大数据期末作业——学生学业分析
数据集下载:
链接:https://pan.baidu.com/s/1EMaN6uuQJlsrvaO2NQKgkQ
提取码:tl58
一、项目背景
1.背景
该数据集记录了280份来自不同国家、不同性别两个学期的学生记录,包括当前受教育程度、班级、所选课程、成绩、出勤特征、以及家长参与等信息,通过分析数据并建立模型预测学生成绩。
2.要求
从数据预处理(20分)、模型建立分析(30分)、参数调优(10分)、预测效果(10分)、数据可视化(10分)、项目报告(20分)给出综合分数
3.数据集介绍
- gender-学生性别(“M”或“FM”)
- National-学生国籍(’ Kuwait’,’ Lebanon’,’ Egypt’,’ SaudiArabia’,’ USA’,’ Jordan’,’ Venezuela’,’ Iran’,’ Tunis’,’ Morocco’,’ Syria’,’ Palestine’,’ Iraq’,’ Lybia)
- PlaceofBirth-学生出生地(“KuwaIT”、“Jordan”、“Iraq ” 、“lebanon”、“SaudiArabia ”、“USA ”、“Palestine”、“Egypt”、“Tunis”、“Iran”、“Lybia ”、“Syria ”、“Morocco”、“venzuela”)
- StageID-学生所属教育级别(“lowerlevel”、“MiddleSchool ”、“HighSchool”)
- GradeId-所属年级(“G-01”、“G-02”、“G-03”、“G-04”、“G-05”、“G-06”、“G-07”、“G-08”、“G-09”、“G-10”、“G-11”、“G-12”)
- SectionID-学生所属教室(‘A’,‘B’,‘C’)
- Topic--课程('IT'、 'Math'、 'Arabic' 、'Science'、'English'、 'Quran' 、'Spanish' 、'French' 、'History'、 'Biology' 'Chemistry' 、'Geology')
- Semester-学年(“F”、“S”)
- Relation-家长负责学生(’mom’,’father’)
- raisedhands-学生在课堂上举起手多少次(数字:0-100)
- VisITedResources-学生访问课程内容的次数(数字:0-100)
- AnnouncementsView-学生检查新公告的次数(数字:0-100)
- Discussion-学生参加讨论小组的次数(数字:0-100)
- ParentAnsweringSurvey-家长是否回答学校提供的调查(’Yes’,’No’)
- ParentschoolSatisfaction-家长对学校的满意度(’Yes’,’No’)
- StudentAbsenceDays-每名学生缺勤天数(above-7, under-7)
- Class-学生成绩分类(L、M、H)
二、分析过程
1.加载数据并并导入相关的包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing, svm
from sklearn.linear_model import Perceptron
from sklearn.tree import DecisionTreeClassifier
data = pd.read_csv('xAPI-Edu-Data.csv')
data.head()
查看数据 :
| gender | NationalITy | PlaceofBirth | StageID | GradeID | SectionID | Topic | Semester | Relation | raisedhands | VisITedResources | AnnouncementsView | Discussion | ParentAnsweringSurvey | ParentschoolSatisfaction | StudentAbsenceDays | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 15 | 16 | 2 | 20 | Yes | Good | Under-7 | M |
