使用python selenium解决谷歌验证码(reCAPTCHA)
来自
[ 不止于python ]
简介
reCAPTCHA项目是由卡内基梅隆大学所发展的系统,主要目的是利用CAPTCHA技术来帮助典籍数字化的进行,这个项目将由书本扫描下来无法准确的被光学文字识别技术识别的文字显示在CAPTCHA问题中,让人类在回答CAPTCHA问题时用人脑加以识别[2]。reCAPTCHA正数字化《纽约时报》(New York Times)的扫描存档[3],目前已经完成20年份的资料,并希望在2010年完成110年份的资料。2009年9月17日,Google宣布收购reCAPTCHA。[4]
为了验证人类所输入的文字是正确的,而不是随意输入,有两个字会被显示出来;一个是光学文字识别软件无法辨别的字,另一个是一个已经知道正确答案的字。如果用户正确的回答出已知正确答案的字,那么就假设所输入的另一个光学识别软件无法识别的字是认真的查看后被输入而非随便输入。[5][6]
reCAPTCHA问题的所需的文字图片,首先会由reCAPTCHA项目网站利用Javascript API获取[7],在最终用户回答问题后,服务器再连回reCAPTCHA项目的主机验证用户的输入是否正确。reCAPTCHA项目提供了许多编程语言的库,让集成reCAPTCHA服务到现有程序的过程可以轻松些。除非有较大的带宽需求,否则reCAPTCHA原则上是一个免费的服务。[8]
