

MySQL死锁分析与解决之路
们使用 MySQL 大概率上都会遇到死锁问题,这实在是个令人非常头痛的问题。本文将会对死锁进行相应介绍,对常见的死锁案例进行相关分析与探讨,以及如何去尽可能避免死锁给出一些建议。
--什么是死锁 --
死锁是并发系统中常见的问题,同样也会出现在数据库MySQL的并发读写请求场景中。当两个及以上的事务,双方都在等待对方释放已经持有的锁或因为加锁顺序不一致造成循环等待锁资源,就会出现“死锁”。常见的报错信息为 ” Deadlock found when trying to get lock... ”。
举例来说 A 事务持有 X1 锁 ,申请 X2 锁,B事务持有 X2 锁,申请 X1 锁。A 和 B 事务持有锁并且申请对方持有的锁进入循环等待,就造成了死锁。
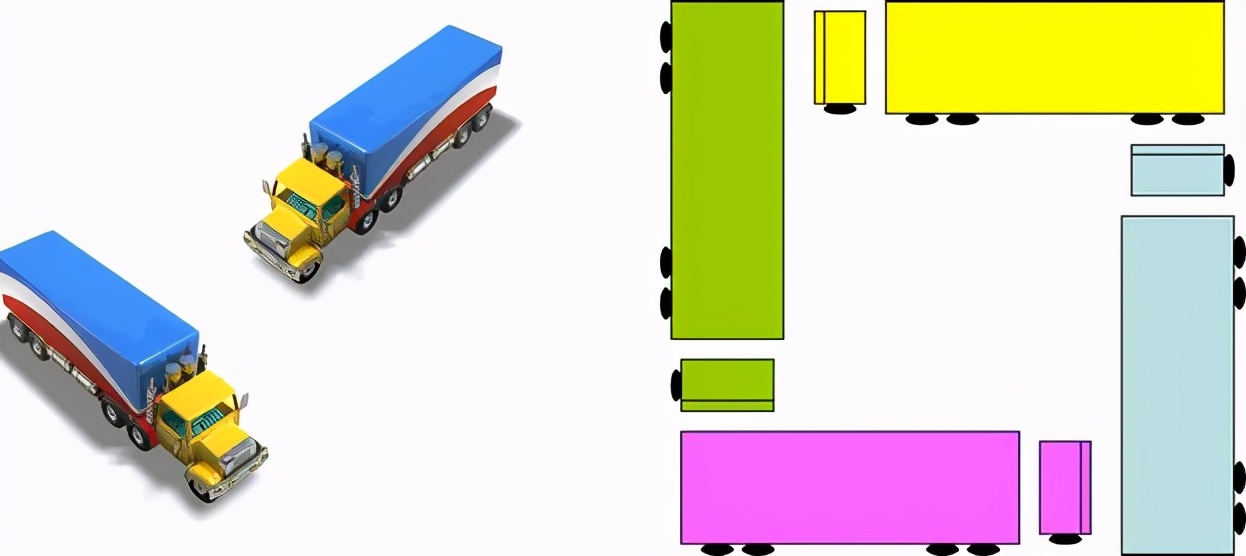
如上图,是右侧的四辆汽车资源请求产生了回路现象,即死循环,导致了死锁。
从死锁的定义来看,MySQL 出现死锁的几个要素为:
a.两个或者两个以上事务
b.每个事务都已经持有锁并且申请新的锁
c.锁资源同时只能被同一个事务持有或者不兼容
d.事务之间因为持有锁和申请锁导致彼此循环等待
说明:后续内容实验环境为 5.7 版本,隔离级别为 RR(可重复读)
-- InnoDB 锁类型--
为了分析死锁,我们有必要对 InnoDB 的锁类型有一个了解。
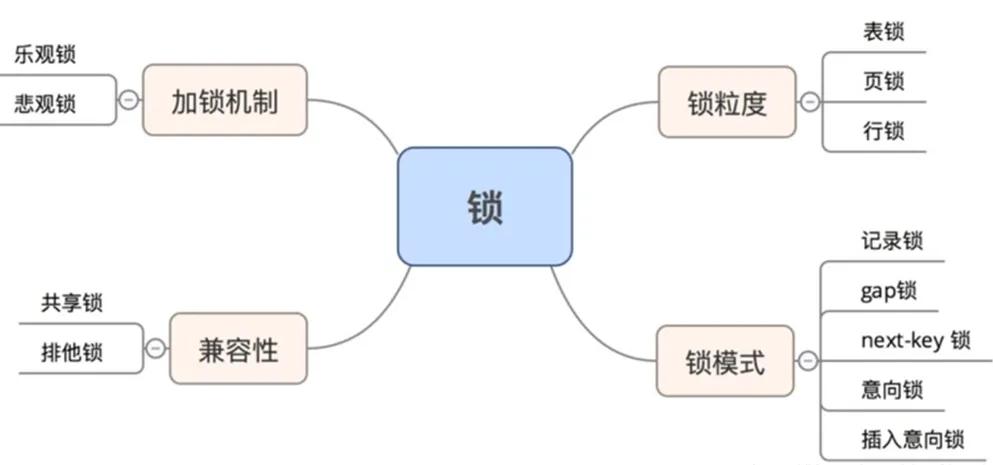
MySQL InnoDB 引擎实现了标准的行级别锁:共享锁( S lock ) 和排他锁 ( X lock )
- 不同事务可以同时对同一行记录加 S 锁。
- 如果一个事务对某一行记录加 X 锁,其他事务就不能加 S 锁或者 X 锁,从而导致锁等待。
如果事务 T1 持有行 r 的 S 锁,那么另一个事务 T2 请求 r 的锁时,会做如下处理:
- T2 请求 S 锁立即被允许,结果 T1 T2 都持有 r 行的 S 锁
- T2 请求 X 锁不能被立即允许