| 1 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 20 | 20 | 3 | 25 | Yes | Good | Under-7 | M |
| 2 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 10 | 7 | 0 | 30 | No | Bad | Above-7 | L |
| 3 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 30 | 25 | 5 | 35 | No | Bad | Above-7 | L |
| 4 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 40 | 50 | 12 | 50 | No | Bad | Above-7 | M |
2.处理数据
2.1查看数据规格
data.shape

2.2查看列信息
data.info()
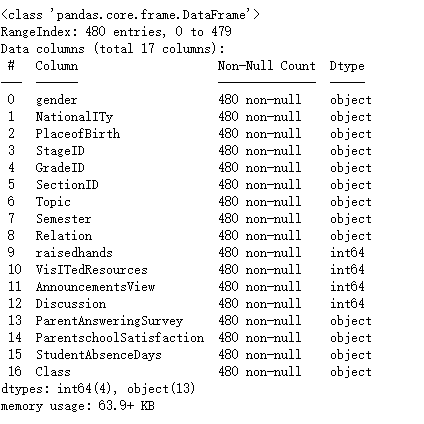
每列都是480行数据,且没有空值,不需要再对数据进行预处理。
2.3查看学生成绩类别
data.Class.unique()
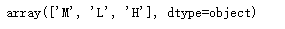
学生成绩一共分为三类['L', 'M', 'H'],这将作为评判学生的标准。
L:0-59 不及格;
M:60-89 中等;
H:90-100 高分。
3.分析数据
3.1学生成绩分析
ax = sns.countplot(x='Class', data=data, order=['L', 'M', 'H'])
#给每列上方加上百分比
for a in ax.patches:
ax.annotate('{:0.2f}%'.format((a.get_height()*100)/len(data)),
(a.get_x()+0.24, a.get_height()+2))
plt.show()
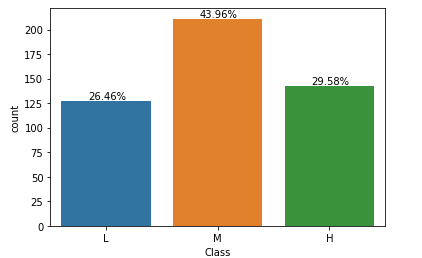
大部分学生都处于中等成绩,高分学生人数占总人数的26.46%。
#查看不及格学生信息
data.loc[data["Class"]=='L']
数据:
| gender | NationalITy | PlaceofBirth | StageID | GradeID | SectionID | Topic | Semester | Relation | raisedhands | VisITedResources | AnnouncementsView | Discussion | ParentAnsweringSurvey | ParentschoolSatisfaction | StudentAbsenceDays | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 10 | 7 | 0 | 30 | No | Bad | Above-7 | L |
| 3 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 30 | 25 | 5 | 35 | No | Bad | Above-7 | L |
| 6 | M | KW | KuwaIT | MiddleSchool | G-07 | A | Math | F | Father | 35 | 12 | 0 | 17 | No | Bad | Above-7 | L |
