基于OneFlow实现Unfold、Fold算子
1、从卷积层说起
熟悉CNN的小伙伴应该知道卷积是一个很常用也很重要的操作,CNN里的卷积和信号处理的卷积并不是一回事,CNN的卷积是做一种二维的互相关运算,以《动手学深度学习》5.1章为示例:
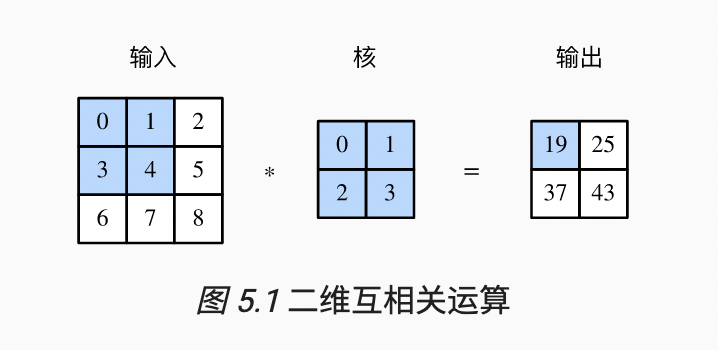
《动手学深度学习》5.1.1. 二维互相关运算
窗口内的元素和卷积核相乘,求和得到输出元素,一份naive的代码如下(同来自《动手学深度学习》
-
from mxnet import autograd, nd
-
from mxnet.gluon import nn
-
-
def corr2d(X, K): # 本函数已保存在d2lzh包中方便以后使用
-
h, w = K.shape
-
Y = nd.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
-
for i in range(Y.shape[0]):
-
for j in range(Y.shape[1]):
-
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
-
return Y
这里是借助了numpy array的索引特性来写的,如果在c++里写,需要的循环层数更多(会在后面进行展示)。而这种循环计算的写法效率并不高,会极大拖慢卷积运算的速度。
2、初见img2col
为了提高卷积运算的速度,img2col算法被发明了出来的,它的本质是用矩阵乘法来等价卷积运算,示例图如下:
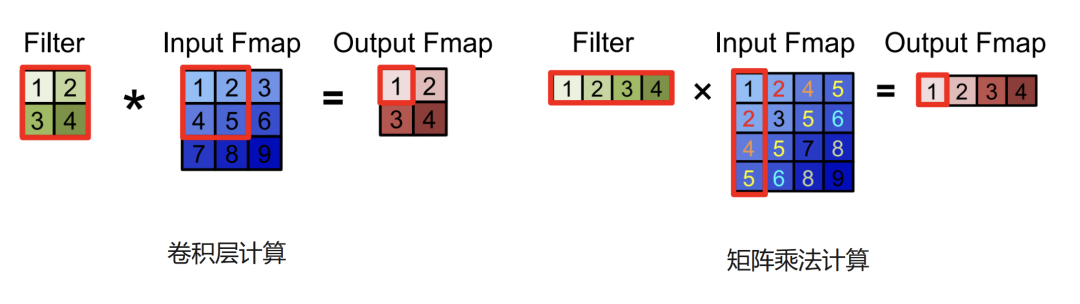
图源来自微软AI-system仓库
https://github.com/microsoft/AI-System/blob/main/docs/SystemforAI-4-Computer%20architecture%20for%20Matrix%20computation.pdf 这是微软的AISystem仓库对应的章节,强烈推荐大家去学习(本人鸽了好久没看完)
可以看到img2col把输入特征图进一步展开,然后把filter展平,两者做矩阵乘,得到了相同的结果。
3、理解img2col
看了上面的图可能还是不能理解这是怎么展开的,这里我们会介绍下:
-
假设输入特征图为(N, Cin, H, W),卷积核参数为(K, K, Cin, Cout), 输出特征图的长宽为(Oh, Ow)
经过img2col后,输入特征图会变换为 (N, Cin*K*K, Oh*Ow) 这么一个三维向量。
此外卷积核我们会reshape成一个二维向量:(Cout, K*K*Cin)。
而这两个向量可以做一个矩阵乘,输出向量为(N, Cout, Oh*Ow),这也是我们预期的卷积结果。
img2col算法是一种用空间换时间的做法,将输入进行变换后,显然它所占用的显存空间变大了,好处则是可以借助矩阵乘,快速地完成卷积运算。
4、img2col源码
darknet的img2col其实是搬运自caffe的,我们这里为了方便理解,以简单的CPU版本为例子,且不考虑batch维度。
为了让读者能够快速运行上代码,这里讲解我以自己写的一版darknet img2col来作为示例。
-
def darknet_img2col(data, channels, height, width, ksize, stride, pad):
-
out_h = int((height + 2*pad - ksize) / stride) + 1