2012年起,reCAPTCHA除了原来的文字扫描图片外,也采用Google街景拍摄的门牌号码照片。[9]
2014年年底,改以“我不是机器人”(I'm not a robot)于方框中打勾,进而完成判别。[10]并开始采用听单词的验证码模式。
2018年,Google发布reCAPTCHA v3,采用分数制验证系统,对用户在网站上的动作进行评分,若分数过低则会被判定为机器人。[11]
2020年,Google发布reCAPTCHA Enterprise,与reCAPTCHA v3相同,采用分数制验证系统,但能够提供更精细的分数以及高风险分数原因代码,以供进一步分析之用。[12][13]
来自 [维基百科]日常使用
作为一个新时代农民, 相信你或多或少见过, 就长这样

如果点击后, 发现当前系统存在风险, 会出来图片验证, 这个图片验证可能是几张图片, 点击完提交, 也有可能是点击完符合条件的图片后, 会在原位置, 出来一张新的图片, 一直点到没有符合条件的图片后, 点击提交, 像这样的
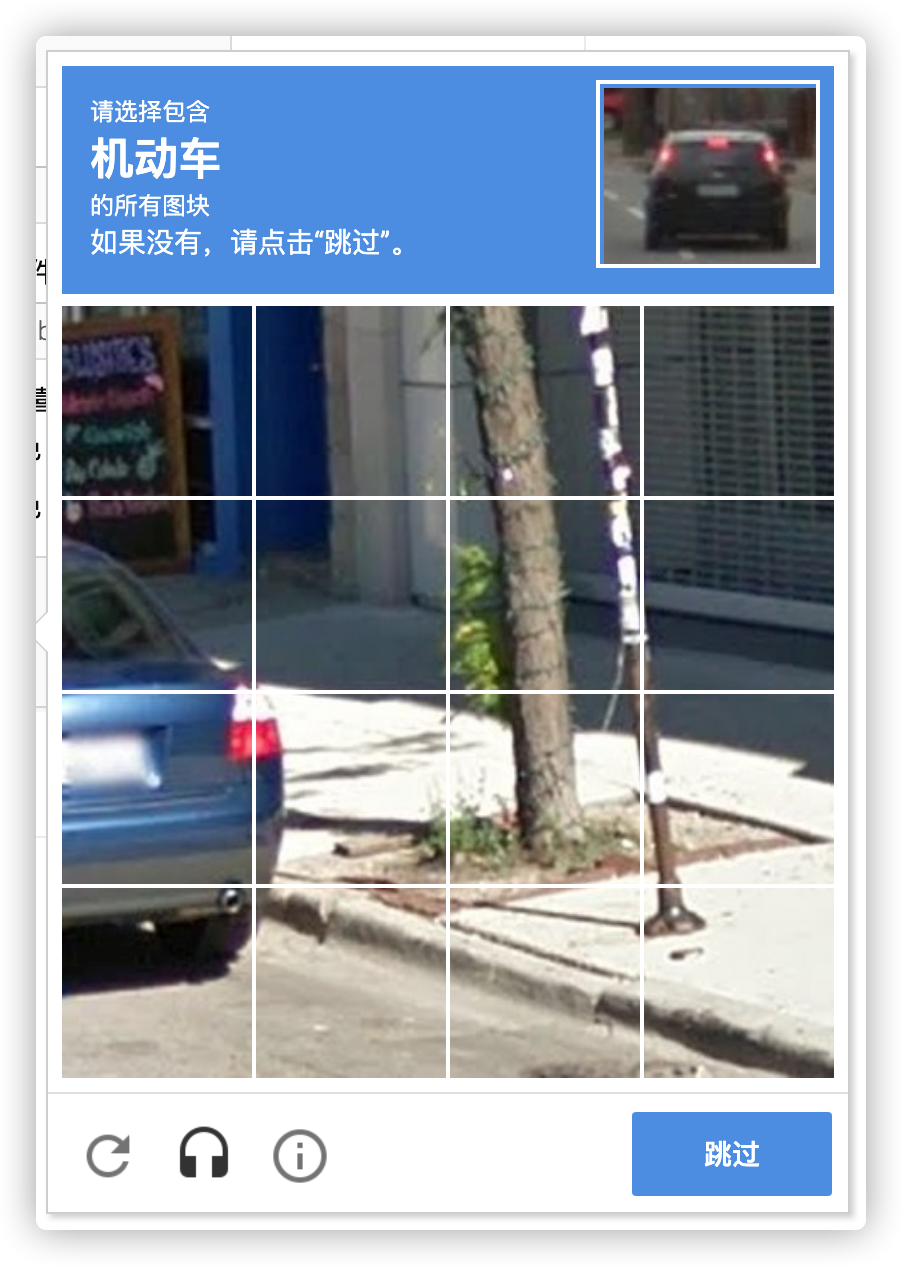
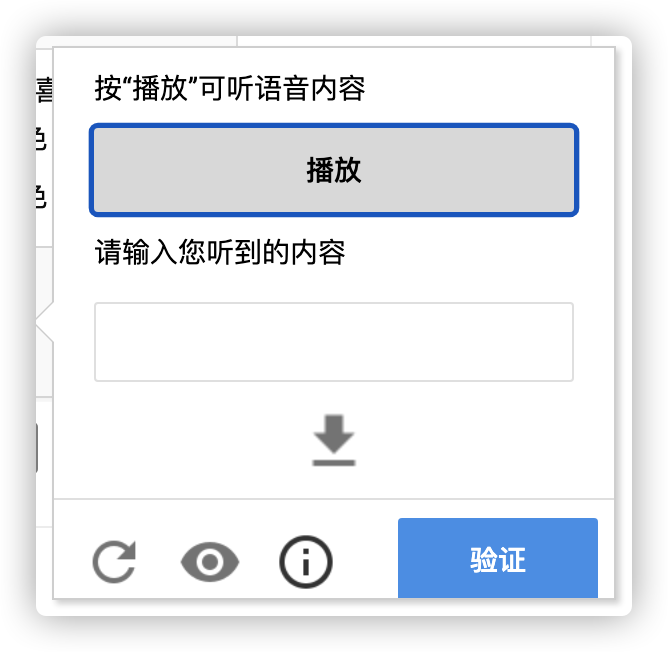
也可以点击耳机按钮, 切换到听写模式
验证码的版本
V2: 就是需要点选的, 显式的验证