| 12 | M | KW | KuwaIT | lowerlevel | G-04 | A | IT | F | Father | 5 | 1 | 0 | 11 | No | Bad | Above-7 | L |
| 13 | M | lebanon | lebanon | MiddleSchool | G-08 | A | Math | F | Father | 20 | 14 | 12 | 19 | No | Bad | Above-7 | L |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 469 | F | Jordan | Jordan | MiddleSchool | G-08 | A | Chemistry | S | Father | 9 | 6 | 15 | 85 | No | Bad | Above-7 | L |
| 474 | F | Jordan | Jordan | MiddleSchool | G-08 | A | Chemistry | F | Father | 2 | 7 | 4 | 8 | No | Bad | Above-7 | L |
| 475 | F | Jordan | Jordan | MiddleSchool | G-08 | A | Chemistry | S | Father | 5 | 4 | 5 | 8 | No | Bad | Above-7 | L |
| 478 | F | Jordan | Jordan | MiddleSchool | G-08 | A | History | F | Father | 30 | 17 | 14 | 57 | No | Bad | Above-7 | L |
| 479 | F | Jordan | Jordan | MiddleSchool | G-08 | A | History | S | Father | 35 | 14 | 23 | 62 | No | Bad | Above-7 | L |
127 rows × 17 columns
似乎不及格的学生缺课天数都超过七天,数值偏低,没有学校调查。
3.2学生成绩与性别关系
#分两个10*5的画布 fig, axarr = plt.subplots(2,figsize=(10,10)) #学生性别柱形图 sns.countplot(x='gender', data=data, order=['M','F'], ax=axarr[0]) #不同性别与成绩的柱形图 sns.countplot(x='gender', hue='Class', data=data, order=['M', 'F'],hue_order = ['L', 'M', 'H'], ax=axarr[1]) plt.show()
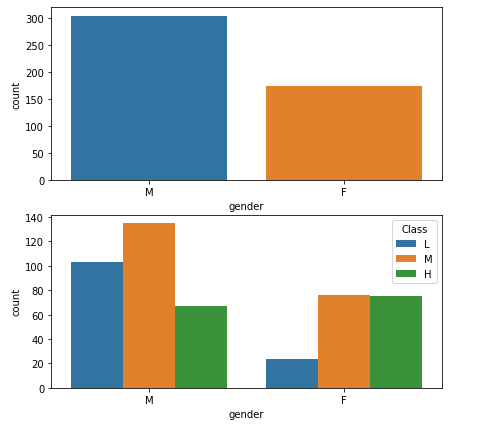
由图可以明显看出女学生的不及格人数要远远少于男同学,且女学生的中等和高分段学生人数基本持平,男女学生在高分段人数相差不大。
推测:性别可能影响的学生成绩。
3.3学生国籍与成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10)) #学生国籍柱形图 sns.countplot(x='NationalITy', data=data, ax=axarr[0]) #不同国籍与成绩柱形图 sns.countplot(x='NationalITy', hue='Class', data=data,hue_order = ['L', 'M', 'H'], ax=axarr[1]) plt.show()
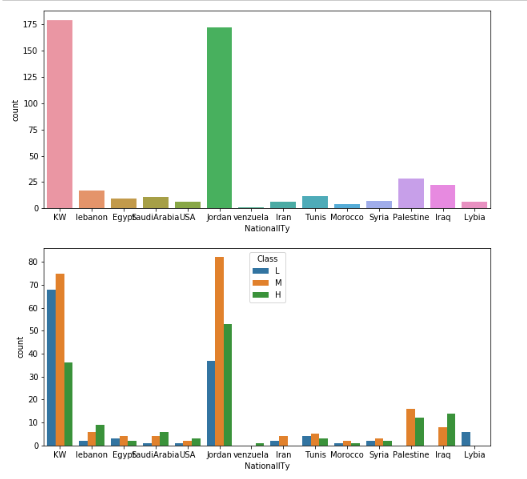
由于除了KW和jordan这两个国籍的学生之外,其余国籍的学生可分析的人数都比较少,并不能得出有效信息。
对比两图:
1.能得出相比于KW的学生,jordan学生不及格人数为KW学生的一半,总体成绩更好一些。
2.Iran和Lybia国籍的学生没有取得高分的。