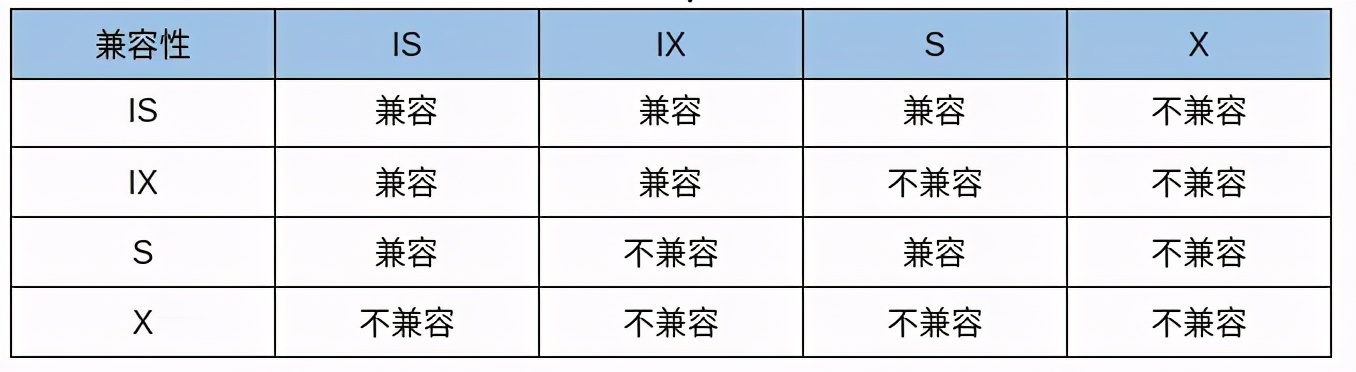
如果 T1 持有 r 的 X 锁,那么 T2 请求 r 的 X、S 锁都不能被立即允许,T2 必须等待 T1 释放 X 锁才可以,因为 X 锁与任何的锁都不兼容。共享锁和排他锁的兼容性如下所示:

间隙锁( gap lock )
间隙锁锁住一个间隙以防止插入。假设索引列有2, 4, 8 三个值,如果对 4 加锁,那么也会同时对(2,4)和(4,8)这两个间隙加锁。
- 如果索引列是唯一索引,那么只会锁住这条记录(只加行锁),而不会锁住间隙。
- 对于联合索引且是唯一索引,如果 where 条件只包括联合索引的一部分,那么依然会加间隙锁。
next-key lock
next-key lock 实际上就是 行锁+这条记录前面的 gap lock 的组合。假设有索引值10,11,13和 20,那么可能的 next-key lock 包括:
(负无穷,10]
(10,11]
(11,13]
(13,20]
(20,正无穷)
在 RR 隔离级别下,InnoDB 使用 next-key lock 主要是防止幻读问题产生。
意向锁( Intention lock )
InnoDB 为了支持多粒度的加锁,允许行锁和表锁同时存在。为了支持在不同粒度上的加锁操作,InnoDB 支持了额外的一种锁方式,称之为意向锁( Intention Lock )。意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度上进行加锁。意向锁分为两种:
- 意向共享锁( IS ):事务有意向对表中的某些行加共享锁
- 意向排他锁( IX ):事务有意向对表中的某些行加排他锁
由于 InnoDB 存储引擎支持的是行级别的锁,因此意向锁其实不会阻塞除全表扫描以外的任何请求。表级意向锁与行级锁的兼容性如下所示:
插入意向锁( Insert Intention lock )
