Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户。怎样评价用户对商品的偏好?可以有很多方法,如用户对商品的打分、购买、页面停留时间、保存、转发等等。得到了用户对商品的偏好,就可以给用户推荐商品。有两种方法:用户A喜欢物品1,商品2和物品1很相似,于是把物品2推荐给用户A;或者用户A和用户B很类似,B喜欢商品2,就将商品2推荐给用户A。所以协同过滤分为两类:基于用户的协同过滤和基于物品的协同过滤。
1. 相似度的计算
协同过滤算法一个重要的问题就是相似度的计算,相似度即衡量两个用户,或者两个物品之间相似的程度。计算相似度有几种方法:同现相似度(Cooccurrence Similarity)、欧氏距离(Euclidean Distance)、皮尔逊相关系数(Pearson Correlarion Coefficient)、Cosine相似度(Cosine Similarity)、Tanimoto系数(Tanimoto Coefficient)等。
1.1 同现相似度(Cooccurrence Similarity)
同现,即同时出现的意思,物品i和物品j的同现相似度的计算公式是:

N(i)是喜欢物品i的用户集合,N(j)是喜欢物品j的用户集合,可以理解为喜欢物品i的用户中有多少喜欢物品j。但是这样存在一个问题,如果物品j是热门物品,喜欢它的用户肯定很多,这样不论i是什么物品,wij的值就会很大。为了避免这个问题的出现,对公式进行了改进:
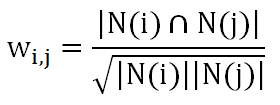
这样如果j是热门物品,分母会很大,从而惩罚了wij的值。
1.2 欧氏距离(Euclidean Distance)
n维空间中两个点x和y的距离:

当n=2时,是平面上两点之间的距离,当n=3时,是立体空间上两点之间的距离。相似度计算公式:
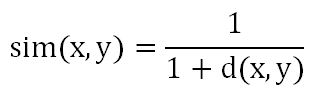
即距离越大,相似度越低;距离越小,相似度越高。当计算两个物品的相似度时,坐标轴是不同的用户,如果所有用户对这两个物品的偏好都差不多,那么这两个物品之间的距离就近,相似度就低,说明这两个物品很相似;反之,则说明这两个物品相似度低。
2. 推荐计算
推荐计算分为两类:基于用户的协同过滤和基于物品的协同过滤。
2.1 基于用户的协同过滤(User CF)
基于用户的协同过滤的基本思想是,对于每一个个用户,根据他对所有物品的偏好,计算他与所有其他用户的相似度(可以使用同现相似度或欧式距离),得到一个用户相似度矩阵Um×m。用户对物品的偏好评分矩阵Pm×n,U×P得到一个m×n矩阵,即对每个用户,每个物品的偏好,过滤掉已经存在的用户对商品的偏好,剩下的数据降序排序,即得到了一个推荐列表。
2.2 基于物品的协同过滤(Item CF)
基于物品的协同过滤的基本思想是,对于每一个个物品,根据所有用户对它的偏好,计算它与所有其他物品的相似度(可以使用同现相似度或欧式距离),得到一个物品相似度矩阵In×n。P×I得到一个m×n矩阵,即对每个用户,每个物品的偏好,过滤掉已经存在的用户对商品的偏好,剩下的数据降序排序,即得到了一个推荐列表。
3. 协同过滤算法的实现
MLlib并没有实现协同过滤算法,可以自己实现。
程序代码:
/** * Created by Administrator on 2017/7/21. */ import org.apache.log4j.{ Level, Logger } import org.apache.spark.{ SparkConf, SparkContext } object ALSTest02 { def main(args:Array[String]) = { // 设置运行环境 val conf = new SparkConf().setAppName("Decision Tree") .setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar")) val sc = new SparkContext(conf) Logger.getRootLogger.setLevel(Level.WARN) // 读取样本数据并解析 val dataRDD = sc.textFile("hdfs://master:9000/ml/data/sample_itemcf3.txt") val userDataRDD = dataRDD.map(_.split(",")).map(f => (ItemPref(f(0), f(1), f(2).toDouble))).cache() // 建立模型 val simModel = new ItemSimilarity() val itemRDD = simModel.Similarity(userDataRDD, "cooccurrence") val recomm = new RecommendedItem val recommRDD = recomm.Recommend(itemRDD, userDataRDD, 30) // 输出结果 println("物品相似度矩阵:") itemRDD.sortBy(f => (f.itemid1, f.itemid2)).collect.foreach { simItem => println(simItem.itemid1 + ", " + simItem.itemid2 + ", " + simItem.similar) } println("用戶推荐列表:") recommRDD.sortBy(f => (f.pref)).collect.foreach { UserRecomm => println(UserRecomm.userid + ", " + UserRecomm.itemid + ", " + UserRecomm.pref) } } }
运行结果:
物品相似度矩阵:
1, 2, 0.6666666666666666
1, 3, 0.6666666666666666
1, 5, 0.4082482904638631
1, 6, 0.3333333333333333
2, 1, 0.6666666666666666
2, 3, 0.3333333333333333
2, 4, 0.3333333333333333
2, 6, 0.6666666666666666
3, 1, 0.6666666666666666
3, 2, 0.3333333333333333
3, 4, 0.3333333333333333
3, 5, 0.4082482904638631
4, 2, 0.3333333333333333
4, 3, 0.3333333333333333
4, 5, 0.4082482904638631
4, 6, 0.6666666666666666
5, 1, 0.4082482904638631
5, 3, 0.4082482904638631
5, 4, 0.4082482904638631
5, 6, 0.4082482904638631
6, 1, 0.3333333333333333
6, 2, 0.6666666666666666
6, 4, 0.6666666666666666
6, 5, 0.4082482904638631
用戶推荐列表:
3, 1, 1.3333333333333333
6, 3, 1.8164965809277263
2, 4, 2.7079081189859817
1, 3, 3.0
5, 4, 3.666666666666666
3, 2, 3.6666666666666665
5, 5, 3.6742346141747673
6, 1, 3.8164965809277263
1, 5, 4.08248290463863
4, 5, 4.4907311951024935
3, 5, 4.4907311951024935
4, 3, 5.0
2, 6, 5.041241452319316
1, 4, 5.666666666666666
4, 1, 5.666666666666666
3, 6, 6.0
5, 6, 6.333333333333332
2, 2, 6.666666666666667
6, 2, 7.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号