#查看Iran国籍的学生
data.loc[data['NationalITy'] == 'Iran']
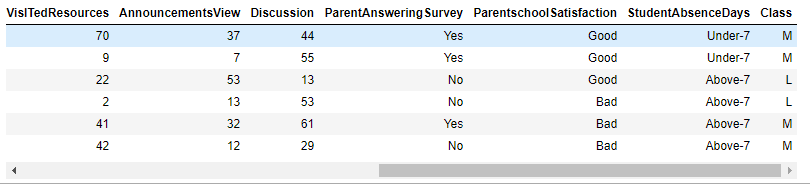
#查看Lybia国籍的学生
data.loc[data['NationalITy'] == 'Lybia']
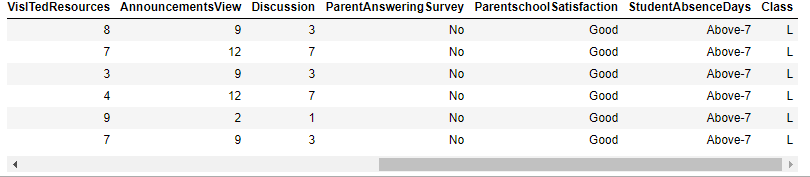
在观察后,发现Lybia国籍学生似乎与所有未通过考试的学生有相似的数据(缺课超过7天,数值偏低,没有学校调查等)。
3.4学生所属教育级别与成绩的关系
fig, axarr = plt.subplots(2,figsize=(6,6)) sns.countplot(x='StageID', data=data, ax=axarr[0]) sns.countplot(x='StageID', hue='Class', data=data, hue_order = ['L', 'M', 'H'], ax=axarr[1]) plt.show()
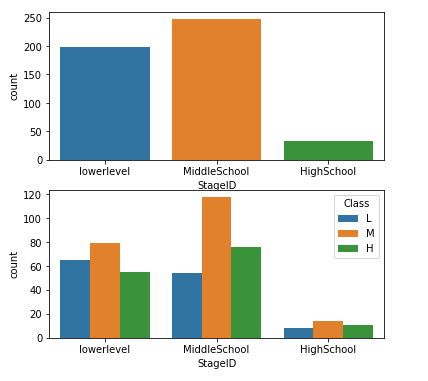
由图可看出,不管是所属哪个教育阶段,都是中等成绩的人数偏多。
3.5学生所属年级与成绩的关系
fig, axarr = plt.subplots(2,figsize=(7,7))
sns.countplot(x='GradeID',
data=data,
order=['G-02', 'G-04', 'G-05', 'G-06', 'G-07', 'G-08', 'G-09', 'G-10', 'G-11', 'G-12'],
ax=axarr[0])
sns.countplot(x='GradeID',
hue='Class',
data=data,
order=['G-02', 'G-04', 'G-05', 'G-06', 'G-07', 'G-08', 'G-09', 'G-10', 'G-11', 'G-12'],
hue_order = ['L', 'M', 'H'],
ax=axarr[1])
plt.show()
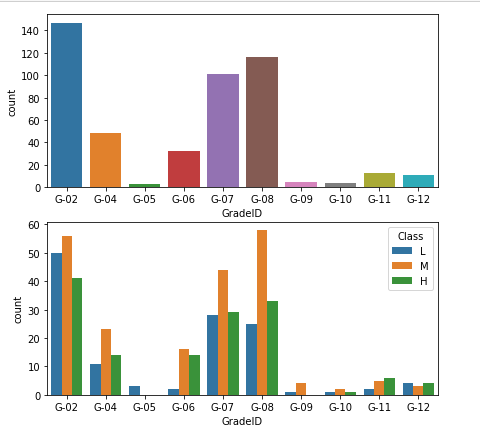
从这些结果来看,五年级、九年级和十年级的学生人数很少。 除此之外,没有五年级学生及格,也没有九年级学生取得高分。
# 查看五年级的样本
data.loc[data['GradeID']=='G-05']

#查看九年级的样本
data.loc[data['GradeID']=='G-09']

在观察后,发现五年级学生似乎与所有未通过考试的学生有相似的数据(缺课超过7天,数值偏低,没有学校调查等) 并且在对比九年级的学生成绩之后发现,这样的情况也发生在九年级当中。
3.6学生所属教室与成绩的关系
fig, axarr = plt.subplots(2,figsize=(5,5))
sns.countplot(x='SectionID', data=data,
order=['A', 'B', 'C'], ax = axarr[0])
sns.countplot(x='SectionID', hue='Class',
data=data, order=['A', 'B', 'C'],
hue_order = ['L', 'M', 'H'], ax = axarr[1])
plt.show()

三个班的总体趋势都差不多,我们并不能得出什么有效信息
3.7学生所选课程与成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10)) sns.countplot(x='Topic', data=data, ax = axarr[0]) sns.countplot(x='Topic', hue='Class', data=data,hue_order = ['L', 'M', 'H'], ax = axarr[1]) plt.show()
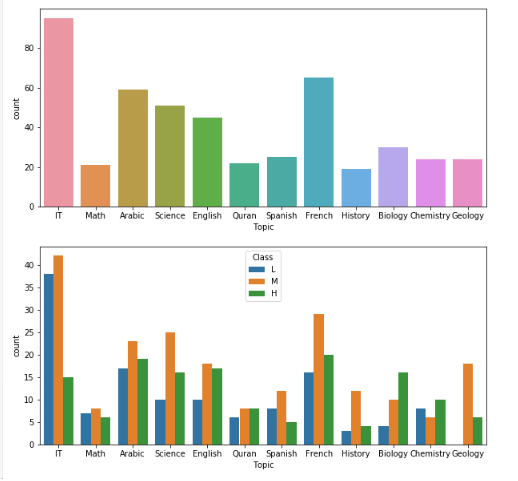