V3: 是无感的验证, 是一个分数制验证系统, 根据用户行为, 计算一个分数

破解平台
- https://2captcha.com/
不但支持reCAPTCHA, 还支持 TikTok等等验证, 功能齐全, 但比较贵 - http://yescaptcha.365world.com.cn/
只支持reCAPTCHA验证, 目前V3版本验证质量一般, 价格美丽, 而且注册就送1500点数, 一次15点数, 可以调用100次, 充值的话是1元1000点
下面以yescaptcha为例, 说一下如何使用(两个平台验证流程几乎相同)
代码
以https://www.google.com/recaptcha/api2/demo 为例介绍
-
需要的值
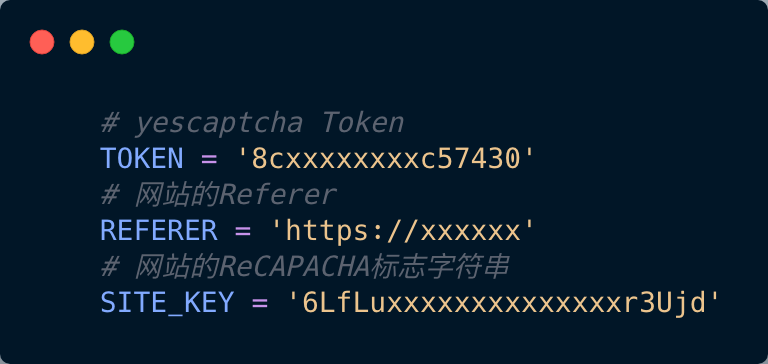
TOKEN: http://yescaptcha.365world.com.cn/ 注册后会生成一个token
REFERER: 网站验证的referer, 找到xxxx/api.js的请求
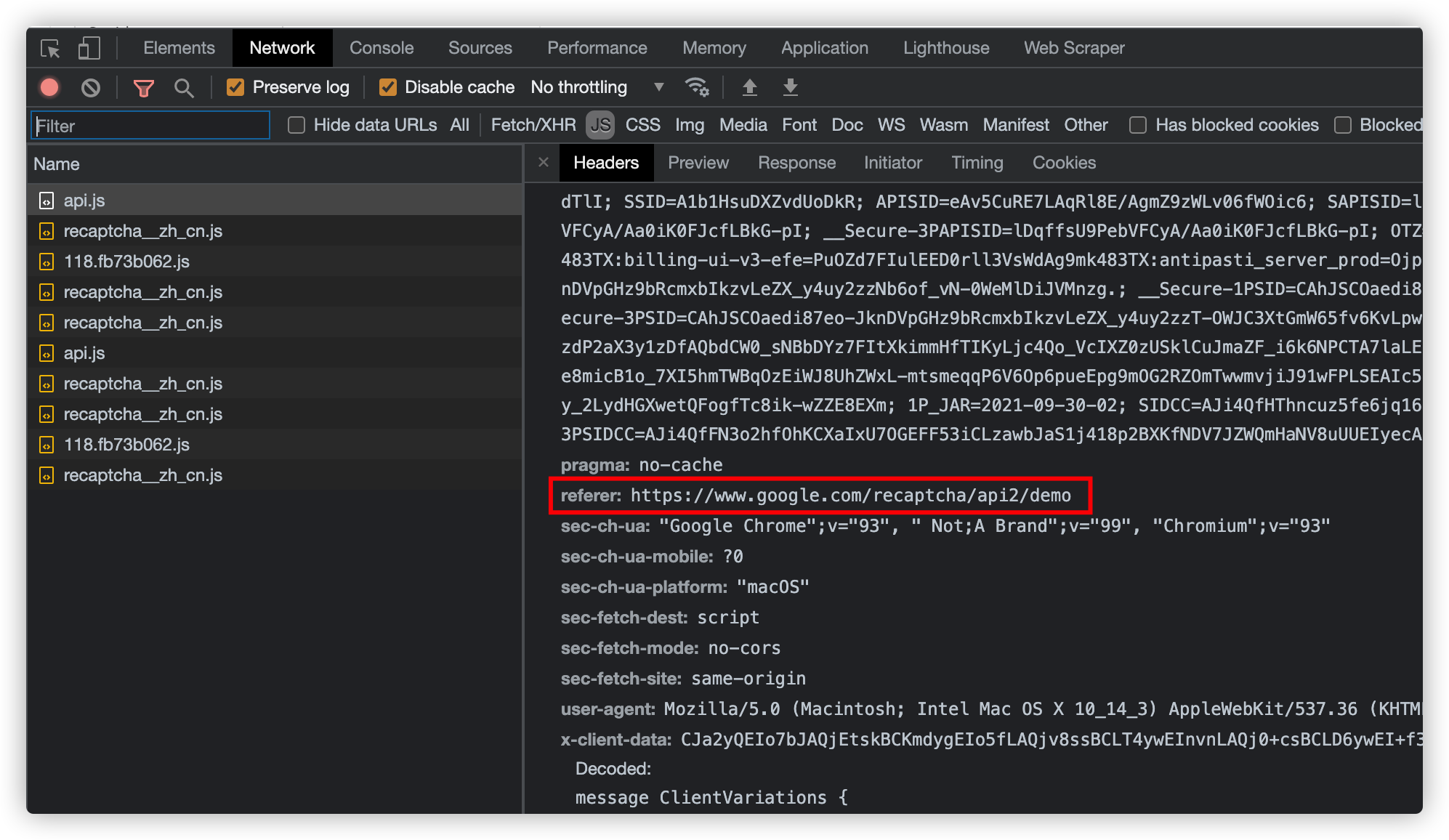
SITE_KEY: 找到ancher的请求
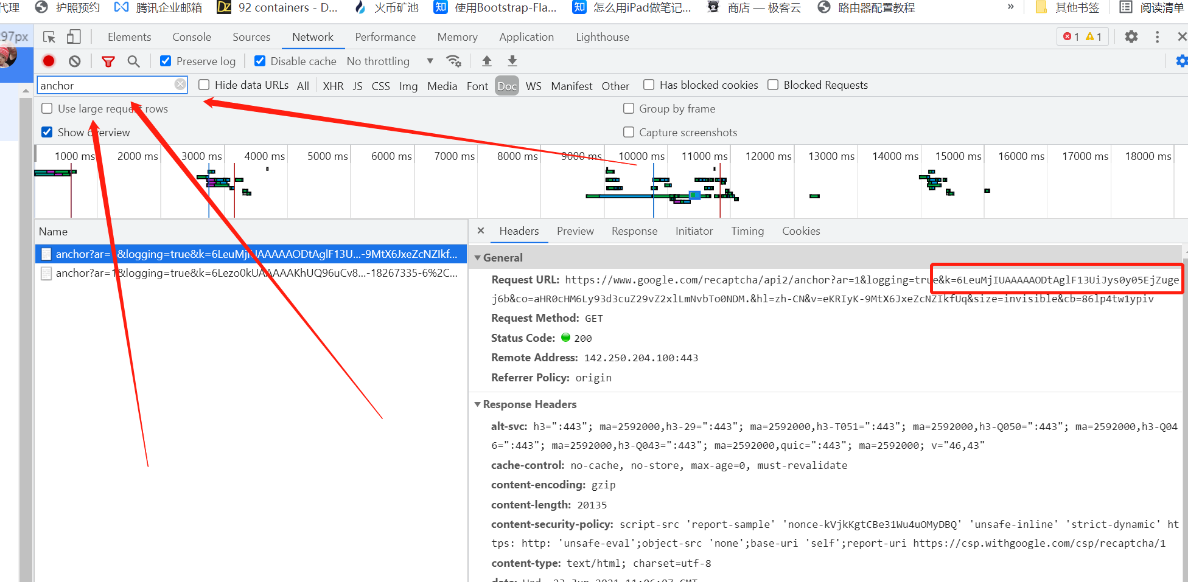
或者查看网页源代码, 找到data-sitekey

-
