MapReduce(分布式计算框架)
MapReduce是一种计算模型,用于处理大数据量的计算,其计算过程可以分为两个阶段(实质上是三个阶段),即Map和Reduce.
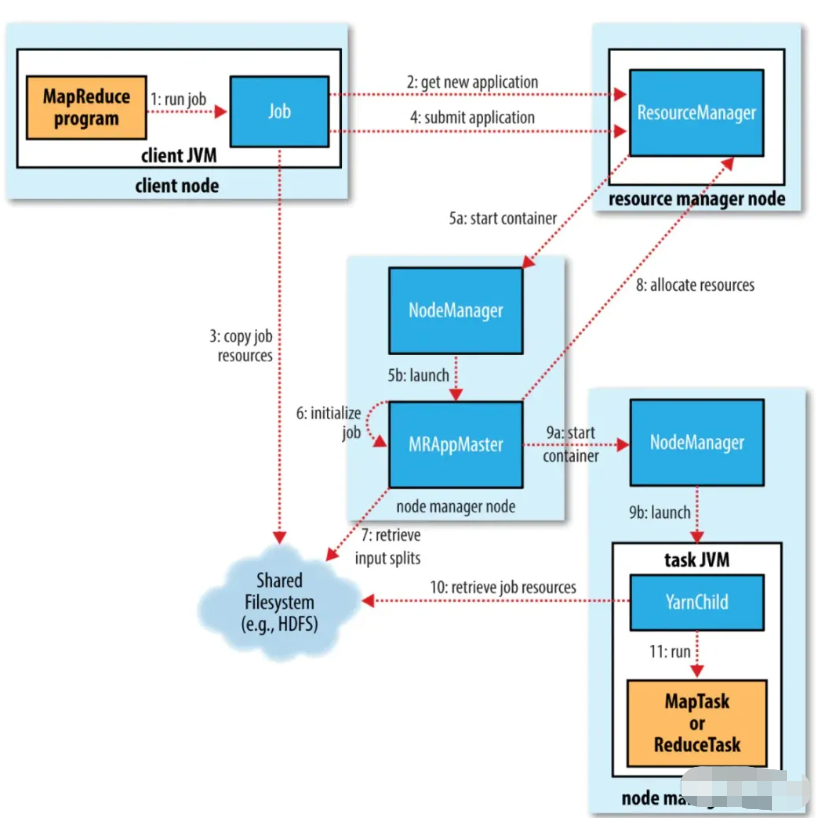
图2-3-1:MapReduce执行步骤
其中Map将输入的原始数据集转化为Key-Value(键-值对),拆分给不同节点并行进行指定的计算操作(例如排序、聚集),形成中间结果,这个计算操作的过程称为Map shuffle;Reduce则并行地对生成的中间结果中相同的Key的所有Value进行规约合并汇总处理后,输出新的Key-Value得到最终结果,这个处理相同Key的过程称为Reduce shuffle. 可以看出,在Map和Reduce中间,其实还有一个过程,就是对Map的输出进行整理并交给Reduce,这个过程就是shuffle. Map和Reduce操作需要我们自己定义相应的Map类和Reduce类,而shuffle则是系统自动帮我们实现的。
简单点理解,可以将Map看作是拆分数据集给不同的节点进行并行计算操作,将Reduce看作是整合每个节点的计算结果以汇总出最终结果(即Map负责分的计算,Reduce负责合的计算)。
图2-3-2:MapReduce工作原理
1. JobTracker和TaskTracker
MapReduce由两种主要的后台程序运行:JobTracker和TaskTracker.
(1) JobTracker
JobTracker是master节点,一个集群中只有一个,负责管理所有作业、任务/作业的监控及错误处理等,并将任务分解成一系列任务,分派给TaskTracker.
(2) TaskTracker
TaskTracker是slave节点,负责运行Map Task和Reduce Task,大数据培训并通过周期性的心跳与JobTracker交互,通知JobTracker其当前的健康状态,每一次心跳包含了可用的Map和Reduce任务数目、占用的数目以及运行中的任务详细信息。
TaskTracker和DataNode运行在一个机器上,从而使得每一台物理机器既是一个计算节点,同时也是一个存储节点,且每一个工作节点上只有一个TaskTracker.