插入意向锁是在插入一行记录操作之前设置的一种间隙锁,这个锁释放了一种插入方式的信号,即多个事务在相同的索引间隙插入时如果不是插入间隙中相同的位置就不需要互相等待。假设某列有索引值2,6,只要两个事务插入位置不同(如事务 A 插入3,事务 B 插入4),那么就可以同时插入。
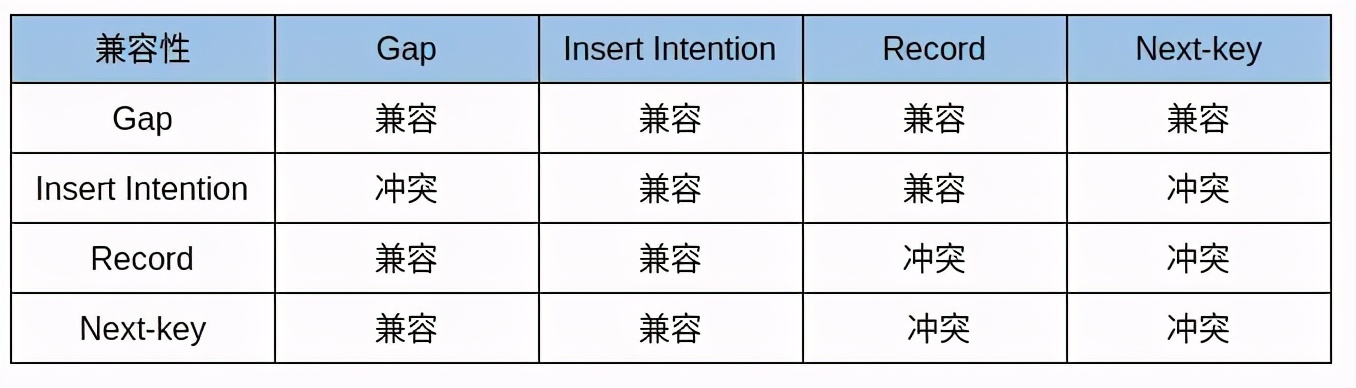
锁模式兼容矩阵
横向是已持有锁,纵向是正在请求的锁:
--阅读死锁日志--
一个温馨小提示: xmen 平台支持查看死锁主库的死锁日志,访问方式如下:
登录 https://xmen.intra.ke.com/#/mysql/mysql-cluster 点击集群管理 -> 输入集群端口 -> 工具集合 -> 查看死锁日志 点击查询即可查看最近一次死锁日志。

在进行具体案例分析之前,咱们先了解下如何去读懂死锁日志,尽可能地使用死锁日志里面的信息来帮助我们来解决死锁问题。
后面测试用例的数据库场景如下:
MySQL 5.7 事务隔离级别为 RR
表结构和数据如下:

测试用例如下:
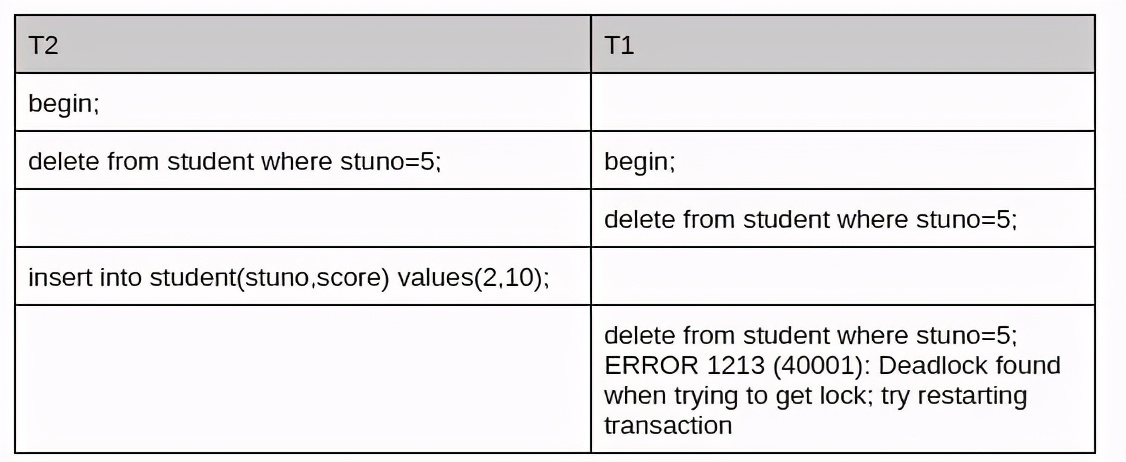
通过执行show engine innodb status 可以查看到最近一次死锁的日志。
日志分析如下:
*** (1) TRANSACTION:
TRANSACTION 2322, ACTIVE 6 sec starting index read
事务号为2322,活跃 6秒,starting index read 表示事务状态为根据索引读取数据。常见的其他状态有:

mysql tables in use 1 说明当前的事务使用一个表。
locked 1 表示表上有一个表锁,对于 DML 语句为 LOCK_IX
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
LOCK WAIT 表示正在等待锁,2 lock struct(s) 表示 trx->trx_locks 锁链表的长度为2,每个链表节点代表该事务持有的一个锁结构,包括表锁,记录锁以及自增锁等。本用例中 2locks 表示 IX 锁和lock_mode X (Next-key lock)