在图中可以看到一个有趣的现象,Geology专业没有不及格的学生。 那么为什么呢? 继续分析
3.8不同学年学生与成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10)) sns.countplot(x='Semester', data=data, ax = axarr[0]) sns.countplot(x='Semester', hue='Class', data=data,hue_order = ['L', 'M', 'H'], ax = axarr[1]) plt.show()
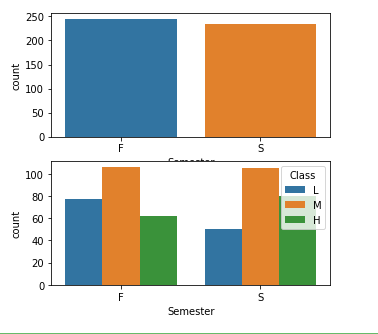
由图可以看出,第二学年的不及格人数比第一学年少,高分人数都比第一学年多。
推测:学年与成绩相关。
3.9学生监护人与学生成绩的关系
fig, axarr = plt.subplots(2,figsize=(5,5)) sns.countplot(x='Relation', data=data, ax = axarr[0]) sns.countplot(x='Relation', hue='Class', data=data,hue_order = ['L', 'M', 'H'], ax = axarr[1]) plt.show()
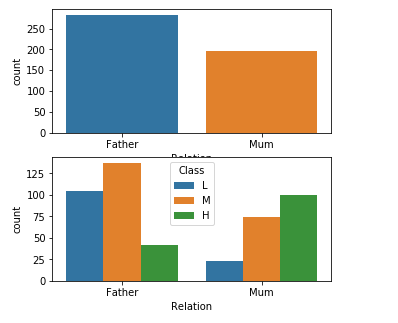
从这两张表可以看出,母亲作为监护人和学生不太可能不及格之间似乎有关联。
3.10学生在课堂举手次数、访问课程内容次数、检查新公告次数、参加讨论次数与成绩的关系
sns.pairplot(data, hue="Class",
diag_kind="kde",
hue_order = ['L', 'M', 'H'],
markers=["o", "s", "D"])
plt.show()
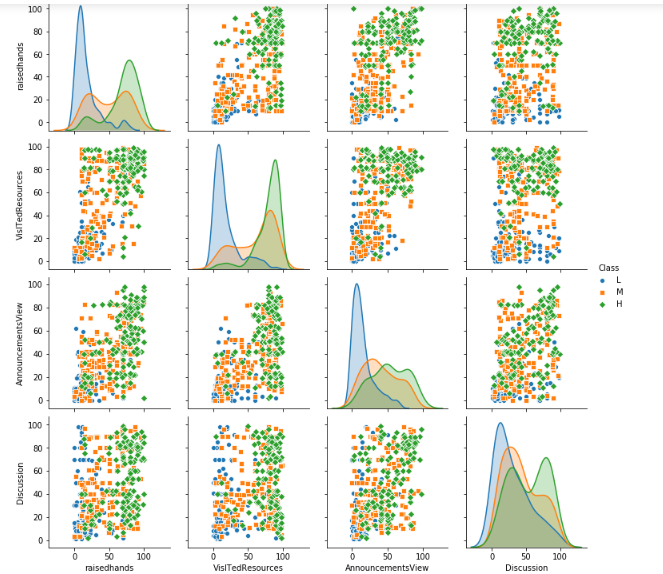
#查看课程的举手,访问课程,查看新公告,讨论此处中位数
data.groupby('Topic').median()
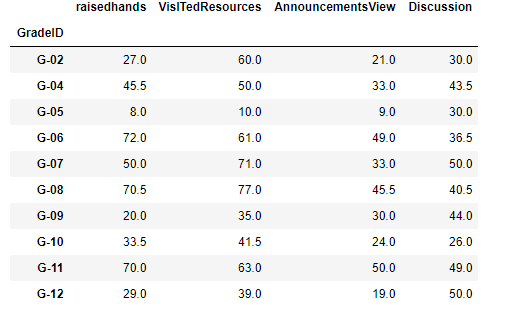
在这里我们可以看出五年级和九年级的数据比其他大多数年级少上许多
3.11家长是否回答学生提供的调查与学生成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10))
sns.countplot(x='ParentAnsweringSurvey', data=data,
order=['Yes', 'No'], ax = axarr[0])
sns.countplot(x='ParentAnsweringSurvey', hue='Class',
data=data, order=['Yes', 'No'], hue_order = ['L', 'M', 'H'],
ax = axarr[1])
plt.show()
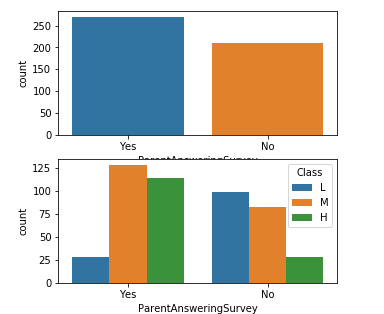
观察这两张图可能会觉得家长是否回答学校调查与学生成绩有关,但是我们并不知道是不是学生的成绩导致他们是否回应学校的调查,这无法从数据得出。
3.12家长对于学校满意度与学生成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10))
sns.countplot(x='ParentschoolSatisfaction', data=data,
order=['Good', 'Bad'], ax = axarr[0])
sns.countplot(x='ParentschoolSatisfaction', hue='Class',
data=data, order=['Good', 'Bad'],
hue_order = ['L', 'M', 'H'], ax = axarr[1])
plt.show()