-
out_w = int((width + 2*pad - ksize) / stride) + 1
-
-
channels_cols = channels*ksize*ksize
-
out_shape = (channels_cols, out_h*out_w)
-
elem_cnt = out_shape[0] * out_shape[1]
-
-
out_array = np.zeros(shape=elem_cnt, dtype=np.float32)
首先我们可以确定输出tensor的各个维度,其中out_h和out_w就是输出的高,宽,采用的是卷积输出的公式:
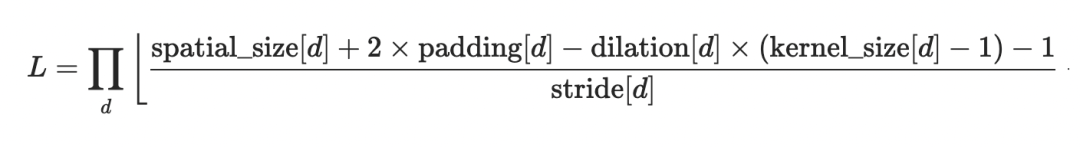
PyTorch的Unfold文档
而channel_cols则是之前我们提到的,img2col会把第二个维度变换为C_in*K*K。
然后进入到次数为channel_cols的for循环
-
for c in range(channels_cols):
-
# 分别计算一个k*k的窗口内,h,w的偏移量
-
kh_offset = (c // ksize) % ksize
-
kw_offset = c % ksize
-
# 计算当前处理的通道index
-
c_im = c // ksize // ksize
然后我们需要根据当前处理的输出元素index,来获取对应输入的元素
-
for h in range(out_h):
-
for w in range(out_w):
-
im_row = kh_offset + h * stride
-
im_col = kw_offset + w * stride
-
index = (c * out_h + h) * out_w + w
im_row的计算方式逻辑是:当前处理的输入元素窗口起始点:即h*stride,然后加上窗口内的kh_offset偏移量。
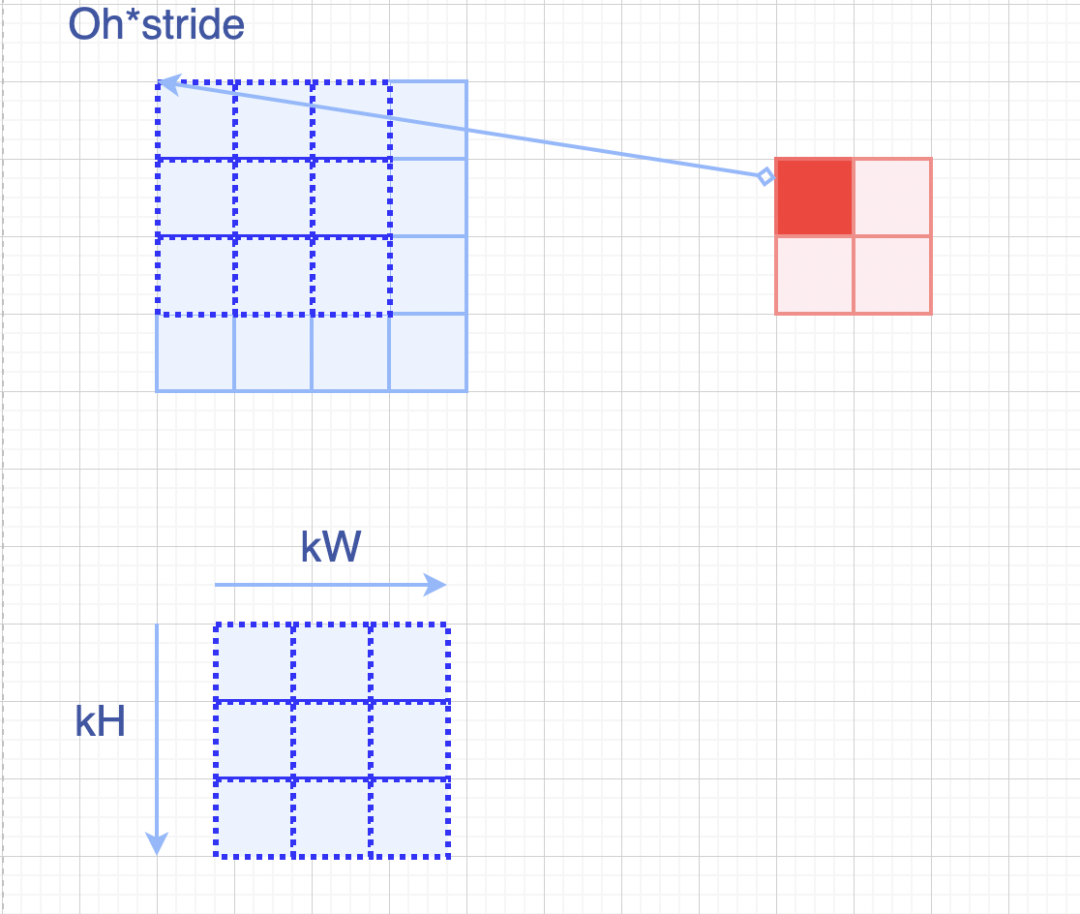
取元素逻辑
而index的计算比较容易,因为输出是(C, H, W),对应的一维index那就是
当前channel*Oh*Ow + 当前h*Ow + 当前w最后我们再将元素取出来,赋给out数组。然后再将一维的out数组reshape成我们前面推导得到的out_shape
-
out_array[index] = im2col_get_pixel(data, height, width, c_im, im_row, im_col, pad)
-
-
out_array = np.reshape(out_array, out_shape)
-
-
return out_array
img2col_get_pixel是一个合法取元素的函数,如果出现越界范围(比如小于0,或者大于Oh),那么就是取到padding的部分,此时我们返回0。
-
def im2col_get_pixel(im, height, width, channel, row, col, pad):
-
row -= pad
-
col -= pad
-
if row < 0 or col < 0 or row >= height or col >= width:
-
return 0
-
return im[int(col + width * (row + height * channel))] # batch*w*h*c + width*height*channel + width*row + col