1 row lock(s) 表示当前事务持有的行记录锁/ gap 锁的个数。
MySQL thread id 37, OS thread handle 140445500716800, query id 1234 127.0.0.1 root updating
MySQL thread id 37 表示执行该事务的线程 ID 为 37 (即 show processlist; 展示的 ID )
delete from student where stuno=5 表示事务1正在执行的 sql,比较难受的事情是 show engine innodb status 是查看不到完整的 sql 的,通常显示当前正在等待锁的 sql。
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 11 page no 5 n bits 72 index idx_stuno of table `cw`.`student` trx id 2322 lock_mode X waiting
RECORD LOCKS 表示记录锁, 此条内容表示事务 1 正在等待表 student 上的 idx_stuno 的 X 锁,本案例中其实是 Next-Key Lock 。
事务2的 log 和上面分析类似:
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 11 page no 5 n bits 72 index idx_stuno of table `cw`.`student` trx id 2321 lock_mode X
显示事务 2 的 insert into student(stuno,score) values(2,10) 持有了 a=5 的 Lock mode X
| LOCK_gap,不过我们从日志里面看不到事务2执行的 delete from student where stuno=5;
这点也是造成 DBA 仅仅根据日志难以分析死锁的问题的根本原因。
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 11 page no 5 n bits 72 index idx_stuno of table `cw`.`student` trx id 2321 lock_mode X locks gap before rec insert intention waiting
表示事务 2 的 insert 语句正在等待插入意向锁 lock_mode X locks gap before rec insert intention waiting ( LOCK_X + LOCK_REC_gap )
--经典案例分析--
案例一:并发申请 gap 锁导致死锁
表结构和数据如下所示:
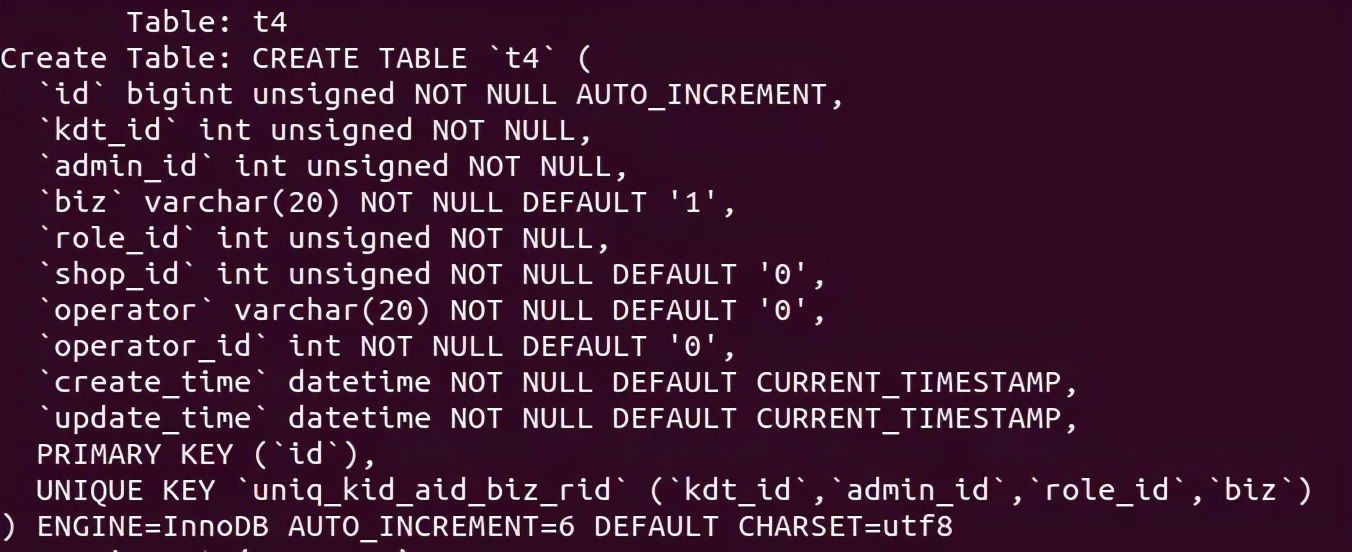

测试用例如下(本测试用例场景是两个事务删除不存在的行,然后再 insert 记录):

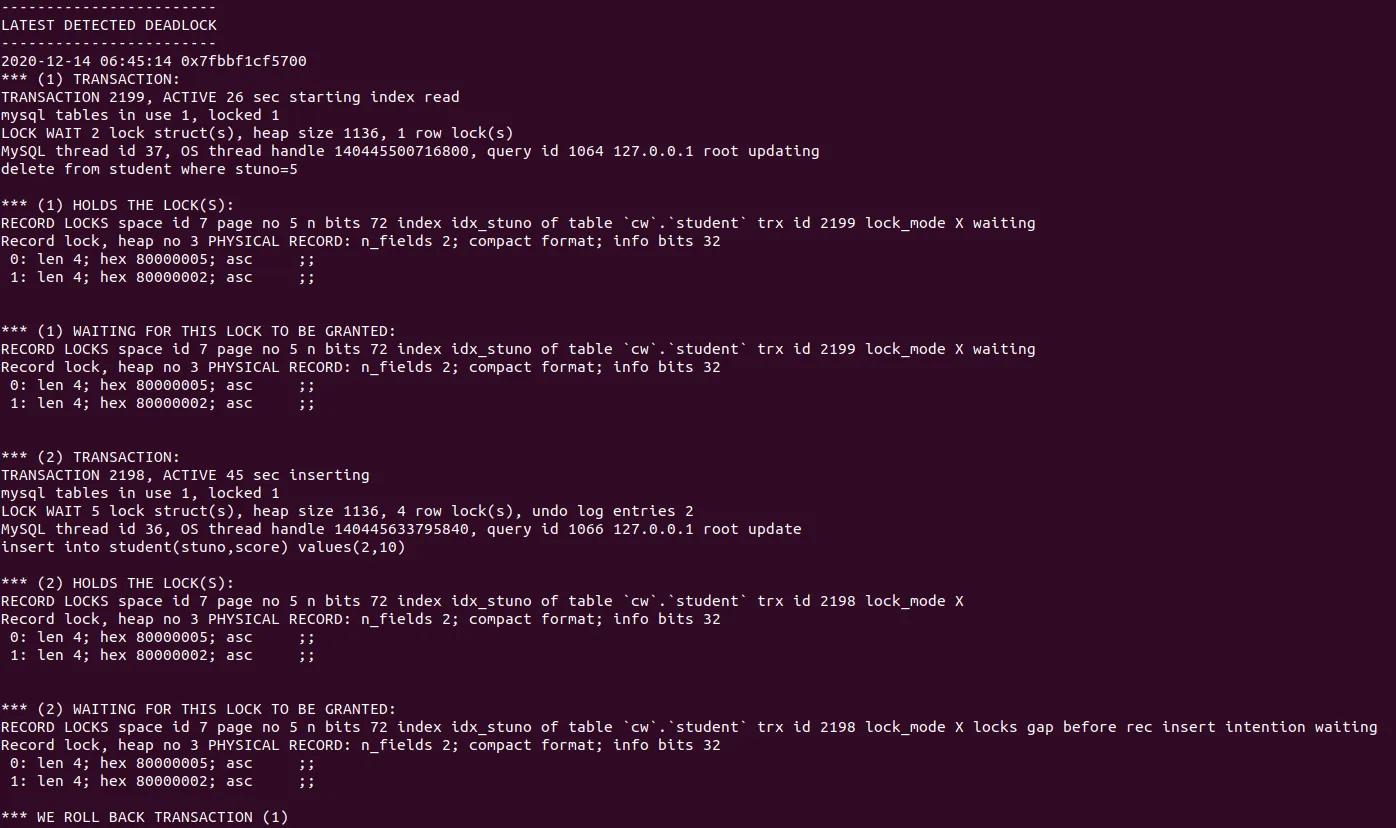
死锁日志如下所示:
死锁日志分析如下:
重点说明下 delete 不存在的记录是要加上 gap 锁, 事务日志中显示lock_mode X locks gap before rec .
1. T2:delete from t4 where kdt_id=15 and admin_id= 1 and biz='retail' and role_id=1; 符合条件的
记录不存在,导致T2先持有了( lock_mode X locks gap before rec ) 锁住
[(2,20,1,1,’ratail’,1,0)-(3,30,1,’retail’,1,0)]的区间,防止符合条件的记录插入。
2. T1 的 delete 与 T1 的 delete 一样同样申请了( lock_mode X locks gap but rec ) 锁住了