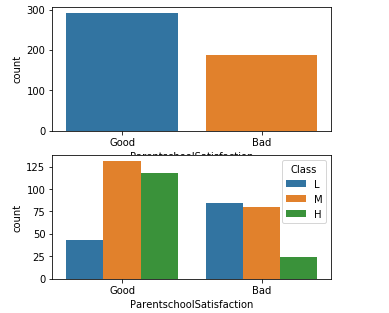
看到家长对于学校满意的结果时,也会出现上次的因果关系。
3.13学生缺勤天数与学生成绩的关系
fig, axarr = plt.subplots(2,figsize=(10,10))
sns.countplot(x='StudentAbsenceDays', data=data,
order=['Under-7', 'Above-7'],
ax = axarr[0])
sns.countplot(x='StudentAbsenceDays', hue='Class',
data=data, order=['Under-7', 'Above-7'],
hue_order = ['L', 'M', 'H'],
ax = axarr[1])
plt.show()

观察得出,学习时间与学生成绩有很强的相关性,缺课查过七天的学生很少取得高分,缺课少于七天的学生很少不及格。
综上分析,学生成绩与访问资源、学生缺席日、举手、公告意见、调查答案、监护人、家长满意度、讨论、性别和学期这些属性有关。
4.建立模型预测与学生成绩的关系
4.1处理非数据列
#将年级转化为数据
gradeID_dict = {"G-01" : 1,
"G-02" : 2,
"G-03" : 3,
"G-04" : 4,
"G-05" : 5,
"G-06" : 6,
"G-07" : 7,
"G-08" : 8,
"G-09" : 9,
"G-10" : 10,
"G-11" : 11,
"G-12" : 12}
data = data.replace({"GradeID" : gradeID_dict})
#将成绩转化为数据
class_dict = {"L" : -1,
"M" : 0,
"H" : 1}
data = data.replace({"Class" : class_dict})
# 转换成Scale数据
data["GradeID"] = preprocessing.scale(data["GradeID"])
data["raisedhands"] = preprocessing.scale(data["raisedhands"])
data["VisITedResources"] = preprocessing.scale(data["VisITedResources"])
data["AnnouncementsView"] = preprocessing.scale(data["AnnouncementsView"])
data["Discussion"] = preprocessing.scale(data["Discussion"])
# 使用虚拟编码转换 将11列转换成64列
data = pd.get_dummies(data, columns=["gender",
"NationalITy",
"PlaceofBirth",
"SectionID",
"StageID",
"Topic",
"Semester",
"Relation",
"ParentAnsweringSurvey",
"ParentschoolSatisfaction",
"StudentAbsenceDays"])
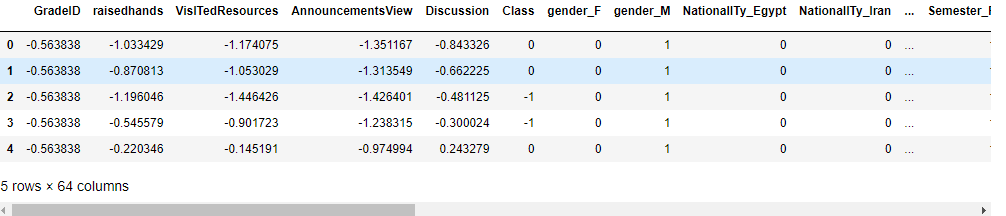
data.head()
部分数据截图:
4.2列出成绩与其他属性列的相关性
corr = data.corr() corr.iloc[[5]]
部分数据截图:

由表中数据可以看出访问资源、学生缺席日、举手、公告意见、调查答案、监护人、家长满意度、讨论、性别和学期都与Class有很强的相关性,这和我们之前的分析一样。
5.训练与预测
5.1使用Perception分类器
perc = Perceptron(eta0=0.1, random_state=15)
#data_train与data_test之比为7:3
results=[]
#进行多次预测
for _ in range(1000):
