Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection (2)
Feature backbone采用DLA,输入维度为3×H×W的RGB图,得到维度D×h×w的特征图F,然后将特征图送入几个轻量级regression heads,2D bouding boxes的中心特征图用下面的模块得到:

其中AN是Attentive Normalization.用公式表示:
![]()
类似的, 2D和3D bouding boxes的中心之间的offset用公式表示:
![]()
深度用以下两个公式表示:
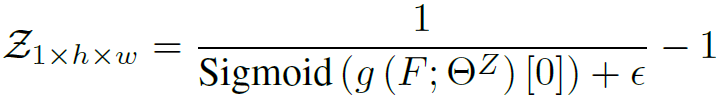
![]()
其中Z是预测的深度值,delta是标准差.
3D bouding boxes的维度用以下公式表示:
![]()
角度用以下公式表示:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号