[(2,20,1,'retail',1,0)-(3,30,1,'retail',1,0)]的区间。
3. T1 的 insert 语句申请插入意向锁,但是插入意向锁和 T2 持有的 X gap ( lock_mode X locks gap before rec ) 冲突,故等待 T2 中的 gap 锁释放。
4. T2 的 insert 语句申请插入意向锁,但是插入意向锁和 T1 持有 X gap (lock_mode X locks gap before rec )冲突,故等待T1中的 gap 锁释放。
总结来说,就是 T1 (insert) 等待 T2 (delete) , T2 (insert) 等待 T1 (delete) 故而循环等待,出现死锁。
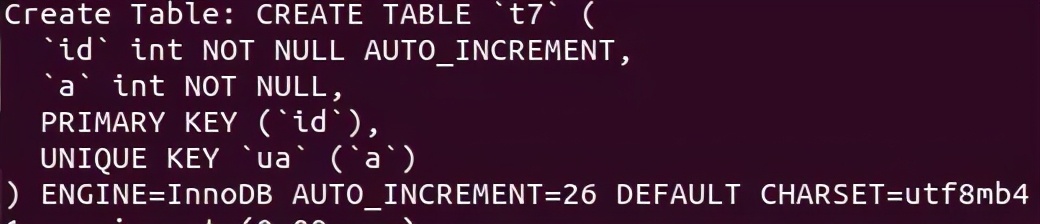
案例二:事务并发 insert 唯一键冲突
表结构和数据如下所示:

测试用例如下:

死锁日志如下:
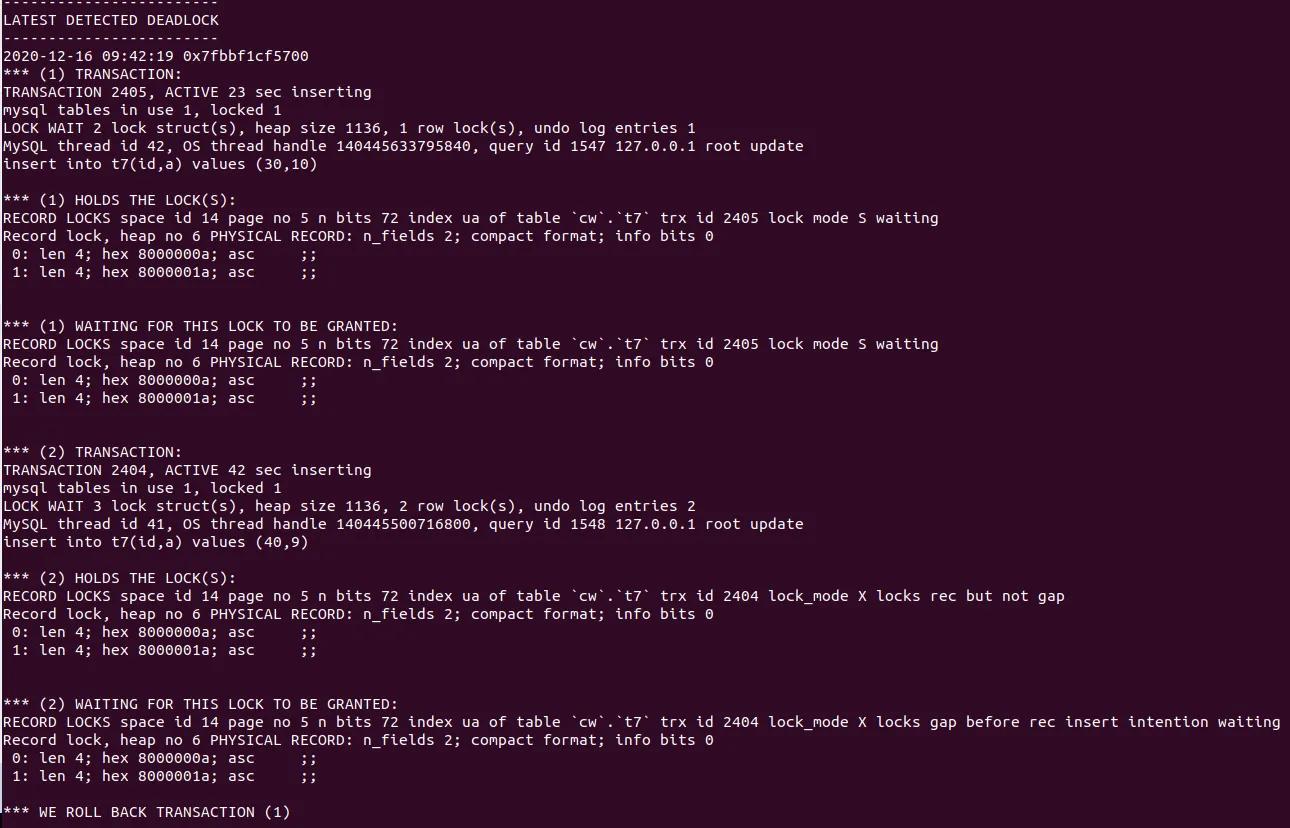
日志分析如下:
1.事务 T2 insert into t7(id,a) values (26,10) 语句 insert 成功,持有 a=10 的 排他行锁( X
locks rec but no gap )
2.事务 T1 insert into t7(id,a) values (30,10), 因为T2的第一条 insert 已经插入 a=10 的记录,
事务 T1 insert a=10 则发生唯一键冲突,需要申请对冲突的唯一索引加上S Next-key Lock
( 即 lock mode S waiting ) 这是一个间隙锁会申请锁住(,10],(10,20]之间的 gap 区域。
3.事务 T2 insert into t7(id,a) values (40,9)该语句插入的 a=9 的值在事务 T1 申请的 gap 锁
[4,10]之间, 故需事务 T2 的第二条 insert 语句要等待事务 T1 的 S-Next-key Lock 锁释放,