# 随机生成0.7的数据集
data_train = data.sample(frac=0.7)
# 数据集lable
data_train_X = data_train.loc[:, lambda x: [l for l in data if l != "Class"]]
data_train_Y = data_train.loc[:, lambda x: "Class"]
# 剩下的就是测试数据集
data_test = data.loc[~data.index.isin(data_train.index)]
# 测试数据集lable
data_test_X = data_test.loc[:, lambda x: [l for l in data if l != "Class"]]
data_test_Y = data_test.loc[:, lambda x: "Class"]
# 用 .fit()方法进行训练
perc.fit(data_train_X, data_train_Y)
#预测结果准确率
results.append(perc.score(data_test_X, data_test_Y))
#结果图
plt.plot([*range(0,1000)],results)

Final = np.hstack(results)
print('Minimum Accuracy Score: %.8f' % Final[Final.argmin()])
print('Maximum Accuracy Score: %.8f' % Final[Final.argmax()])
print('Average Accuracy Score: %.8f' % np.average(Final))

Perceptron 分类器平均预测结果准确率是0.65
5.2使用决策树分类器
#data_train与data_test之比为7:3
results2 = []
for i in range(1,15):
# 训练集
data_train = data.sample(frac=0.7)
# lable
data_train_X = data_train.loc[:, lambda x: [l for l in data if l != "Class"]]
data_train_Y = data_train.loc[:, lambda x: "Class"]
# 测试集
data_test = data.loc[~data.index.isin(data_train.index)]
# label
data_test_X = data_test.loc[:, lambda x: [l for l in data if l != "Class"]]
data_test_Y = data_test.loc[:, lambda x: "Class"]
#建立不同深度决策树
tree = DecisionTreeClassifier(random_state=56, criterion='gini', max_depth=i)
# .fit() 训练
tree.fit(data_train_X, data_train_Y)
#结果
results2.append(tree.score(data_test_X, data_test_Y))
#绘制不同深度决策树准确率折线图
plt.plot([*range(1,15)],results2) plt.grid(True, linestyle='--', alpha=0.5)

#输出最大值及对应深度
print(max(results2),results2.index(max(results2)))
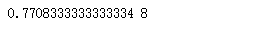
综上,对比两个不同分类器得出的结果,深度为7的决策树分类器经过训练之后预测的结果更准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号