我们可以简单构造一个数组来验证结果(以微软AI-System课程的示例作为输入)
-
x = np.arange(1, 10).astype(np.float32)
-
out = darknet_img2col(x, channels=1, height=3, width=3, ksize=2, stride=1, pad=0)
输出结果符合预期:
-
[[1. 2. 4. 5.]
-
[2. 3. 5. 6.]
-
[4. 5. 7. 8.]
-
[5. 6. 8. 9.]]
col2img
col2img则是img2col的逆过程,有兴趣的读者可以参考下这个博客:
https://blog.csdn.net/caicaiatnbu/article/details/102626135
在后面的oneflow实现里会有更完整的图例用于理解
OneFlow对应的实现
PR地址:
https://github.com/Oneflow-Inc/oneflow/pull/5675
5、OneFlow版本的Unfold
在深度学习框架里,img2col和col2img在Pytorch里还有另外的名字,也就是Unfold和Fold。通常想自己自定义一些跟卷积相关的骚操作时候,就经常会用到这两个Op。
我们假设输入是一个(1, 2, 4, 4)的张量,但在框架内部,我们通常都是以一个一维数组来存储的,如下图所示:

输入内存排布
然而我们需要对应的高维数组索引,OneFlow内部有一个NdIndexHelper类,构造的时候我们可以传入高维shape,然后调用OffsetToNdIndex来进行一维offset到高维索引的转换。
这里我们分别给输入,输出Tensor构造一个NdIndexHelper
-
in_index_helper = NdIndexOffsetHelper<INDEX_T, kInputNDim>(input_dims); // 格式为(N, C, H, W)
-
out_index_helper = NdIndexOffsetHelper<INDEX_T, kOutputNDim>(output_dims); // 格式为(N, C, Kh, Kw, Oh, Ow)
比较特别的是,我们把输出构造成一个6维的形式。
接着就是从输出的视角来推导应该取哪一个输入元素
-
// index_a format: (N, C, di, hi, wi, db, hb, wb) or (N, di, hi, wi, db, hb, wb, C)
-
// index_b format: (N, C, D, H, W) or (N, D, H, W, C)
-
// return: true indicates out-of-bound, otherwise in-bound
-
template<typename INDEX_T, int NDIM, int SDIM>
-
OF_DEVICE_FUNC bool UnfoldIndexTransform(const UnfoldParams<INDEX_T, NDIM, SDIM>& params,
-
const INDEX_T* index_a, INDEX_T* index_b) {
-
// batch dim index transform
-
index_b[0] = index_a[0];
-
// channel dim index transform
-
using ParamType = UnfoldParams<INDEX_T, NDIM, SDIM>;