在日志中显示 lock_mode X locks gap before rec insert intention waiting 。
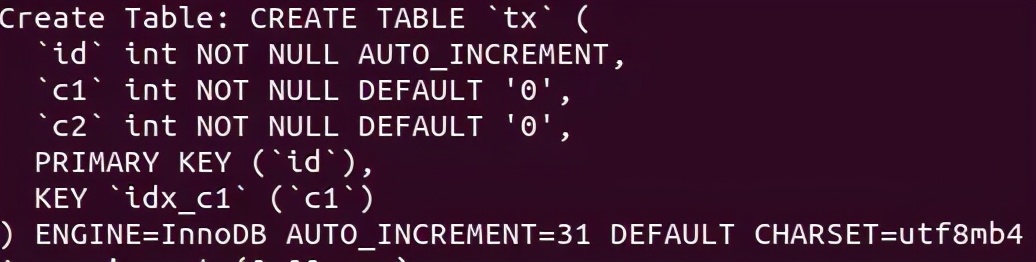
案例三:普通索引和主键相互竞争导致循环等待
表结构和数据如下所示:

测试用例如下:
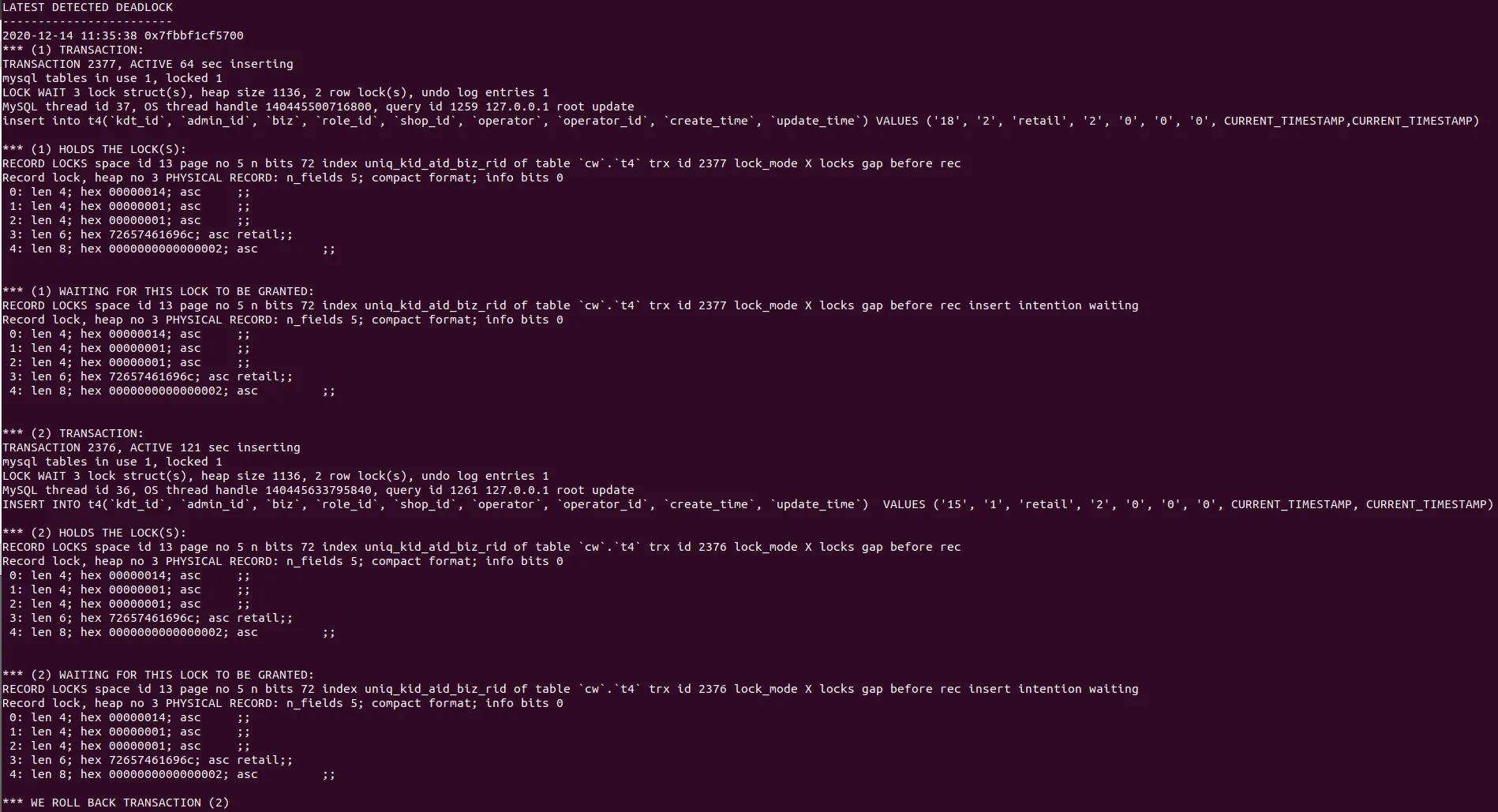
死锁日志:
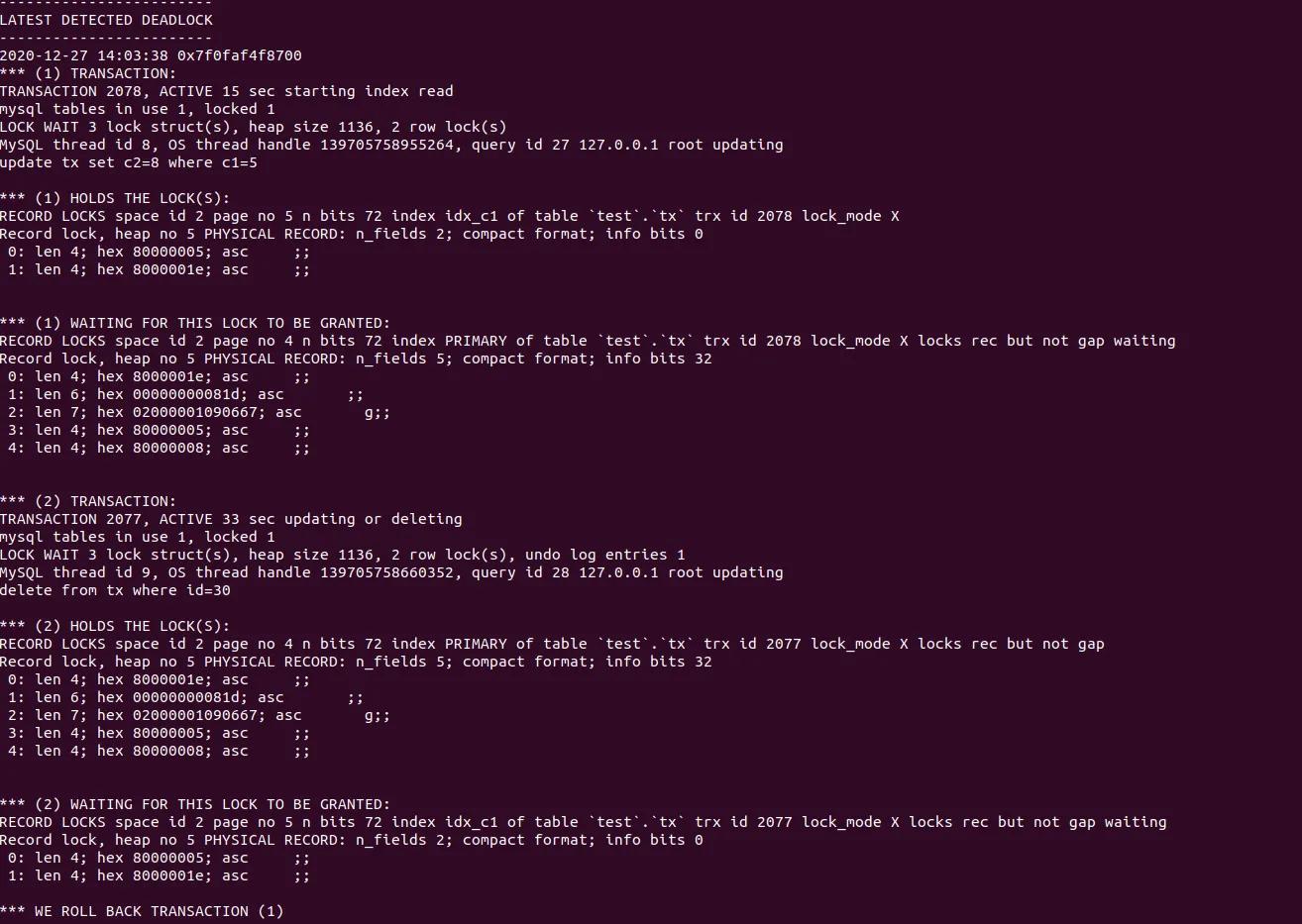
死锁日志分析:
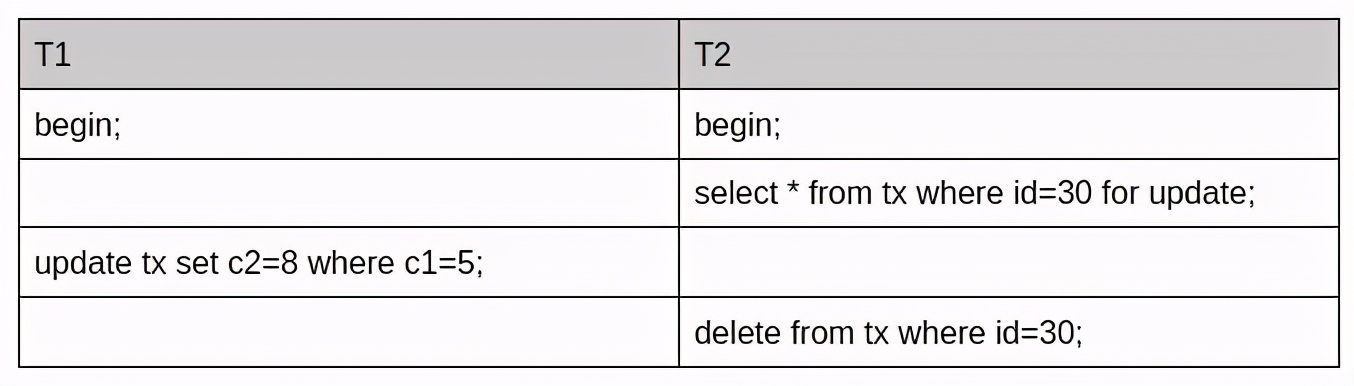
首先要理解的是 对同一个字段申请加锁是需要排队的。
其次表tx中索引 idx_c1 为非唯一普通索引。
(1). T2 执行 select for update 操作持有记录 id=30 的主键行锁:PRIMARY of table `test`.`tx` trx id 2077 lock_mode X locks rec but not gap。
(2). T1 语句 update 通过普通索引 idx_c1 更新 c2,先获取 idx_c1 c1=5 的 X 锁 lock_mode X locks rec but not gap, 然后去申请对应主键 id=30 的行锁, 但是 T2 已经持有主键的行数,于是 T1 等待。
(3). T2 执行根据主键 id=30 删除记录,需要申请 id=30 的行锁以及 c1=5 的索引行锁。但是 T1 以及持有该锁, 故会出现 index idx_c1 of table `test`.`tx` trx id 2077 lock_mode X locks rec but not gap waiting .
T2(delete) 等待 T1(update), T1(update) 等待 T2 (select for update)循环等待,造成死锁。
案例四:先 update 再 insert 的并发死锁问题
表结构如下,无数据:
