推荐算法!基于隐语义模型的协同过滤推荐之商品相似度矩阵
项目采用ALS作为协同过滤算法,根据MongoDB中的用户评分表计算离线的用户商品推荐列表以及商品相似度矩阵。
通过ALS计算商品相似度矩阵,该矩阵用于查询当前商品的相似商品并为实时推荐系统服务。
离线计算的ALS 算法,算法最终会为用户、商品分别生成最终的特征矩阵,分别是表示用户特征矩阵的U(m x k)矩阵,每个用户有 k个特征描述;表示物品特征矩阵的V(n x k)矩阵,每个物品也由 k 个特征描述。
V(n x k)表示物品特征矩阵,每一行是一个 k 维向量,虽然我们并不知道每一个维度的特征意义是什么,但是k 个维度的数学向量表示了该行对应商品的特征。
所以,每个商品用V(n x k)每一行的向量表示其特征,于是任意两个商品 p:特征向量为,商品q:特征向量为之间的相似度sim(p,q)可以使用和的余弦值来表示:
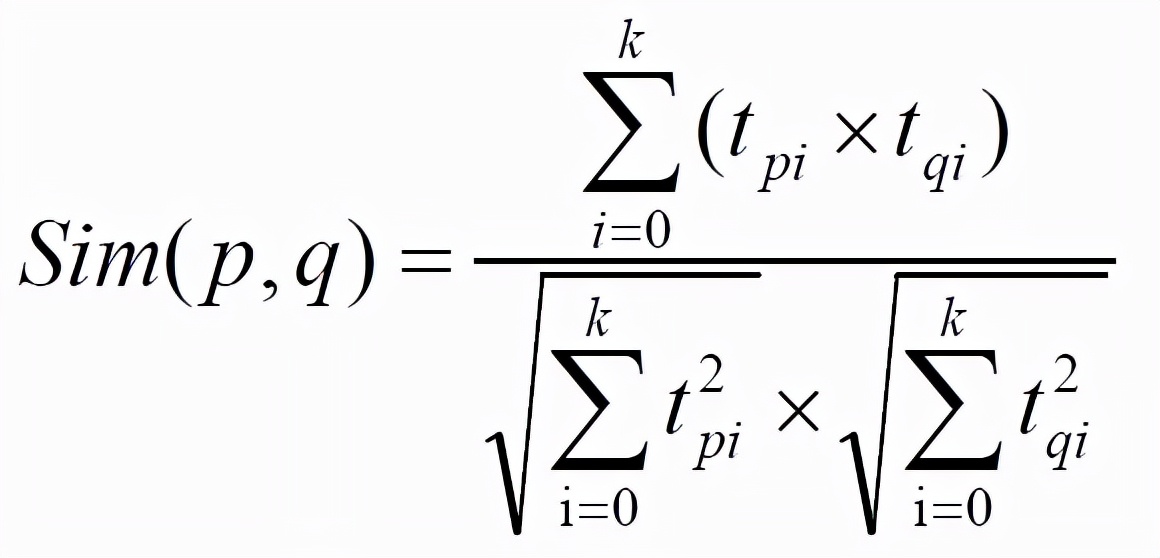
数据集中任意两个商品间相似度都可以由公式计算得到,商品与商品之间的相似度在一段时间内基本是固定值。最后生成的数据保存到MongoDB的ProductRecs表中。

核心代码如下:
//计算商品相似度矩阵
//获取商品的特征矩阵,数据格式 RDD[(scala.Int, scala.Array[scala.Double])]
val productFeatures = model.productFeatures.map{case (productId,features) =>
(productId, new DoubleMatrix(features))
}
// 计算笛卡尔积并过滤合并
val productRecs = productFeatures.cartesian(productFeatures)
.filter{case (a,b) => a._1 != b._1}
.map{case (a,b) =>
val simScore = this.consinSim(a._2,b._2) // 求余弦相似度
(a._1,(b._1,simScore))
}.filter(_._2._2 > 0.6)
.groupByKey()
.map{case (productId,items) =>
ProductRecs(productId,items.toList.map(x => Recommendation(x._1,x._2)))
}.toDF()
productRecs
.write
.option("uri", mongoConfig.uri)
.option("collection",PRODUCT_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()其中,consinSim是求两个向量余弦相似度的函数,代码实现如下:
//计算两个商品之间的余弦相似度
def consinSim(product1: DoubleMatrix, product2:DoubleMatrix): Double ={
product1.dot(product2) / ( product1.norm2() * product2.norm2() )
}在上述模型训练的过程中,我们直接给定了隐语义模型的rank,iterations,lambda三个参数。对于我们的模型,这并不一定是最优的参数选取,所以我们需要对模型进行评估。通常的做法是计算均方根误差(RMSE),考察预测评分与实际评分之间的误差。

有了RMSE,我们可以就可以通过多次调整参数值,来选取RMSE最小的一组作为我们模型的优化选择。
在scala/com.atguigu.offline/下新建单例对象ALSTrainer,代码主体架构如下:
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender"
)
//创建SparkConf
val sparkConf = new SparkConf().setAppName("ALSTrainer").setMaster(config("spark.cores"))
//创建SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val mongoConfig = MongoConfig(config("mongo.uri"),config("mongo.db"))
import spark.implicits._
//加载评分数据
val ratingRDD = spark
.read
.option("uri",mongoConfig.uri)
.option("collection",OfflineRecommender.MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRating]
.rdd
.map(rating => Rating(rating.userId,rating.productId,rating.score)).cache()
// 将一个RDD随机切分成两个RDD,用以划分训练集和测试集
val splits = ratingRDD.randomSplit(Array(0.8, 0.2))
val trainingRDD = splits(0)
val testingRDD = splits(1)
//输出最优参数
adjustALSParams(trainingRDD, testingRDD)
//关闭Spark
spark.close()
}其中adjustALSParams方法是模型评估的核心,输入一组训练数据和测试数据,输出计算得到最小RMSE的那组参数。代码实现如下:
//输出最终的最优参数
def adjustALSParams(trainData:RDD[Rating], testData:RDD[Rating]): Unit ={
//这里指定迭代次数为5,rank和lambda在几个值中选取调整
val result = for(rank <- Array(100,200,250); lambda <- Array(1, 0.1, 0.01, 0.001))
yield {
val model = ALS.train(trainData,rank,5,lambda)
val rmse = getRMSE(model, testData)
(rank,lambda,rmse)
}
// 按照rmse排序
println(result.sortBy(_._3).head)
}计算RMSE的函数getRMSE代码实现如下:
def getRMSE(model:MatrixFactorizationModel, data:RDD[Rating]):Double={
val userProducts = data.map(item => (item.user,item.product))
val predictRating = model.predict(userProducts)
val real = data.map(item => ((item.user,item.product),item.rating))
val predict = predictRating.map(item => ((item.user,item.product),item.rating))
// 计算RMSE
sqrt(
real.join(predict).map{case ((userId,productId),(real,pre))=>
// 真实值和预测值之间的差
val err = real - pre
err * err
}.mean()
)
}运行代码,我们就可以得到目前数据的最优模型参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号