Spark分布式集群的搭建和运行
集群共三台CentOS虚拟机,一个Matser,主机名为master;三个Worker,主机名分别为master、slave03、slave04。前提是Hadoop和Zookeeper已经安装并且开始运行。
1. 在master上下载Scala-2.11.0.tgz,复制到/opt/下面,解压,在/etc/profile加上语句:
export SCALA_HOME=/opt/scala-2.11.0
export PATH=$PATH:$SCALA_HOME/bin
然后运行命令:
source /etc/profile
在slave03、slave04上也执行相同的操作。
2. 在master上下载spark-2.1.0-bin-hadoop2.6,复制到/opt/下面。解压,在/etc/profile加上语句:
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
然后运行命令:
source /etc/profile
3. 编辑${SPARK_HOME}/conf/spark-env.sh文件,增加下面的语句:
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_121
# SCALA_HOME
export SCALA_HOME=/opt/scala-2.11.0
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.6
# Master主机名
export SPARK_MASTER_HOST=master
# Worker的内存大小
export SPARK_WORKER_MEMORY=1g
# Worker的Cores数量
export SPARK_WORKER_CORES=1
# SPARK_PID路径
export SPARK_PID_DIR=$SPARK_HOME/tmp
# Hadoop配置文件路径
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0-cdh5.9.0/etc/hadoop
# Spark的Recovery Mode、Zookeeper URL和路径
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:12181,slave03:12181,slave04:12181 -Dspark.deploy.zookeeper.dir=/spark"
在${SPARK_HOME}/conf/slaves中增加:
matser
slave03
slave04
这样就设置了三个Worker。
修改文件结束以后,将${SPARK_HOME}用scp复制到slave03和slave04。
4. 在master上进入${SPARK_HOME}/sbin路径,运行:
./start-master.sh
这是启动Master。
再运行:
./start-slaves.sh
这是启动Worker。
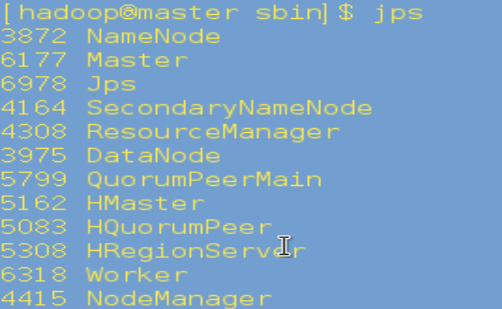
5. 在master上运行jps,如果有Master和Worker表明启动成功:
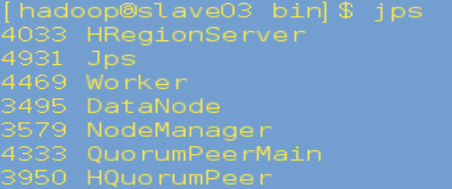
在slave03、slave04上运行jps,有Worker表明启动成功:
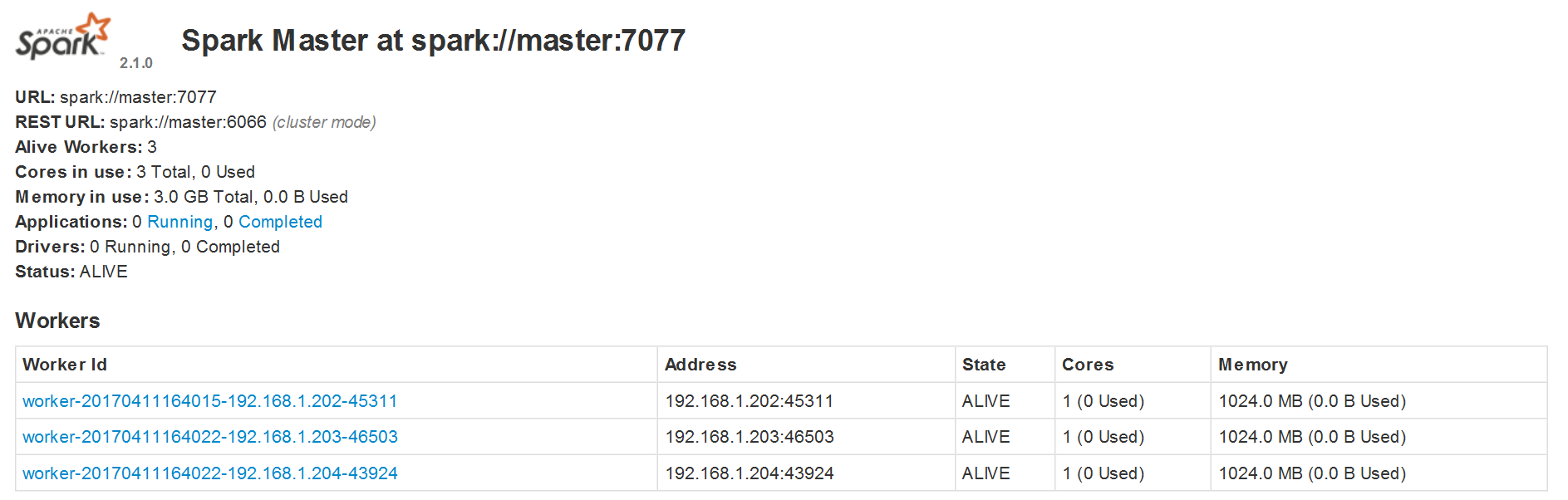
6. 访问http://master:8081,出现下面的页面表明启动成功:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号