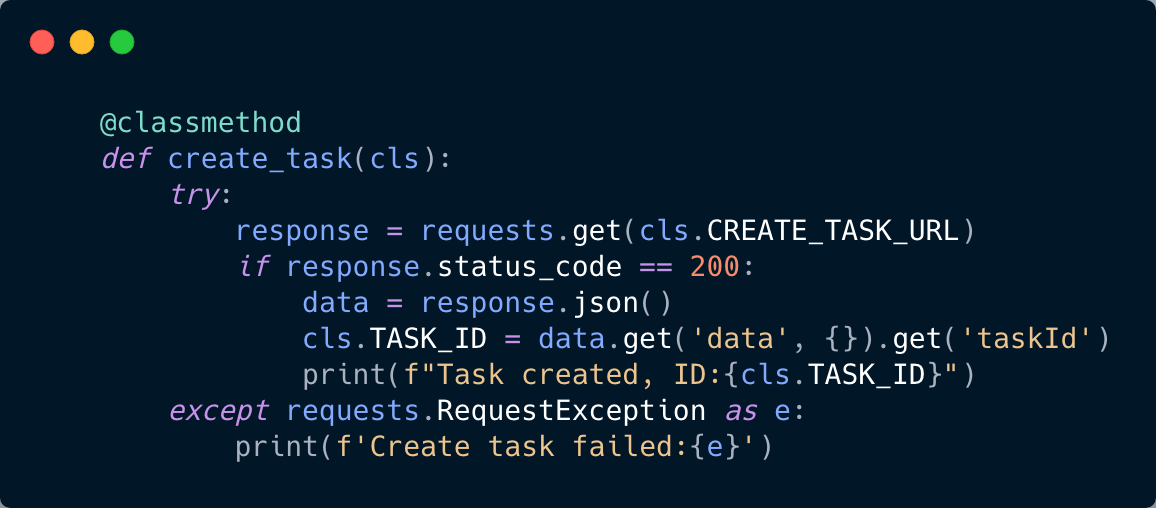
创建验证码任务
url : http://api.yescaptcha.365world.com.cn/v3/recaptcha/create
参数:
|
参数名 |
是否必须 |
说明 |
| token
|
是 |
请在个人中心获取 (Token) |
|
siteKey |
是 |
ReCaptcha SiteKey (固定参数) |
|
siteReferer |
是 |
ReCaptcha Referer (一般也为固定参数) |
|
captchaType (验证码版本) |
否 |
ReCaptchaV2(默认) / ReCaptchaV3 不知道是哪一种看后面的说明 ReCaptchaV3 V3必填 |
|
siteAction |
否 |
ReCaptchaV3 必填 Action动作 默认verify |
|
minScore |
否 |
ReCaptchaV3 选填 最小分数(0.1-0.9) |
代码
会返回一个任务id, 用于获取验证结果
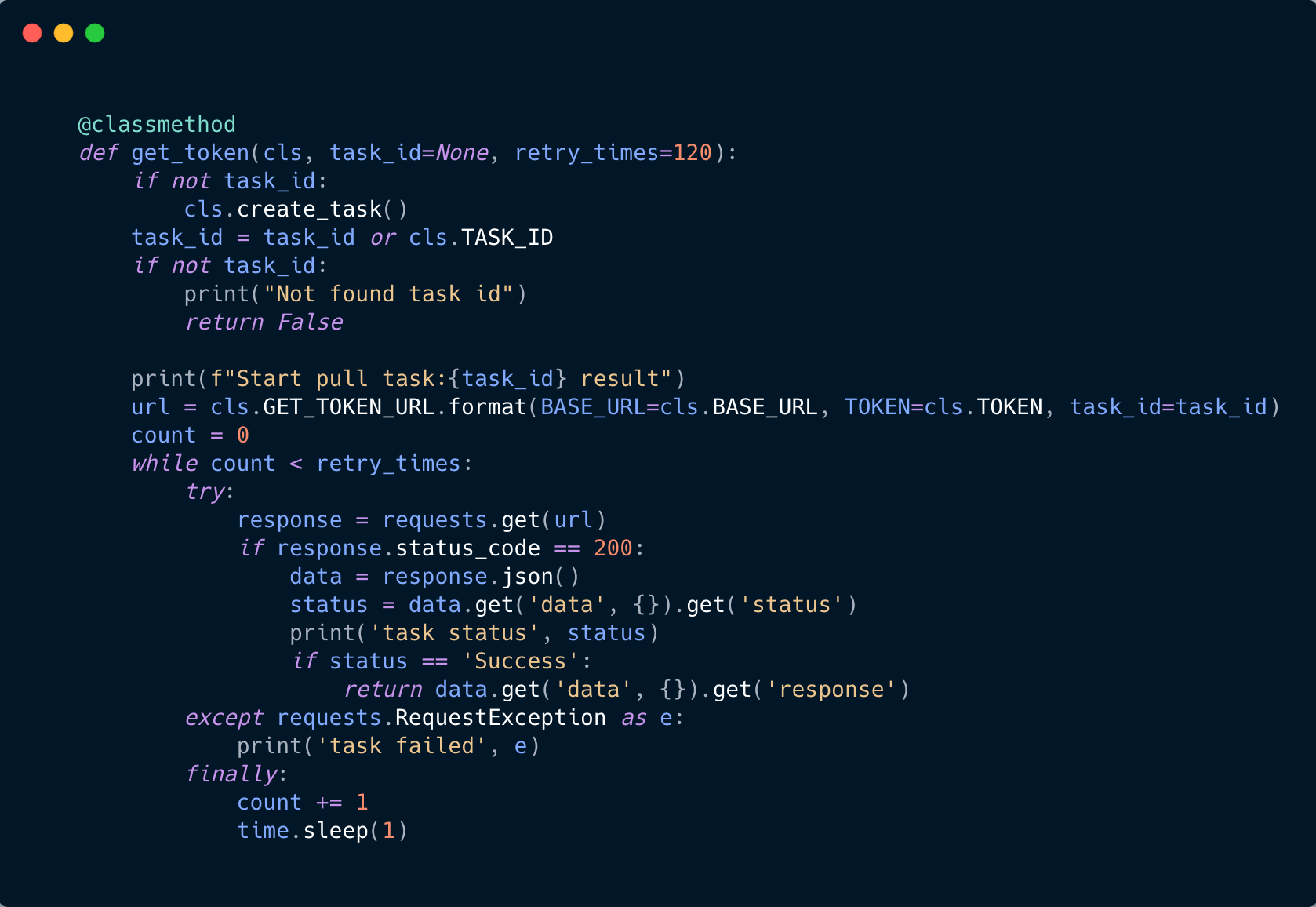
- 获取任务结果
url: http://api.yescaptcha.365world.com.cn/v3/recaptcha/status
参数:
|
参数名 |