-
index_b[ParamType::kInputChannelDim] = index_a[ParamType::kOutputChannelDim];
-
// spatial dim index transform
-
-
// D,H,W spatial dim index transform
-
for (int64_t d = 0; d < NDIM; ++d) {
-
INDEX_T idx = index_a[SDIM + NDIM + d] * params.stride[d]
-
+ index_a[SDIM + d] * params.dilation[d] - params.padding[d];
-
if (idx < 0 || idx >= params.dims[d]) return true;
-
index_b[SDIM + d] = idx;
-
}
-
return false;
-
}
-
模板参数 INDEX_T表示Index的数据类型(可以有int32_t, int64_t),NDIM表示处理几维数据(这里我们是2维),SDIM则是决定通道维所在位置,SDIM=1是NHWC格式,SDIM=2则是NCHW格式(这里我们取2)
-
输入参数 index_a表示输出的NdIndexHelper,index_b则表示的是输入的NdIndexHelper
从前面我们可以看到N,C这两个维度的index是不变的,所以我们直接给过去
然后进入一个次数为NDIM==2的循环
这里index的计算是从输出往输入推,公式是(以H为例):
Oh*stride_h + kh*dilation_h - padding_h计算得到输入的index,如果小于0或者大于输入的宽高,则说明是到了padding的地方,我们直接return true,以表示越界。如果能取到元素,我们则将这个index赋给index_b即输入的NdIndexHelper,且return false。
这部分的分解操作可参考下图:

从输出推导的好处就是整个运算是一个elementwise的操作,我们可以用输出tensor的元素个数做一个循环完成整个unfold操作。大数据培训
-
template<typename T, typename INDEX_T, int NDIM, int SDIM>
-
__global__ void CudaUnfoldForward(UnfoldParams<INDEX_T, NDIM, SDIM> params, const T* in, T* out) {
-
CUDA_1D_KERNEL_LOOP_T(INDEX_T, out_offset, params.out_elem_cnt) {
-
using ParamType = UnfoldParams<INDEX_T, NDIM, SDIM>;
-
INDEX_T in_index[ParamType::kInputNDim] = {0};
-
INDEX_T out_index[ParamType::kOutputNDim] = {0};
-
params.out_index_helper.OffsetToNdIndex(out_offset, out_index);
-
if (!UnfoldIndexTransform<INDEX_T, NDIM, SDIM>(params, out_index, in_index)) {
-
INDEX_T in_offset = params.in_index_helper.NdIndexToOffset(in_index);
