多个顾客 import threading import queue import time q = queue.Queue(maxsize=10) #生产者 def producer(name): count = 1 while True: q.put("包子%d"%count) print("生产了包子%d"%count) count += 1 time.sleep(0.8) #消费者 def consumer(name): count = 1 while True: print("[%s]取到了[%s]并且吃了它。。。"%(name,q.get())) time.sleep(2) if __name__ == '__main__': p = threading.Thread(target=producer,args=("刘大厨",)) a = threading.Thread(target=consumer,args=("A",)) b = threading.Thread(target=consumer,args=("B",)) p.start() a.start() b.start()
# 多对多 多个大厨对多个顾客 import threading import queue import time,random q = queue.Queue(maxsize=10) count = 1 #生产者 def producer(name): global count while True: # if mutex.acquire(): # q.put("包子%d"%count) # print("%s生产了包子%d"%(name,count)) # count += 1 # time.sleep(random.random()*10) # mutex.release() q.put("包子%d" % count) print("%s生产了包子%d" % (name, count)) count += 1 time.sleep(random.random() * 10) #消费者 def consumer(name): count = 1 while True: print("[%s]取到了[%s]并且吃了它。。。"%(name,q.get())) time.sleep(random.random() * 10) if __name__ == '__main__': mutex = threading.Lock() p1 = threading.Thread(target=producer,args=("刘大厨",)) p2 = threading.Thread(target=producer,args=("李大厨",)) a = threading.Thread(target=consumer,args=("A",)) b = threading.Thread(target=consumer,args=("B",)) c = threading.Thread(target=consumer,args=("C",)) d = threading.Thread(target=consumer,args=("D",)) p1.start() p2.start() a.start() b.start() c.start() d.start()
队列:
队列的使用,Python的Queue模块中提供了同步的、线程安全的队列类
FIFO(先入先出)队列 格式:q = queue.Queue()
LIFO(后入先出)队列 格式: q = queue.LifoQueue()
priority 优先级队列 格式: q = queue.PriorityQueue()
向队列中添加数据 q.put(1,'a'), 1代表优先级,越小优先级越高,也可以设置成负数 即优先级越小,越先出来
这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么就做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,
那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了
解决这个问题于是引入了生产者和消费者模式。
二.GIL(全局解释器锁)
在单线程中数2亿个数和在两个线程中分别数1亿个数,哪个效率更高?速度更快?
用事实来证明:
from threading import Thread from multiprocessing import Process import time #计数 def two_hundred_million(): start_time = time.time() i = 0 for _ in range(200000000): i = i + 1 end_time = time.time() print("Total time:{}".format(end_time - start_time)) #数1亿 def one_hundred_million(): start_time = time.time() i = 0 for _ in range(100000000): i = i + 1 end_time = time.time() print("Total time:{}".format(end_time - start_time)) if __name__ == "__main__": #单线程---主线程 #two_hundred_million() #Total time:19.491114616394043 #多线程 # for _ in range(2): # t = Thread(target=one_hundred_million) #Total time:18.768073320388794 # t.start() #Total time:18.906081438064575 #多进程 # for _ in range(2): # p = Process(target=one_hundred_million) #Total time:11.364650011062622 # p.start() #Total time:11.398651838302612
答案已经很明显了:单线程为20秒左右,两个线程分别也是20秒左右
原因很简单:GIL(全局解释器锁)
Python 代码的执行是由 Python 虚拟机(又名解释器主循环)进行控制的。Python 在 设计时是这样考虑的,在主循环中同时只能有一个控制线程在执行,
就像单核 CPU 系统 中的多进程一样。内存中可以有许多程序,但是在任意给定时刻只能有一个程序在运行。
同理,尽管 Python 解释器中可以运行多个线程,但是在任意给定时刻只有一个线程会被解释器执行。
对 Python 虚拟机的访问是由全局解释器锁(GIL)控制的。这个锁就是用来保证同时只能有一个线程运行的。在多线程环境中,Python 虚拟机将按照下面
所述的方式执行。
1. 设置 GIL。
2. 切换进一个线程去运行。
3. 执行下面操作之一。
4. 指定数量的字节码指令。
5. 线程主动让出控制权(可以调用 time.sleep(0)来完成)。
6. 把线程设置回睡眠状态(切换出线程)。
7. 解锁 GIL。
8. 重复上述步骤。
如何避免受到GIL的影响
使用进程
以上例子很明显就可以看出答案:一个单进程为20秒左右,两个进程分别为10秒左右
用multiprocess替代Thread
multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用
了多进程 而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
当然multiprocess也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量
对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocess由于进程之间无法看到对方的数据,只能通过在主线程申
明一个Queue,put再get或者用share memory的方法。这个额外的实现成本使得本来就非常痛苦的多线程程序编码,变得更加痛苦了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号