是否必须 |
说明 |
|
taskId |
是 |
创建任务获取到的ID |
代码
使用方式及验证结果
-
用requests方式
验证结果

-
使用selenium
在页面上有两种方式
回调: 在页面上看不到点击验证, 而是在登录的时候才会调用验证
这种的就要找回调函数, 然后使用回调函数加上验证的token调用
文档: https://yescaptcha.atlassian.net/wiki/spaces/YESCAPTCHA/pages/9077039/reCaptcha
非回调:
在页面上可以看到验证, 验证完后, 然后可以点击登录, 就像我们正在验证的demo网站

代码:
https://shimowendang.com/docs/vQRuIEUiT5ocoAZ9/read
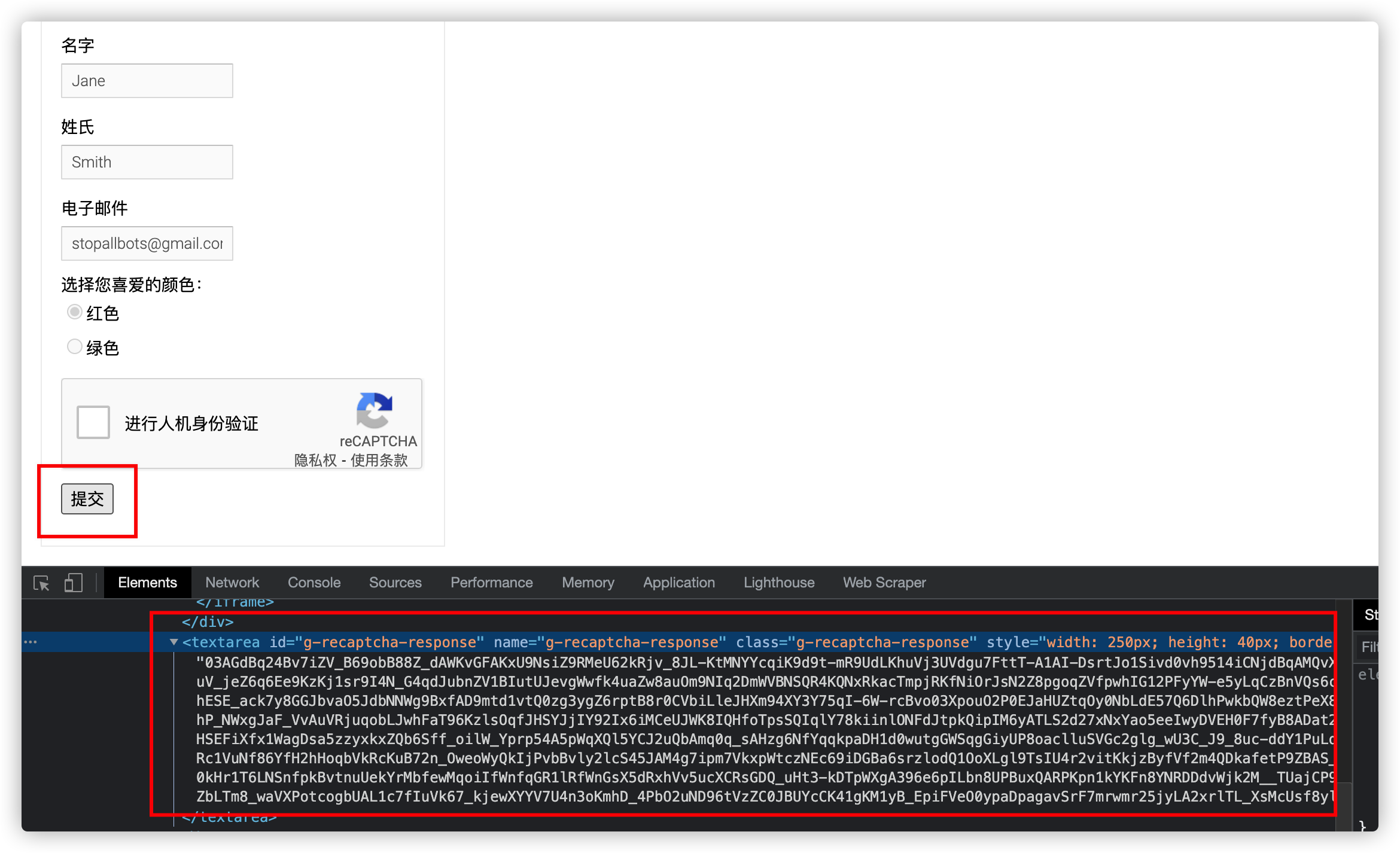
- 直接在页面上验证
打开控制台, 搜索g-recaptcha-response

这样就不验证也可以直接点击提交
跳转到验证成功页面
完整代码
# -*- coding: utf-8 -*-
import requests
import time
class ReCAPTCHA(object):
# Token
TOKEN = 'xxxxxxxxxx'
REFERER = 'https://www.google.com/recaptcha/api2/demo'