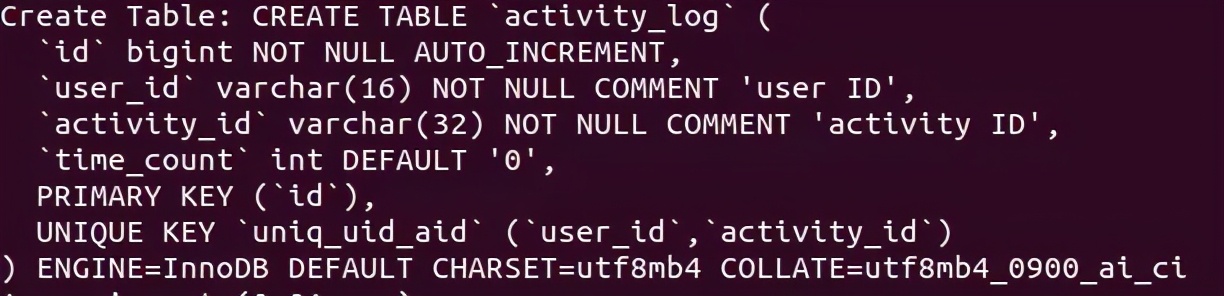
测试用例如下:
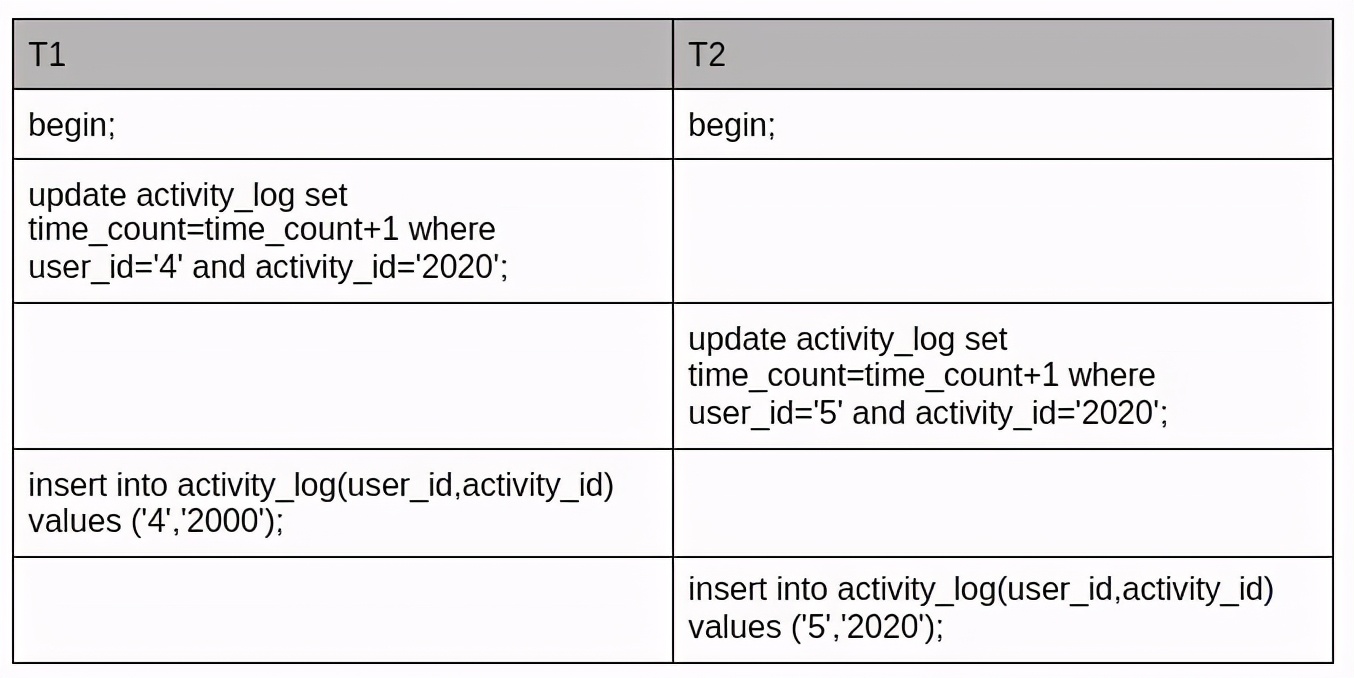
死锁日志如下:
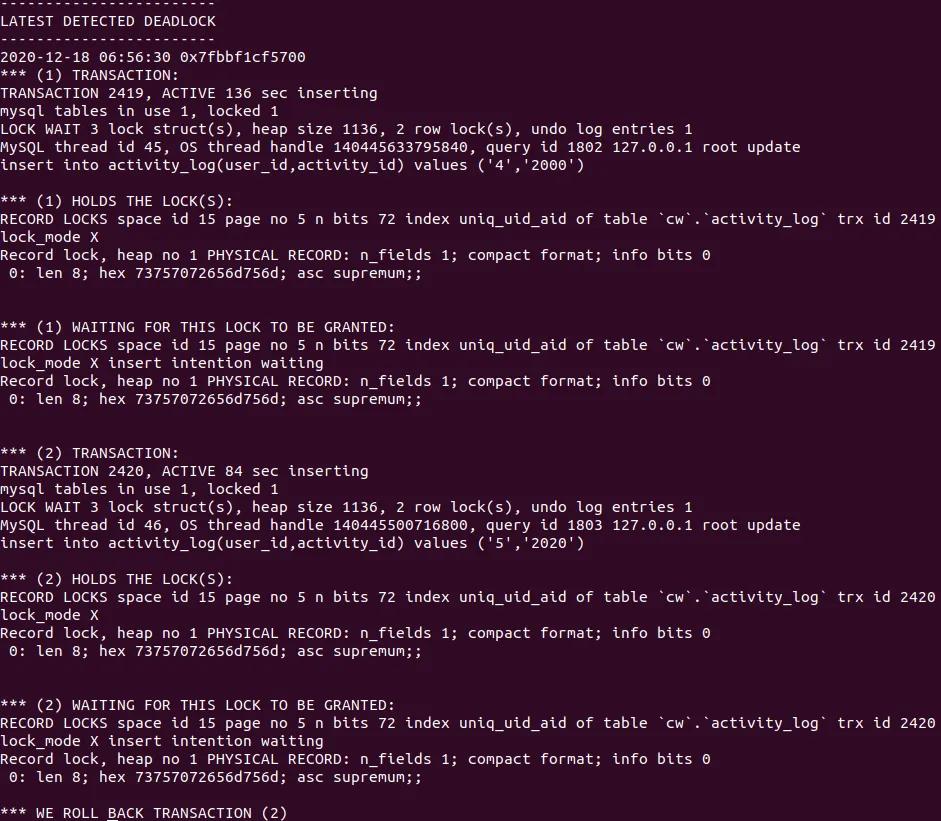
死锁分析:
可以看到两个事务 update 不存在的记录,先后获得间隙锁( gap 锁),gap 锁之间是兼容的所以在update环节不会阻塞。两者都持有 gap 锁,然后去竞争插入意向锁。当存在其他会话持有 gap 锁的时候,当前会话申请不了插入意向锁,导致死锁。
--如何尽可能避免死锁--
1.合理的设计索引,区分度高的列放到组合索引前面,使业务 SQL 尽可能通过索引定位更少的行,减少
锁竞争。
2.调整业务逻辑 SQL 执行顺序, 避免 update/delete 长时间持有锁的 SQL 在事务前面。
3.避免大事务,尽量将大事务拆成多个小事务来处理,小事务发生锁冲突的几率也更小。
4.以固定的顺序访问表和行。比如两个更新数据的事务,事务 A 更新数据的顺序为 1,2;事
务 B 更新数据的顺序为 2,1。这样更可能会造成死锁。
5.在并发比较高的系统中,不要显式加锁,特别是是在事务里显式加锁。如 select … for
update 语句,如果是在事务里(运行了 start transaction 或设置了autocommit 等于0),
那么就会锁定所查找到的记录。
6.尽量按主键/索引去查找记录,范围查找增加了锁冲突的可能性,也不要利用数据库做一些
额外额度计算工作。比如有的程序会用到 “select … where … order by rand();”
这样的语句,由于类似这样的语句用不到索引,因此将导致整个表的数据都被锁住。
7.优化 SQL 和表设计,减少同时占用太多资源的情况。比如说,减少连接的表,将复杂 SQL
分解为多个简单的 SQL。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通