Spark的运行模式(2)--Yarn-Cluster和Yarn-Client
3. Yarn-Cluster
Yarn是一种统一资源管理机制,可以在上面运行多种计算框架。Spark on Yarn模式分为两种:Yarn-Cluster和Yarn-Client,前者Driver运行在Worker节点,后者Driver运行在Client节点上。采用Spark on Yarn模式,只需要在一个节点部署Spark就行了,因此部署比较简单。
先介绍一下Yarn-Cluster。
首先把spark-assembly-1.6.0-hadoop2.6.0.jar上传到HDFS。
由于Yarn在安装Hadoop的时候已经配置了,所以就直接对Spark进行配置了。spark-env.sh在部署Standalone模式是已经设置了,所以也不需要在设置。这里只需要在Master节点设置spark-defaults.conf,该文件在${HADOOP_HOME}/conf目录下,增加以下设置:
spark.master spark://master:7077
spark.yarn.jar hdfs://master:9000/spark/jars/spark-assembly-1.6.0-hadoop2.6.0.jar
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark/logs
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
spark.yarn.scheduler.heartbeat.intervals-ms 5000
spark.yarn.preserve.staging.files false
spark.yarn.max.executor.failures 6
spark.driver.extraJavaOptions -Dhdp.version=2.6.5
spark.yarn.am.extraJavaOptions -Dhdp.version=2.6.5
Spark on Yarn不需要启动Spark的Master或者Slave,只需要启动Hadoop的DFS和Yarn就行了,也就是只需要运行Hadoop的start-all.sh就行了,因此运行也相对简单,并且性能还比较好。
启动Hadoop的DFS和Yarn以后,运行:
![]()
其中的 --master yarn-cluster表明以Yarn-Cluster模式运行。运行结束以后可以Master:8080看到这个Application:
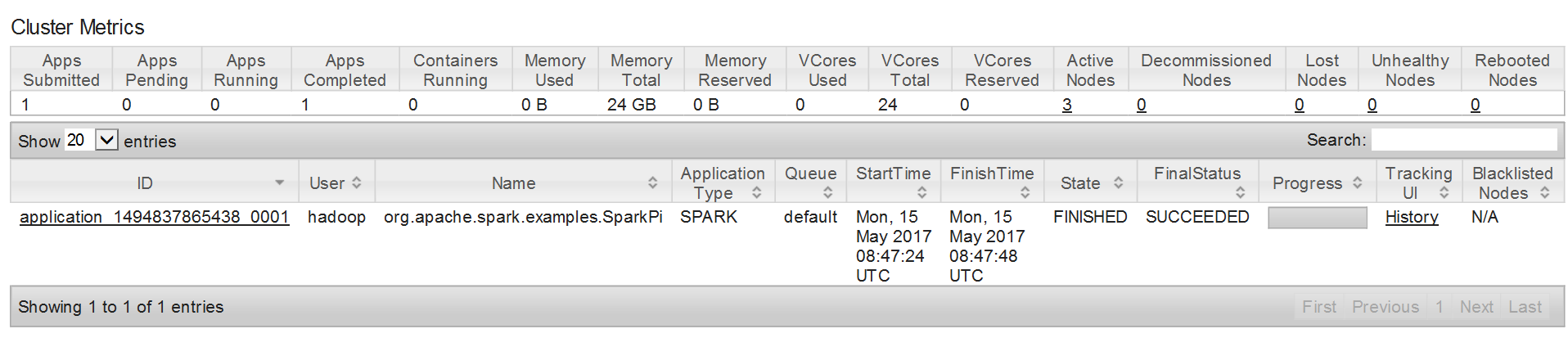
点进Logs可以看见运行结果:
![]()
3. Yarn-Client
Yarn-Client的部署和Yarn-Cluster是一样的,区别就在于Yarn-Cluster的Driver运行在Worker节点,而Yarn-Client的Driver运行在Client节点。
输入命令:
![]()
其中--master yarn-client表明以Yarn-Client模式运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号