BASE_URL = 'http://api.yescaptcha.365world.com.cn'
# Site Key
SITE_KEY = '6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-'
CREATE_TASK_URL = f"{BASE_URL}/v3/recaptcha/create?token={TOKEN}&siteKey={SITE_KEY}&siteReferer={REFERER}"
GET_TOKEN_URL = "{BASE_URL}/v3/recaptcha/status?token={TOKEN}&taskId={task_id}"
TASK_ID = None
@classmethod
def create_task(cls):
try:
response = requests.get(cls.CREATE_TASK_URL)
if response.status_code == 200:
data = response.json()
cls.TASK_ID = data.get('data', {}).get('taskId')
print(f"Task created, ID:{cls.TASK_ID}")
except requests.RequestException as e:
print(f'Create task failed:{e}')
@classmethod
def get_token(cls, task_id=None, retry_times=120):
if not task_id:
cls.create_task()
task_id = task_id or cls.TASK_ID
if not task_id:
print("Not found task id")
return False
print(f"Start pull task:{task_id} result")
url = cls.GET_TOKEN_URL.format(BASE_URL=cls.BASE_URL, TOKEN=cls.TOKEN, task_id=task_id)
count = 0
while count < retry_times:
try:
response = requests.get(url)
if response.status_code == 200:
data = response.json()
status = data.get('data', {}).get('status')
print('task status', status)
if status == 'Success':
