Spark Datafram----pyspark第六次作业
练习:
1、将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
|
{ "id":1 , "name":" Ella" , "age":36 } { "id":2, "name":"Bob","age":29 } { "id":3 , "name":"Jack","age":29 } { "id":4 , "name":"Jim","age":28 } { "id":4 , "name":"Jim","age":28 } { "id":5 , "name":"Damon" } { "id":5 , "name":"Damon" } |
为employee.json创建DataFrame,并写出Python语句完成下列操作:
>>spark=SparkSession.builder.getOrCreate()
>>df=spark.read.json('file:///usr/local/spark/mycode/dafaframe/employee.json')
1.查询所有数据;
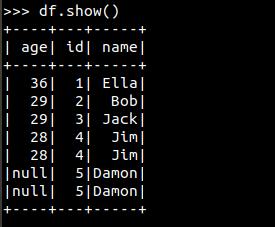
>>df.show()
2.查询所有数据,并去除重复的数据;
>>df.distinct().show()

3.查询所有数据,打印时去除id字段;
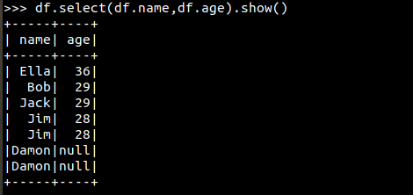
>>df.select(df.name,df.age).show()
4.筛选出age>30的记录;
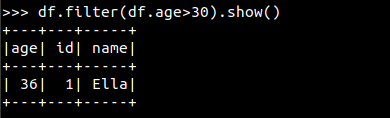
>>df.filter(df.age>30).show()
5.将数据按age分组;
>>df.groupby('age').count().show()

6.将数据按name升序排列;
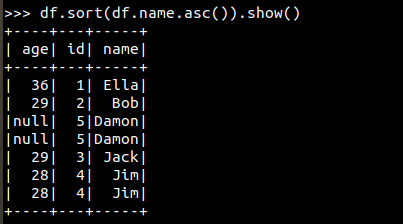
>>df.sort(df.name.asc()).show()
7.取出前3行数据;
>>df.show(3)

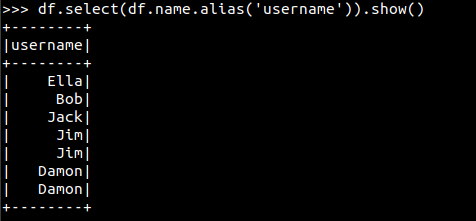
8.查询所有记录的name列,并为其取别名为username;
>>df.select(df.name.alias('username')).show()
9.查询年龄age的平均值;
>>df.groupby.avg('age').collect()[0].adDict()['avg(age)']
30.0
10.查询年龄age的最小值。
>>df.groupby.min('age').collect()[0].adDict()['min(age)']
28
2.编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
|
1,Ella,36 2,Bob,29 3,Jack,29 |
请将数据复制保存到Linux系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
from pyspark.sql import SparkSession, Row
spark = SparkSession.builder.appName('employee').getOrCreate()
sc = spark.sparkContext
lines = sc.textFile('file:///usr/local/spark/mycode/data/employee.txt')
result1 = lines.filter(lambda line: (len(line.strip()) > 0))
result2 = result1.map(lambda x: x.split(','))
#将RDD转换成DataFrame
item = result2.map(lambda x: Row(id=x[0], name=x[1], age=x[2]))
df = spark.createDataFrame(item)
df.show()

3.统计chines_year文件每年各类节目的数量,打印(节目名称、数量、年份)。要求首先按照节目名称升序排序,节目名称相同时其次按照年份升序排序。采用Spark RDD和Spark SQL两种方式。分别写出代码并截图。
sortTypeRDD.py
from pyspark import SparkConf, SparkContext
from operator import gt
class SecondSortKey():
def __init__(self, k):
self.year = k[0]
self.name = k[1]
def __gt__(self, other):
if other.name == self.name:
return gt(self.year, other.year)
else:
return gt(self.name, other.name)
def main():
conf = SparkConf().setAppName('spark_sort').setMaster('local')
sc = SparkContext(conf=conf)
data = sc.textFile('file:///usr/local/spark/mycode/data/chinese_year.txt')
rdd = data .map(lambda x: (x.split("\t")[1], x.split("\t")[0]))\
.map(lambda x: (x, 1))\
.reduceByKey(lambda a, b: a+b)\
.map(lambda x: (SecondSortKey(x[0]), x[0][0]+','+x[0][1]+','+str(x[1])))\
.sortByKey(True)\
.map(lambda x: x[1])
rdd.foreach(print)
if __name__=='__main__':
main()
SortTypeSql.py
from pyspark.sql import SparkSession, Row
#读取text文件
spark = SparkSession.builder.appName('topNSQL').getOrCreate()
sc = spark.sparkContext
lines = sc.textFile("file:///usr/local/spark/mycode/data/chinese_year.txt")
result1 = lines.filter(lambda line: (len(line.strip()) > 0) and (len(line.split('\t'))==4))
result2 = result1.map(lambda x: x.split('\t'))
#将RDD转换成DataFrame
item = result2.map(lambda x: Row(year=x[0], type=x[1], program=x[2], performers=x[3]))
df = spark.createDataFrame(item)
df.createOrReplaceTempView('items')
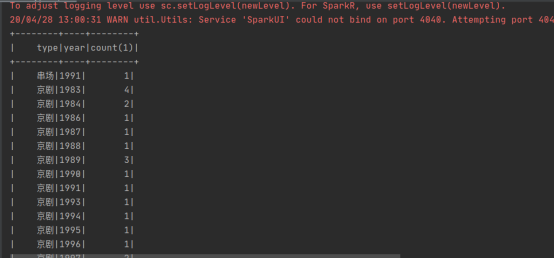
df1 = spark.sql('select type,year,count(*) from items group by type ,year order by type ,year ')
df1.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号