2. Map Task和Reduce Task
在MapReduce计算框架中,一个application被划分成Map和Reduce两个计算阶段,它们分别由一个或者多个Map Task和Reduce Task组成。
(1) Map Task
每个Map Task处理输入数据集合中的一片数据(InputSplit),并将产生的若干个数据片段写到本地磁盘上。Map Task整体计算流程分为以下五个阶段(其中最后三个阶段就是上面提到的 Map shuffle):
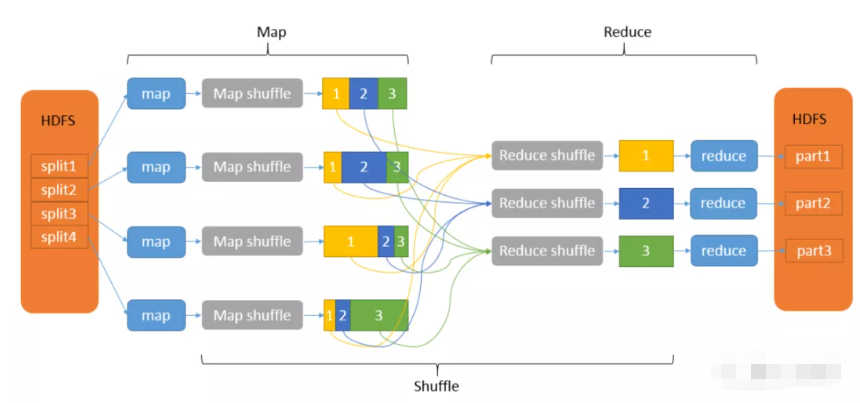
图2-3-3:Map Task工作机制
-
Read阶段:Map Task通过用户编写的RecordReader从输入InputSplit中解析出一个个的Key-Value.
-
Map阶段:该阶段主要将解析出来的Key-Value交给用户编写的map()函数处理,并产生新的Key-Value.
-
Collect阶段:在用户编写的map()函数中,首先调用Partitioner计算该Key-Value所属的partition,并将Key-Value写入到环形缓冲区中。
-
Spill阶段:即“溢写”阶段,当环形缓冲区比较满后,Map Task会将缓冲区中的数据写到本地磁盘的临时文件中,在写入文件之前,Map Task会首先对数据进行一次排序。
-
Combine阶段:当该Map Task的所有数据处理结束之后,Map Task对所有生成的临时文件进行合并,确保当前的Map Task只生成一个数据文件。
(2) Reduce Task
Reduce Task从每个Map Task上远程拷贝相应的数据片段,经分组聚集和归约后,将结果写到HDFS上作为最终结果。Reduce Task整体计算流程也分为五个阶段(其中前面三个阶段就是上面提到的 Reduce shuffle):
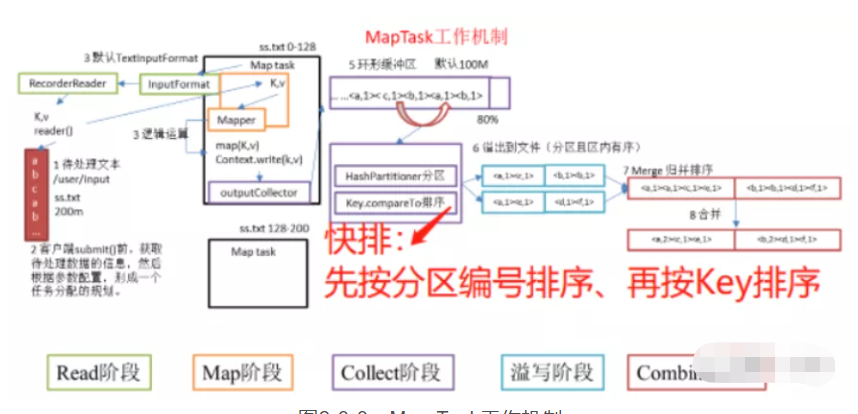
图2-3-4:Reduce Task工作机制
-
Copy阶段:Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
-
Merge阶段:在远程拷贝数据的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
-
Sort阶段:按照MapReduce语义,用户编写的reduce()函数输入数据是按Key进行聚集的一组数据。为了将Key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个Map Task已经实现对自己的处理结果进行了局部排序,因此,Reduce Task只需对所有数据进行一次归并排序即可。
-
Reduce阶段:在该阶段中,Reduce Task将每组数据依次交给用户编写的reduce()函数处理。
-
Write阶段:reduce()函数将计算结果写到HDFS上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号