return data.get('data', {}).get('response')
except requests.RequestException as e:
print('task failed', e)
finally:
count += 1
time.sleep(1)
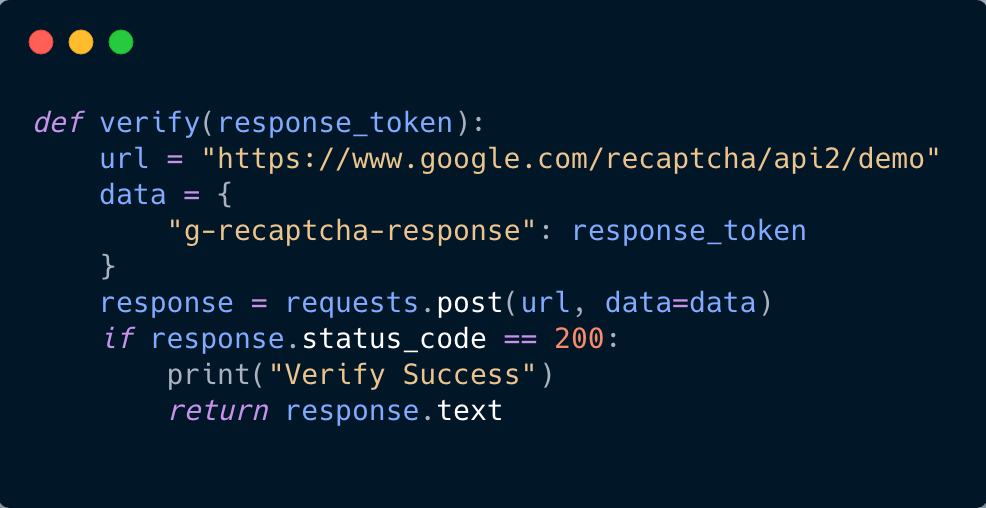
def verify(response_token):
url = "https://www.google.com/recaptcha/api2/demo"
data = {
"g-recaptcha-response": response_token
}
response = requests.post(url, data=data)
if response.status_code == 200:
print("Verify Success")
return response.text
if __name__ == "__main__":
token = ReCAPTCHA.get_token()
print(token)
verify(token)
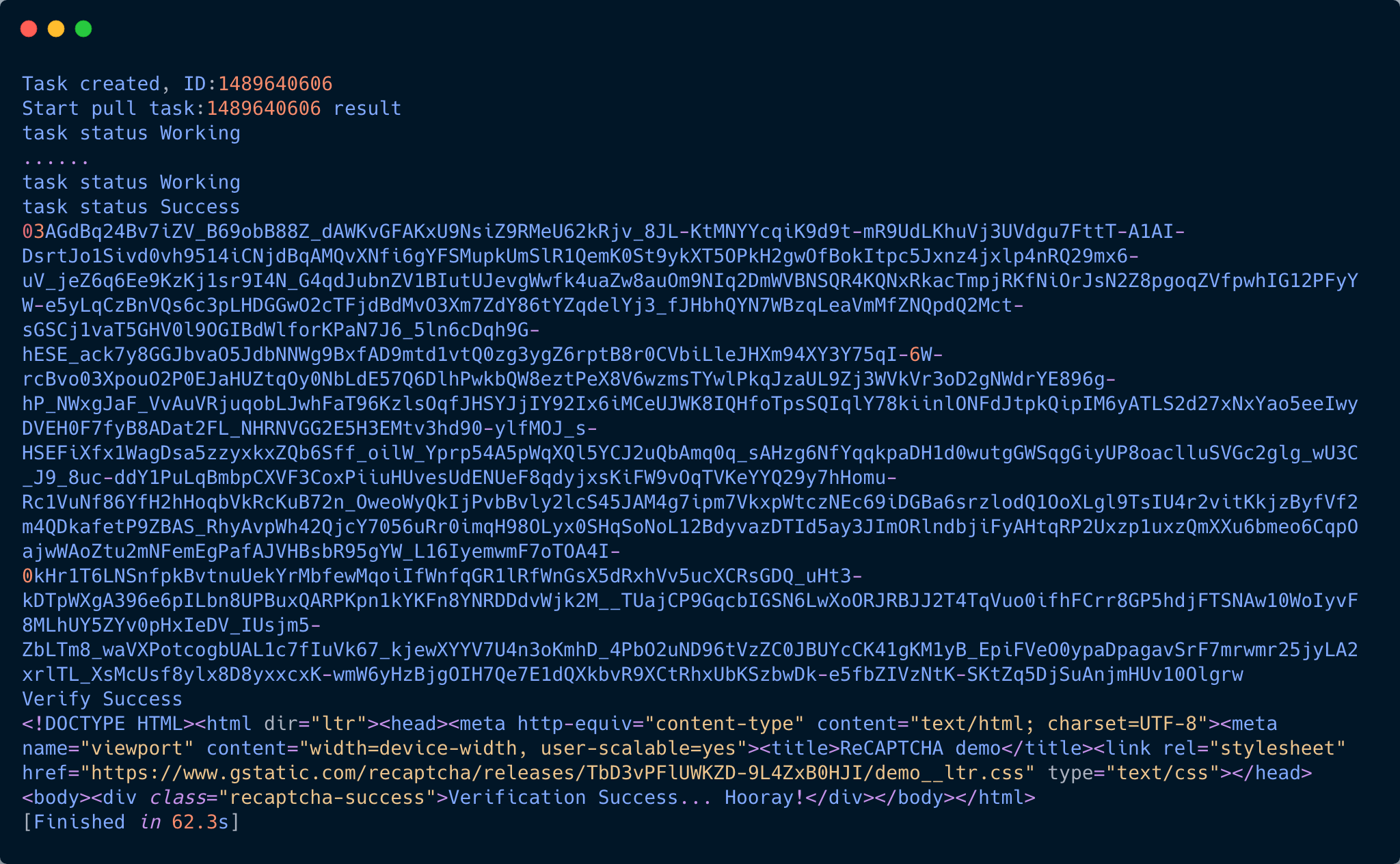
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号