-
out[out_offset] = in[in_offset];
-
} else {
-
out[out_offset] = static_cast<T>(kUnfoldPaddingValue);
-
}
-
}
-
}
-
首先根据offset来计算当前处理输出元素的NdIndex
-
然后判断UnfoldIndexTransform该方法的返回值
-
如果为false,则说明我们可以取到输入元素,将其index转换为1d的offset,并赋值给输出
-
如果为true,则越界,我们填充先前设定好的一个padding_value(0)
至此整个img2col流程已经完成,整体操作可参考下图:
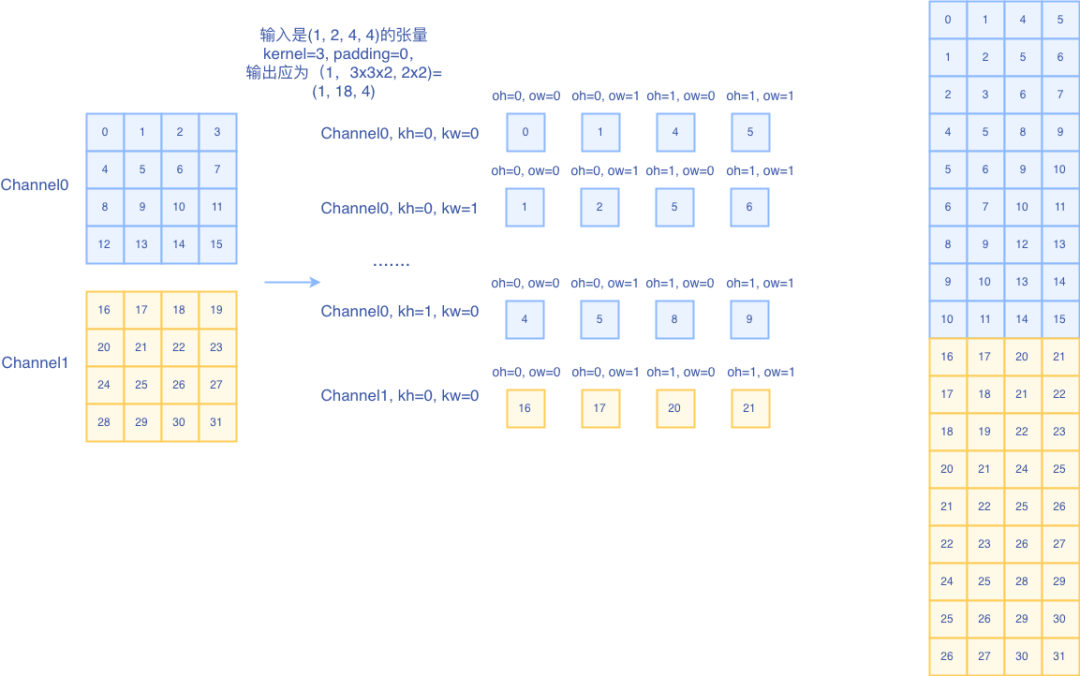
6、OneFlow版本的Fold
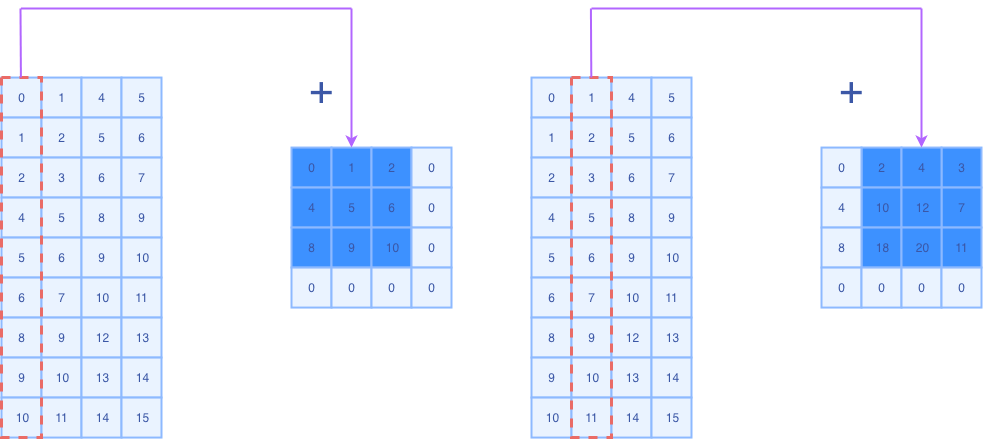
Fold就是将每一列填充回到kxk的地方
如果能理解前面的Unfold,那么这里的Fold也能很容易的理解。只是操作的元素反过来而已。
-
template<typename T, typename INDEX_T, int NDIM, int SDIM>
-
__global__ void CudaFoldForward(FoldParams<INDEX_T, NDIM, SDIM> params, const T* input_ptr,
-
T* output_ptr) {
-
CUDA_1D_KERNEL_LOOP_T(INDEX_T, in_offset, params.in_elem_cnt) {
-
using ParamType = FoldParams<INDEX_T, NDIM, SDIM>;
-
INDEX_T in_index[ParamType::kInputNDim] = {0};
-
INDEX_T out_index[ParamType::kOutputNDim] = {0};
-
params.in_index_helper.OffsetToNdIndex(in_offset, in_index);
-
if (!FoldIndexTransform<INDEX_T, NDIM, SDIM>(params, in_index, out_index)) {
-
INDEX_T out_offset = params.out_index_helper.NdIndexToOffset(out_index);
-
XPUAdd<T>::Invoke(&input_ptr[in_offset], &output_ptr[out_offset]);
-
} else {
-
continue;
-
}
-
}
-
}
沿用前面的索引映射逻辑,我们进入一个循环次数为输入元素个数的循环体,计算得到当前offset对应的输入NdIndex。
如果FoldIndexTransform返回的是false,则计算输出的offset,并使用原子加atomic add,把输入元素累加到该输出位置。
7、小结
这部分代码是接手同事写一半的代码完成的,不得不说同事的构思真的很巧妙,通过模板参数能够拓展1d 2d 3d,nchw, nhwc各种格式,尽管直观上不太好理解。
darknet版本(Caffe同款)是比较直观的帮助新手入门的img2col算法,可以结合那两篇CSDN博客来理解整个过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号