An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
模型如下图所示:
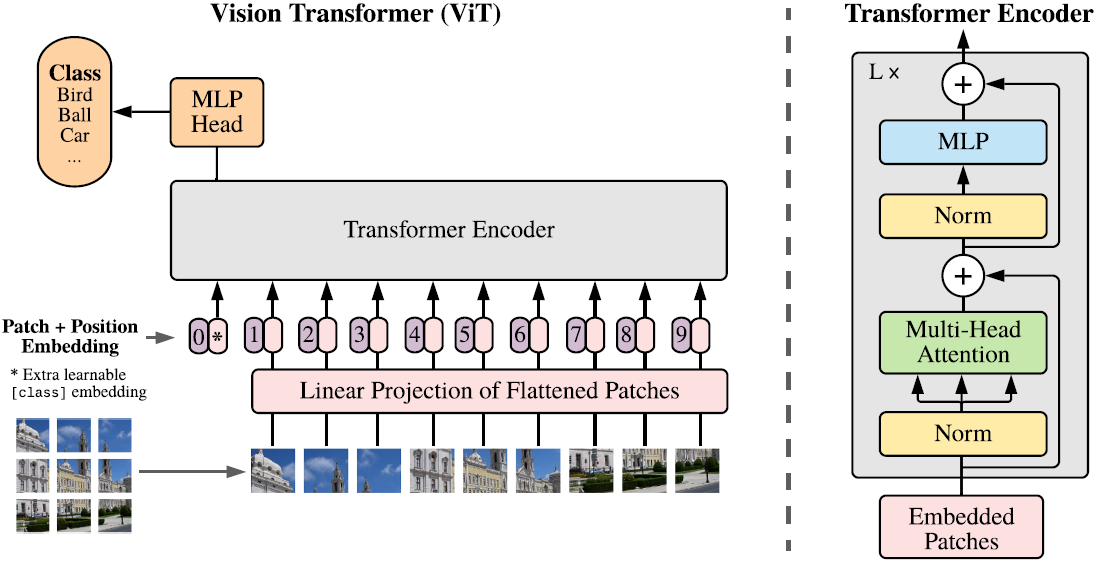
将H×W×C的图像reshape成了N×(P2×C),其中(H,W)是图像的原始分辨率,C是通道数,(P,P)是每个图像块的分辨率,N=H×W/P2为图像块的数量,将一个图像块使用可学习的线性层映射到维度为D的隐藏向量,如式(1)所示,线性映射的输出称为patch embeddings.在patch embeddings之前增加了一个可学习的embedding:xclass.patch embeddings后面的是position embeddings,用于保留位置信息,再加上多头自注意力(MSA),MLP,Layernorm(LN),最后输出Encoder.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号